(目的)貿易統計(実データ)の処理体験をする人を増やす
現在、政府統計データは、さまざま角度から分析可能な形で提供されています。しかし、データを分析して、そこから意味を読み取ろうとする動きはまだまだ少ない気がします。貿易統計のように重要でアクセス数の多い統計データがもっと活用されてもよいと思い、手軽に(でもないですが、)活用できるための記事を書いています。
(想定読者)
貿易統計のデータを、まずは、もう少し細かく集計して、分析したいという人向けです。具体的には、シンクタンクの新人や、大学院生で、統計データ分析のスキルがあるといいなと普段から思っている人向けです。SQLをつかった経験のない人が、この記事を実践して、少しの努力で、手軽にSQLを使えるようなったら、儲けものでしょう。
必要なスキルは、そこそこハードルが高いです。jupyter で,sql,pandas 使って集計します。ここでの説明は、google の colaboratory(無料です。)
という仕組みが前提です。jupyter は、手元のPCでも設定可能ですが、クラウドで動かせるcolaboratory が何かと便利です。
データ
kaggle にsqlite の形式でおいてあります。主なデータは、国連の多国間の貿易データで、ここ から取得して、日本の貿易データも付加しています。データは、2014年なので、少し古いです。
多国間のデータなので、例えば、日本から中国への自動車輸出を見てから、中国の自動車輸入を見て、日本は何番目の輸出金額なのかを調べることができます。中国と日本の2国間しかわからない貿易統計では、これはできません。なお、最新の国連データは、ここ です。
準備
-
上記データをダウンロード
-
jupyter 環境用意して、データ(database.sqlite) をjupyter のカレントディレクトリにおく。
-
jupyter の環境は、colaboratory につくると便利です。その時、データはgoogle drive におくと便利です。参考はこちら
-
google のアカウントがあるのは、すみません。前提にしています。
-
sql,python,pandas,jupyter ぐらいできないとまずいと思っているなら、ぜひがんばって準備で環境ととのえてみてください。
jupyter はじめ
最初に、使うものを import しています。sqlite3 がはいっていなかったら、
sudo apt install sqlite3 でインストールしておきましょう。
import os,sys,re
import sqlite3
import pandas as pd
import pandas.io.sql as psql
import matplotlib
import matplotlib.pyplot as plt
db ='database.sqlite'
conn = sqlite3.connect(db)
# mysql での desc table名 相当
desc = 'PRAGMA table_info([{table}])'
# mysql での show tables
show_tables = "select tbl_name from sqlite_master where type = 'table'"
次は、日本からの輸出額のランキングを、2014(古いですね...)のデータから抽出してグラフにします。このグラフはいくらでもあるので、つまらないですが、練習と思ってください。
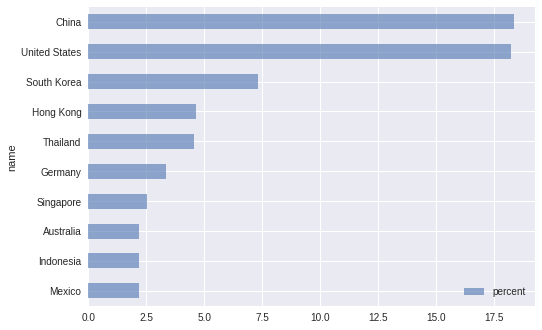
# ある国(origin)からの輸出の相手国別(dest)ランキング
# 日本(jpn) を指定
country='jpn'
# まず合計を計算する
# sql 文
sql="""
select sum(export_val) as total
from hs07_2014
where origin = '{country}'
"""[1:-1]
# 上記のSQL文の意味
# sum(export_val) as total 輸出金額を合計して、項目 total に格納
# 輸出元をcountryで指定(例えば、country='jpn'で日本に指定)
# 2014年の多国間貿易統計(hs07_2014)から、輸出額を抜き出して合計する
# sql 実行
all = pd.read_sql(sql.format(country=country),conn)['total'].iloc[0]
# pd.read_sql(sql文(sql...),データベース接続(conn))
# 合計額を、all という変数に格納します。
# sql の、{country} 部分は、実行するときに、変数 country に置換されます。
# それが、sql.format(country=country) の部分
# ['total'].iloc[0] は、結果が項目(total)と行(最初の行なので、0)を指定
# 合計を表示
print(all)
sql="""
select sum(export_val) as total,dest,c.name
from hs07_2014 h,country_names c
where h.dest = c.id_3char and
origin = '{country}'
group by dest
order by total desc
"""[1:-1]
# 詳しくはのちほど書きますが、輸出金額を輸出先の国別ごとに集計しています。
# 集計実行
df = pd.read_sql(sql.format(country=country),conn)
# 合計をつかって、percentの項目を追加
df['percent'] = 100*(df['total']/all)
# index に国名(name) をいれて、グラフの項目にします。
df.index = df['name']
# 最初の10つを抽出してグラフにします。
df[['name','percent']].head(10).sort_values('percent',ascending=True).plot.barh(alpha=0.6)
読み取れること
中国、アメリカが日本の主要な輸出先(当たり前ですね。)