#はじめに
職場を出た際に、スマホから自動でツイートする機能はできましたので、
次は職場の最寄り駅の発車時刻や遅延情報を表示したいです。
そうすれば、時間があるから寄り道しようとか、時間がないからすたすた歩こうとかできますよね。
時刻表を取得するAPIに、「駅すぱあとWebサービス」がありますが、有料です。
「駅すぱあとWebサービス」
https://docs.ekispert.com/v1/
それでは自分で作ればいいじゃないかと思い、色々調べたところ、興味深い記事が出てきました。
ブログ「入鋏省略」:時刻表スクレイピングツールに対する考え
https://nkth.info/blog/dia_scraping/
サーバに負担をかけずに時刻表情報を抽出し、個人利用する分には問題ないそうです。
よって、スクレイピングによって、時刻表と遅延情報を取得して行きます。
私は京急線で通勤しているので、今回は京急線に絞っていきます。
本記事では、スクレイピングによって京急線の発車時刻と遅延情報を取得します。
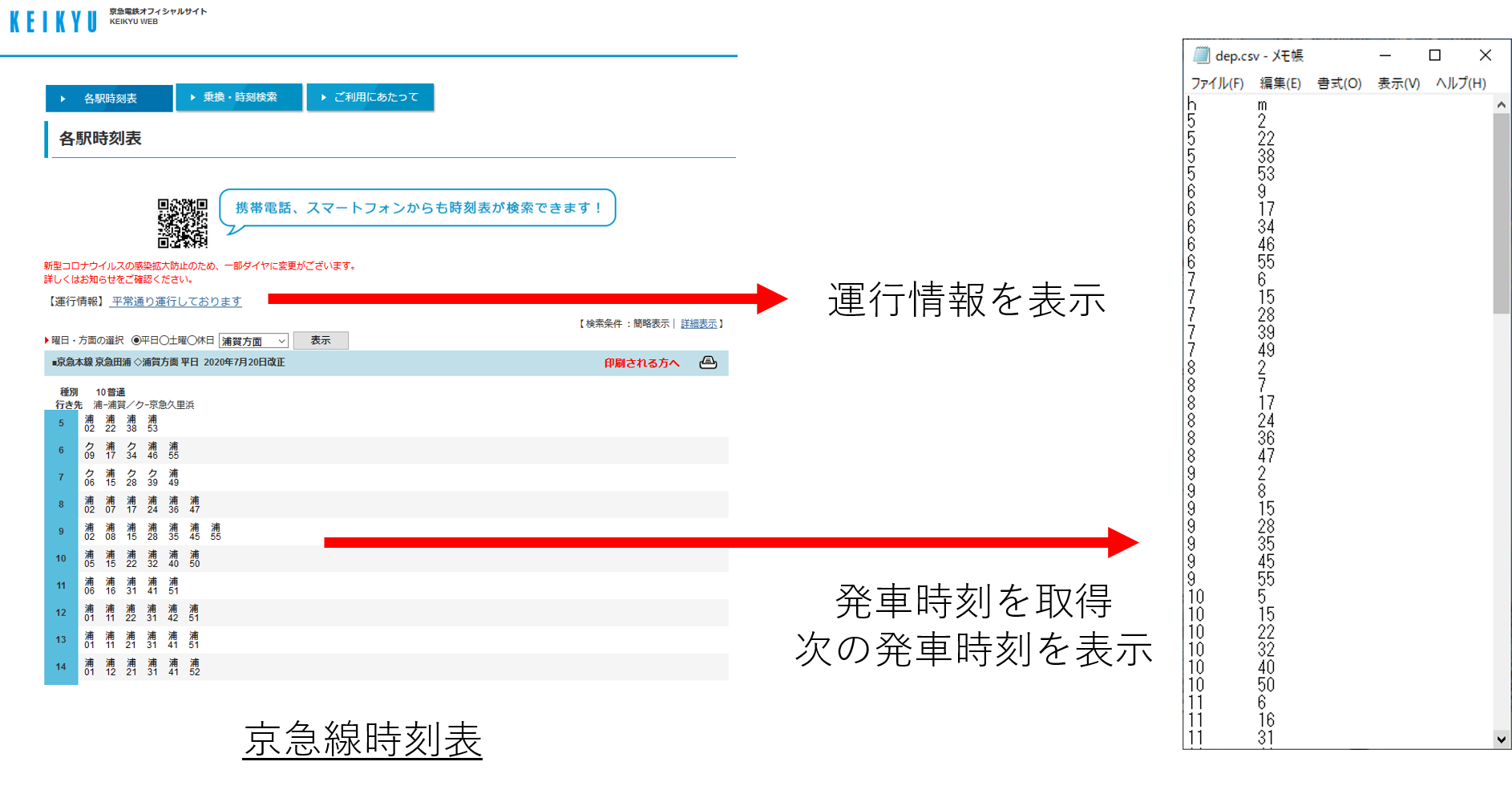
本記事の目指すことろ↑
#想定と実行環境
今回の想定は下記のとおりです。
使用鉄道路線:京急本線
職場最寄り駅:黄金町駅(私の住所とは一切関係ありません。)
使用列車:普通列車下り
実行環境:
Ubuntu18.04LTS(将来的にはAndroidかAWSを想定)
Python 3.6.9
#環境構築
スクレイピング用で有名なライブラリにbeautifulsoupがあります。
Code Zine:PythonでHTMLを解析してデータ収集してみる? スクレイピングが最初からわかる『Python 2年生』
https://codezine.jp/article/detail/12230
しかし、京急線時刻表の場合、beautifulsoupではうまく取得できません。
試しにbeautifulsoupで取得したデータは下記のとおりです。
<html>
<head>
<title>京急本線:京急田浦駅時刻表</title>
<meta content="max-age=1" http-equiv="Cache-Control"/>
</head>
<body>
★検索結果<br/>
京急本線<br/>
京急田浦駅時刻表<br/>
浦賀方面<br/>
平日のダイヤ<br/>
23:04 浦賀 <font color="#000000">普通</font><br/>
23:17 浦賀 <font color="#000000">普通</font><br/>
23:27 浦賀 <font color="#000000">普通</font><br/>
23:40 浦賀 <font color="#000000">普通</font><br/>
23:52 浦賀 <font color="#000000">普通</font><br/>
0:04 浦賀 <font color="#000000">普通</font><br/>
0:23 浦賀 <font color="#000000">普通</font><br/>
2020/7/20現在<br/>
<hr/>
<a href="T5?uid=27329&dir=38&path=2020102623438741&slCode=250-40&time=2125&d=2&dw=0&date=&pFlg=2&reFlg=0&USR=IM">↑前時間</a><br/>
<a accesskey="1" href="T3?uid=27329&dir=38&path=2020102623438741&sf=%8B%9E%8B%7D%93%63%89%59&sfCode=2053&slCode=250-40&d=2&time=2300&dw=0&USR=IM">1.方面/時刻選択へ</a><br/>
<hr width="80%"/>
全国の駅の時刻表は<a href="http://1069.jp/">駅探★時刻表</a>へ<hr width="80%"/>
<a accesskey="8" href="/transit/norikae/T1?USR=IM&sf=%8B%9E%8B%7D%93%63%89%59">8.駅の時刻表トップ</a><br/>
<a accesskey="9" href="http://www.keikyu.co.jp/m/index.html">9.トップへ</a><br/>
<center>(C)KEIKYU</center>
</body>
</html>
ダイヤが一部しか表示されません。
これは京急のWebサーバはブラウザが描画するための情報しか送っておらず、
ブラウザで見える情報≠サーバから帰ってきたデータ
だそうです。
GAMMASOFT:requestsで取得できないWebページをスクレイピングする方法
https://gammasoft.jp/blog/how-to-download-web-page-created-javascript/
そこで、上記記事のとおり、「requests-html」を使用して、ブラウザが処理した後のページ情報を取得します。
下記コマンドを入力し、「requests-html」をインストールします。
$ pip install requests #requests-htmlの依存ライブラリ
$ pip install requests-html
サンプルファイルを改造し、京急線の時刻表で、黄金町駅、普通下りのURLを指定、ブラウザで処理したのちにソースを取得します。
from requests_html import HTMLSession
url = "https://norikae.keikyu.co.jp/transit/norikae/T5?uid=34683&dir=7&path=202010272317801&USR=PC&dw=0&slCode=250-28&d=2&rsf=%89%A9%8B%E0%92%AC"
#京急線 黄金町駅 下り普通のURL
# セッション開始
session = HTMLSession()
r = session.get(url)
# ブラウザエンジンでHTMLを生成させる
r.html.render()#ブラウザでHTMLを生成
print(r.text)#ブラウザで生成したHTMLを出力
初回起動時のみ、勝手に「chromium」がインストールされます。
$ python req.py
[W:pyppeteer.chromium_downloader] start chromium download.
Download may take a few minutes.
100%|████████████████████████████████████████████████████████| 108773488/108773488 [00:09<00:00, 11116758.16it/s]
[W:pyppeteer.chromium_downloader]
chromium download done.
無事にページ情報が出力されることを確認します。
(全部表示すると長すぎるので省略します。)
ちなみに下記コマンドだけで、平常通り運行しているか分かります。
$ python req.py | grep 運行情報 -A 1 #検索文字列「運行情報」が含まれる行と、その次の行を出力
<div style="font-size: larger;">【運行情報】<a href="https://unkou.keikyu.co.jp/?from=top" target="_blank">
平常通り運行しております
#駅テーブルの作成
駅名・曜日(平日・土曜・休日)・方面(泉岳寺・浦賀)とURLの対応表を作っていきます。
京急線時刻表のページのURLを見てみましょう。
https://norikae.keikyu.co.jp/transit/norikae/T5?uid=6403&dir=18&path=20201029203818692&USR=PC&dw=0&slCode=250-28&d=2&rsf=%89%A9%8B%E0%92%AC
色んなURLパラメータが存在しますが、このうち必須のパラメータは、
・dw(曜日:Day of the weekの略? 0が普通、1が土曜、2が休日)
・slCode(駅のユニークコード:250-00(品川)から)
・d(方面:Directionの略?1が上り、2が下り)
だけでした。
よって、上記のURLでアクセスできるページは、
https://norikae.keikyu.co.jp/transit/norikae/T5?dw=0&slCode=250-28&d=2
と同じです。
すっきりしました。
これぐらいであればプログラミングを簡単そうです。
ちなみに、羽田空港のslCode(253-7)は欠番でした。
#実 装
やっとページ情報が取得できたので、スクレイピングしていきます。
下記プログラムを作成します。
詳細はコメントを見てください。
git-hubでも本プログラム(keikyu_futsu.py)と駅テーブルファイル(station_table.csv)あげました。
https://github.com/zakuzakuzaki/zaki-aws/blob/main/station/koganecho.py
from requests_html import HTMLSession #スクレイピング
import datetime #現在時刻の取得
import csv #csvファイルの読み込み
import sys #コマンドライン引数、プログラム終了
def get_info(st, r):
#改行単位でsplit
#参考URL:https://karupoimou.hatenablog.com/entry/2019/07/08/112734
page = r.text.split("\n")
for i in range(len(page)):
p = page[i]
if "運行情報" in p:
unko = page[i+1]#「運行情報」文字列の次の行に内容が書いてある.
return st +"駅は"+ unko
def get_timetable(r):
#時刻表(時間)を取得
hour = r.html.find(".side01")#平日
if len(hour)==0:
hour = r.html.find(".side02")#平日以外
hour_list = []
for h in hour:
hour_list.append(int(h.text))
train = hour_list[0]#始発時間を取得
#時刻表(分)を取得
minute = r.html.find(".min1001")#普通列車のclass
minute_list = []
for m in minute:
minute_list.append(int(m.text))
del minute_list[0]#最初と最後の要素は時刻ではないので削除
del minute_list[-1]#同上
#時刻表を格納するための2次元配列の初期化
num = len(minute_list)
dep = [[0 for i in range(2)] for j in range(num)]
#時刻表の構築作業
for i in range(num):
if i>0 and minute_list[i-1] > minute_list[i]:
train+=1
dep[i] = (train, minute_list[i])
return dep
def echo_dep(dep, time):
#指定時刻から先の3つの発車時刻を格納するため配列の定義
dep_time = []
#現在時刻から最も近い発車時刻を取得
next=0
now_i=0
num = len(dep)
for i in range(num):#始発電車から1つずつ探していく.
if dep[i][0]==time.hour:#現在時刻(時間)と比較
now_i = i
if dep[i][1]>time.minute:#現在時刻(分)と比較
next = i
break
if next==0:#分がHitしなかった場合の処理(時間を繰り上げ)
next=now_i+1
#表示用リストの作成
for i in range(3):
if next+i>=num:
next = -1
dep_time.append("〜終電〜")
dep_time.append(str(dep[next+i][0]).zfill(2)+":"+str(dep[next+i][1]).zfill(2))
return dep_time
def get_url(st , dir, dw):
#パラメータslCodeの作成
#参考:https://note.nkmk.me/python-csv-reader-writer/
with open('station_table.csv') as f:
reader = csv.reader(f)
l = [row for row in reader]
num = len(l)
for i in range(num):
if l[i][0]==st:#駅名で検索
slCode = l[i][1]
if i==l:
print("エラー:不明な駅名です.")
sys.exit(1)
#パラメータd,dwはそのまま
return "https://norikae.keikyu.co.jp/transit/norikae/T5?dw="+dw+"&slCode="+slCode+"&d="+dir
if __name__ == '__main__':
if len(sys.argv) != 4:
print("次のコマンドライン引数を与えてください.\n1->駅名(日本語),2->上り:1,下り:2,3->平日:0,土曜:1,休日:2")
sys.exit(1)
url = get_url(sys.argv[1], sys.argv[2], sys.argv[3])
#①駅名(日本語),②上り:1,下り:2,③平日:0,土曜:1,休日:2
# セッション開始
session = HTMLSession()
r = session.get(url)
# ブラウザエンジンでHTMLを生成させる
r.html.render()
#運行情報を取得
info = get_info(sys.argv[1],r)
#時刻表を取得
dep = get_timetable(r)
#現在時刻を取得
#参考URL:https://note.nkmk.me/python-datetime-now-today/
time = datetime.datetime.now()
#次の発車時刻を取得
dep_time = echo_dep(dep, time)
#結果出力
print("今日もおつかれさまでした.")
print(info)
print("次の発車は,")
[print(i) for i in dep_time]
sys.exit(0)
上記プログラムは下記記事を参考に参考しました。
・文字列抽出
なろう分析記録:【Pythonサンプルコード】スクレイピングで「特定の文字列を含む行」だけを抽出したい時の簡単な方法を解説
https://karupoimou.hatenablog.com/entry/2019/07/08/112734
note.nkmk.me:Pythonで文字列を抽出(位置・文字数、正規表現)
https://note.nkmk.me/python-str-extract/
・現在時刻を取得
note.nkmk.me:Pythonで現在時刻・日付・日時を取得
https://note.nkmk.me/python-datetime-now-today/
・csvファイル読み込み
note.nkmk.me:PythonでCSVファイルを読み込み・書き込み(入力・出力)
https://note.nkmk.me/python-csv-reader-writer/
#テスト
実行結果は下記の通りです。
$ python keikyu.py 黄金町 2 1 #「黄金町・下り・平日」を指定
今日もおつかれさまでした.
黄金町駅は平常通り運行しております
次の発車は,
22:12
22:22
22:30
無事、運行状況と次の列車の発車時間を表示させることができました。
駅名等を変えても正常に動作することを確認しました。
#おわりに
退社時を想定して、職場の最寄り駅の発車時刻と遅延情報を表示できました。
はじめてスクレイピングしましたが、結構楽しいですね。
ただ、pythonコードが汚いので、もう少し綺麗にできたらいいなと思います。
ちなみに今回は普通列車のみでしたが、抽出するclassを変更すれば、他の列車でも対応可能です。
複数列車の指定が時間かかりそうだったので、今回はパスしました。
<span class="syasyu1004"><span class="min1004">10</span>快特</span>
<span class="syasyu1003"><span class="min1003">10</span>特急</span>
<span class="syasyu1010"><span class="min1010">10</span>エアポート急行</span>
<span class="syasyu1001"><span class="min1001">10</span>普通</span>
上記ページのURL(横浜駅浦賀方面時刻表)
https://norikae.keikyu.co.jp/transit/norikae/T5?uid=22537&dir=34&path=2020102723533416&USR=PC&dw=0&slCode=250-25&d=2&rsf=%89%A1%95%6C