はじめに
ゲーム「ポケットモンスター」シリーズにおいてはポケモンの鳴き声は電子音のようなSEとして表現されています。ほぼ全てのポケモンに固有の鳴き声が割り当てられており、本編をプレイしたことがある方にとっては馴染み深いものも多いと思われます。以下の動画はそれらの例です。
これらの音声をデータセットにし、機械学習の手法の1つ"**WaveGAN**"でポケモンの鳴き声を生成しました。以下は生成例です。
機械学習で音声を生成する手法「WaveGAN」でポケモンの鳴き声を出力させてみましたhttps://t.co/Izt2nq9Q3e pic.twitter.com/fqzEFwSqoH
— zassou (@zassouEX) March 12, 2021
本記事ではこれに用いた手法を紹介していきます。
WaveGAN
音声の生成にはWaveGANという手法を使っています。これは**GAN(Generative adversarial networks、敵対的生成ネットワーク)**という手法をベースにしたもので、以下のように構成されています。
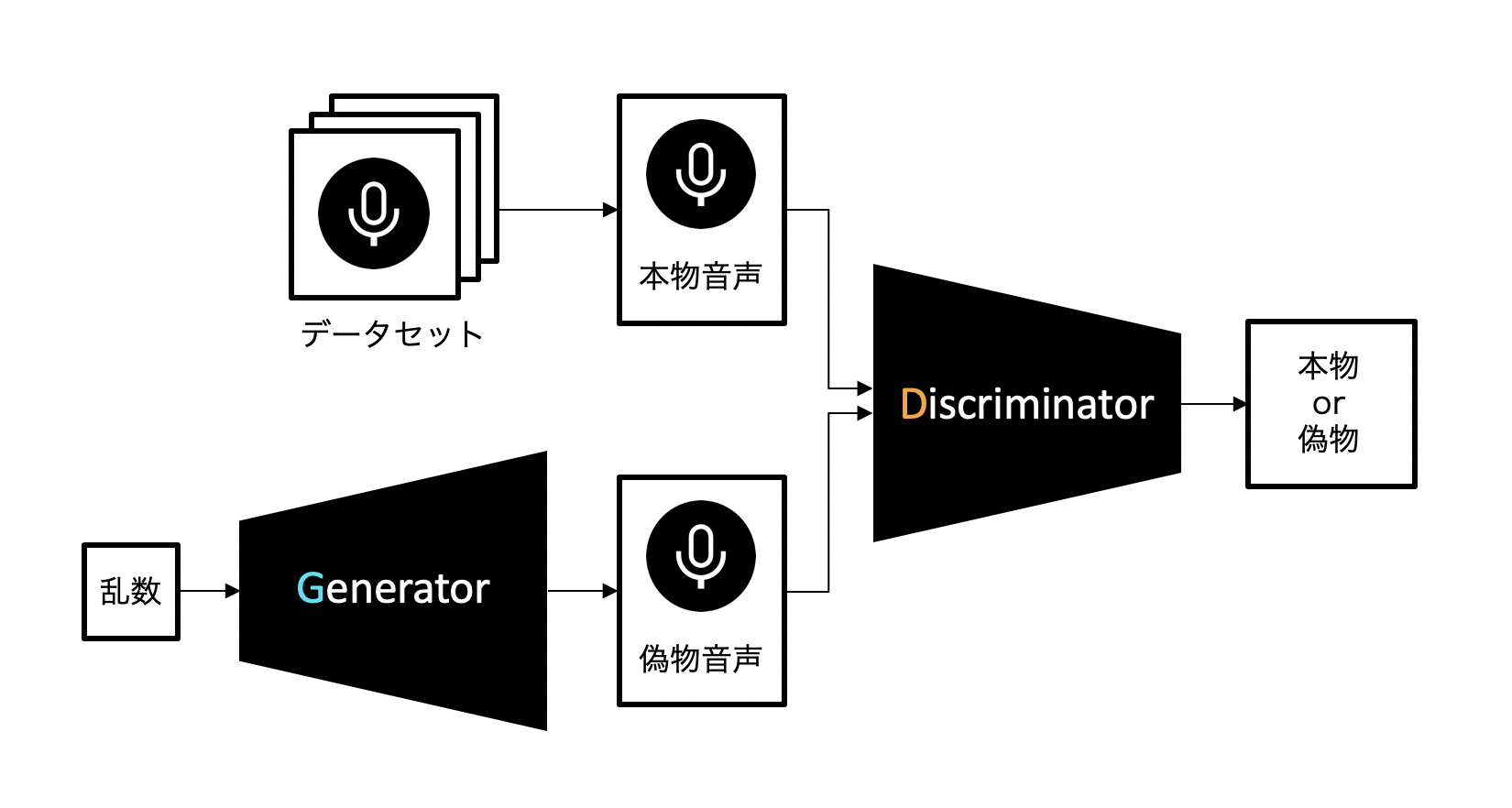
この手法では、音声を生成するニューラルネットワーク(Generator)と、音声を識別するニューラルネットワーク(Discriminator)の2つを組み合わせます。
Generatorは音声データを生成し(これを偽物音声と呼ぶことにします)、それによってDiscriminatorをデータセット中の本物の音声データ(本物音声と呼ぶことにします)だと誤認させることを目指して学習を進めます。一方でDiscriminatorはGeneratorに騙されないよう、より正確に音声データの真贋を見極めるよう学習します。
二つのニューラルネットワークがお互いに鍛え合うことで、Generatorは徐々に学習データに近い音声を生成できるようになっていきます。
要するにGenerator VS Discriminatorです。
データセット
データセットには全国図鑑でNo.001のフシギダネ〜No.898のバドレックスまで全部のポケモンの鳴き声(.wav形式、サンプリングレート16000Hz)を用います。同じ種類のポケモンでもフォルムチェンジで鳴き声が変わるようであればそれもデータセットに含めます。ただしメガシンカ、ダイマックス時の鳴き声は学習全体に与える影響を考え除外しました。
Generatorの作成
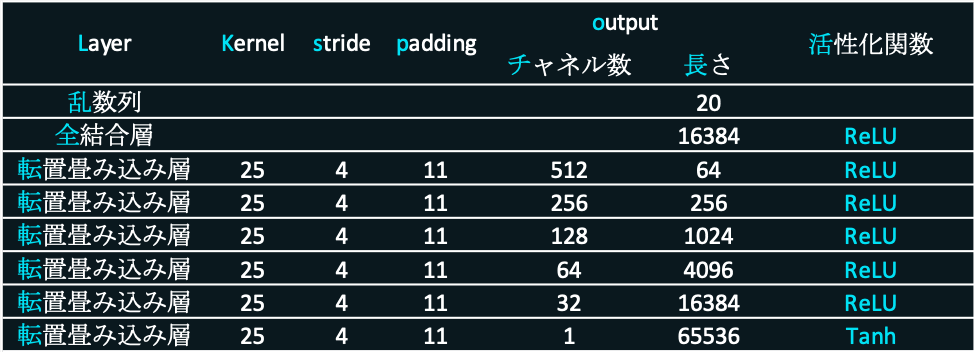
Generatorの役割は、入力に乱数で構成された数列(これを乱数列と表現することにします)をとり、それを元にして音声を生成することです。生成した音声をDiscriminatorに入力した時、本物音声だと騙せるように学習していきます。
入力する乱数列の長さは20とし、出力する音声は長さ65536の時系列データ(約4秒程度)とします。入力を1次元転置畳み込み層(TransConv1D)に通していき最終的に音声を出力します。
Discriminatorの作成
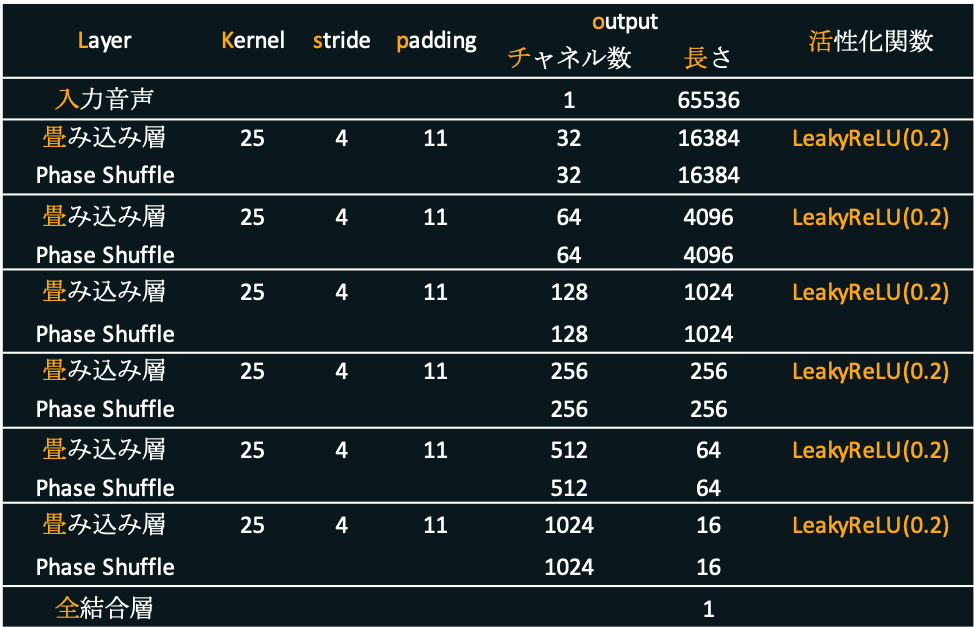
Discriminatorは入力された音声が本物音声なのか、Generatorによって生成された偽物音声なのかを正しく識別できるよう目指して学習を進めます。要は音声認識器を作ります。
入力する音声は長さ65536の時系列データとし、出力はどれだけ本物らしいかを表す値(範囲は0~1)とします。入力を1次元畳み込み層(Conv1D)とPhase Shuffle(後述)に通していき最終的な判断結果を得ます。
checkerboard artifacts
GANによる画像生成において、Generatorが転置畳み込みによって出力した画像にはcheckerboard artifactsという、市松模様のような周期的なパターンが出現することがあります。

一部の特例をのぞいて、一般的にほとんどの学習データの画像においてはこのようなパターンは現れないため、Discriminatorはこの模様を含む画像が入力された時、それを偽物画像だと判定するように学習が進みます。
音声生成でもcheckerboard artifactsのようなパターン(以下ではこれを単にcheckerboard artifactsと呼ぶことにします)が生成されることがあり、ノイズのような形で知覚できるようです。音声においてcheckerboard artifactsは常に特定の位相でのみ発生するそうで、このことが原因でDiscriminatorが意図しない学習をしてしまい、結果的にモデル全体がうまく機能しなくなることがあるようです。
そこでDiscriminatorにPhase Shuffleという操作を行う層を導入します。
Phase Shuffle
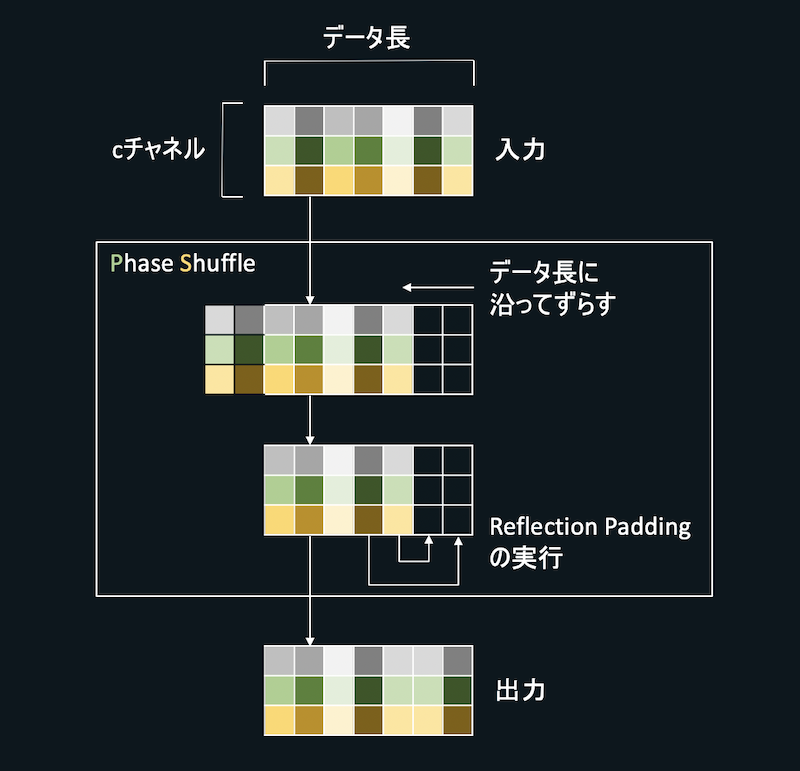
checkerboard artifactsによってDiscriminatorが意図しない学習をしてしまうのを防止するため、Phase Shuffleを実行する層を導入します。
Phase Shuffleを行う層ではまず入力された特徴量に対し、$m$要素ずらす操作を実行します(ただし$m\in [-n,n]$、$n$はハイパーパラメーターで、今回は$n=2$に設定)。$m$はPhase Shuffleを実行するたびにランダムに$[-n,n]$の範囲から選び出す整数です。さらに、$m$要素ずらした結果空いた箇所をReflection Paddingによって埋めます。
この操作によってDiscriminatorの学習がうまくいく理由として、WaveGANの論文中では以下のように言及されています。
"Intuitively speaking, phase shuffle makes the discriminator’s job more challenging by requiring invariance to the phase of the input waveform." (直訳 : 直感的に言えば、phase shuffleは、入力波形の位相に不変性を要求することで、Discriminatorの仕事をより困難にします。)
自分的な解釈ですが、おそらくcheckerboard artifactsが常に特定の位相でのみ発生するところを、Phase Shuffleによってより多様な位相で発生するようにすることで意図通りの学習が進むようにしているものと思われます。
学習方法・誤差関数
GeneratorとDiscriminatorの損失関数はWGAN-GPとしました。WGAN-GPの定義は以下です。
- Generatorの損失関数
-E[d_{fake}]
- Discriminatorの損失関数
E[d_{fake}] - E[d_{real}] + \lambda E_{\substack{\hat{x}\in P_{\hat{x}}}}[(||\nabla_{\hat{x}}D(\hat{x})||_{2}-1)^{2}]
乱数列をGeneratorへ入力、ミニバッチの数$M$(今回は$M=16$と設定)だけ音声を生成します。それらをDiscriminatorに入力し、どれくらい本物らしいかを示す値をそれぞれの入力音声に対し$M$個出力させます。これを$d_{fake}$とします。
また、本物音声を$M$個Discriminatorに入力し、その時の$M$個の出力を$d_{real}$とします。$E$はミニバッチに対して平均をとる操作です。
Discriminatorの損失関数の第3項はgradient penaltyと呼ばれている項です。詳しい解説はこちら。
誤差伝搬の最適化手法にはAdamを使い、学習率0.0001、Adamの一次モーメントと二次モーメント(モーメント推定に使う指数減衰率)はそれぞれ0.5と0.9に設定しました。
全体像
以上のようにして作成したGeneratorとDiscriminatorを図のように組み合わせ、WaveGANを構成します。
学習+音声生成
今回はミニバッチ数16、エポック数は500に設定しました。
ポケモンの鳴き声を用いて学習を行い、Generatorに音声を生成させます。学習途中における出力は次のようになりました。
学習途中における出力です。ノイズのような音声から学習を経るごとに出力が変化しているのがわかります。 pic.twitter.com/bHJR0qYWdG
— zassou (@zassouEX) March 12, 2021
ソースコード
実装したコードはこのリポジトリにあります。
https://github.com/zassou65535/WaveGAN
余談
GANは本来音声の生成よりも、画像の生成や画像間の変換で有名な手法です。
GANによる画像生成や変換に関しても解説記事を書いているので是非こちらもどうぞ。
画像変換 :
機械学習で画像を変換する手法「UGATIT」でメルアイコン変換器を作りました。https://t.co/stNnKuSf0Z pic.twitter.com/vk99ZXOX9g
— zassou (@zassouEX) December 1, 2020
画像生成 :
機械学習で画像を生成する手法「GAN」を用いてメルアイコン生成器 version2を作りましたhttps://t.co/D84EkyL7LA pic.twitter.com/Fyt9cb1ysn
— zassou (@zassouEX) August 8, 2020
まとめ
WaveGANによって音声を生成しました。一般に画像に関する分野でよく使われている手法が、音声においても通用するのは興味深いですね。
機械学習で音声を生成する手法はWaveGANだけでなくSpecGAN、GANSynth、WaveNetなど多種多様な方法がこれまでに提案されています。いずれも長さ数秒程度の音声の出力が可能で、短めのサウンドエフェクトなどの生成に向いているかと思われます。皆さんもどんどん音声生成しましょう。
参考
Adversarial Audio Synthesis
PyTorch reimplementation of WaveGAN
Synthesizing Audio with Generative Adversarial Networks
Deconvolution and Checkerboard Artifacts