前回
【Kaggleのはじめかた】 チュートリアル ML編 part3
ではデータセットに含まれる欠損値の補償について取り扱いました
今回はlevel 2.2から始めていきます
2.2 : Using Categorical Data with One Hot Encoding
前回まではデータを取り扱う際に、扱いずらいデータを編集、あるいはカラムごと削除してしまう話をしました。では、どのようにして文字列などを扱うことができるのでしょうか?
この章のタイトルにある、One-Hot Encodingは単語などをプログラムで取り扱うためにカテゴリーを01で分類してしまう手法のことです。
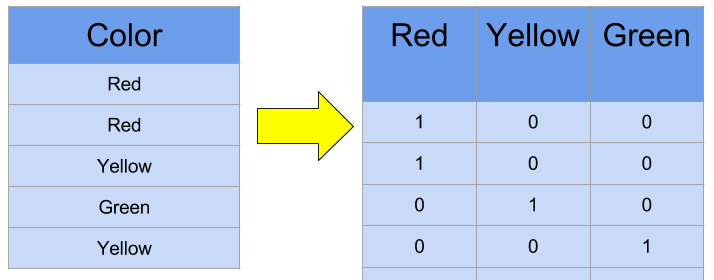
このようにして、単語をベクトルとして扱えるようになります。
例
チュートリアルのサンプルコードが少々分かりにくかったため、ある程度オリジナルなものをサンプルとして紹介します。
# おなじみ
import pandas as pd
# pathを短く
melbourne_file_path = '../input/melb_data.csv'
melbourne_data = pd.read_csv(melbourne_file_path)
print(melbourne_data.columns)
まずは毎度おなじみのデータセットの用意から。前回までのkernelをしようとしたところ上手くいかなかったため新しいkernelを使用しています。
新しいカーネルですと、データセットがダウンロードされていないので、Codeの隣にあるDataタブで検索して追加する必要があります。
pathについて、"../input/melb_data.csv"だとうまくいきました。不透明なディレクトリ構造のため、エラーに注意してください。
# データ分割用のライブラリをインストール
from sklearn.model_selection import train_test_split
# 本来はこんなにありませんが、練習のため全部入れてみました
melbourne_predictors = ['Suburb', 'Address', 'Rooms', 'Type', 'Price', 'Method', 'SellerG',
'Date', 'Distance', 'Postcode', 'Bedroom2', 'Bathroom', 'Car',
'Landsize', 'BuildingArea', 'YearBuilt', 'CouncilArea', 'Lattitude',
'Longtitude', 'Regionname', 'Propertycount']
# train_predictorsが欲しかったので、ここに格納してあげます。
train_predictors = melbourne_data[melbourne_predictors]
# やっとです。各カラムのデータ型を表示します
train_predictors.dtypes.sample(10)
Price float64
BuildingArea float64
Method object
Longtitude float64
Postcode float64
Date object
Address object
YearBuilt float64
Regionname object
Landsize float64
dtype: object
チュートリアルとは違った結果になりますが、確かにデータ型が混在していますね。