この記事を書くことになった経緯
実家をリフォームするにあたり、大量のアルバムを処分することになりました![]()
写真の数でいうと私がメインに写ってるものだけでもざっくり2000枚はあったんじゃないかと思います。
当時のめっちゃかわいい私の写真をそのまま捨てるのもなんだかもったいないと思ったため、目grepで厳選して150枚くらいを手元に残しました。
しかしこの150枚もただ手元に置いておくと劣化していく一方です。
ではデジタル化して保存しておこうと![]()
私もエンジニアの端くれ、ただクラウドサービスに保管するだけというのもつまらないので、せっかくだからS3より低料金で保存できるS3 Glacierを使おうと思い立ったわけです。
![]() あくまでもS3 Glacierを使ってみたい、という欲求が先にありました。AmazonPrimeの特典で使えるAmazonPhotos、Pixel限定特典Googleフォト無制限利用など、そういったサービスの利用は除外してます。普通に使う分にはそっちのほうがオススメだと筆者も思ってます
あくまでもS3 Glacierを使ってみたい、という欲求が先にありました。AmazonPrimeの特典で使えるAmazonPhotos、Pixel限定特典Googleフォト無制限利用など、そういったサービスの利用は除外してます。普通に使う分にはそっちのほうがオススメだと筆者も思ってます ![]()
余談ですがデジタル化は富士フイルムの「写真スキャンサービス」を利用しました。
単に大手のサービスだから良いだろう、という理由での選択で他サービスとの金額の比較などはしていません。
注文が殺到しているため遅れるとのことで、ちょっと時間はかかりましたが綺麗にスキャンしていただきました ![]()
結論
上記のような用途だったらS3 Glacierは使わないほうがいい。
おとなしくS3を使おう。S3のストレージクラスの設定で低頻度やGlacierを使うのがいいんじゃないかな。
あとはAmazonPhotosやGoogleフォトみたいなクラウドサービス。アルバム機能とかタグ機能とか便利ですし。
経過報告
やったこと
ざっくり
- S3よりデータ保存料が安い
- 取り出すのに時間がかかる
くらいの知識しかなかったので、まずはGlacierとは何者かを調べるところから始めます。
Glacierの基礎知識
公式のドキュメントを見ましょう。
- https://docs.aws.amazon.com/amazonglacier/latest/dev/introduction.html
- https://docs.aws.amazon.com/amazonglacier/latest/dev/amazon-glacier-data-model.html
なお、本記事の7割くらいは上記の記事たちの意訳です。英語が得意な方は原典を当たりましょう。
Vault - ボールト
S3のバケットに値するようなもの。正式には「アーカイブを保存するためのコンテナ」と説明されている。
ボールトの作成はGUI(コンソール)でできるが、それ以外はCLIやAPI、SDKを使う必要がある。
つまりArchiveの取得などの操作もすべてCLIなどから行う必要があるのでエンジニア以外の方にはとっつきづらい。
ただしS3のバケットの設定でライフサイクルをGlacierにするとS3側のGUIで操作することはできる。
1つのボールトに保存できるアーカイブに制限はない。
操作はすべてリージョンごとに分割されてる。リージョンをまたいだ操作はできなさそう。
Archive - アーカイブ
S3のオブジェクトに値するようなもの。
アップロード時に説明(description)を添えることができる。このdescriptionはあとからは変えられない。
またS3みたいに任意のファイル名(キー名)を割り当てることはできず、ランダムで割り当てられるアーカイブIDとdescriptionだけしかそのファイルを表すものはない。
なのでS3みたいにフォルダを分けるとかもできない。Vault単位で分けるしかない。
上記のことからGlacier単体では目視でArchiveの内容を確認・推測するということは難しい。(descriptionを見て判断するしかない)
ちなみにSQLでS3やGlacierをSELECTできるという機能があるが、それはS3のオブジェクト、Glacierのアーカイブに対して行う、つまりデータの中身を検索してひっかけるもの。
なのでVaultに対して検索をかけてArchiveを探すようなものではない点に留意すること。
更新という概念はない。削除→再アップロードが基本。
もちろんIDは一意なので再アップロードすることによってアーカイブIDは変わる。
Job - ジョブ
Selectクエリを実行したりArchiveを取得したりする際に実行するもの。
Glacierは即時に結果が返ってくるものではないのでジョブを発行して、そのジョブが終わったかどうかを確認して次のジョブを実行するべきかを判断する。
つまりWebを代表するようなリアルタイムアプリケーションには向かない。
ジョブの種類は3つ。
- select - アーカイブの検索
- archive-retrieval - アーカイブの取得
- inventory-retrieval - インベントリの取得
アーカイブの検索と取得のジョブはボールト名とアーカイブIDが、インベントリ(アーカイブのリスト)の取得ジョブはボールト名がそれぞれ必須パラメータとして必要。
なお、アーカイブの検索には出力結果をS3に配置するので透過的にS3も使うことになる。(権限設定周りを忘れずにね)(アーカイブの検索だけ?取得系にも必要なのでは?未検証だけど気になる)
ジョブごとにジョブタイプ、説明、作成日、完了日、ジョブステータスなどの情報を持っている。
特定のジョブに関する情報を取得したり、ボールトに関連付けられているすべてのジョブのリストを取得できる。
ジョブリストの中には最近完了したものも含まれる、とのこと。完了しているジョブは一定期間(24時間ってどこかのドキュメントで見た気がするけどうろ覚え)するとジョブリストの結果からは消える(取得できなくなる)。
ジョブ完了通知の設定
ジョブが完了したときにAmazon SNSを通じて完了を通知する設定が可能。
設定はVault1つに対して1SNSトピックに限定される。アーカイブやジョブごとではない点に留意。
通知設定をしないこともできるし、後から通知設定の追加/削除ができたり、通知設定がどうなってるかの確認も可能。
試しにVaultの作成をする
Vaultを作成する場合、こんな感じのコマンドを実行します。
$ aws glacier create-vault --account-id $ACCOUNT_ID --vault-name my-old-photos --profile zom
AWSのアカウントIDとVault名、あとは使用するプロファイル名ですね。
IAMやcredentialの設定に不備がなければ下記のように成功のレスポンスが返ってきます。
※$のところは各自で設定してください。(IAMのユーザ名のzomのところもですが)
{
"location": "/$ACCOUNT_ID/vaults/my-old-photos"
}
私の場合、IAMでzomユーザの権限をキツくして、CLIでの実行時にも2要素認証を必要とするようにしてしまっていたため下記のような手順で実行していました。
$ aws sts get-session-token --serial-number "arn:aws:iam::$ACCOUNT_ID:mfa/zom" --token-code $TOKEN --profile=zom
{
"Credentials": {
"AccessKeyId": "access key id",
"SecretAccessKey": "secret access key",
"SessionToken": "session token",
"Expiration": "2021-05-05T03:57:17+00:00"
}
}
aws sts get-session-tokenで返ってきたcredentialを~/.aws/credentialにセットします。
[mfa]
aws_access_key_id = $AccessKeyId
aws_secret_access_key = $SecretAccessKey
aws_session_token = $SessionToken
上記の$の部分はすべて返ってきたjsonを使うようにしています。
そして、こう。
$ aws glacier create-vault --account-id $ACCOUNT_ID --vault-name my-old-photos --profile mfa --region=ap-northeast-1
※mfaユーザのprofile指定をしていなかったのでコマンドラインオプションで指定しました。
Glacierとはあまり関係ないところで躓きました ![]()
AWSのソリューションアーキテクトの人の資料を見る
このVaultを作ったタイミングでググって出てきた資料に目を通しました。
[AWSマイスターシリーズReloaded -Amazon Glacier-](//www.slideshare.net/AmazonWebServicesJapan/awsreloaded-amazon-glacier)そしてそこに書かれていた文言ですべてを察しました。
アップロード時にシステム側でArchive IDを自動発行
• 別途メタデータ/インデックス管理DBを準備することを推奨
ああ、デスヨネ…![]()
つまりGlacierを使いたい場合には別途DB、AWSのサービスで実現するならRDB on EC2(Lightsail)かRDSの利用もセットとなり、目的であるお安く管理なんてとてもとても…。
※ここでは月々数円単位での運用を想定しています。
他に思ったこと
GlacierにはVaultLockというArchiveの削除を防ぐ仕組みなどがあります。
そういうところから察するに、個人レベルの写真の保存とかそういうものではなくて、業務上の監査が必要なレベルの処理ログなどを保管して、
監査のタイミングで取り出す、などが想定されうる使い方なんだろうな…などと…。
単にS3より安いから使ったろ!ではない…ということですね。
結論に立ち戻る
本記事の途中で「S3のバケットの設定でライフサイクルをGlacierにするとS3側のGUIで操作することはできる。」と書きました。
そのとおりでS3からオブジェクトをアップロードする際にストレージクラスの指定ができ、ここでGlacierを選べます。
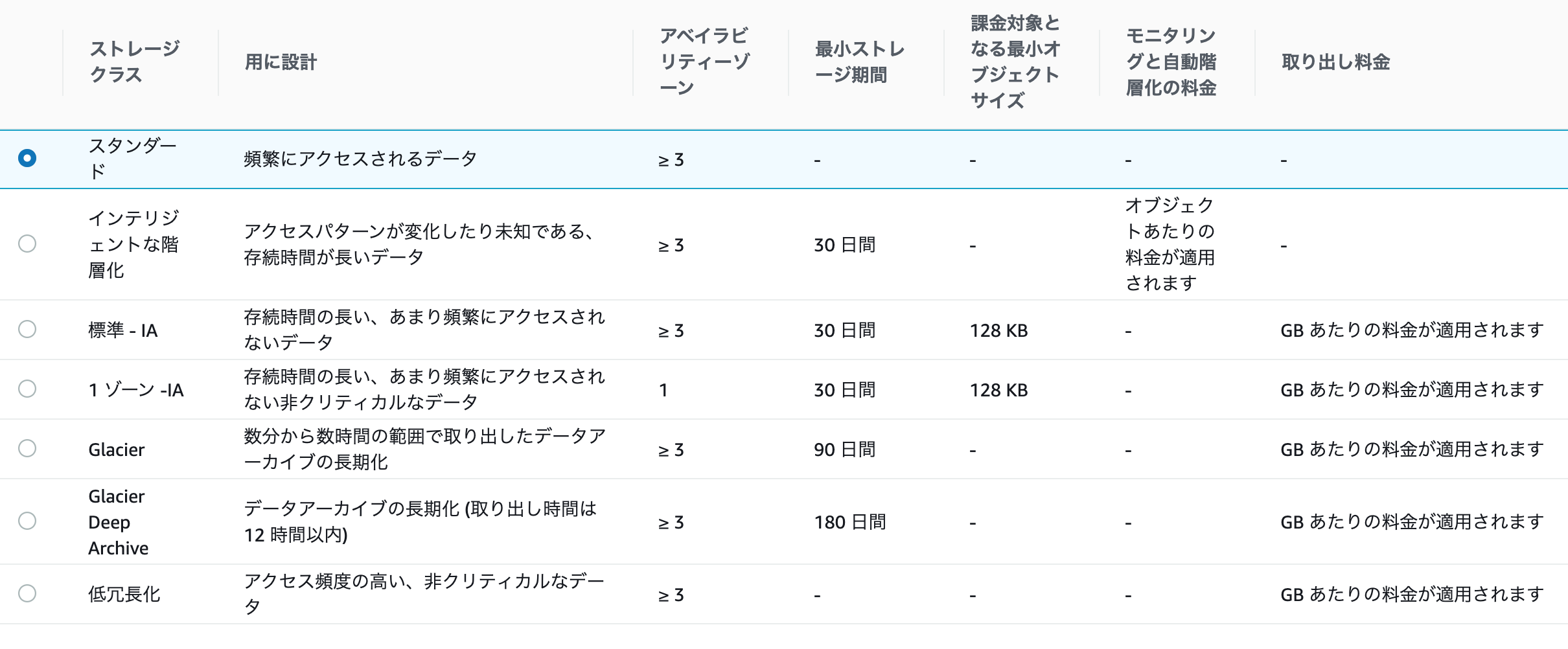
ここでGlacierを選択した場合だと、ジョブの実行や取得といったことがS3のGUI上で操作可能です。
そこまでシビアにコスト管理しないならS3標準IA(低頻度アクセス)や、可用性が低くても何ら問題ないのだったら1ゾーンIAでもいいのでは…
という感じになります。
そこらへんは料金表とにらめっこして決めればよいかと思います。
ということでGlacierで低コストで写真管理!なんて面倒なことは止めましょう、という記事でした。
他にGlacierを初手に選ぶ人がいないことを願います ![]()