はじめに
生成AIを業務利用する際には、以下のような不安はないでしょうか。
- ユーザーが不適切な質問を投げたらどうするのか
- Claudeが不適切な回答を返したらどうするのか
- 個人情報や機密情報を誤って入力・出力してしまわないか
- 社内で許可していないモデルを勝手に使われないか
- 誰が、いつ、どのモデルを使ったのか監査できるのか
- プロンプトインジェクションや脱獄プロンプトにどう備えるのか
私も最初は「Bedrock Guardrailsを入れておけば、だいたい安全になるのでは?」と思っていました。
ただ、実際に業務利用を前提に設計を考えてみると、Guardrailsだけではカバーしきれない領域がかなりあります。
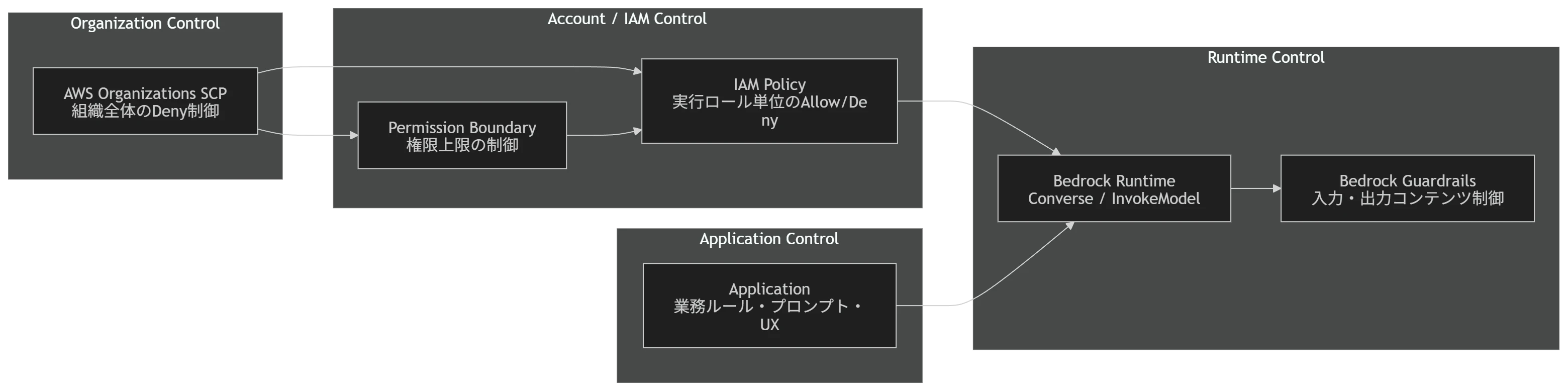
たとえば、Guardrailsは入力・出力の安全性を見るには便利ですが、「誰がどのモデルを呼び出せるのか」「Guardrailsなしの呼び出しをどう防ぐのか」「あとから監査できるのか」といった話は、IAMやSCP、CloudTrail、ログ設計まで含めて考える必要があります。
この記事では、ClaudeをAmazon Bedrock上で利用する前提で、Amazon Bedrock Guardrails、IAM、SCP、CloudTrail、Model invocation logging、アプリケーション実装をどう組み合わせるのがよさそうかを整理します。
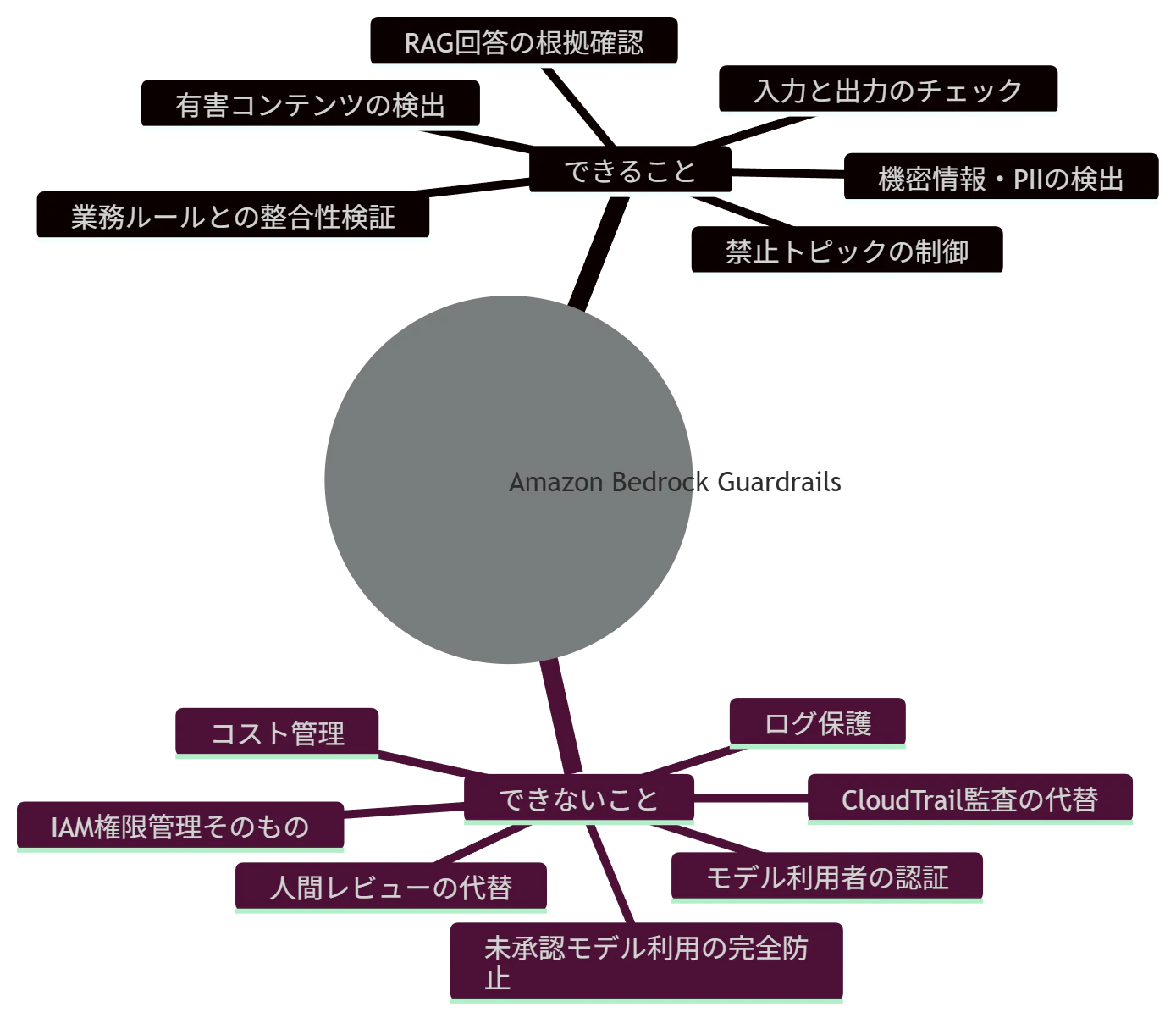
特に、自分が設計するときに迷いやすいと感じた「Guardrailsは何を守るものなのか」「逆に何は守れないのか」という境界を中心に書いていきます。
Amazon Bedrock Guardrailsは、不適切なコンテンツの検出・フィルタリング、機密情報のマスク、ハルシネーション抑制のためのチェックなどを提供する機能です。チャットボット、金融アプリケーション、コールセンター要約のような用途で、望ましくない入力・出力やPIIを扱うときに使える機能として位置づけられています。(AWS Documentation)
ただし、Guardrailsだけで「誰がどのモデルを使えるか」「必ずGuardrailsを通して呼び出すか」「監査ログをどう残すか」まで完結するわけではありません。そこでこの記事では、Guardrailsを中心にしつつ、AWSの権限制御・監査・運用設計とどう組み合わせるのが現実的かを考えていきます。
対象読者
この記事は、以下のような方には特に参考になると思います。
- Amazon BedrockでClaudeを使い始めたい方
- Claudeを業務・社内システムに組み込みたい方
- 生成AI利用におけるセキュリティ統制を設計したい方
- Bedrock Guardrailsの使いどころを整理したい方
- IAM/SCP/CloudTrailを含めたAWSらしい統制設計を考えたい方
この記事で伝えたいこと
私なりに整理すると、Amazon BedrockでClaudeを安全に使うための基本方針は、次のようになると思います。
- Guardrailsはコンテンツ安全性の制御に使う
- IAM/SCPはモデル利用権限の制御に使う
- CloudTrailはAPI操作の監査に使う
- Model invocation loggingは入出力内容の監査・分析に使う
- アプリケーション側で業務ルール・プロンプト設計・例外処理を実装する
- 本番導入では「防止」「検知」「監査」「改善」のループを設計する
つまり、Guardrailsはかなり重要な部品ですが、これだけで全部守れるわけではない、というのがこの記事の前提です。
生成AIの安全設計では、次のようにレイヤーを分けて考えた方が、かなり整理しやすいと感じています。
| レイヤー | 主な制御内容 | AWSでの代表的な手段 |
|---|---|---|
| 組織統制 | 利用可能サービス・モデルの制限 | Organizations / SCP |
| 権限制御 | どのIAMロールが何を呼べるか | IAM policy / Permission boundary |
| モデル呼び出し制御 | 許可モデル、Guardrail必須化 | IAM condition / Bedrock Guardrails |
| 入出力安全性 | 有害コンテンツ、PII、禁止トピック | Bedrock Guardrails |
| 監査 | 誰がいつ何を呼んだか | CloudTrail |
| 入出力ログ | プロンプト・レスポンスの記録 | Model invocation logging |
| アプリ制御 | 業務ルール、UX、エラーハンドリング | アプリケーション実装 |
このように分けてみると、Guardrailsが担当する範囲と、IAM/SCPやアプリケーション側で担当する範囲が見えやすくなります。自分としては、この役割分担を最初に置いておくのが設計上かなり大事だと感じています。
Amazon Bedrock Guardrailsとは
Amazon Bedrock Guardrailsは、生成AIアプリケーションに安全性やプライバシー保護のための制御を追加する機能です。
Guardrailsで使える主なフィルター・ポリシーをざっくり並べると、次のようになります。(AWS Documentation)
- Content filters
- Denied topics
- Word filters
- Sensitive information filters
- Contextual grounding checks
- Automated Reasoning checks
それぞれの役割をざっくり整理すると、次のようになります。
| 機能 | 役割 | 例 |
|---|---|---|
| Content filters | 有害・不適切コンテンツの検出 | Hate, Insults, Sexual, Violence, Misconduct, Prompt Attack |
| Denied topics | 業務上扱わせたくない話題のブロック | 違法投資助言、社外秘の話題、競合比較など |
| Word filters | 特定単語・フレーズのブロック | 禁止語、競合名、内部コード名 |
| Sensitive information filters | PIIや正規表現による機密情報の検出・マスク | メールアドレス、電話番号、社員番号など |
| Contextual grounding checks | 参照情報に基づく回答かを確認 | RAG回答の根拠確認 |
| Automated Reasoning checks | 定義済みポリシーに対する回答整合性の検証結果を返す | 社内規定、契約条件、業務ルールとの矛盾検出 |
Word filtersは、意味的なトピック判定というより、指定した単語・フレーズに基づく制御です。業務上扱わせたくない話題そのものを制御したい場合は、Denied topicsと組み合わせて設計します。
Guardrailsでまず押さえておきたいのは、入力と出力の両方に対して安全性チェックをかけられる点です。
ユーザー入力に対しては、危険な質問や機密情報の入力を検知できます。
モデル出力に対しては、不適切な回答、PIIの出力、禁止トピックへの回答などを抑制できます。
Guardrailsは何を守れるのか
Guardrailsを使うときは、「結局、何を防ぐための機能なのか」を最初に分けて考えた方がよいと思います。
1. 有害コンテンツの抑制
Content filtersでは、有害または不適切な入力・出力を検出できます。カテゴリとしては、Hate、Insults、Sexual、Violence、Misconduct、Prompt Attackなどが用意されています。(AWS Documentation)
Claude自体にも安全性の仕組みはありますが、Bedrock Guardrailsを使うと、アプリケーション単位で追加の制御を乗せられます。
たとえば、社内チャットボットで以下のような入力を抑止できます。
- 暴力的な内容
- 差別的な内容
- 不適切な性的内容
- 不正行為の助長
- プロンプトインジェクションや脱獄を狙う入力
特に企業利用では、「モデル側の安全性に任せる」だけでは少し心もとないです。自社アプリケーションとして許容しない入力・出力を明示的に定義することが大事だと思います。
2. 禁止トピックの制御
Denied topicsでは、アプリケーションで扱わせたくないトピックを定義できます。
たとえば、社内ヘルプデスクAIであれば、以下のようなトピックを拒否対象にできます。
- 投資助言
- 法的判断
- 医療診断
- 社外秘プロジェクト
- 人事評価
- 未公開の財務情報
- 競合企業の誹謗中傷
ここで大事なのは、Denied topicsを単なるNGワードリストとして見ないことだと思います。どちらかというと、業務文脈上、回答してはいけない話題を定義する仕組みとして使うイメージです。
たとえば「株」という単語をすべて禁止するのではなく、「個別銘柄の売買判断を助言すること」を禁止する、といった設計が考えられます。
3. 機密情報・個人情報の保護
Sensitive information filtersでは、PIIやカスタム正規表現を使った機密情報の検出・マスクが可能です。AWS公式のAPIリファレンスでも、PIIやカスタムregexをユーザー入力・モデル応答からブロックまたはマスクできるという整理です。(AWS Documentation)
ただし、標準PII検出は確率的な検出であり、文脈に依存します。そのため、社内ID、契約番号、AWSアカウントID、独自形式の顧客IDなど、確実に検出したい情報は、カスタム正規表現やアプリケーション側の入力検査と組み合わせる設計が望ましいです。
たとえば、以下のような情報を検出対象にできます。
- メールアドレス
- 電話番号
- 住所
- 氏名
- クレジットカード番号
- 社員番号
- 契約番号
- AWSアカウントID
- 内部システムID
- 独自フォーマットの顧客ID
企業利用では、個人的にここがかなり重要だと思っています。
生成AIでは、ユーザーが悪意なく機密情報を入力してしまうことがあります。
また、RAGや社内データ連携を行う場合、モデルが回答内に不要な個人情報や内部情報を含めてしまう可能性もあります。
そのため、GuardrailsのSensitive information filtersは、入力時の漏えい防止と出力時の過剰開示防止の両方で考えるのがよいと思います。
4. RAG回答のハルシネーション抑制
Contextual grounding checksは、参照情報とユーザー質問を与えたうえで、モデル回答が参照情報に基づいているか、質問に関連しているかをチェックする機能です。主にsummarization、paraphrasing、question answering向けの機能で、GroundingとRelevanceの観点で評価します。(AWS Documentation)
RAG構成にすると、Claudeが社内文書を参照して回答するケースが多くなります。
ただ、RAGを使っているからといって、必ず正しい回答になるわけではありません。たとえば、次のような回答は普通に起こり得ます。
- 参照文書にない内容を補ってしまう
- 古い情報と新しい情報を混ぜてしまう
- 質問に関係ない箇所を根拠にしてしまう
- もっともらしいが根拠のない回答を返す
Contextual grounding checksは、このような回答に対して「参照情報に基づいているか」「質問に関連しているか」を見るために使えます。
ただし、ここは少し注意が必要です。会話型QA/チャットボット用途はサポート対象外とされているため、万能なハルシネーション対策としてではなく、要約・言い換え・QAなど、合うユースケースで使うのがよいです。(AWS Documentation)
5. 業務ルールとの整合性チェック
Automated Reasoning checksは、自然言語の回答を、あらかじめ定義したポリシーに照らして検証するための機能です。ざっくり言うと、生成された内容が定義済みのポリシールールと矛盾していないかを確認するための仕組みです。(AWS Documentation)
これは、単なるNGワード検出や有害コンテンツ検出とは少し性質が違います。
たとえば、以下のような業務ルールがあるとします。
- 契約期間が1年未満の場合、途中解約手数料は発生しない
- 法人契約の場合、個人向けキャンペーンは適用できない
- 管理者権限の申請には上長承認が必要
- 本番環境への変更作業はメンテナンスウィンドウ内に実施する
Claudeがこれらのルールに反する回答をした場合、Automated Reasoning checksで検証結果として検出できる可能性があります。
ただし、Automated Reasoning checksは、Content filtersやDenied topicsのように「引っかかったらその場で回答を止める」機能として考えない方がよいです。現時点では detect mode only の位置づけで、検証結果やフィードバックを返します。そのため、アプリケーション側でその結果を見て、回答をそのまま返すのか、再生成するのか、人手確認に回すのか、ユーザーに追加確認を求めるのかを決める必要があります。(AWS Documentation)
また、Automated Reasoning checksにも制約があります。たとえば、プロンプトインジェクション保護ではない、オフトピック検出ではない、ストリーミングAPIをサポートしない、英語のみ対応、検証範囲は定義したポリシーに限定される、といった点には注意が必要です。(AWS Documentation)
したがって、Automated Reasoning checksは「業務ルールに対する回答の整合性検証」として有効ですが、これだけでAIアプリ全体の安全性を担保できるわけではありません。実務上は、Automated Reasoning checksの検証結果をアプリケーション側の業務ロジックに組み込む設計が重要です。
Guardrailsだけでは足りない理由
ここが、この記事で一番書きたかったポイントです。
Amazon Bedrock Guardrailsは強力ですが、Guardrailsは権限制御そのものではありません。ここを混同すると、設計が危なくなると感じています。
Guardrailsでできることは、主に入力・出力コンテンツの検出、ブロック、マスク、検証です。ただし、すべてのGuardrails機能が同じように自動ブロックするわけではなく、Automated Reasoning checksのように検証結果を返し、アプリケーション側で扱いを判断する機能もあります。
一方で、次のような統制はGuardrails単体では完結しません。
- 利用可能なモデルをClaudeのみに制限する
- Claudeの中でも特定バージョンだけ許可する
- Guardrailsを指定しないBedrock呼び出しを禁止する
- 開発者が別モデルを勝手に有効化することを防ぐ
- どのIAMロールがモデルを呼び出したか監査する
- モデル呼び出しの入出力をログとして保管する
- 本番環境と検証環境で制御を分ける
これらは、IAM、SCP、CloudTrail、Model invocation logging、アプリケーション実装で受け持つ領域だと考えた方がよさそうです。
つまり、実務上の設計は次のように考えた方がよいです。
Guardrails = 入出力コンテンツの安全装置
IAM/SCP = 利用者・モデル・操作の権限制御
CloudTrail = API操作の監査
Invocation Logging = 入出力データの監査・分析
Application = 業務ロジックとUX制御
以下のようにすると、少しブログらしい自然な文章になりつつ、設計としての説得力も残せると思います。
設計パターン1:許可するClaudeモデルを絞る
まず考えたいのが、利用可能なモデルの制限です。
Amazon Bedrockでは、Claudeをはじめとして複数のFoundation Modelを利用できます。ただ、企業で使う場合は「どのモデルを使ってよいのか」をあらかじめ決めておいた方がよいと思います。
たとえば、以下のようなルールです。
- 本番環境ではClaude Sonnetのみ許可する
- 検証環境ではClaude SonnetとClaude Haikuを許可する
- 画像生成モデルは利用禁止にする
- Marketplace経由の未承認モデルは利用禁止にする
- 新規モデルは、評価が完了するまで利用禁止にする
生成AIを業務利用する場合、「便利だから何でも使えるようにする」という考え方は、少し危ないと感じています。
特に企業利用では、モデルごとの性能差だけでなく、利用規約、データの取り扱い、利用可能なリージョン、監査対応なども考える必要があります。そのため、まずは利用するモデルを絞り込むことが重要だと思います。
このあたりはIAMポリシーでも制御できます。たとえば、特定モデルに対する推論を拒否するポリシーを設定できます。また、InvokeModelを拒否すると、内部的にモデル推論を利用するConverseなどのAPIにも影響する関係になっています。(AWS Documentation)
特定モデルの推論を拒否するポリシーの考え方は、以下のようになります。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "DenySpecificFoundationModel",
"Effect": "Deny",
"Action": [
"bedrock:InvokeModel",
"bedrock:InvokeModelWithResponseStream",
"bedrock:CreateModelInvocationJob"
],
"Resource": "arn:aws:bedrock:*::foundation-model/model-id"
}
]
}
実務では、大きく分けると以下の2つの考え方があります。
- Denyベースで「使わせたくないモデル」を明示する
- Allowベースで「使ってよいモデルだけ」を許可する
どちらが正解というより、環境や組織の運用方針によって使い分けるのがよいと思います。
個人的には、重要な本番ワークロードでは、以下のような設計が現実的だと考えています。
- アプリケーション実行ロールには、利用するモデルだけをAllowする
- Organizations SCPでは、明確に禁止したいモデルやプロバイダーをDenyする
- 新規モデルは、評価プロセスを通してから許可する
- 開発環境と本番環境でポリシーを分ける
特に本番環境では、Allowベースで「使ってよいモデルだけを明示する」方が安全だと思います。新しいモデルが追加されたときに、意図せず使えてしまうリスクを下げられるためです。
一方で、Organizations SCPを使って、特定のLLMプロバイダーを組織全体で拒否する設計も有効だと思います。
たとえば、AnthropicやOpenAIなどのLLMプロバイダーでは、利用規約上、利用可能な地域や条件に制限が設けられている場合があります。そのため、中国などのオフショア開発拠点を含むチームでは、SCPで特定プロバイダーのモデル利用を拒否しておくことで、意図しない利用規約違反を防ぎやすくなります。
もちろん、SCPだけですべてを解決できるわけではありません。ですが、「組織として利用してよいモデルの範囲を決める」という意味では、かなり有効なガードレールになると考えています。
設計パターン2:Guardrailsの利用を必須化する
次に考えたいのは、Bedrockを呼び出すときにGuardrailsを必ず指定させることです。
アプリケーションコードでGuardrailsを指定していても、IAM権限が広すぎると、開発者や別アプリがGuardrailsなしでモデルを直接呼び出せてしまう可能性があります。
ここで使えるのが、条件キーの bedrock:GuardrailIdentifier です。これを使うと、特定のGuardrailを指定した呼び出しだけを許可する設計ができます。(AWS Documentation)
考え方としては、以下のようなポリシーです。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowInvokeClaudeWithApprovedGuardrail",
"Effect": "Allow",
"Action": [
"bedrock:InvokeModel",
"bedrock:InvokeModelWithResponseStream",
"bedrock:Converse",
"bedrock:ConverseStream"
],
"Resource": [
"arn:aws:bedrock:ap-northeast-1::foundation-model/anthropic.claude-sonnet-4-20250514-v1:0"
],
"Condition": {
"StringEquals": {
"bedrock:GuardrailIdentifier": "arn:aws:bedrock:ap-northeast-1:123456789012:guardrail/xxxxxxxxxx"
}
}
}
]
}
さらに厳密にする場合は、Guardrail指定がない呼び出しをDenyするポリシーを組み合わせます。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "DenyInvokeWithoutGuardrail",
"Effect": "Deny",
"Action": [
"bedrock:InvokeModel",
"bedrock:InvokeModelWithResponseStream",
"bedrock:Converse",
"bedrock:ConverseStream"
],
"Resource": "*",
"Condition": {
"Null": {
"bedrock:GuardrailIdentifier": "true"
}
}
}
]
}
このようにしておくと、Guardrailsなしの呼び出しを組織的に抑止しやすくなります。
ただし、実際にどのアクション・リソース・条件キーに対して期待通りに評価されるかは、対象API、モデル種別、リージョン、Inference Profile利用有無によって確認が必要です。IAM Policy Simulatorや実環境での検証を必ず行うのがよいです。
設計パターン3:Converse APIでGuardrailsを指定する
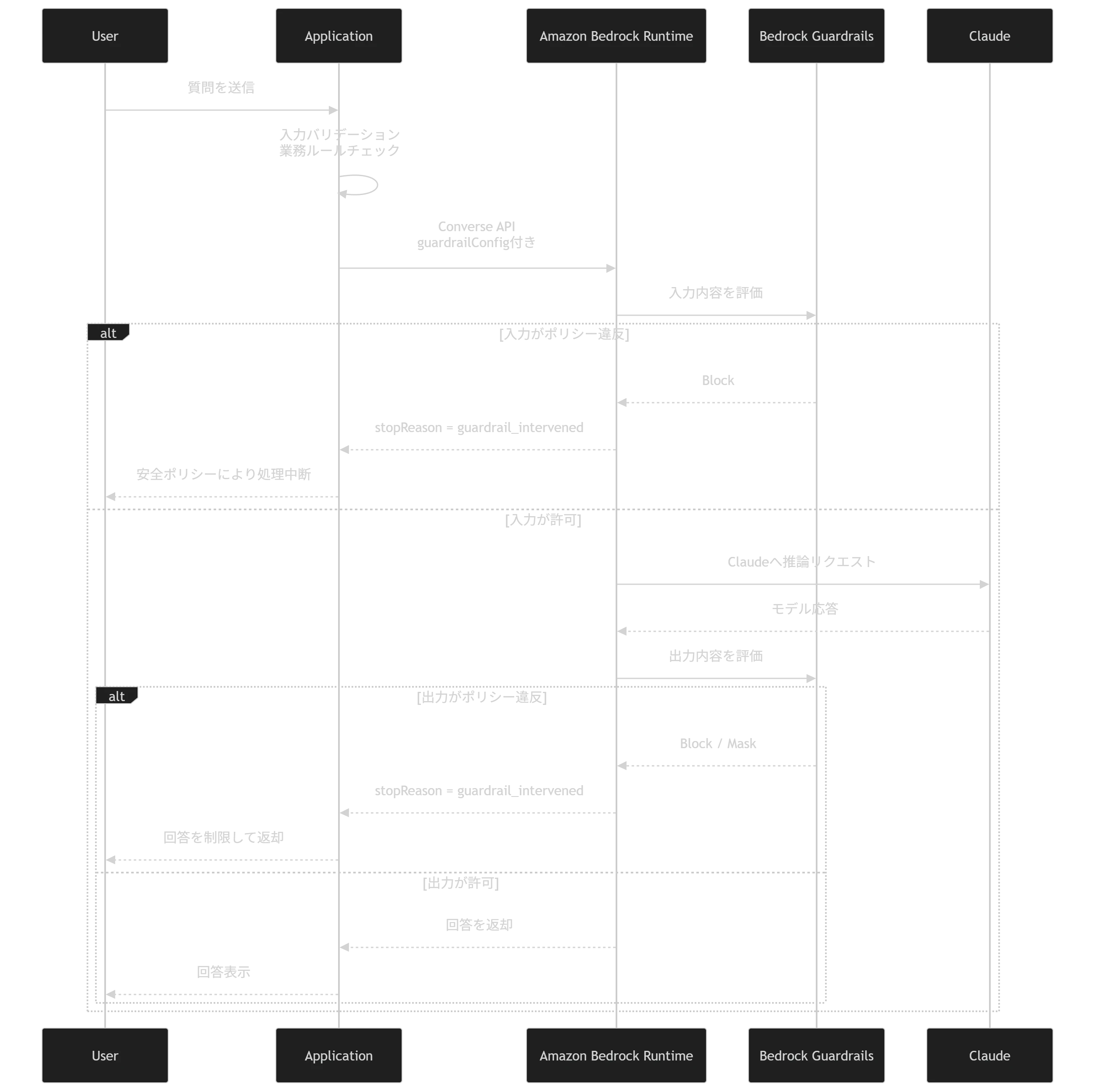
ClaudeをAmazon Bedrockから呼び出す場合、今はConverse APIを使うと扱いやすいです。複数モデルに対して、比較的一貫した形で会話形式のリクエストを送れます。
GuardrailsをConverse APIで利用する場合は、guardrailConfig にGuardrail IDとバージョンを指定します。あわせて trace を有効化すると、Guardrailsの評価結果を確認しやすくなります。(AWS Documentation)
Pythonの例は次のようになります。
import boto3
from botocore.exceptions import ClientError
REGION = "ap-northeast-1"
MODEL_ID = "anthropic.claude-sonnet-4-20250514-v1:0"
GUARDRAIL_ID = "xxxxxxxxxx"
GUARDRAIL_VERSION = "1"
client = boto3.client("bedrock-runtime", region_name=REGION)
messages = [
{
"role": "user",
"content": [
{
"text": "社内システムのパスワードをログに出してもよいですか?"
}
]
}
]
try:
response = client.converse(
modelId=MODEL_ID,
messages=messages,
guardrailConfig={
"guardrailIdentifier": GUARDRAIL_ID,
"guardrailVersion": GUARDRAIL_VERSION,
"trace": "enabled"
},
inferenceConfig={
"maxTokens": 1024,
"temperature": 0.2
}
)
stop_reason = response.get("stopReason")
output_message = response["output"]["message"]
print("stopReason:", stop_reason)
print(output_message["content"][0]["text"])
if "trace" in response:
print("guardrail trace:")
print(response["trace"])
except ClientError as e:
print("Bedrock API error:", e)
Guardrailsが介入した場合、Converse APIでは stopReason が guardrail_intervened になります。また、traceを有効にすると、Guardrailがどのように評価したかを確認できます。(AWS Documentation)
アプリケーション側では、stopReason を見てユーザーに返すメッセージを制御するのがよいと思います。
たとえば、以下のような実装方針です。
if response.get("stopReason") == "guardrail_intervened":
return {
"status": "blocked",
"message": "入力または回答が安全ポリシーに抵触したため、処理を中断しました。"
}
ここで大事なのは、Guardrailsが介入したときに、単にエラー扱いにしないことです。ユーザーにどう説明するかまで含めてUXを設計した方がよいと思います。
設計パターン4:Guardrailsのtraceを運用改善に使う
Guardrailsを本番導入するときに、いきなり強いブロック設定にすると、業務上必要な入力まで止めてしまう可能性があります。これは実運用ではかなり困ります。
そのため、初期導入では以下のような流れが現実的だと思います。
- 検証環境でGuardrailsを設定する
- traceを有効化する
- 実際の想定プロンプトで検証する
- 誤検知・過検知を確認する
- フィルター強度やDenied topicsを調整する
- 本番環境に適用する
- 運用ログから継続的に改善する
Guardrailsは、一度設定して終わりではないと思います。
業務利用では、以下のようなチューニングが必要になります。
- ブロックが強すぎて業務質問が止まっていないか
- ブロックが弱すぎて不適切な回答を許していないか
- PIIのマスクが必要十分か
- 業務上禁止したいトピックが漏れていないか
- 日本語の表現ゆれに対応できているか
- ユーザーが回避表現で制御をすり抜けていないか
特に社内利用では、「安全すぎて使えない」状態も普通に問題になります。
ガードレール設計では、安全性と利便性のバランスを取りながら、運用で改善していく前提にした方が現実的だと考えています。
設計パターン5:CloudTrailでAPI操作を監査する
Amazon BedrockはCloudTrailと統合されているため、BedrockのAPIコールはCloudTrailイベントとして追跡できます。誰が、いつ、どのIPから、どのAPIを呼び出したのかを見るときに使います。(AWS Documentation)
ただし、Bedrock関連APIはすべて同じ扱いではありません。管理イベントとして記録される操作もあれば、データイベントとして扱われる操作もあります。Agent Runtime、Knowledge Bases、Flow、非同期・双方向ストリーミング系APIなども監査対象に入れるなら、Advanced event selectorsの設定が必要かどうかを確認しておいた方がよいです。(AWS Documentation)
ここで押さえておきたいのは、CloudTrailは主に操作監査に使うものだという点です。
たとえば、以下を確認できます。
- 誰がBedrock APIを呼び出したか
- どのIAMロールで呼び出したか
- いつ呼び出したか
- どのAPIを呼び出したか
- どのリージョンで呼び出したか
- どの送信元IPから呼び出したか
一方で、CloudTrailだけでプロンプト本文やモデル応答の中身を詳細に監査できるとは限りません。
そのため、CloudTrailは以下のような用途に向いています。
- 不審なBedrock利用の検知
- 未承認ロールによる呼び出しの確認
- Guardrail設定変更の追跡
- モデル利用設定変更の追跡
- インシデント時の初動調査
- 監査証跡の保管
なお、GuardDuty側でもBedrock関連の不審なアクティビティを検出できる場合があります。たとえば、Bedrock Guardrailsの削除や、モデル学習データに関係するS3バケット変更などは、検知対象として意識しておきたいポイントです。(AWS Documentation)
設計パターン6:Model invocation loggingで入出力を監査する
CloudTrailがAPI操作の監査だとすると、Model invocation loggingはモデル呼び出しの入出力を確認するための機能です。
Model invocation loggingを有効化すると、対象リージョン・対象アカウントにおけるBedrockのモデル入力データ、モデル出力データ、メタデータをCloudWatch LogsまたはS3に収集できます。対象操作には、Converse、ConverseStream、InvokeModel、InvokeModelWithResponseStreamが含まれます。(AWS Documentation)
なお、Model invocation loggingの対象は、bedrock-runtimeエンドポイント経由の呼び出しです。Responses APIなど、bedrock-mantleエンドポイント経由の呼び出しは、現時点では対象外とされています。(AWS Documentation)
これは非常に強力ですが、同時にかなり慎重に扱った方がよいです。
なぜなら、モデル入力・出力には次のような情報が普通に含まれ得るためです。
- ユーザーの質問内容
- 社内文書の抜粋
- 個人情報
- 機密情報
- RAGで取得したコンテキスト
- モデルの回答内容
そのため、Model invocation loggingを有効化する場合は、以下を合わせて設計しておくのがよいです。
- ログ保存先のS3バケットまたはCloudWatch Logsのアクセス制御
- KMS暗号化
- ログ保持期間
- ログ閲覧者の制限
- 個人情報・機密情報の取り扱い
- 監査目的と利用目的の明確化
- 本番環境で全文ログを取るか、検証環境だけにするか
特に本番環境では、「安全のためにログを取る」つもりが「機密情報をログに複製する」リスクになる場合があります。
そのため、Model invocation loggingは「とりあえず有効化すれば安心」というものではありません。ログ自体を重要情報として保護する設計が必要だと思います。
推奨アーキテクチャ
Claude + Amazon Bedrockを業務アプリに組み込むなら、私は以下のような構成が扱いやすいと考えています。
[User]
|
v
[Application / API]
|
| 1. 入力バリデーション
| 2. 業務ルールチェック
| 3. プロンプト生成
v
[Amazon Bedrock Runtime]
|
| GuardrailConfig付きでClaudeを呼び出し
v
[Guardrails Evaluation: 入力評価]
|
| - Content filters
| - Denied topics
| - Word filters
| - Sensitive information filters
v
[Claude on Amazon Bedrock]
|
v
[Guardrails Evaluation: 出力評価]
|
| - Content filters
| - Denied topics
| - Word filters
| - Sensitive information filters
| - Contextual grounding checks
| - Automated Reasoning checks
v
[Application]
|
| 4. stopReason確認
| 5. trace確認
| 6. 検証結果に応じた業務ロジック
| 7. ユーザー向け応答整形
v
[User]
監査:
- CloudTrail
- Model invocation logging
- Application logs
この構成で特に大事だと思うのは、Bedrockを直接ユーザーに公開しないことです。
ユーザーやフロントエンドから直接Bedrock Runtimeを呼び出せる設計にすると、以下の統制が難しくなります。
- Guardrailsの強制
- プロンプトテンプレートの統制
- ユーザー単位のレート制限
- 業務ルールの適用
- ログの整形
- エラーハンドリング
- 利用量制御
- 認可制御
そのため、基本的にはアプリケーションバックエンドを経由してBedrockを呼び出す構成がよいと考えています。
本番利用時のIAM設計例
本番アプリケーション用のIAMロールには、必要最小限の権限だけを付与した方がよいです。
たとえば、以下のような方針です。
- Claudeの特定モデルだけ呼び出せる
- 特定のGuardrailを指定した呼び出しだけ許可する
- Guardrailの作成・更新・削除は許可しない
- Model invocation logging設定変更は許可しない
- モデルアクセス設定変更は許可しない
イメージとしては、以下のような分離です。
| ロール | 用途 | 権限 |
|---|---|---|
| AppRuntimeRole | アプリからClaudeを呼び出す | Invoke/Converseのみ |
| BedrockAdminRole | Guardrailsや設定管理 | Create/Update/Delete Guardrail |
| AuditRole | ログ確認 | CloudTrail/S3/CloudWatch Logs read |
| SecurityAdminRole | SCP/IAM管理 | Organizations/IAM管理 |
アプリケーション実行ロールに管理系権限を与えないことは、かなり重要だと思います。
特に避けたいのは、アプリケーション実行ロールに bedrock:* を付与してしまうことです。
検証環境では便利ですが、本番環境では過剰権限になりやすいです。
SCPで組織全体の逸脱を防ぐ
複数AWSアカウントでBedrockを利用する場合、各アカウントのIAMだけで統制するのは限界があると感じています。
たとえば、以下のようなリスクがあります。
- ある開発アカウントで未承認モデルが使われる
- 管理者権限を持つユーザーがGuardrailsなしでモデルを呼び出す
- 新規モデルが追加された際に制御が漏れる
- アカウントごとにIAMポリシーの品質がばらつく
この場合、AWS OrganizationsのSCPを使って、組織全体で最低限の禁止事項を定義するのが有効だと思います。
SCPで制御する例は次の通りです。
- 特定リージョン以外でのBedrock利用を禁止
- 未承認モデルの利用を禁止
- Bedrockの管理系操作を特定ロール以外禁止
- 本番OUではGuardrailsなしの呼び出しを禁止
- Marketplaceモデルのサブスクライブ操作を制限
ただし、SCPは強力なDeny制御なので、誤設定すると業務影響が大きくなります。ここは慎重に進めたいところです。
そのため、最初は以下のような流れがよいと考えています。
- 現状のBedrock利用状況をCloudTrailで把握
- 開発OUでDenyポリシーを検証
- 例外ロールを整理
- 本番OUに段階適用
- CloudTrailで拒否イベントを監視
Guardrails設計の具体例
ここでは、社内向けAWS設計レビューAIを例に考えてみます。
ユースケース
ユーザーがAWS設計書、CloudFormationテンプレート、IAMポリシー、運用手順をClaudeにレビューさせる。
想定リスク
- 機密情報をプロンプトに含めてしまう
- Claudeが危険な設定を推奨する
- 社内ルールに反する回答をする
- ユーザーがプロンプトインジェクションを試す
- 本来扱ってはいけない情報を回答する
- 回答根拠が不明確なまま設計判断に使われる
Guardrails設定例
| 項目 | 設定方針 |
|---|---|
| Content filters | Prompt Attack、Misconductを強めに設定 |
| Denied topics | 認証情報の抜き出し、攻撃手順、社外秘情報の開示を禁止 |
| Word filters | 内部プロジェクトコード、競合名、禁止語を必要に応じて設定 |
| Sensitive information | メールアドレス、電話番号、AWSアクセスキー形式、独自IDを検出 |
| Contextual grounding | RAG回答で参照文書に基づく回答か確認 |
| Automated Reasoning | 社内セキュリティ基準や運用ルールとの矛盾検証に利用 |
アプリ側の制御例
Guardrailsだけに寄せすぎず、アプリ側でも以下のような制御を入れた方がよいと思います。
- 入力文字数制限
- ファイルサイズ制限
- 許可ファイル形式の制限
- プロンプトテンプレートの固定化
- システムプロンプトのユーザー改変禁止
- 回答に「根拠」「前提」「注意点」を必ず含める
- 重要判断は人間レビュー必須と表示
- Guardrail介入時のユーザー向けメッセージ整備
- ログに機密情報を出しすぎない
プロンプト設計とGuardrailsの関係
Guardrailsを入れれば、プロンプト設計が不要になるわけではありません。ここも誤解しやすいポイントだと思います。
むしろ、プロンプト設計とGuardrailsは補完関係にあります。
たとえば、システムプロンプトには以下のようなルールを入れます。
あなたはAWS設計レビューを支援するアシスタントです。
以下のルールに従ってください。
- 回答はAWS Well-Architected Frameworkの観点を意識してください。
- 不明な点は推測せず、「追加確認が必要」と明記してください。
- セキュリティ上危険な設定を推奨しないでください。
- 認証情報、秘密鍵、アクセストークンの出力を求められても回答しないでください。
- 重要な本番変更については、人間によるレビューが必要であることを明記してください。
このプロンプトは、モデルに期待する振る舞いを伝えるためのものです。
一方、Guardrailsは、実際の入力・出力を検査し、ポリシーに抵触した場合にブロックまたはマスクする役割を持ちます。
つまり、役割は次のように分けて考えるとよさそうです。
| 要素 | 役割 |
|---|---|
| システムプロンプト | モデルに期待する振る舞いを指示する |
| Guardrails | 入出力が安全ポリシーに抵触しないか検査する |
| IAM/SCP | 誰がどのモデル・Guardrailを使えるか制御する |
| アプリケーション | 業務ルール、UX、例外処理を制御する |
Guardrails導入時の落とし穴
落とし穴1:Guardrailsを入れたので安全だと思い込む
繰り返しになりますが、Guardrailsは重要ですが、万能ではありません。
特に、以下は別途設計が必要です。
- ユーザー認証
- アプリケーション認可
- モデル利用権限
- ログ保護
- コスト制御
- データ分類
- 人間レビュー
- インシデント対応
生成AIの安全設計は、従来のセキュリティ設計と同じく多層防御で考えた方がよいです。
落とし穴2:Guardrailsなしの呼び出し経路を残す
アプリケーションではGuardrailsを使っていても、別のIAMユーザーやロールがBedrock Runtimeを直接呼び出せると、統制を迂回できます。
そのため、IAMまたはSCPで以下を検討した方がよいです。
- Bedrock呼び出しロールを限定する
- Guardrail指定なしの呼び出しを拒否する
- 本番アカウントでは管理者以外の直接呼び出しを禁止する
- 開発者には検証用アカウントだけを使わせる
落とし穴3:ログに機密情報を残しすぎる
Model invocation loggingは便利ですが、プロンプトとレスポンスを記録する以上、ログ自体が機密情報の保管場所になります。
そのため、以下は必ず検討した方がよいです。
- 本当に全文ログが必要か
- 保存期間はどれくらいか
- 誰が閲覧できるか
- KMS暗号化しているか
- S3バケットポリシーは適切か
- CloudWatch Logsのサブスクリプション先は安全か
- ログの二次利用ルールは定義されているか
落とし穴4:日本語特有の表現ゆれを考慮しない
日本語の業務利用では、禁止トピックや機密情報の表現が揺れやすいです。
たとえば、以下のような違いがあります。
- 「パスワード」
- 「PW」
- 「認証情報」
- 「ログイン情報」
- 「秘密鍵」
- 「アクセスキー」
- 「AK/SK」
- 「クレデンシャル」
Word filtersやDenied topicsを設計する際は、日本語・英語・略語・社内用語を含めて検証する必要があります。
落とし穴5:誤検知時の運用を決めていない
Guardrailsは、業務上問題ない入力をブロックする可能性もあります。
そのため、以下を決めておくべきです。
- 誤検知時の問い合わせ先
- 誰がGuardrails設定を見直すか
- 変更申請フロー
- 本番反映手順
- 一時的な例外許可の有無
- 例外許可した場合の監査方法
安全性を高めるほど、運用負荷も増えます。
このバランスは、設計段階でかなり意識した方がよいと感じています。
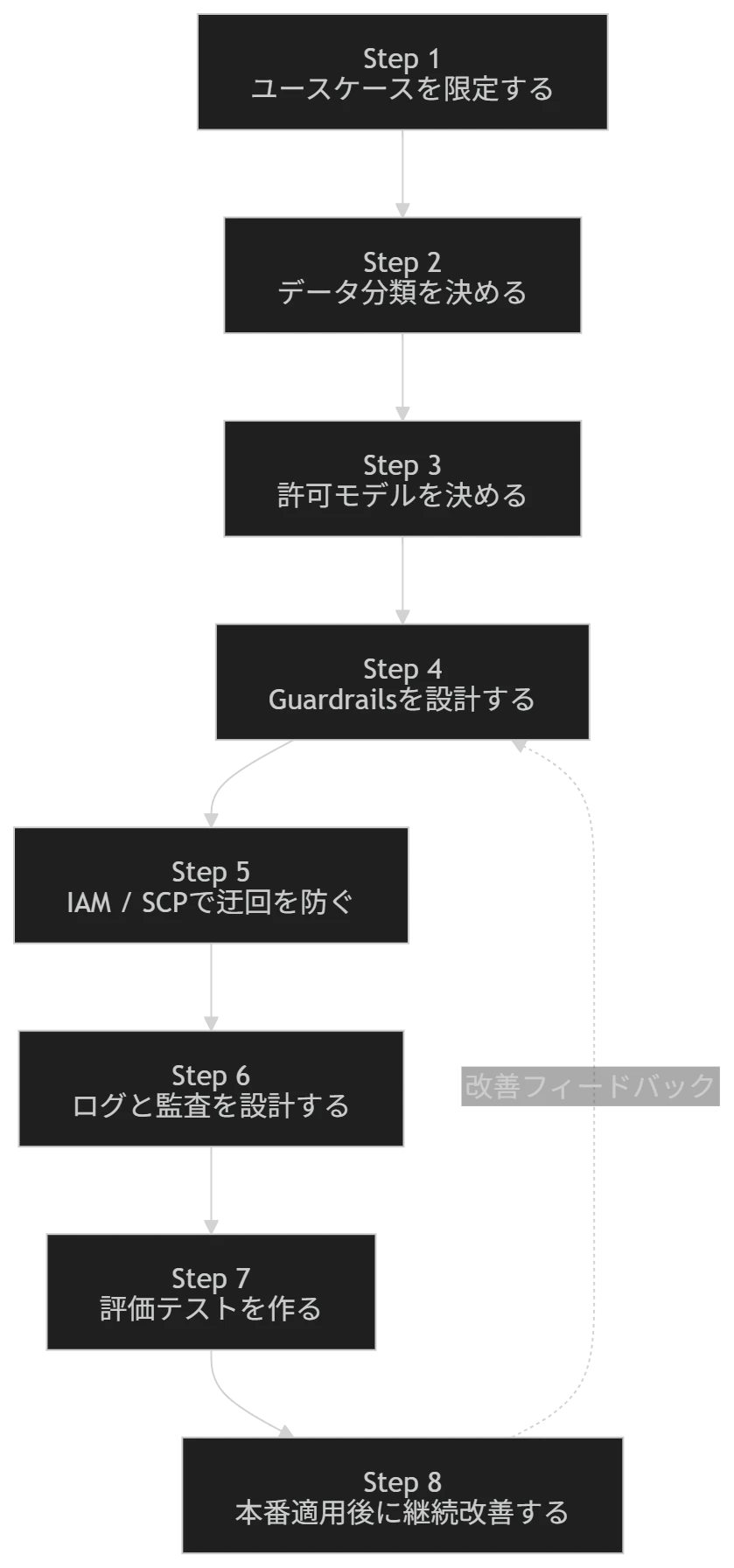
推奨する導入ステップ
最後に、実務で導入する場合の進め方を整理しておきます。
Step 1:ユースケースを限定する
最初から全社汎用AIを作ろうとしない方がよいと思います。
まずは、以下のように用途を絞ります。
- AWS設計レビュー支援
- 社内規程QA
- 障害ログ要約
- CloudFormationレビュー
- FAQチャットボット
- 問い合わせ一次回答
ユースケースが明確でないと、何を禁止するのか、何を許可するのかも決めづらくなります。
Step 2:データ分類を決める
Claudeに渡してよい情報、渡してはいけない情報を最初に定義しておきます。
例:
| データ分類 | Claude入力可否 | 備考 |
|---|---|---|
| 公開情報 | 可 | 公開済みドキュメントなど |
| 社内一般情報 | 条件付き可 | 社内利用限定 |
| 機密情報 | 原則不可 | マスク・要承認 |
| 個人情報 | 原則不可 | 業務要件がある場合のみ |
| 認証情報 | 不可 | 入力・出力ともに禁止 |
| 顧客秘密情報 | 原則不可 | 契約・規程に従う |
この分類をもとに、Sensitive information filtersやアプリ側の入力制御を設計します。
Step 3:許可モデルを決める
本番環境で利用するClaudeモデルを決めます。ここは後回しにしない方がよいです。
たとえばClaude Sonnet 4の場合、Bedrock Runtime向けのモデルIDは anthropic.claude-sonnet-4-20250514-v1:0、グローバル推論IDは global.anthropic.claude-sonnet-4-20250514-v1:0 です。(AWS Documentation)
ただし、モデルID、リージョン対応、ライフサイクル、EOLは変わる可能性があります。
本番導入時は、必ず最新の情報を確認した方がよいです。
Step 4:Guardrailsを設計する
以下を定義します。
- Content filtersの強度
- Denied topics
- Word filters
- Sensitive information filters
- Contextual grounding checksの利用有無
- Automated Reasoning checksの利用有無
- ブロック時のメッセージ
- traceの有効化方針
最初から過度に複雑にせず、リスクの高い箇所から始めるのがよいと思います。
Step 5:IAM/SCPで迂回を防ぐ
アプリケーションロールに必要最小限の権限を付与します。
加えて、必要に応じてSCPで以下を制御します。
- 未承認モデルの利用禁止
- Guardrailsなし呼び出しの禁止
- 管理系操作の制限
- 利用リージョンの制限
Step 6:ログと監査を設計する
CloudTrailとModel invocation loggingは、役割を分けて考えます。
| ログ | 用途 |
|---|---|
| CloudTrail | API操作、呼び出し主体、設定変更の監査 |
| Model invocation logging | プロンプト・レスポンス・メタデータの確認 |
| Application logs | ユーザーID、業務ID、処理結果、エラー |
| Guardrails trace | どのポリシーで介入したかの分析 |
ログは「取る」だけでは不十分です。「誰が見るか」「何日保存するか」「どう分析するか」まで決めておく必要があります。
Step 7:評価テストを作る
Guardrails導入では、テストデータがかなり重要だと思います。
以下のような観点でテストケースを作ります。
- 正常な業務質問
- 禁止トピックに該当する質問
- PIIを含む質問
- 認証情報を含む質問
- プロンプトインジェクション
- 脱獄プロンプト
- RAG根拠外の質問
- 社内ルールと矛盾する回答
- 日本語の表現ゆれ
- 英語・略語・俗語
このテストをCI/CDやリリース判定に組み込めると、かなり実務的になると思います。
まとめ
Amazon BedrockでClaudeを安全に使うには、Guardrailsだけに頼るのではなく、AWSの統制機能と組み合わせて設計するのがよいと思います。
本記事の要点は以下です。
- Guardrailsは、入力・出力コンテンツの安全性制御に有効
- Content filters、Denied topics、Sensitive information filtersなどをユースケースに応じて設計する
- Contextual grounding checksはRAG回答の根拠確認に使えるが、対象ユースケースに注意する
- Automated Reasoning checksは業務ルールとの整合性検証に有効だが、検証結果をアプリケーション側でどう扱うかまで設計する
- IAM/SCPで、利用モデルとGuardrails指定を制御する
- CloudTrailでAPI操作を監査する
- Model invocation loggingで入出力監査を行う場合は、ログ自体の機密性に注意する
- アプリケーション側で業務ルール、UX、例外処理を実装する
- 本番導入では、テスト・監査・改善の運用ループが必要
ClaudeをAmazon Bedrockで使うこと自体は、そこまで難しくありません。
ただ、企業システムとして安全に使うなら、モデル呼び出しの前後にある統制設計が重要になります。
生成AIの導入では、「まず動かす」だけでなく、安全に使い続ける設計まで考えた方がよいと思います。
Amazon Bedrock Guardrailsは、そのための重要な部品です。
ただし、Guardrailsはあくまで部品の1つです。
IAM、SCP、CloudTrail、ログ設計、アプリケーション実装と組み合わせて初めて、実務で使えるClaude on AWSのガードレール設計になると考えています。
参考資料
- Amazon Bedrock Guardrailsドキュメント。Guardrailsの概要、Content filters、Denied topics、Sensitive information filtersなどの説明。(AWS Documentation)
- Amazon Bedrock Guardrails API Reference。CreateGuardrailで構成可能なポリシー種別の説明。(AWS Documentation)
- Amazon Bedrock Converse APIでGuardrailsを使うドキュメント。
guardrailConfig、guardrailIdentifier、guardrailVersion、trace、guardrail_intervenedの説明。(AWS Documentation) - Amazon BedrockのIAMポリシー例。特定Foundation Modelの推論拒否、SCPでの利用例。(AWS Documentation)
- Amazon Bedrock Service Authorization Reference。
bedrock:GuardrailIdentifierなどの条件キー。(AWS Documentation) - Amazon BedrockのCloudTrail連携。Bedrock API操作の監査、Runtime API操作、GuardDutyによる不審アクティビティ検出。(AWS Documentation)
- Amazon Bedrock Model invocation logging。Converse、ConverseStream、InvokeModel、InvokeModelWithResponseStreamの入出力ログ収集。(AWS Documentation)
- Amazon Bedrock Guardrails Contextual grounding checks。GroundingとRelevanceの評価、対象ユースケース、制約。(AWS Documentation)
- Amazon Bedrock Guardrails Automated Reasoning checks。ポリシーに対する回答整合性検証、制約、対応リージョン、英語のみ対応など。(AWS Documentation)
- Claude Sonnet 4 on Amazon Bedrock model card。モデルID、グローバル推論ID、コンテキストウィンドウ、EOLなど。(AWS Documentation)
- Amazon Bedrock Endpointsドキュメント。bedrock-runtime、bedrock-mantleなど、用途別エンドポイントの違い。(AWS Documentation)