豚肉輸入からわかる貿易協定の影響(すみません。記事古いです。できるだけ早く変更します。)
kaggle の学び合う会 #貿易統計 に続く個別課題です。kaggle の notebook に続けて書いてたのですが、長くて使いずらいので、qiita に切り出すようにしました。
豚肉(HS4 0203) をカナダ、アメリカで比較します。TPPでカナダが伸びましたが、アメリカも貿易協定を日本と結んだので、2020年1月は逆転しています。下記のセルで、そのデータを集計していきます。『これから先は、個別の課題を扱います』以下に下記のセルを順に作成して、実行します。
課題用の一時テーブルをつくり、計算負荷を減らします。
# 計算負荷を減らすために先に 豚肉全体(0203) 輸入(import) を年のテーブル(year_from_1997)から作成する
# 作成する一時テーブル名は、y_hs_0203_import
# 一時テーブルがあったときは、削除するのが、次の try ~ except までです。
#
try:
cursor.execute('drop table y_hs_0203_import')
except:
pass
# 条件 HS4 豚肉 hs4 = '0203' 輸入 exp_imp=2 で、year_from_1997 からデータを抽出
# 複数行にわたるので、ヒヤドキュメントという記述方法つかっています。""" から、""" までを
# sql に格納します。最後にある[1:-1]は、最初の行と最後の行を除くためです。
sql="""
create table y_hs_0203_import
as select Year,hs9,hs6,Country,Value
from year_from_1997
where
exp_imp=2 and
hs4 = '0203'
"""[1:-1]
cursor.execute(sql)
年、年月の時系列で、2つの系列の比較をする関数。具体的には、アメリカとカナダの比較
# 2か国比較用の関数 sql 以下は、規定値 実際に使うときは、適宜規定値を変えてください。
def graph_c2(sql,period='Year',last_p='2019',c2=[['302','Canada','r'],['304','USA','b']]):
# pandas というpython のデータ形式に、sql の実行結果を格納します。
df = pd.read_sql(sql,conn)
# グラフで表示がわかりやすくなるために、名前を付与
df['name'] = ''
# Country が数字型になっているので、変換しておきます。(データ作成のミスなんでそのうち元データ修正します)
df['Country'] = df['Country'].astype('str')
df.loc[df['Country'] == c2[0][0], 'name'] = c2[0][1]
df.loc[df['Country'] == c2[1][0], 'name'] = c2[1][1]
# グラフ作成
plt.figure(figsize=(20, 10))
ax = sns.lineplot(x=period,y='Value',hue='name',
data=df,linewidth=7.0,
palette={c2[0][1]: c2[0][2] ,c2[1][1]: c2[1][2]})
# 年,年月が途中で省略されないため
ax.xaxis.set_major_locator(ticker.MultipleLocator(1))
# sql からつくられたデータフレームを返り値にします。
return(df)
sql テンプレート
# sql 文のテンプレート カナダ(302) アメリカ(304) を 比較 変数は、hsコードの部分 {w}がそれです。
# sql_tmpl は、同じ名前をつかいまわしているので注意が必要です。
# 最終的な表示のの指定は、規定値をつかいできるだけ簡単にするのがいいと思っての運用です。
# どういった運用がいいかは人によって判断が異なりますので、適宜変更をしてください。
sql_tmpl="""
select ym,Country,sum(Value) as Value
from ym_2018_2020
where {w} and
exp_imp = 2 and
Country in ('302','304')
group by ym,Country
"""[1:-1]
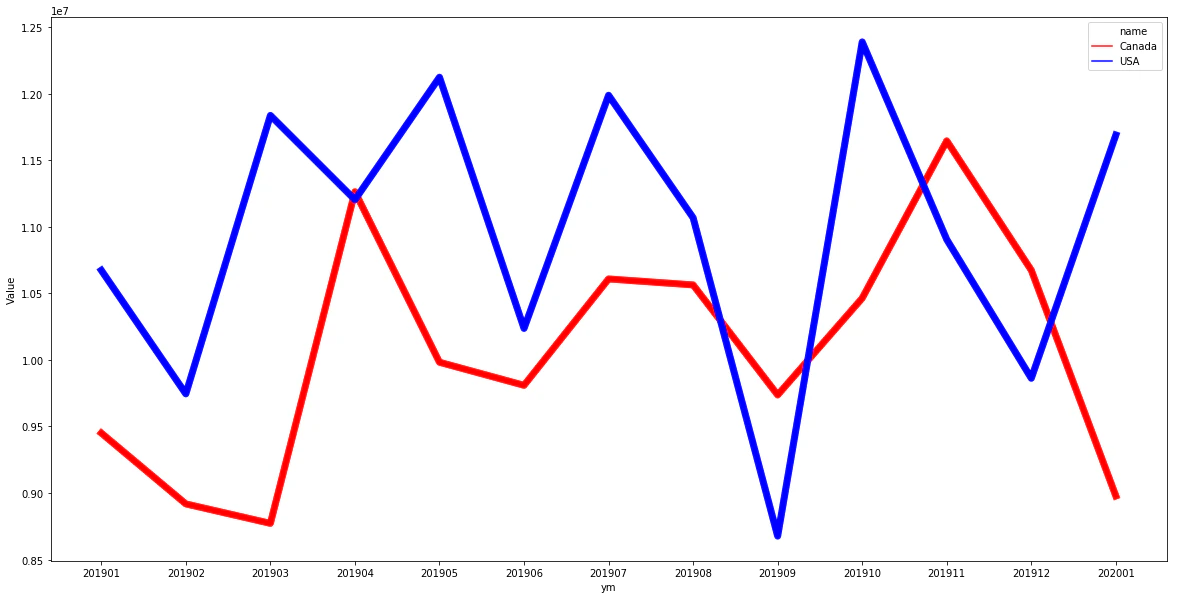
2018/01 - 2020/01 の豚肉全体(0203) の金額ベースでのアメリカとカナダの比較をグラフで表示です。結構月による変動があります。2020/01 は、アメリカに逆転されています。
# 年月で、豚全体の比較です。USA が逆転です。
w = "hs4='0203'"
sql = sql_tmpl.format(w=w)
df = graph_c2(sql,'ym','202001')
# 次の df をコメントアウトすると,データフレームの内容表示が抑制されます。
# エクセルにコピペして使う場合は、
# df
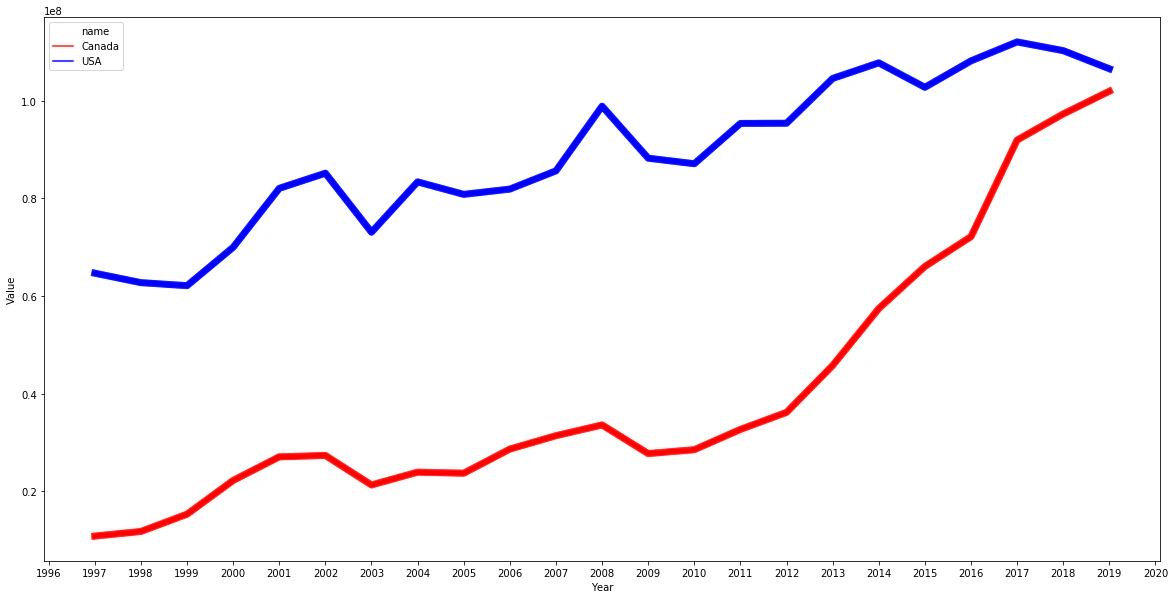
1997-2019 の豚肉(0203)の比較 アメリカが落ちているというより、カナダが伸びている感じですね。
# 豚肉 全体を年で比較します。
sql="""
select Year,Country,sum(Value) as Value
from y_hs_0203_import
where Country in ('302','304')
group by Year,Country
"""[1:-1]
df = graph_c2(sql)

HS4 0203 を、HS6 に分けて集計
sql="""
select hs6,sum(Value) as Value
from y_hs_0203_import
where Year = 2019
group by hs6
order by Value desc
"""[1:-1]
df = pd.read_sql(sql,conn)
# Markdown 用の出力
print(tabulate(df.head(10), tablefmt="pipe", headers="keys"))
冷凍: 020329 冷蔵: 020319 アメリカ、カナダ以外には、冷凍が多いです。
| hs6 | Value | |
|---|---|---|
| 0 | 020329 | 289447198 |
| 1 | 020319 | 214100663 |
| 2 | 020322 | 953476 |
| 3 | 020312 | 558767 |
| 4 | 020321 | 16022 |
| 5 | 020311 | 468 |
sql テンプレート切り替え、HSコード指定ができるようにします。
# sql 文のテンプレートを切り替えます。
sql_tmpl="""
select Year,Country,sum(Value) as Value
from y_hs_0203_import
where {w} and
Country in ('302','304')
group by Year,Country
"""[1:-1]
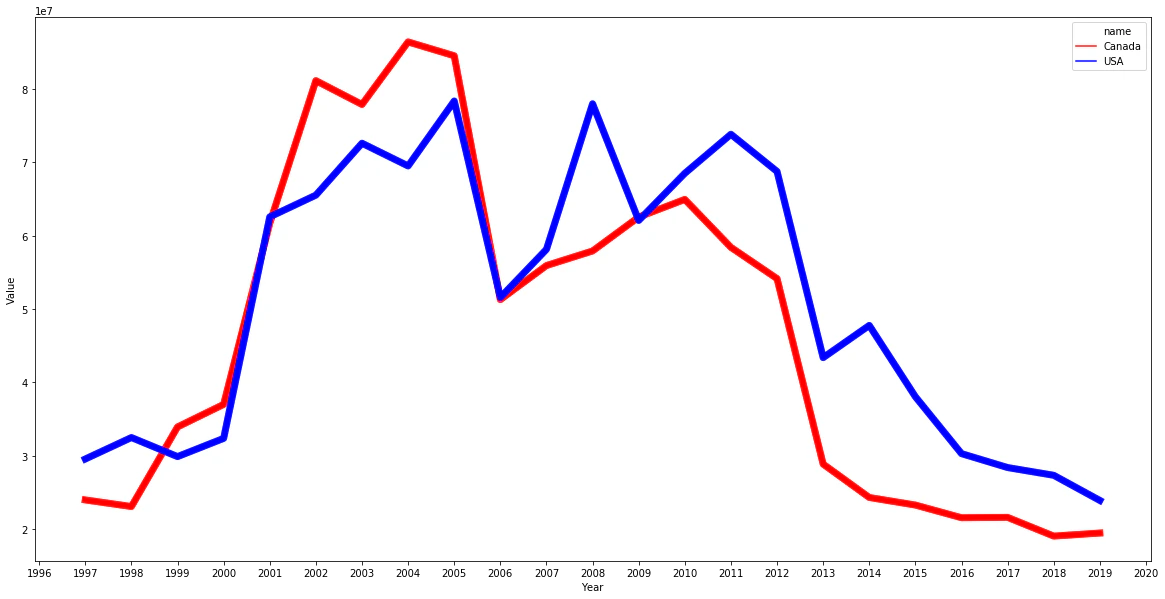
冷蔵 カナダは、TPP以前から伸びています。なぜでしょうか
# 冷蔵
w = "hs6 = '020319'"
sql = sql_tmpl.format(w=w)
df = graph_c2(sql)
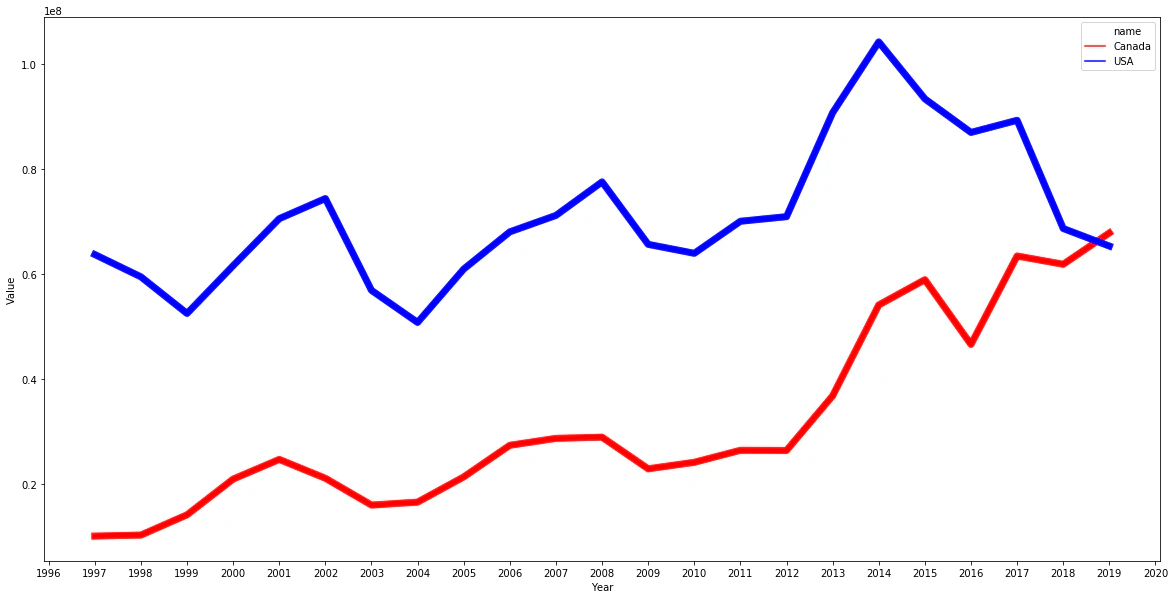
冷凍 減っています。なぜなんでしょう。
# 冷凍 減っています。
w = "hs6 = '020329'"
sql = sql_tmpl.format(w=w)
df = graph_c2(sql)
HS9 020319022 (冷蔵のHS9 で一番多い)で、カナダ、アメリカを比較
# Canada と USA の比較 1997-2019 冷蔵のうち一番分量の多い 020319022 のグラフ
w = "hs9='020319022'"
sql = sql_tmpl.format(w=w)
df = graph_c2(sql)
豚肉の国別ランキング(2019)
# 豚肉の輸入国ランキング 2019 y_hs_0203 から、集計
sql="""
select Country,sum(Value) as Value
from y_hs_0203_import
where Year = 2019
group by Country
order by Value desc
"""[1:-1]
# 国名をつけ加えるところは、pandas
df= pd.read_sql(sql,conn)
df['Country']=df['Country'].apply(str)
df = pd.merge(df,country_eng_df,on='Country')
print(tabulate(df.head(10), tablefmt="pipe", headers="keys"))
| Country | Value | Country_name | Area | |
|---|---|---|---|---|
| 0 | 304 | 130701952 | United_States_of_America | North_America |
| 1 | 302 | 121883537 | Canada | North_America |
| 2 | 218 | 64817019 | Spain | Western_Europe |
| 3 | 204 | 58695740 | Denmark | Western_Europe |
| 4 | 305 | 53588273 | Mexico | Middle_and_South_America |
| 5 | 207 | 17734471 | Netherlands | Western_Europe |
| 6 | 409 | 14548203 | Chile | Middle_and_South_America |
| 7 | 213 | 13747683 | Germany | Western_Europe |
| 8 | 210 | 8453213 | France | Western_Europe |
| 9 | 220 | 6686972 | Italy | Western_Europe |
まとめ
- TPPで、カナダは日本市場でシェアを取りました。これからは、アメリカがどのくらいもりかえせるか?
- 冷凍肉のスペインも今後のびそうですね。デンマーク、メキシコもスペインと横並びといってよいです。