はじめに
学習率の最適化手法の一つである、Warmup Stable Decay(WSD)についての備忘録となります。
背景
LLMのハイパラ探索としての学習率をどうするか問題があった。
思想
Cosine LR Decayでは、cosine曲線のように緩やかに学習率を下げていって、パラメータ更新を行っていた。
ただ、この手法は以下の課題を持っていた
- 事前にこれだけのステップ数で収束するだろうということを知っていなければならない
- 継続学習するにしても、学習率が下がりきっているので、ここからまた上げなおすとスパイクが起きて学習がおじゃんに
本論文では、コサインスケジュールの代替として、一定の学習率+クールダウン=Constant LR + Cooddownという手法を提案している。
これは、トレーニングの大部分で学習率を一定に保ち、終了間際で(最後の15%の期間など)で、学習率を急激に下げることになる。
画期的なポイント
- 任意のタイミングで、クールダウンさせるように仕向けることができるので、事前にステップ数を決める必要がない
- 複数のクールダウン分岐を作れることで、少ない計算量でスケーリング側を導き出せる。
伸びしろ点
- 論文内の下流ベンチマークテストでは、必ずしもこの手法を取り入れて学習したモデルがよい結果を出したわけではない
→ データセットの食わせ方、ほかの条件が固定だったのかが気になるところ
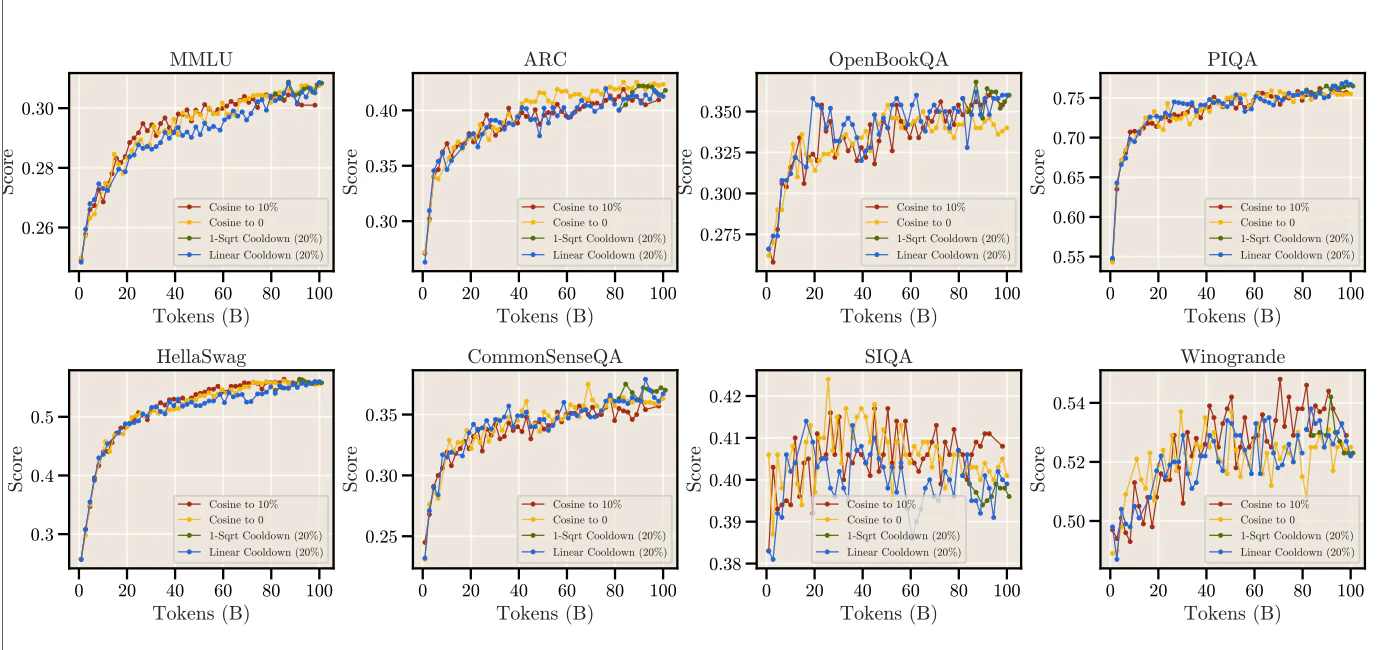
- 8B以上の超パラメータにおいて、高い学習率のままいっても学習が不安定にならないのかどうかの検証
気づき
- さすがに急激に下がったところからまた学習することはできないので、着地点はしっかりと見極めること。
関連論文
-
Training Compute-Optimal Large Language Models
https://arxiv.org/pdf/2203.15556
本論文が乗り越えようとしている対象。Cosineスケジュールは学習期間とサイクル長が一致していないと最適ではないという、スケーリング側を確立した論文 -
The Road Less Scheduled
https://arxiv.org/pdf/2405.15682
そもそも、学習率のスケジュール調整すらいらなくね?というアプローチ。本論文でも比較実験がされている。本手法に及ばなかったものの、有力な対抗馬 -
Simple and Scalable Strategies to Continually Pre-train Large Language Models
https://arxiv.org/pdf/2403.08763
一度、下げた学習率を再び上げる際に起きる、忘却や損失スパイクについて述べた論文。
Constant LRで維持することの重要性の背景が理解できる。
参考文献