はじめに
この記事では、Logstashを用いてMySQLのデータをElasticsearchに流すときにNested fieldにデータ入れる方法の紹介になります。
LogstashのJdbc input pluginを使うだけでは、NestedデータをElasticsearchに送ることはできません。そこで、Ruby filterを利用して同期する方法のサンプルになります。サンプルとなるMappingは、ユーザに対してn個の学校データを持つような構造となってます。詳しいMapping定義は、Logstashの設定を参照
準備
- Dockerの環境構築
- mysql jdbc-connectorの用意
環境構築
はじめにマウントしていく設定などを作成していきます。このサンプルでは、以下のような構造で設定していきます。
./
├── coordination
│ ├── config
│ │ ├── logstash.yml
│ │ └── pipeline.yml
│ ├── mysql-connector-java-8.0.21.jar
│ ├── pipeline
│ │ ├── nested_data_pipeline.conf
│ │ └── pipeline.conf
│ ├── template
│ │ └── index-template.json
│ └── sql
│ ├── statement_education_background.sql
│ └── statement_user.sql
├── docker-compose.yaml
└── mysql
└── init
├── 1_ddl.sql
├── 2_data.sh
├── education_background_data.csv
└── user_data.csv
MySQLの設定
コンテナ起動時に、Elasticsearchに流すための初期データをMySQLに流す必要があります。dockerのmysqlは、docker-entrypoint-initdb.dディレクトリにddlやshellを配置すると起動時に実行してデータの流し込みができます。そのため、docker-entrypoint-initdb.dにddlとshell、csv(初期データ)を配置していきます。数値_{ファイル名}のようなファイル名にすると数値順で実行していくれます。
./mysql/init に以下のファイルを作成していきます。
CREATE DATABASE IF NOT EXISTS `datas`;
USE `datas`;
DROP TABLE IF EXISTS `user`;
CREATE TABLE `user`
(
`user_id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(64) DEFAULT NULL,
`gender_cd` enum ('M','F') DEFAULT NULL,
`birthday` date DEFAULT NULL,
`insert_tm` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`update_tm` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`user_id`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4 COMMENT ='user data';
DROP TABLE IF EXISTS `education_background`;
CREATE TABLE `education_background`
(
`education_background_id` bigint(20) NOT NULL AUTO_INCREMENT,
`user_id` bigint(20) NOT NULL,
`school_name` varchar(128) NOT NULL,
`school_type` varchar(20) NOT NULL,
`graduation_year` date DEFAULT NULL,
`drop_flg` tinyint(1) NOT NULL DEFAULT '0',
`insert_tm` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`update_tm` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`education_background_id`),
CONSTRAINT `fk_user_id`
FOREIGN KEY (`user_id`) REFERENCES `user` (`user_id`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4 COMMENT ='education background';
# !/bin/bash
mysql -uroot -proot --local-infile datas -e \
"LOAD DATA LOCAL INFILE '/docker-entrypoint-initdb.d/user_data.csv'
INTO TABLE user
FIELDS TERMINATED BY ','
ENCLOSED BY '\"'
LINES TERMINATED BY '\n'"
mysql -uroot -proot --local-infile datas -e \
"LOAD DATA LOCAL INFILE '/docker-entrypoint-initdb.d/education_background_data.csv'
INTO TABLE education_background
FIELDS TERMINATED BY ','
ENCLOSED BY '\"'
LINES TERMINATED BY '\n'"
1,hoge,M,1970-01-01,1970-01-01,1970-01-01
2,foo,M,1980-01-01,1970-01-01,1970-01-01
3,baz,F,1990-01-01,1970-01-01,1970-01-01
4,huga,F,2000-01-01,1970-01-01,1970-01-01
5,john smith,M,2010-01-01,1970-01-01,1970-01-01
1,1,xxx,high school,1990-01-01,0,1970-01-01,1970-01-01
2,1,xxx,college,1990-01-01,0,1970-01-01,1970-01-01
3,1,ooo,graduate college,1990-01-01,0,1970-01-01,1970-01-01
4,2,ooo,high school,1990-01-01,0,1970-01-01,1970-01-01
5,2,ooo,college,1990-01-01,0,1970-01-01,1970-01-01
6,2,ooo,graduate college,1990-01-01,0,1970-01-01,1970-01-01
7,3,aaa,high school,1990-01-01,0,1970-01-01,1970-01-01
8,3,bbb,college,1990-01-01,0,1970-01-01,1970-01-01
9,4,bbb,high school,1990-01-01,0,1970-01-01,1970-01-01
10,5,111,high school,1990-01-01,0,1970-01-01,1970-01-01
11,5,222,college,1990-01-01,0,1970-01-01,1970-01-01
12,5,333,graduate college,1990-01-01,0,1970-01-01,1970-01-01
Logstashの設定
Jdbc input pluginでデータを取りに行くため、jdbc-connectorが必要です。また、outputでElasticsearchに流し込むとき初回はindexが存在しません。そのため、output時にindex templateを作成してMappingなどを定義していきます。
Logstashのoutput先はuser indexとしています。
はじめにcoordination/template/にtemplateを作成していきます。schoolをnestedにして構造を持てるようにしています。
{
"index_patterns": [
"user"
],
"settings": {
"number_of_shards": 1
},
"mappings": {
"properties": {
"user_id": {
"type": "long"
},
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"gender_cd": {
"type": "keyword"
},
"birth_date": {
"type": "date"
},
"school": {
"type": "nested",
"properties": {
"school_name": {
"type": "text"
},
"school_type": {
"type": "keyword"
},
"graduation_year": {
"type": "date"
},
"drop_flg": {
"type": "long"
}
}
}
}
},
"version": 1
}
次にパイプラインを作成していきます。outputでは、templateを指定してindex定義をさせるようにしています。
input {
jdbc {
id => "statement_user"
jdbc_driver_library => "/usr/share/logstash/mysql-connector-java-8.0.21.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "${RDS_READ_ENDPOINT}${RDS_DBNAME}?useSSL=false"
jdbc_user => "${RDS_DBUSER}"
jdbc_password => "${RDS_PASSWORD}"
statement_filepath => "/usr/share/logstash/sql/statement_user.sql"
jdbc_default_timezone => "Asia/Tokyo"
}
}
output {
elasticsearch {
hosts => "${ES_ENDPOINT}"
index => "${ES_INDEX}"
action => "update"
doc_as_upsert => true
document_id => "%{user_id}"
template => "/usr/share/logstash/template/index-template.json"
template_name => "user_template"
template_overwrite => true
}
}
このパイプラインでは、schoolを除くデータを流し込むものです。
schoolに流し込むパイプラインは、別で定義します。
input {
jdbc {
id => "statement_education_background"
jdbc_driver_library => "/usr/share/logstash/mysql-connector-java-8.0.21.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "${RDS_READ_ENDPOINT}${RDS_DBNAME}?useSSL=false"
jdbc_user => "${RDS_DBUSER}"
jdbc_password => "${RDS_PASSWORD}"
statement_filepath => "/usr/share/logstash/sql/statement_education_background.sql"
jdbc_default_timezone => "Asia/Tokyo"
}
}
filter {
ruby {
code => "event.set('school', JSON.parse(event.get('school').to_s))"
}
}
output {
elasticsearch {
hosts => "${ES_ENDPOINT}"
index => "${ES_INDEX}"
action => "update"
doc_as_upsert => true
document_id => "%{user_id}"
template => "/usr/share/logstash/template/index-template.json"
template_name => "user_template"
template_overwrite => true
}
}
nested_data_pipeline.confパイプラインのfilterでMySQLのデータをJSONパースしています。このfilterがないと、JSONを文字列として、Elasticsearchに同期されてしまいます。
filter {
ruby {
code => "event.set('school', JSON.parse(event.get('school').to_s))"
}
}
次にパイプラインが読み込むSQLの作成です。
SELECT user_id,
name,
gender_cd,
birthday
FROM user
ORDER BY user_id
select user_id,
concat('[', group_concat(
json_object('school_name', school_name,
'school_type', school_type,
'graduation_year', graduation_year,
'drop_flg', drop_flg)
), ']') as school
from education_background
group by user_id
学校データは、json_object、group_concatを用いてJSONの配列を作成しています。
最後にconfigです。
logstash.ymlに関しては、適当です。このサンプルの場合、あまり意味はないですがpersistedにしてます。
path.data: /usr/share/logstash/queue/data
queue.type: persisted
path.logs: /var/log/logstash
queue.max_bytes: 1024mb
queue.checkpoint.writes: 8192
queue.page_capacity: 64mb
queue.max_events: 0
log.level: info
log.format: json
slowlog.threshold.warn: 1s
slowlog.threshold.info: 100ms
slowlog.threshold.debug: 100ms
slowlog.threshold.trace: 100ms
このサンプルは、マルチパイプラインのため、2つパイプラインを設定します。
- pipeline.id: rds-es
path.config: "/usr/share/logstash/pipeline/pipeline.conf"
pipeline.workers: 1
pipeline.batch.size: 1024
- pipeline.id: json-rds-es
path.config: "/usr/share/logstash/pipeline/nested_data_pipeline.conf"
pipeline.workers: 1
pipeline.batch.size: 1024
docker-composeの設定
version: '3'
services:
mysql:
image: mysql:5.7
container_name: mysql
volumes:
- ./mysql/init:/docker-entrypoint-initdb.d
ports:
- 3400:3306
environment:
MYSQL_DATABASE: datas
MYSQL_USER: user
MYSQL_ALLOW_EMPTY_PASSWORD: 1
MYSQL_PASSWORD:
MYSQL_ROOT_PASSWORD: root
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:7.7.0
container_name: elasticsearch
ports:
- 9209:9200
environment:
- discovery.type=single-node
- ES_JAVA_OPTS=-Xms400m -Xmx400m
kibana:
image: docker.elastic.co/kibana/kibana:7.7.0
container_name: kibana
environment:
ELASTICSEARCH_HOSTS: http://elasticsearch:9200
ports:
- 5609:5601
depends_on:
- elasticsearch
logstash:
image: docker.elastic.co/logstash/logstash:7.7.0
container_name: logstash
volumes:
- ./coordination/pipeline:/usr/share/logstash/pipeline
- ./coordination/persisted:/usr/share/logstash/persisted
- ./coordination/template:/usr/share/logstash/template
- ./coordination/sql:/usr/share/logstash/sql
- ./coordination/mysql-connector-java-8.0.21.jar:/usr/share/logstash/mysql-connector-java-8.0.21.jar
environment:
- CLEAN_RUN=true
- RDS_READ_ENDPOINT=jdbc:mysql://mysql:3306/
- RDS_DBNAME=datas
- RDS_DBUSER=root
- RDS_PASSWORD=root
- ES_ENDPOINT=http://elasticsearch:9200
- ES_INDEX=user
depends_on:
- elasticsearch
- mysql
データ同期と確認
環境構築後に、docker-compose up -dをしてください。コンテナ起動後、http://localhost:5609/にアクセスし、データを確認します。
以下のようなデータが格納されているはずです。
{
"_index": "user",
"_type": "_doc",
"_id": "1",
"_score": 1.0,
"_source": {
"@timestamp": "2020-08-30T23:43:40.908Z",
"school": [
{
"graduation_year": "1990-01-01",
"drop_flg": 0,
"school_type": "high school",
"school_name": "xxx"
},
{
"graduation_year": "1990-01-01",
"drop_flg": 0,
"school_type": "college",
"school_name": "xxx"
},
{
"graduation_year": "1990-01-01",
"drop_flg": 0,
"school_type": "graduate college",
"school_name": "ooo"
}
],
"@version": "1",
"user_id": 1,
"birthday": "1970-01-01T00:00:00.000Z",
"name": "hoge",
"gender_cd": "M"
}
}
以下のクエリを実行してみます。
GET user/_search
{
"query": {
"nested": {
"path": "school",
"query": {
"bool": {
"must": [
{
"match": {
"school.school_name": "ooo"
}
}
]
}
}
}
}
}
サンプルデータで、school_nameがoooになっているユーザは2つあります。nested queryで検索ができているので、正しく同期されました。
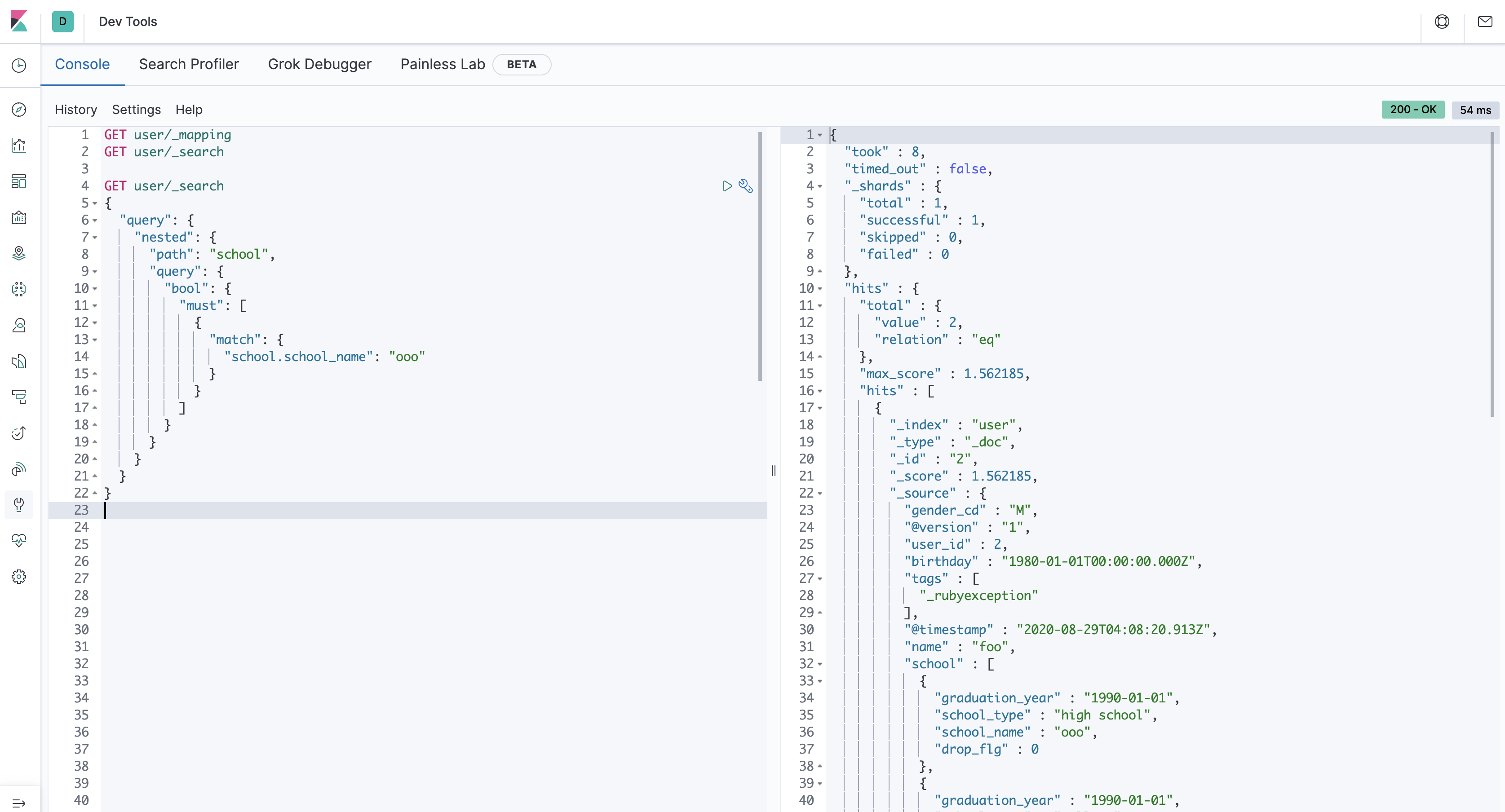
{
"took" : 9,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.290984,
"hits" : [
{
"_index" : "user",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.290984,
"_source" : {
"@timestamp" : "2020-08-30T23:43:40.923Z",
"tags" : [
"_rubyexception"
],
"user_id" : 2,
"birthday" : "1980-01-01T00:00:00.000Z",
"@version" : "1",
"gender_cd" : "M",
"name" : "foo",
"school" : [
{
"graduation_year" : "1990-01-01",
"school_type" : "high school",
"school_name" : "ooo",
"drop_flg" : 0
},
{
"graduation_year" : "1990-01-01",
"school_type" : "college",
"school_name" : "ooo",
"drop_flg" : 0
},
{
"graduation_year" : "1990-01-01",
"school_type" : "graduate college",
"school_name" : "ooo",
"drop_flg" : 0
}
]
}
},
{
"_index" : "user",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.290984,
"_source" : {
"@timestamp" : "2020-08-30T23:43:40.908Z",
"school" : [
{
"graduation_year" : "1990-01-01",
"drop_flg" : 0,
"school_type" : "high school",
"school_name" : "xxx"
},
{
"graduation_year" : "1990-01-01",
"drop_flg" : 0,
"school_type" : "college",
"school_name" : "xxx"
},
{
"graduation_year" : "1990-01-01",
"drop_flg" : 0,
"school_type" : "graduate college",
"school_name" : "ooo"
}
],
"@version" : "1",
"user_id" : 1,
"birthday" : "1970-01-01T00:00:00.000Z",
"name" : "hoge",
"gender_cd" : "M",
"tags" : [
"_rubyexception"
]
}
}
]
}
}