💡 Notice for English Speakers > An English version of this article is available on dev.to:
Stop Choosing Between Speed and LoRAs: Meet ComfyUI-TensorRT-Reforge 🚀
はじめに
ComfyUIで画像生成を楽しんでいる皆さん、 もっと生成速度を爆速にしたい! と思ったことはありませんか?
AIモデルの推論を高速化させる技術の1つに「TensorRT」があります。ComfyUI上でTensorRTを利用できるようにするカスタムノードはいくつか存在しますが、「LoRAが使えない」「Anima2B非対応」「ノードが古くてメンテナンスが止まっている…」といった悩ましい問題がありました。
そこで今回、「TensorRTの爆速生成の恩恵を受けつつ、LoRAもAnima2Bも自由に使える」 最新のカスタムノード『ComfyUI-TensorRT-Reforge』を開発しました!
本記事では、このカスタムノードの使い方や、背後で動いているちょっと面白い技術について分かりやすく紹介していきます。
謝辞
本プロジェクトはComfyUIの作者でもある comfyanonymous 氏によるComfyUI-TensorRTを参考にさせていただき、さらに進化させたものです。
作ったもの
「ComfyUI-TensorRT-Reforge」には、大きく分けて2つのカスタムノードが含まれています。
- TensorRT Exporter Reforge(以下、Exporter)
- TensorRT Loader Reforge(以下、Loader)
役割はとてもシンプルです。
まず Exporter が、 .safetensors モデルを高速なTensorRTモデルに変換して保存します。次に Loader が、その変換されたモデルをComfyUI上で読み込み、いつも通りに扱えるようにラップしてくれます。
動作要件
動作要件と、今回テストした環境は以下の通りです。
| 対象 | 動作要件 | テスト環境 |
|---|---|---|
| OS | Windows11/10, WSL, Ubuntu | Docker on WSL(Dockerfile) |
| GPU | RTX 2000シリーズ以降 | RTX 4070 Ti |
| VRAM | 8GB以上 | 12GB |
| CUDA | 12.x | 12.8 |
| 対象モデル | Anima2B , SD1.5, SDXL, AuraFlow, Flux, SD3, SVD | Anima2B , SD1.5, SDXL, SD3 |
注意点
CUDA11やCUDA13は現在サポートしていません。
ONNXやTensorRTのバージョン、エクスポート時のオプションを調整すれば動作する可能性はあります。もし動いたよ!という方がいらっしゃれば、こちらで報告していただけると嬉しいです
インストール
「ComfyUI-TensorRT-Reforge」の導入は、通常のカスタムノードと同様に簡単です。お好みの環境に合わせて以下のいずれかの方法でインストールしてください。
1. ComfyUI-Manager を使う方法(推奨)
ComfyUI-Managerを導入している方は、GUI上から数クリックで導入が完了します。
- ComfyUIのメニューから [Manager] をクリックします。
- [Custom Nodes Manager] を開きます。
- 検索窓に
TensorRT-Reforgeと入力します。 -
ComfyUI-TensorRT-Reforgeが見つかったら [Install] ボタンをクリックします。 - インストール完了後、ComfyUIを 再起動 してください。
Managerのリストに見当たらない場合
本プロジェクトは公開直後のため、タイミングによってはリストに反映されていないことがあります。その場合は、Managerの「Install via Git URL」から本リポジトリのURLを入力するか、以下の「手動インストール」をお試しください。
2. 手動でインストールする方法(git clone)
ターミナルやコマンドプロンプトから直接インストールする場合は、以下の手順で行います。
# custom_nodesディレクトリに移動
cd custom_nodes
# リポジトリをクローン
git clone https://github.com/zaochuan5854/ComfyUI-TensorRT-Reforge
# 必要なライブラリのインストール
cd ComfyUI-TensorRT-Reforge
pip install -r requirements.txt
使い方
それでは、実際の使い方をステップバイステップで見ていきましょう。
この画像をドラッグアンドドロップすることでワークフローをインポートできます。
0. 引数の追加
本ノードを利用して .safetensor モデルをTensorRTモデルに変換する際Windows環境では(すべての環境で必須です)引数 --disable-dynamic-vram を起動時に追加する必要があります。ComfyUIのバージョンによっては認識しない場合がありますがその際はつけなくて大丈夫です。
--disable-dynamic-vram 引数を追加
モデル変換時に必ず行ってください。ComfyUIのバージョンによって認識しないものがあります、その場合は外してください。
1. safetensorモデルの変換(Exporter)
まずはExporterノードを配置して、高速化したい .safetensors モデルを選択します。
次に「生成時のバッチサイズ」「画像サイズの範囲」「LoRA機能を有効にするか」を設定し、出力ファイル名のプレフィックス(接頭辞)を指定して実行します。

※上図は anima-preview2.safetensor を使って、「バッチサイズ1」「1024x1024の画像のみを出力する」TensorRTモデルを作成している例です。
変換時の注意
- 変換処理には3〜10分程度かかる場合があります。気長にお待ちください。
- ここでLoRAを「有効」にしないと、後からLoRAを当てることができません!
- Animaモデル、またはLoRAを有効にした場合、独自の
.bundleファイル(フォーマット詳細)が生成されます。
画像サイズの「範囲指定」について
TensorRTは、事前に「入力するデータの形(サイズ)」をカッチリ決めておく必要があります。サイズを1つに固定すると最も高速化されますが、その代わり決まったサイズの画像しか出力できなくなります。(max, minを 0 にすると指定なしになります)
2. TensorRTモデルの読み込み(Loader)
変換が終わったら、Loaderノードで先ほど作成したモデルを選択し、モデル形式(Model Type)を選びます。

モデル形式はファイル名から自動で設定されますが、念のため正しい形式になっているか確認してください。
3. 潜在画像(Latent)の設定と画像生成
あとは通常のモデルと同じようにワークフローを組んで生成ボタンを押すだけです!

🚨 潜在画像のサイズ・バッチ数に注意!
潜在画像のバッチサイズや画像サイズが、Exporterで設定した値と矛盾しているとエラーになります。Exporterでの設定値はTensorRTのファイル名に記載されているので、迷ったらそこを確認してください。
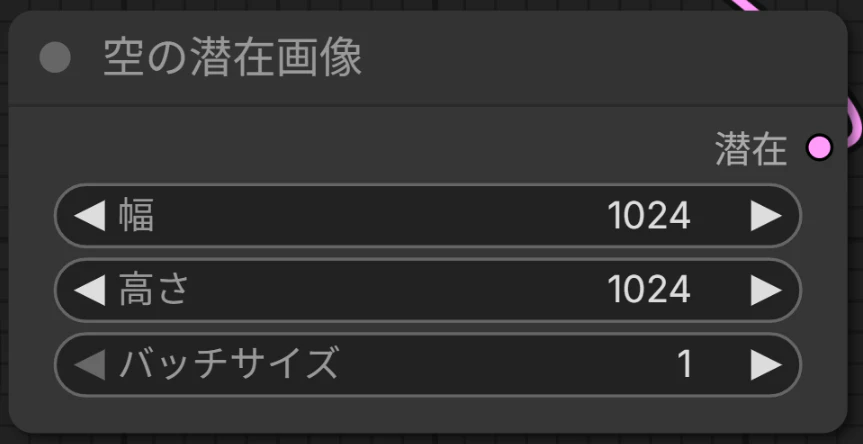
※例では、Exporterで設定した通りに「幅1024、高さ1024、バッチサイズ1」を入力しています。
技術面の解説(なぜ速くてLoRAも使えるのか?)
ここからは少し技術的な話になります。「なぜこのノードが劇的な高速化とLoRAの両立を実現できているのか」、その核となる技術要素をサクッと解説します。
基礎技術のおさらい
TensorRT:特定のGPUに最適化された専用マシン
通常、ComfyUIで .safetensors を読み込むと、PyTorchなどの汎用フレームワーク上で演算が行われます。PyTorchはどんな環境でも動く「汎用的なマニュアル車」のようなもので、柔軟な反面、どうしてもオーバーヘッド(ロス)が生じます。
一方 TensorRT は、お使いのGPU環境に特化した「エンジンの最適化」を行います。
- カーネル融合: バラバラの計算処理(ReLUやConvなど)をガッチャンコして1つの命令にし、メモリへのアクセス回数を減らします。
- 最適ルートの選択: そのGPUで一番速く計算できるアルゴリズムを自動で選び出します。
例えるなら、TensorRTは 「特定のサーキットを最速で走るためだけにチューニングされた専用のF1マシン」 を作っているような状態です。
LoRA (Low-Rank Adaptation):賢い差分学習
LoRAは、巨大なベースモデルのパラメータを直接いじるのではなく、小さな行列を追加することでサクッとモデルのテイストを変える技術です。
数式で表すと、元の重み行列 $W$ に対する更新は以下のようになります。
$$W_{updated} = W + \Delta W = W + BA$$
ここで追加される行列 $A$ と $B$ は、元のサイズに比べて圧倒的に小さいため、計算量やファイルサイズを抑えつつ高い表現力を発揮できます。
Refitの導入:カチカチのエンジンに柔軟性を
これまでのTensorRT最大の弱点は**「硬さ」**でした。
一度エンジンをカチカチにビルドしてしまうため、LoRAを切り替える(重みを変える)たびに、「また数分かけてF1マシンをイチから作り直し…」という途方もない手間がかかっていたのです。
これを解決したのが Refit(リフィット) という機能です。
Refitって何をしているの?
Refitは、エンジンの「演算構造(ネットワークの形)」はそのままに、内部の「重み」だけを高速に書き換える技術です。
- 骨組みはそのまま: TensorRTがせっかく最適化した最速の計算ルートは一切崩しません。
- 中身だけ注入: あらかじめ「ここは後で書き換えるよ」とマークしておいた重み領域に、新しいLoRAの成分を直接流し込みます。
これができると何が嬉しいか?
このRefitを活用することで、これまでTensorRTでは鬼門だった「LoRAの高速な切り替え」が実現しました。
- 切り替えが高速に: 数分かかっていた再構築が、わずか数秒で終わります。
- 速さはそのまま: TensorRT本来の圧倒的なスピードを維持したまま、色々なLoRAをガチャガチャ付け替えて遊べます。
「TensorRTの爆速」×「LoRAの柔軟さ」。この美味しいとこ取りをしたのが、今回の「ComfyUI-TensorRT-Reforge」です!
付録
開発環境のDockerfile
余分なパッケージも入っているので、環境に合わせて適宜修正して使ってください。
(※ビルドにはめちゃくちゃ時間がかかります…)
FROM nvidia/cuda:12.8.1-cudnn-devel-ubuntu24.04
RUN apt-get update && \
DEBIAN_FRONTEND=noninteractive apt-get install -y --no-install-recommends \
tzdata && \
ln -sf /usr/share/zoneinfo/Asia/Tokyo /etc/localtime && \
echo "Asia/Tokyo" > /etc/timezone && \
apt-get clean && \
rm -rf /var/lib/apt/lists/*
RUN apt-get update && apt-get install -y --no-install-recommends \
build-essential curl git tmux nano htop lsyncd ssh-client fontconfig fonts-ipafont fonts-ipaexfont\
&& rm -rf /var/lib/apt/lists/*
RUN fc-cache -fv
COPY --from=ghcr.io/astral-sh/uv:latest /uv /uvx /bin/
ENV VIRTUAL_ENV=/opt/venv
ENV PATH="$VIRTUAL_ENV/bin:$PATH"
WORKDIR /opt
ENV UV_HTTP_TIMEOUT=600
RUN uv venv $VIRTUAL_ENV --python 3.12 --seed \
&& uv pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu128 \
&& uv pip install comfy-cli ComfyUI-EasyNodes beautifulsoup4 aiohttp_retry
RUN (echo n; echo y) | comfy --workspace /opt/comfyui install --nvidia --cuda-version 12.8\
&& comfy --workspace /opt/comfyui node install \
ComfyUI-Impact-Pack \
ComfyUI-Manager \
was-node-suite-comfyui
RUN cd /opt/comfyui/custom_nodes \
&& git clone https://github.com/Suzie1/ComfyUI_Comfyroll_CustomNodes.git
RUN cd /opt/comfyui/custom_nodes \
&& git clone https://github.com/rgthree/rgthree-comfy.git
RUN cd /opt/comfyui/custom_nodes \
&& git clone https://github.com/cosmicbuffalo/comfyui-mobile-frontend.git
ENV UV_INDEX_STRATEGY=unsafe-best-match
RUN cd /opt/comfyui/custom_nodes \
&& git clone https://github.com/zaochuan5854/ComfyUI-TensorRT-Reforge.git \
&& cd ComfyUI-TensorRT-Reforge \
&& uv pip install -r requirements.txt
WORKDIR /opt/comfyui
ENV COMFYUI_PATH="/opt/comfyui"
bundleファイルのフォーマット
中身の .engine や .onnx を直接抜き出したい高度なユーザー向けの情報です。以下、またはソースコードを参考にパースしてください。
## File Layout
Each data chunk's role is defined by its leading ID. The appearance order within the file is arbitrary.
+-----------------------------------------+ <--- Offset 0
| [ID:1B][Size:8B][Chunk Data...] | Data Chunk A
+-----------------------------------------+
| [ID:1B][Size:8B][Chunk Data...] | Data Chunk B
+-----------------------------------------+
| ... | (Additional Chunks in any order)
+-----------------------------------------+ <--- End of Data Chunks (data_limit)
| |
| Metadata Section (JSON) | Variable Length (No ID prefix)
| |
+-----------------------------------------+ <--- Metadata End (EOF - 8 bytes)
| Metadata Size (8 bytes) | uint64, Little Endian
+-----------------------------------------+ <--- EOF
---
## ID Definition
- 0x01: TensorRT Engine Data
- 0x02: ONNX Model Data
- 0x03: WeightsMap (JSON / Binary)
- 0x04-0xFF: Reserved for future extensions
---
## Parsing Logic (ID-Driven)
1. Read the last 8 bytes of the file to get `meta_size`.
2. Calculate `data_limit` = (EOF - 8 - meta_size).
3. Initialize `current_offset = 0`.
4. While `current_offset < data_limit`:
a. Read 1 byte as `chunk_id`.
b. Read 8 bytes as `chunk_size`.
c. Record `data_start = current_offset + 9`.
d. Store the mapping of `chunk_id` -> `data_start`.
e. Jump to the next chunk: `current_offset += (9 + chunk_size)`.
5. Seek to `data_limit` and parse the Metadata JSON.