■初めに
クエリにほとんど触った事がなかったので、同じように初学者の方の役に立てばと思いつつ書いてみます。
ちなみに以下のサイトを参考に進めていましたが、ほぼ経験がなく上手くいかなかった部分があったのでもう少し噛み砕いてやってみたという雰囲気です。
参考URL
https://dev.classmethod.jp/articles/cloudtrail-audit-report-by-amazon-athena/
https://dev.classmethod.jp/articles/get_s3data_by_athena/
■準備するもの
・CloudTrailのログがS3に出力されるようにしておく
・クエリ結果を保存するS3の準備
■手順
1.まずはAWSコンソールから「Athena」のサービスページへ移行
Amazon Athena
https://ap-northeast-1.console.aws.amazon.com/athena/home?region=ap-northeast-1
2.クエリエディタを起動
特に何もいじってません
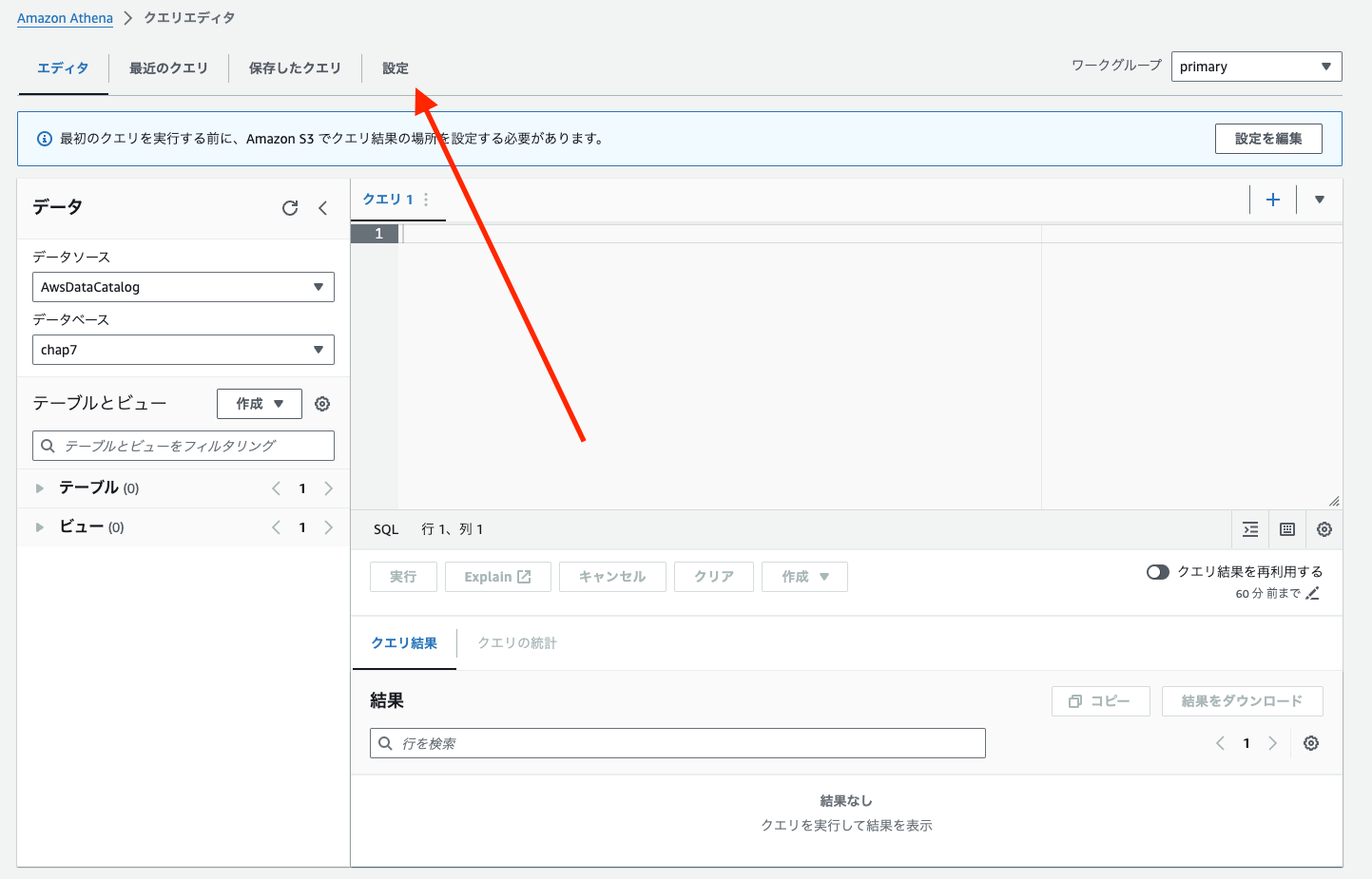
3.まずはクエリ結果の保存先S3バケットを設定しておきましょう
上部「設定」より指定できます
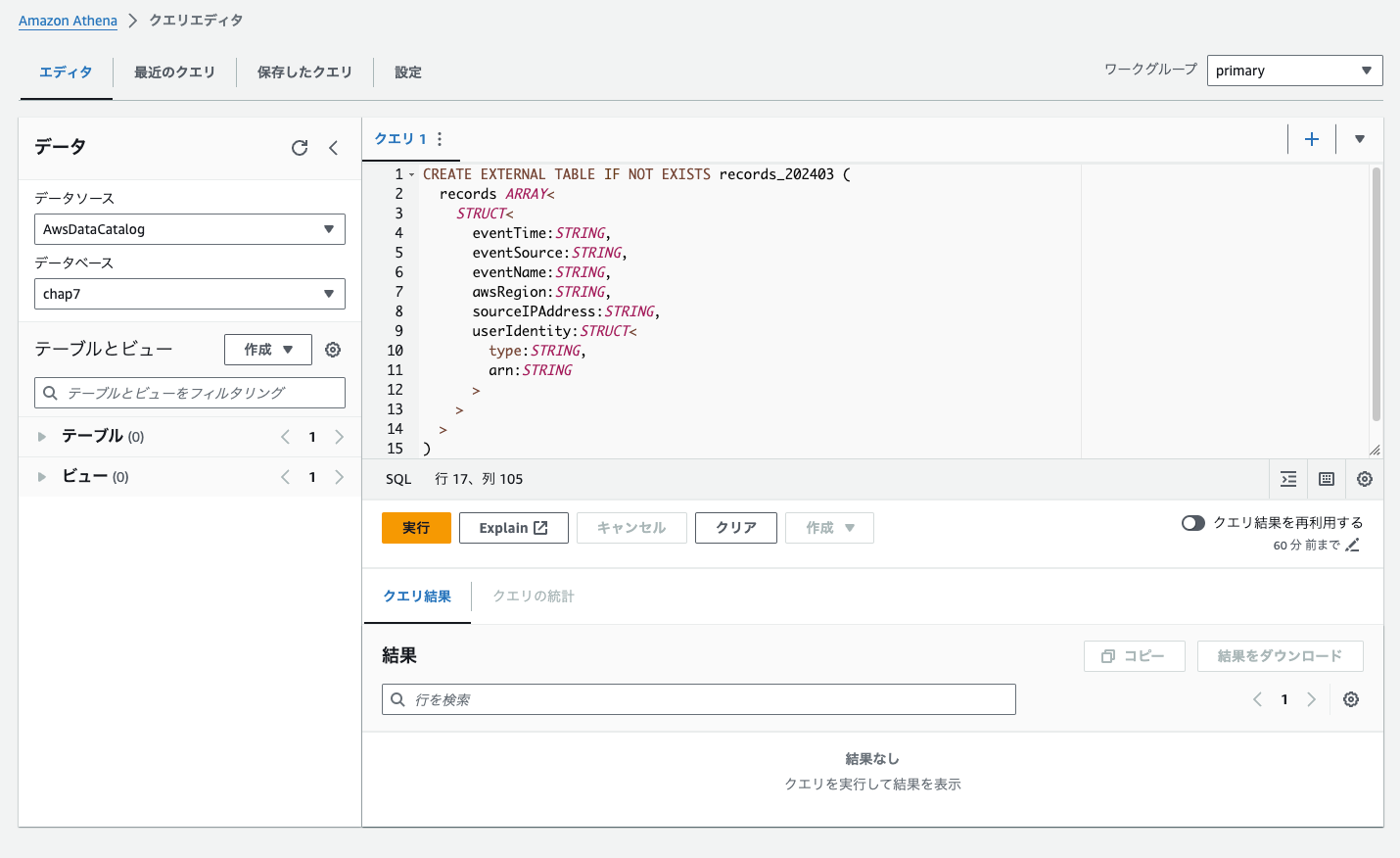
4.Athena内でテーブルの作成
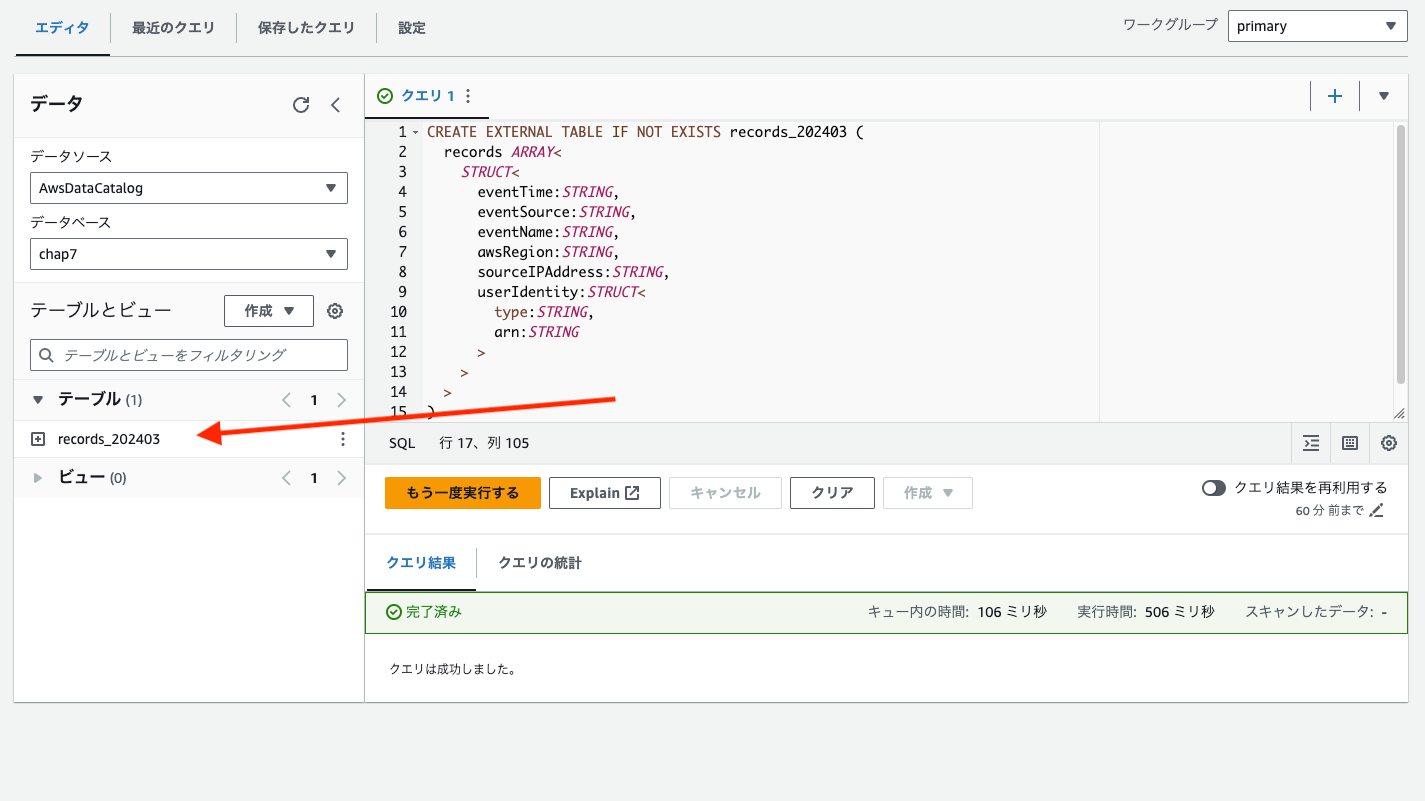
まずはテーブルの作成です。以下を実行します。
1行目終わりの「records_202403」がテーブルの名前になるので任意で変更が必要なのと、
最終行でS3のディレクトリ(CloudTrailログの方)を指定する必要があります
CREATE EXTERNAL TABLE IF NOT EXISTS records_202403 (
records ARRAY<
STRUCT<
eventTime:STRING,
eventSource:STRING,
eventName:STRING,
awsRegion:STRING,
sourceIPAddress:STRING,
userIdentity:STRUCT<
type:STRING,
arn:STRING
>
>
>
)
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
LOCATION 's3://[CloudTrailログ出力バケット名]/[prefix指定があれば]/AWSLogs/[AWSアカウントID]/CloudTrail/[Region]/2024/03';
実行前
実行
作成されました!
5.とりあえず表示してみる
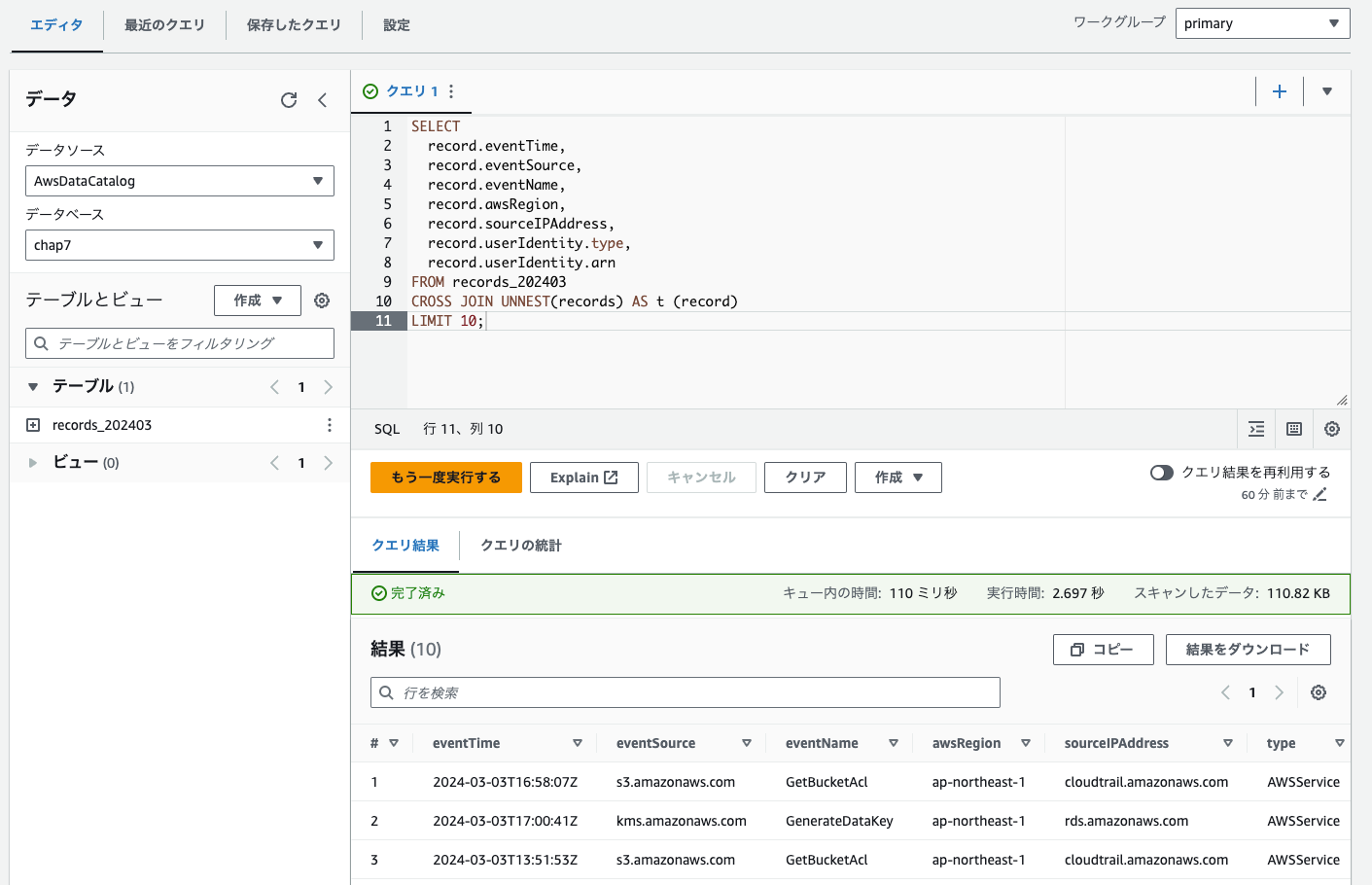
以下を実行してみましょう。
SELECT以下に書いてある項目が表示されるかと思います。
FROMは作成したテーブル名です!
LIMITの部分の数字を変更すれば表示数を増減できます。
SELECT
record.eventTime,
record.eventSource,
record.eventName,
record.awsRegion,
record.sourceIPAddress,
record.userIdentity.type,
record.userIdentity.arn
FROM records_202403
CROSS JOIN UNNEST(records) AS t (record)
LIMIT 10;
6.必要な項目をフィルタリング
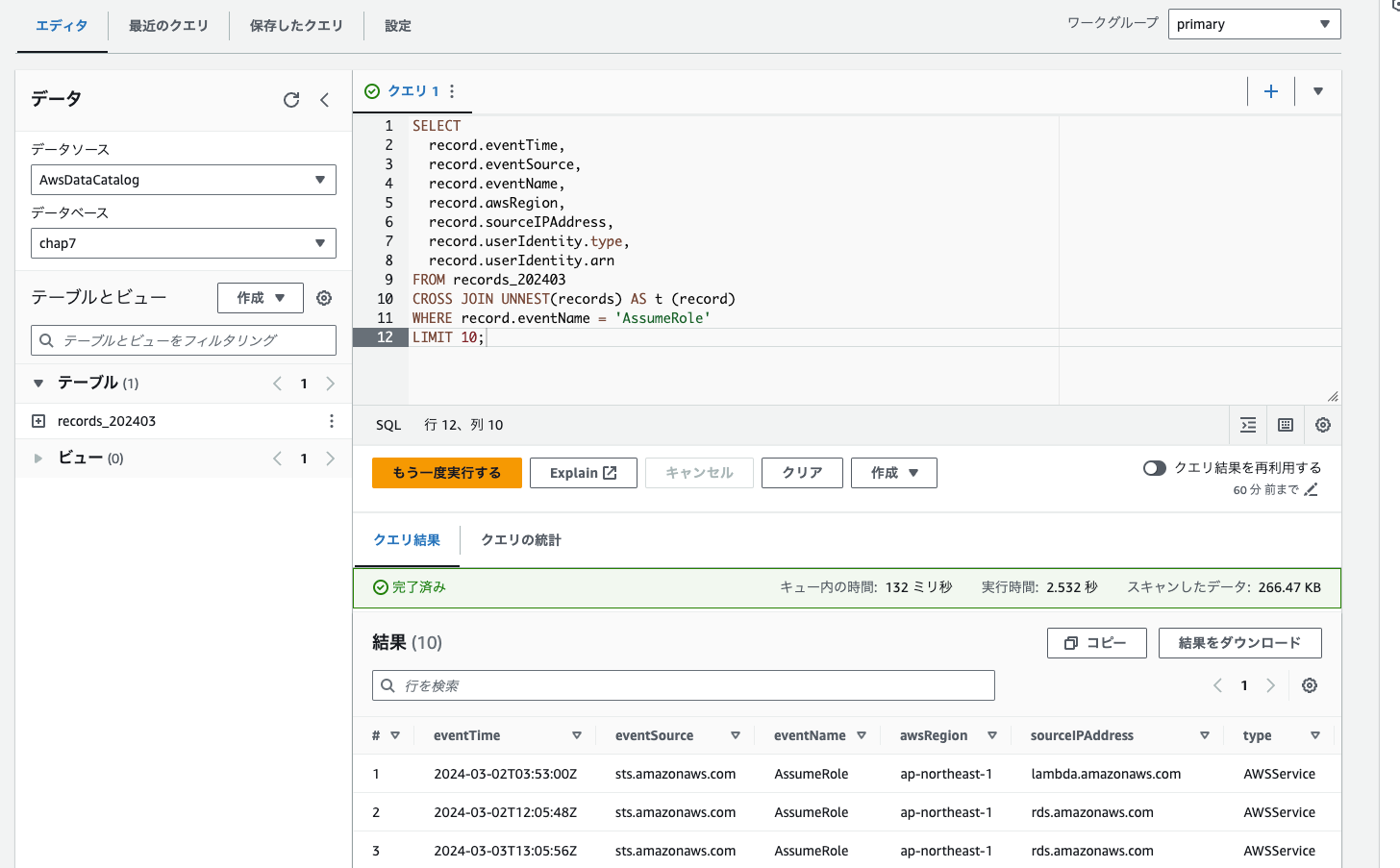
次は「WHERE」で必要なものをフィルタリングします
ここでは「eventName」から目についた「AssumeRole」を指定してみました。
SELECT
record.eventTime,
record.eventSource,
record.eventName,
record.awsRegion,
record.sourceIPAddress,
record.userIdentity.type,
record.userIdentity.arn
FROM records_202403
CROSS JOIN UNNEST(records) AS t (record)
WHERE record.eventName = 'AssumeRole'
LIMIT 10;
指定した10件分が出ました!
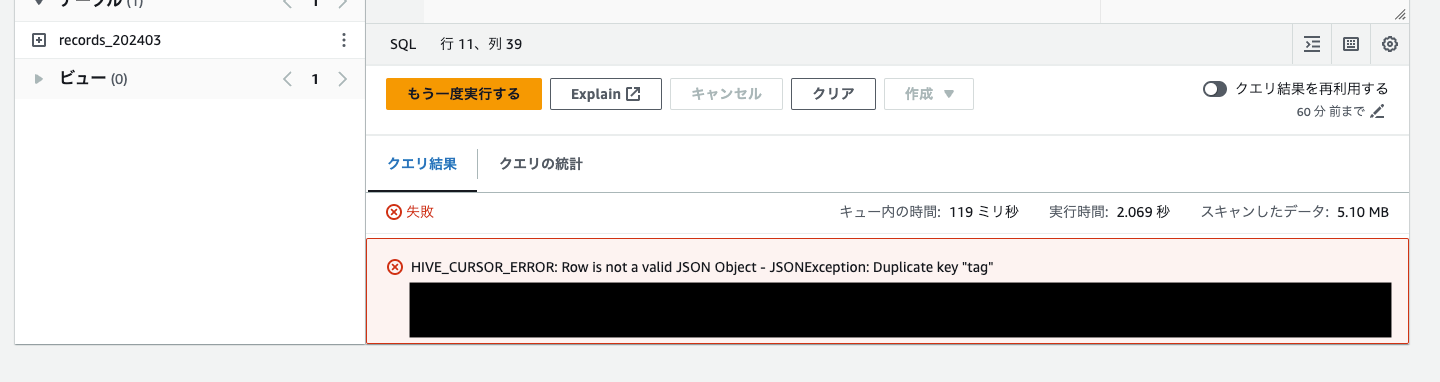
ちなみに参考記事にある「ConsoleLogin」でフィルタした所、エラーが出たのでそもそも発生していないイベントとかだとエラーを返すのかも…?と思っています。
7.エクスポートする
もうお気づきかと思いますが、クエリを実行すると「結果をダウンロード」項目がでます。
ここからエクスポートするか保存先のS3からエクスポートしてみましょう。
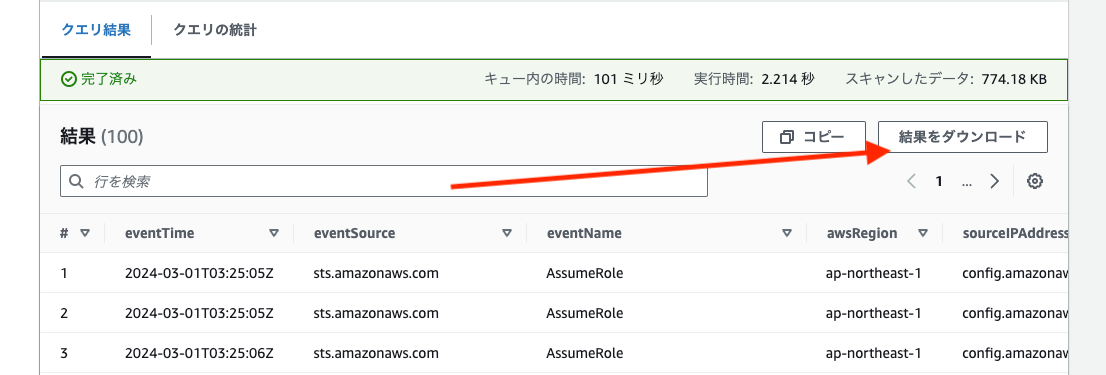
後、繰り返し実行する場合はS3側のライフサイクル等も設定して不要なファイルが溜まらないようにしましょう。
以上です!
(これを書いてから気づきましたがCloudTrail側から簡単に実行できるみたいですね…こっちもやってみようと思います)
