追記情報
- (2020/11/7 18:30) @scivola さんのコメントに基づき、 ラスタースキャン、 ベクタースキャン、 ブラウン管 の説明を追加しました。
TL;DR
PDFについて次のような内容を(私の好奇心の赴くままに)調べたので共有したいと思います。
- 「PostScript」とは?
- 高速ロードの仕組み
- フォント埋め込み
「PDFってどんなファイルなんだろう」
PDFを使ったこと無い人はいないと思います。
それほど、PDFは身近な存在となる一方で、その仕組みについて触れる機会はほとんどないと言っても過言ではないです。
何百ページにも渡る本をPDFで開いた時、ページ移動したときに、パッと表示されたりしますよね。
あれってなんでか知っていますか?
私はもちろん知りませんでした。
たまたま仕事でPDFをあれこれいじるにあたって、仕様がわかってないこともあり、なかなかうまくいかず、途方に暮れていました。
いくつかの記事を読んだりしていると、
「あれ、PDFってどんなファイルなんだろう」
という 謎の好奇心 が湧いてきました。
テキストエディタでPDFを無理やり開いたり、蟻地獄のようにPDFのことを調べていくと、
あれ、案外 PDF 面白いなぁ・・・
などと思うようになりました。
そんなことで、PDFについて記事を書くことにしたわけです。
この記事について
英語版WikipediaをDeepLで適宜翻訳したものに感想やら説明、補足など入れながら説明していくスタイルです。
PDFの技術的特徴を3つほど解説していく記事です。(もちろん本来の特徴はもっとありますが収まらないので渋々3個にしてます)
誤字脱字や、表現が曖昧な点、そもそも内容が大きく異なっている場合があれば、コメント欄などで指摘してくださると幸いです。
PDFってなんぞや?
何はともあれ、PDFをWikipediaで調べてみることから始めてみます。
Portable_Document_Format(en.wikipedia.org)
PDF(Portable Document Format)は、1993年にAdobeによって開発されたファイル形式で、テキストの書式設定や画像を含む文書を、アプリケーションソフトウェア、ハードウェア、オペレーティングシステムに依存しない方法で表示するためのものです。 PostScript言語に基づいて、各PDFファイルは、テキスト、フォント、ベクターグラフィックス、ラスター画像、および表示に必要なその他の情報を含む、固定レイアウトのフラット文書の完全な記述をカプセル化しています。PDFは2008年にISO 32000として標準化され、その実装のためのロイヤリティを必要としなくなった。
(中略)
PDFは、2008年7月1日にオープンスタンダードとしてリリースされ、国際標準化機構(International Organization for Standardization)によってISO 32000-1:2008として発行されるまで、アドビが管理していたプロプライエタリなフォーマットでした。2008年、アドビはISO 32000-1の公開特許ライセンスを発行し、アドビが所有するPDF準拠の実装を作成、使用、販売、配布するために必要なすべての特許に対してロイヤリティフリーの権利を付与しました。
PDFは、テキストや画像を含む文書を、アプリケーションやOSなどの環境に依存しない方法で表示することができるファイル形式です。
1993年にAdobeによって開発されて以来、広く普及するに至り、2008年に国際標準化機構(ISO)によって標準化され、Adobeがロイヤリティフリー(決められた範囲内での使用料の免除)の権利を付与したことで、自由に実装などができるようになっているようです。
以下のPDFでは、ISO32000のPDF仕様を読むことができます。
Portable Document Format
PDFの技術的な基礎
PDFを使ったことない人はいないと思いますが、普段使うだけで内部実装を気にする機会は少ないですよね。
PDFはどういう技術でできているのでしょうか?
Portable_Document_Format(en.wikipedia.org)から引用すると、
- レイアウトとグラフィックを生成するためのPostScriptページ記述プログラミング言語のサブセット。
- フォントを文書と一緒に移動できるようにするためのフォント埋め込み/置換システム。
- 構造化されたストレージシステムで、これらの要素と関連するコンテンツを1つのファイルに束ね、必要に応じてデータ圧縮を行います。
つまり、PDFは大きく分けて次の3つの技術を組み合わせています。
- PostScriptページ記述言語(レイアウト・グラフィックの生成)
- 構造化されたストレージシステム(データ圧縮など)
- フォント埋め込み・置換システム
せっかくなので、この記事ではこれらを調べていくことにします。
- 「PostScript」とは?
- 高速ロードの仕組み
- フォント埋め込み
PDFの技術的特徴1:「PostScript」とは?
まず、 PostScriptとはなんでしょうか?
私自身、名前自体は見たことがありましたが、画像系のフォーマットであるぐらいしか知りませんでした。
それでは、PostScriptについて見てます。
PostScript
PostScript(PS)は、電子出版やDTPビジネスにおけるページ記述言語です。動的に型付けされた連結型のプログラミング言語で、1982年から1984年にかけてAdobe Systems社でJohn Warnock、Charles Geschke、Doug Brotz、Ed Taft、Bill Paxtonによって作成されました。
PostScriptは、電子出版やDTPビジネスにおけるページ記述言語であるらしいです。
そもそも ページ記述言語 とはなんでしょうか?
ページ記述言語
Page_description_language(en.wikipedia)
デジタル印刷において、ページ記述言語(PDL)は、実際の出力ビットマップ(または一般的にはラスタグラフィックス)よりも高いレベルで印刷されたページの外観を記述するコンピュータ言語である。重複する用語としては、プリンタ制御言語があり、これにはヒューレット・パッカードのプリンタコマンド言語(PCL)が含まれる。PostScriptは、最も注目されているページ記述言語の一つである。PDLをマークアップ言語化したものがページ記述マークアップ言語である。
ページ記述言語は、 出力ビットマップ(ラスタグラフィックス)よりも高いレベルで印刷されたページの外観を記述するコンピュータ言語である、とあります。
ここで ラスタグラフィック という単語が出てきたのですが、これについては後ほど詳しく見ていきます。
一旦、PostScriptの歴史に戻ってみます。
PostScript言語のコンセプトは、1976年にコンピュータグラフィックス会社であるEvans & Sutherland社のJohn Gaffney氏によって生み出されました。当時、GaffneyとJohn Warnockは、ニューヨーク港の大規模な3次元グラフィックスデータベース用のインタプリタを開発していました。
PostScript言語のコンセプト自体は 1976年に John Warnock, Gaffney さんによって生み出されました。
それとは別に、時代はまさにレーザープリンタの黎明期であり、印刷対象となるページ画像の定義の標準化が検討されていた ようです。
しかし、柔軟性の欠けた形式が使われていたり、なかなか暗中模索の状況が続いていました。
そこで誕生したのが、 Adobe Systems です。
1978年、当時Xerox PARCにいたJohn GaffneyとMartin NewellはJ&MまたはJaM(「John and Martin」の意)を書き、VLSI設計や活字・グラフィック印刷の研究に使用した。この作業は後に進化し、インタープレス言語へと拡大していった。
WarnockはChuck Geschkeとともに退社し、1982年12月にAdobe Systemsを設立した。彼らは、Doug Brotz、Ed Taft、Bill Paxtonとともに、Interpressに似たよりシンプルな言語であるPostScriptを開発し、1984年に発売しました。この頃、スティーブ・ジョブズの訪問を受け、彼はレーザープリンタを駆動するための言語としてPostScriptを使用するように促した。
当時、レーザープリンタの開発を行っていた Xerox PARC にいた John Warnock と Chuck Geschke は Xerox PARCを退社し、 Adobe Systems を設立しました。
そこでシンプルなコード記述言語である PostScript が開発されることになったわけです。
そんな中、 PostScriptを Steve Jobs が気に入ったらしく、 Appleで PostScript を使うようになり、 1985年に Apple LaserWriter というPostScriptを搭載した最初のプリンタが発売されました。
そんなこんなで PostScript言語用のインタプリタがレーザープリンタについているのが一般的になるなど、グラフィック出力のための最適な言語として PostScript の普及が進んで行きました。
しかし、印刷するときに生のPostScriptコードを印刷するためには、そのままではできません。
PostScriptは、あくまで ベクターグラフィックス として印刷データを保存しているため、プリンタが ラスターグラフィックス に変換する ラスタライズ を行う必要があります。
その際、プリンタはCPUやメモリを大きく消費するため、ハイエンドなプリンタ以外はラスタライズを行わないものもありました。
随分とカタカナが多いのですが、 ラスタライズとは何か を簡単に紹介してみます。
ラスタライズ
ラスタライズ(またはラスタライズ)とは、ベクターグラフィックス形式(図形)で記述された画像を取り込み、ラスタ画像(一連のピクセル、ドット、またはラインであり、それらを一緒に表示すると、図形で表現された画像を作成する)に変換する作業である。 ラスタライズされた画像は、コンピュータのディスプレイ、ビデオディスプレイ、プリンタに表示されたり、ビットマップファイル形式で保存されたりする。ラスタライズとは、3Dモデルを描画する技術や、ポリゴンや線分などの2Dレンダリングプリミティブをラスタライズされたフォーマットに変換することを指す場合がある。
ようするに、ラスタライズとは、 ベクターグラフィックス形式で記述された画像 を、ピクセルやドットなどで表現するラスタ画像に変換する作業 のことをいいます。
ベクターグラフィックス とはなんでしょうか?
ベクターグラフィックス
ベクトルグラフィックスは、ポリゴンや他の形状を形成するために線や曲線によって接続されている直交平面上のポイントの面で定義されているコンピュータグラフィックスのイメージです。ベクトル・グラフィックスに、ポイント、ライン、およびカーブがエイリアシングなしで任意の解像度にスケールアップまたはスケールダウンすることができるという点で、ラスター・グラフィックス上のユニークな利点があります。点はベクトルパスの方向を決定します; 各パスはストロークの色、形状、曲線、太さ、塗りつぶしの値を含む様々なプロパティを持つことができます。
画像や図形を、点で表現することで、 任意の解像度でキレイに表現することができる のが、ベクターグラフィックス形式の特徴です。
イメージとしては、例えば平面上で「三角形」を表現することを考えます。
三角形は、ご存知のように三点の座標を決めれば一意に位置と形が決まります。
三角形を「三点の座標」で表現するのが ベクターグラフィックス という感じです。
例えば、 SVG や、 EPS 、 PDF が代表的なベクターグラフィックス形式のファイル形式です。
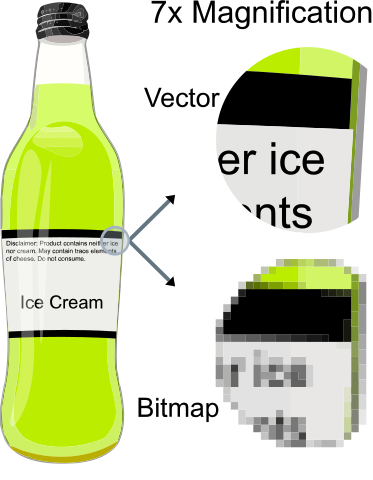
(Rasterisation(en.wikipedia) より引用)
この画像で対比されているように、 Bitmap つまり、 ラスターグラフィックス形式 も存在しています。
ラスターグラフィックス形式
コンピュータグラフィックスおよびデジタル写真では、ラスタグラフィックスまたはビットマップ画像は、ビットマップディスプレイ(モニタ)、紙、または他の表示媒体を介して表示可能な、一般的に長方形の格子状のピクセル(色の点)を表すドットマトリクスデータ構造である。ラスター画像は、普及・制作・生成・取得形式が異なる画像ファイルに格納されている。
一方、 ラスターグラフィックス形式 は、画像を細かい長方形の ピクセル に分割して、各点の色を表す行列形式のデータ構造を持ちます。
例えば、皆さんも馴染みが深い JPEG や PNG、 GIF などがラスターグラフィックス形式の代表例です。
先ほどの三角形の例でいうと、平面を格子状に区切り、各格子ごとに値を付けていきます。
ラスターグラフィックスで三角形を表現するには、その線分が通る格子に値(つまり、色)をつけることになります。
データ量は、格子ごとの値を持つ必要があるラスターグラフィックスの方が、座標などのシンプルな表現で図形を記述するベクターグラフィックスよりも大きくなってしまいがちです。
「ラスター」という言葉がどうして使われるのか軽く調べてみましたが、どうやら2次元の画像を点で一次元でスキャンし、その次に直角方向にスキャンする ラスタースキャン あたりが語源になっているような気がします(間違ってたらすいません)。
ラスタースキャン(ja.wikipedia.org)
(追記) ラスターの語源
2020/11/7 18:30 頃に追記です。
「ラスターってなんやねん」と投げやりな書き方をしていましたが、 @scivola さんにコメント欄でとても丁寧に教えていただきました。
そのコメントを、自分なりに簡単にまとめてみます。
raster とは、 CRTディスプレイの走査線 のことです。
CRT(Cathode-ray tube) とは、日本語でいうと、 ブラウン管 というやつです。(めっちゃ有名だった
そもそもの話からすると、電子線を蛍光体にぶつけると発光する原理があります。
蛍光体を何かしらの面に塗りつけて、電子線をぶつけてやると、ぶつけられた場所だけが光ります。
この原理を使ったディスプレイが ブラウン管 です。
電子銃で電子線を放出する時に、 方向を変えたり、強度を変えたりすることで、光り方を制御できます。
そんでもって、この電子銃による電子線の当て方の違いこそが、 ベクトルスキャンとラスタースキャン(、ラジアルスキャン)の違い です。
ベクトルスキャン は、ある図形を表示するときに、 強度を一定に保ち、電子線の方向だけ変えて、ブラウン管に表示させます 。
一方、 ラスタースキャン は、電子線の方向を、蛍光面の左の端から右の端までバーッと動かし、端まで着いたら少し下で同じように左→右と動かし、最終的には面全体に電子線を当てます。
これでどうやって図形を描くねん、となりますが、ラスタースキャンは 電子線の強度を変えることで任意の図形を描く ことができます。
ラスタースキャンの柔軟性の高さから、テレビジョンにはラスタースキャンが用いられるようになったようです。
辞書によれば,英語の raster はドイツ語の Raster からの外来語で,1930 年代には使われていたようです。
ドイツ語の Raster はラテン語で「熊手」を意味する rastrum に由来するようです(知らんけど)。
熊手で掻いていく動作ってことですかね。
肝心のラスターの語源としては、おそらく 熊手 というのが私にも勝手にしっくりきたので、それでいきましょう。(結局適当
(追記終わり)
プリンタのラスタライズ
直観とも一致しますが、プリンタは、画像が格子状になっていて印刷すべき各点の色がわかりやすいラスター形式の方が嬉しいです。
しかし、PostScriptはベクター形式であるため、それをプリンタが印刷する前にラスター形式に変換するラスタライズを行わないといけないという理屈です。
この辺の話も深掘りすると面白そうですが、記事が長くなりすぎるので興味ある方は調べてみてください。
PostScriptとPDFの関係
さて、肝心の PostScript と PDF の関係についてです。
PDF(en.wikipedia)によると、基本的には、PostScript の役割である、ページ記述言語としての特徴は引き継いでいます。
一部、PostScriptには存在している、フロー制御といった複雑な機能を削除し、簡略化しているようです。
また、PDFは PostScript をさらに発展させるための機能を追加しています。
文書形式として、PDFにはPostScriptよりもいくつかの利点があります。
PDF には PostScript のソースコードのトークン化された解釈された結果が含まれており、PDF ページ記述内の項目への変更と、結果として得られるページの外観への変更とが直接対応するようになっています。
PDF (バージョン 1.4 以降) は透過グラフィックに対応していますが、PostScript は対応していません。
PostScript は暗黙のグローバル状態を持つ解釈型プログラミング言語なので、あるページの記述に付随する命令は、後続のどのページの外観にも影響を与えます。そのため、 PostScript 文書内のすべての先行ページは、与えられたページの正しい外観を決定するために処理される必要がありますが、PDF 文書内の各ページは他のページの影響を受けません。その結果、PDF ビューアでは、長い文書の最後のページにすばやくジャンプできるのに対し、PostScript ビューアでは、目的のページを表示する前にすべてのページを順次処理する必要があります (オプションの PostScript 文書構造化規約が慎重にコンパイルされて含まれていない限り)。
なんかいろいろ書いてありますが、次のような感じです。
- PDFには、トークン化された解釈結果が含まれていて、ページ記述内の項目変更が、ページ外観への変更と直接対応する(よくわかっていないので、詳しい人教えてクレメンス)
- PDFに透過グラフィックはあるが、PostScriptにはない
- PostScript にはグローバル状態があり、全ページに影響するが、PDFはページごとにスコープが切れている
PDFは、 ランダムアクセス(任意のページへの移動)に強いファイル形式 です。
皆さんも、ページ番号を入力すると、瞬時にそのページに飛ぶ経験をしたことがあるでしょう。
これは、 各ページが他のページの影響を受けないように設計されている ため、他のページの読み込みができていなくても、そのページの読み込みをすることができるという特徴があります。
PostScriptは、グローバルな状態を持っていて、ページを順次処理して行く必要があるため、あるページに飛ぼうとしてもそれまでのページが処理されていなければ表示できない、といったことがあります。
続いては、 ランダムアクセスを可能にするPDFの工夫 を見てみましょう。
PDFの特徴2:構造化されたストレージシステムが実現する高速ロードの仕組み
PDFファイルは、バイナリコンテンツを持つ可能性のある特定の要素を除いて、7ビットのASCIIファイルです。PDF ファイルは、マジックナンバーと %PDF-1.7 などのフォーマットのバージョンを含むヘッダーで始まります。この形式は、COS(「カルーセル」オブジェクト構造)形式のサブセットである。
PDFを何かしらのテキストエディタで覗いてみると、めちゃくちゃ文字化けしている(つまりバイナリ化されている)領域と、普通の文字で書かれている領域があることがわかります。
PDFは、 オブジェクト という構成要素の集まりからなっていて、これらのオブジェクトが参照して作りあげられています。
適当に作ったPDFをテキストで見てみるとこんな感じの中身を見ることができます。
%PDF-1.3
4 0 obj
<< /Length 5 0 R /Filter /FlateDecode >>
stream
xUO�
...
Į��D���'��+�;��b�B��p������W�\veܱ���mь���`���a�����d���"Κ���O��Wt ��S��2EVZ�iOt ���������
7Z1�
endstream
endobj
% (略)
15 0 obj
<< /Type /StructElem /S /H1 /P 12 0 R /Pg 2 0 R /K 2 >>
endobj
3 0 obj
<< /Type /Pages /MediaBox [0 0 1920 1080] /Count 1 /Kids [ 2 0 R ] >>
endobj
16 0 obj
<< /Type /Catalog /Pages 3 0 R /MarkInfo << /Marked true >> /StructTreeRoot
13 0 R >>
endob
ぱっと見意味わからんわ、となりそうですがちょっと待ってください。
基本的に、各オブジェクトは次のような形をしています。
15 0 obj
<< /Type /StructElem /S /H1 /P 12 0 R /Pg 2 0 R /K 2 >>
endobj
この例では、最初に オブジェクト番号 (ここでは 15)と呼ばれるオブジェクトの名前に相当するものが書かれていて、その後には、オブジェクトがどういうものかの説明が続きます。
他のオブジェクトを参照するときは、オブジェクト番号を指定するという仕組みになっています。
割と 0 であることが多いですが、先頭二個目の数字である 世代番号 と組み合わせることで、オブジェクトが指定できるようになります。
PDFファイルの最後には、 xref テーブルと呼ばれる表があります。
xref
0 22
0000000000 65535 f
0000005471 00000 n
0000000276 00000 n
0000003539 00000 n
0000000022 00000 n
0000000257 00000 n
% (略)
startxref
5825
%%EOF
これは、 各オブジェクトの定義が書かれたファイル先頭からのオフセットが書かれています。
つまり、この表を事前に読み込んでおけば、 すぐにオブジェクト番号からオブジェクトにアクセスできます(ランダムアクセス可能)。
これが、 PDFがどのページを開いてもロードが速い理由の一つ です。
事前にオブジェクトの定義されている位置を計算し、それを最初からファイルの中に書いておくという工夫なわけです。
なかなか面白いですね。
確かにファイルシステムのようなストレージと似たような仕組みなので、 構造化されたストレージシステム と表現されます。
それでは最後に取り上げたいPDFの技術的特徴の一つ、 フォント埋め込み について見てみます。
PDFの特徴3:PDFのフォント埋め込み
PDFの技術的な特徴の一つに、 フォントの埋め込み が存在します。
ここではその概観について触れようと思います。
PDF(en.wikipedia)によると、PDFのフォントオブジェクトは、 デジタルフォントの記述 を目的としており、大きく分けて二つの種類があります。
- フォント名など、フォントの特徴を記述している場合
- フォントファイルをそのまま埋め込んでいる場合
PDF内のフォントオブジェクトは、デジタル書体の記述です。書体の特徴を記述している場合と、埋め込まれたフォントファイルを含んでいる場合があります。後者の場合は埋め込みフォントと呼ばれ、前者の場合は非埋め込みフォントと呼ばれます。埋め込み可能なフォントファイルは、広く使われている標準的なデジタルフォントフォーマットに基づいています。Type 1 (およびその圧縮版 CFF)、TrueType、そして(PDF 1.6 からは)OpenType です。さらに PDF は、フォントの構成要素が PDF グラフィック演算子によって記述される Type 3 バリアントにも対応しています。
PDF Reference 5.1 Organization and Use of Fonts を参照してみると、テキストの文字を表現するために キャラクタ(Character) と グリフ(Glyph) という二つの概念を導入しています。
- キャラクタ(Character) = 抽象的な文字("A"とか)
- グリフ(Glyph) = 特定のフォントでキャラクタを表現したもの(○○ゴシックの"A"とか)
例えば、 Helvetica のようなフォントというのは、アルファベットのキャラクタの集合(A,B,Cとか)の各要素に対し、グリフを定義したものということになります。
また、 PDFビューアなどのアプリケーションでフォントを表示する場合には、 フォントプログラム というものを使います。
フォントプログラム は、 Type 1 や True Type という特殊な言語で書かれたもので、フォントインタプリタというもので解釈されるようです。
フォントオブジェクトでフォントを表現する!
上記のリファレンスでの例をそのまま紹介します。
PDFの中で使用する フォントオブジェクト を宣言します。
この例では、 Helvetica という名前のフォントを使ったフォントオブジェクトを定義しています。
フォントオブジェクトには、フォントに関するメタ情報が入っています。
/Resources
<< /Font << /F13 23 0 R >>
>>
23 0 obj
<< /Type /Font
/Subtype /Type1
/BaseFont /Helvetica
>>
endobj
続いて、このフォントオブジェクトを参照するようなテキストオブジェクトを作り、文字列を設定したり、ページに対するオブジェクトの位置を指定したりできます。
BT
/F13 13 Tf
288 720 Td
(ABC) Tj
ET
フォント埋め込みには、ストリームオブジェクトを使う!
フォント埋め込みは、どうするかというと、 ストリームオブジェクト を使います。
PDFで使えるオブジェクトの中には、圧縮されたバイナリを表現できる ストリームオブジェクト があります。
文字化けしてしまうような部分は、このストリームオブジェクトだったわけです。
グリフといったフォントの情報をまるっとバイナリ圧縮し、ストリームオブジェクトに詰め込みます。
12 0 obj
<< /Filter /ASCII85Decode
/Length 41116
/Length1 2526
/Length2 32393
/Length3 570
>>
stream
% (バイナリがうわーっとある)
endstream
endobj
こんな感じで、バイナリにすべきところはバイナリにしつつ、単なるテキストや位置を表現するようなシンプルなオブジェクトは読みやすい形式になっているのがPDFの特徴のようです。
まとめ
なかなか長くなってしまいましたが、 PDFの面白さ、伝わりましたでしょうか?
- 「PostScript」とは?
- 高速ロードの仕組み
- フォント埋め込み
のように見てきました。
PostScriptの仕組みそのものもそもそもすごいのかもしれませんが、PDFはプログラミング言語であるPostScriptの良いところだけを取り出し、構造をシンプルにすることで広く普及される人気のファイル形式へと進化してきました。
オブジェクトの位置をファイルそのものに表として書き込んでいるおかげで、どのページに行っても、ファイル内の位置によらずロードができるようになる点もなかなか面白いです。
フォントを埋め込んだりすることで、マシンごとに違うフォントに影響されることなく、グリフを表示できるようになるわけです。
いろいろ面白い特徴があるPDFですが、今回紹介したような機能に留まらず、 画像や動画などのメディアを載せる仕組みも組み込まれており、今後とも重宝される存在となることでしょう。
この記事が、これからも続いていくPDFライフの一助となれば幸いです。
それでは、読んでいただきありがとうございました!
面白ければLGTMしてもらえると嬉しいです。
Twitter(@zawawahoge)もやってますので興味があればご覧になってください!