前回の記事でコメントいただいたので。
こんな感じになる。
前回はランダムでルーン文字に置換しただけだったけど、今回のは頑張ればちゃんと読める。
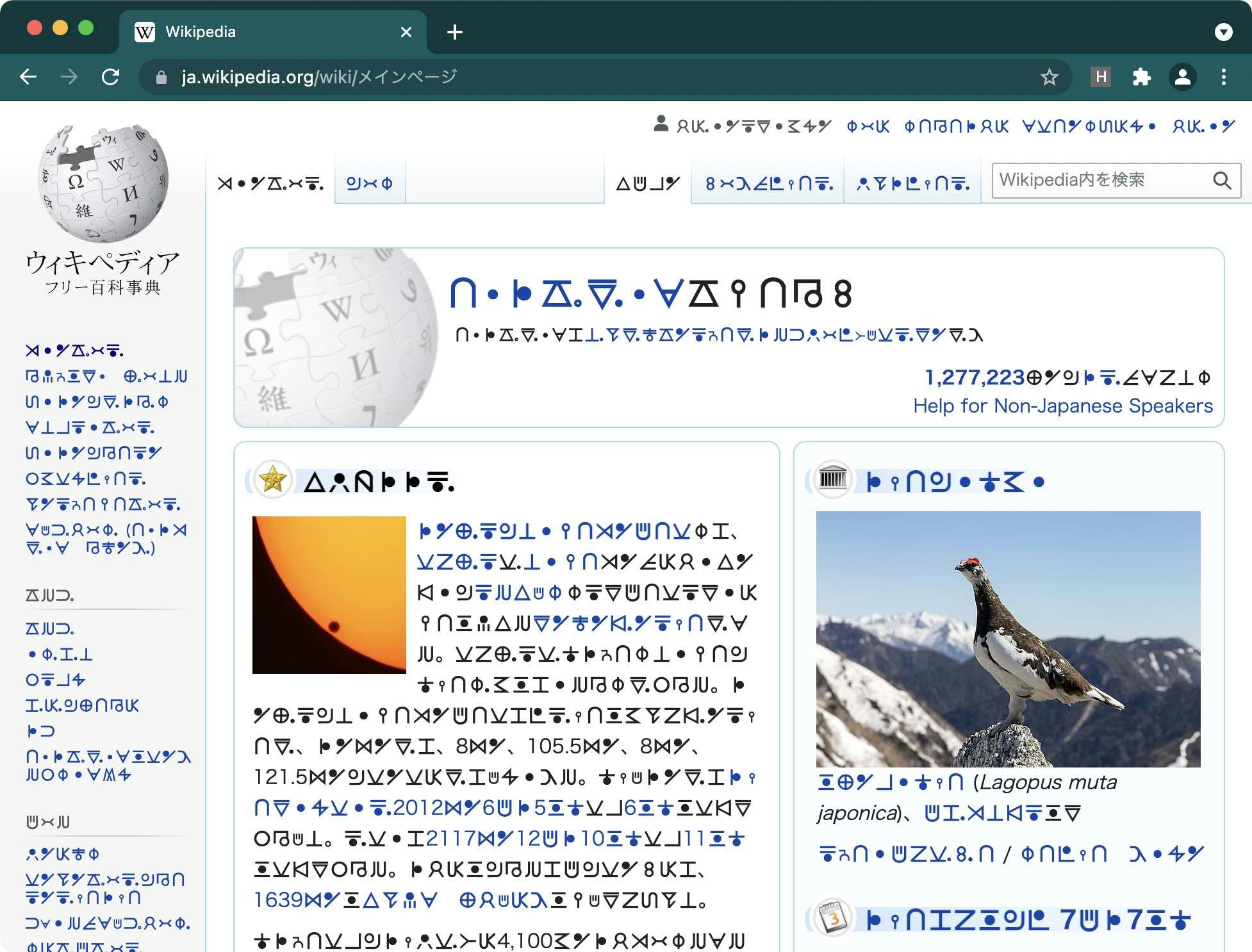
前回の記事のものを改造していきます。
どうすりゃいいの?
- Chrome拡張からフォントを読み込ませる
- 漢字を読み仮名に変換
- 半角カタカナ→全角カタカナ
- カタカナだけspanで囲んでフォント適用
ハンター文字 is 何
まずそもそもハンター文字とは何か。
休載記録更新中の伝説のマンガ、HUNTERxHUNTERで使われてる字体。
五十音を表現可能。
ここで見てもらった方が早い。
ハンター文字のフォントを使う
こちらのサイトでフォントをダウンロードできる。
ひらがな・カタカナで同じ文字が表示される。半角カタカナは無理。
ダウンロードして適当なフォルダにぶち込んでおく。
ここではvendorという名前にした。
今のフォルダ構造はこんな感じ。
- manifest.json
- isekai.js
- vendor/
- hunter.ttf
で、閲覧中のページ側からこのフォントをダウンロード可能にしなければいけない。
manifest.jsonのweb_accessible_resourcesを指定すれば可能。
manifest.jsonに以下を追加する。
"web_accessible_resources": [
{
"matches": ["<all_urls>"],
"resources": ["vendor/*"]
}
]
これで、ページ側からvendor以下のファイルをダウンロード可能になった。
CSSを挿入すればフォントを使える。
chrome.action.onClicked.addListener((tab) => {
const fontURL = chrome.runtime.getURL("vendor/hunter.ttf");
const css = `
@font-face {
font-family: "HunterFont";
src: url("${fontURL}");
}`;
const target = { tabId: tab.id, allFrames: true };
chrome.scripting.insertCSS({ target, css });
});
漢字の読み仮名を取得 (kuromoji.js)
読み仮名を取得できるAPIとかあるけど、1ページみるごとに何千回も通信してらんない。
kuromoji.jsで読み仮名を取得する。
↑このページからbuild/kuromoji.jsと、dict/フォルダまるごとをダウンロードする。
そしてvendorにぶち込む。今のフォルダ構造。
- manifest.json
- isekai.js
- vendor/
- hunter.ttf
- kuromoji.js
- dict/
- *.dat.gz
これらもページ側からダウンロード可能にしておかなければならない。
既にvendor/以下を指定済みなので問題ない。
こんな感じで使える。
(manifest.jsonでcontent_scriptsから読み込ませてもいいんだけど、毎回実行するわけじゃないしページ開くたびに使わないjs読み込むのは嫌だったからdynamic importにした)
(async () => {
const jsPath = chrome.runtime.getURL("vendor/kuromoji.js");
const dicPath = chrome.runtime.getURL("vendor/dict");
// kuromoji.jsをグローバルに読み込み
await import(jsPath);
const getTokenizer = () =>
new Promise((res) =>
kuromoji.builder({ dicPath }).build((_, tokenizer) => res(tokenizer))
);
const tokenizer = await getTokenizer();
const getYomigana = (str) =>
tokenizer.tokenize(str).map((token) =>
token.reading ?? token.surface_form
).join("");
console.log(getYomigana("処刑用BGM")); // ショケイヨウBGM
})();
半角カタカナ→全角カタカナ
今回のフォントは半角カタカナを表示できないので、全角カタカナに変換する。
// 全角カタカナ
const first = "ァ".codePointAt();
const last = "ー".codePointAt();
const pts = [...Array(last - first + 1).keys()].map((i) => i + first);
const zen = [...String.fromCodePoint(...pts)];
// 全角カタカナに対応する半角カタカナ
const han =
"ァアィイゥウェエォオカガキギクグケゲコゴサザシジスズセゼソゾタダチヂッツヅテデトドナニヌネノハバパヒビピフブプヘベペホボポマミムメモャヤュユョヨラリルレロヮワヰヱヲンヴヵヶヷヸヹヺ・ー"
.match(/.[゙゚]?/g);
// 半角カタカナ→全角カタカナの連想配列
const keysAndValues = zen.map((z, i) => [han[i], z]);
const dict = Object.fromEntries(keysAndValues);
// 半角カタカナ→全角カタカナにする関数
const rex = /[ヲ-ン][゙゚]?/g;
const rep = (c) => dict[c] ?? c;
const toZenKana = (str) => str.replace(rex, rep);
console.log(toZenKana("アカネチャンカワイイヤッター")) // アカネチャンカワイイヤッター
カタカナだけspanで囲む
今回のフォントは五十音以外の文字が表示されない。
カタカナだけspanタグに入れてフォントを適用する。
targetNodes.forEach((node) => {
// 文字列をカタカナに変換
let str = node.nodeValue;
str = toZenKana(str);
str = getYomigana(str);
// カタカナだけspanで囲む
const kana = str.match(/[ァ-ー]+/g);
const kanaJanai = str.split(/[ァ-ー]+/g);
const nodes = kanaJanai.flatMap((str, i) => {
if (kana[i]) {
const span = document.createElement("span");
span.textContent = kana[i];
span.style.fontFamily = "HunterFont";
return [str, span];
} else {
return str;
}
});
// nodeを置換
node.replaceWith(...nodes);
});
完成
全部合わせたらこんな感じ。
力尽きたから説明しないけどテキストノードの取得はdocument.createTreeWalkerにした。
"use strict";
async function tensei() {
// 半角カタカナ → 全角カタカナ
const toZenKana = (() => {
// 全角カタカナ
const first = "ァ".codePointAt();
const last = "ー".codePointAt();
const pts = [...Array(last - first + 1).keys()].map((i) => i + first);
const zen = [...String.fromCodePoint(...pts)];
// 全角カタカナに対応する半角カタカナ
const han =
"ァアィイゥウェエォオカガキギクグケゲコゴサザシジスズセゼソゾタダチヂッツヅテデトドナニヌネノハバパヒビピフブプヘベペホボポマミムメモャヤュユョヨラリルレロヮワヰヱヲンヴヵヶヷヸヹヺ・ー"
.match(/.[゙゚]?/g);
// 半角カタカナ→全角カタカナの連想配列
const keysAndValues = zen.map((z, i) => [han[i], z]);
const dict = Object.fromEntries(keysAndValues);
// 半角カタカナ→全角カタカナにする関数を返す
const rex = /[ヲ-ン][゙゚]?/g;
const rep = (c) => dict[c] ?? c;
// 半角カタカナ → 全角カタカナ
const toZenKana = (str) => str.replace(rex, rep);
return toZenKana;
})();
// ヨミガナを取得する関数 (kuromoji.js)
const getYomigana = await (async () => {
const jsPath = chrome.runtime.getURL("vendor/kuromoji.js");
const dicPath = chrome.runtime.getURL("vendor/dict");
// kuromoji.jsをグローバルに読み込み(content_scripts側のグローバルに読み込まれる)
await import(jsPath);
const getTokenizer = () =>
new Promise((res) =>
kuromoji.builder({ dicPath }).build((_, tokenizer) => res(tokenizer))
);
const tokenizer = await getTokenizer();
const getYomigana = (str) =>
tokenizer.tokenize(str).map((token) =>
token.reading ?? token.surface_form
).join("");
return getYomigana;
})();
// 対象となるテキストノードのみを取得するジェネレータ
function* getTargetNodes() {
const acceptNode = (node) => {
// 親がヤバいやつは除外
if (/script|style/i.test(node.parentNode.nodeName)) {
return NodeFilter.FILTER_REJECT;
}
// 日本語を含むやつのみ取得
if (/[\p{sc=Hira}\p{sc=Kana}\p{sc=Han}]/u.test(node.nodeValue)) {
return NodeFilter.FILTER_ACCEPT;
}
};
const walker = document.createTreeWalker(
document.body,
NodeFilter.SHOW_TEXT,
{ acceptNode },
);
// ノードがなくなるまでcurrentNodeを返す
while (walker.nextNode()) yield walker.currentNode;
}
// nodeを書き換えながら処理すると次のnodeを読んでくれなくなるので、一旦配列に格納
const targetNodes = [...getTargetNodes()];
// 置換
targetNodes.forEach((node) => {
// 文字列をカタカナに変換
let str = node.nodeValue;
str = toZenKana(str);
str = getYomigana(str);
// カタカナだけspanで囲む
const kana = str.match(/[ァ-ー]+/g);
const kanaJanai = str.split(/[ァ-ー]+/g);
const nodes = kanaJanai.flatMap((str, i) => {
if (kana[i]) {
const span = document.createElement("span");
span.textContent = kana[i];
span.style.fontFamily = "HunterFont";
return [str, span];
} else {
return str;
}
});
// nodeを置換
node.replaceWith(...nodes);
});
}
// 拡張のアイコンを押したら実行
chrome.action.onClicked.addListener((tab) => {
// アクティブタブでtensei関数を実行
const target = { tabId: tab.id, allFrames: true };
chrome.scripting.executeScript({ target, function: tensei });
// アクティブタブにcssを挿入
const fontURL = chrome.runtime.getURL("vendor/hunter.ttf");
const css = `@font-face {font-family: "HunterFont"; src: url("${fontURL}")}`;
chrome.scripting.insertCSS({ target, css });
});
{
"manifest_version": 3,
"version": "0.1.0",
"name": "HUNTER拡張",
"description": "Chrome拡張作ったらハンター文字しか表示されなくなった件",
"background": {
"service_worker": "isekai.js"
},
"action": {
"default_title": "ハンター文字に翻訳"
},
"permissions": ["activeTab", "scripting"],
"web_accessible_resources": [
{
"matches": ["<all_urls>"],
"resources": ["vendor/*"]
}
]
}
あ、dynamic importでkuromoji.jsを読み込んでるけど、これはタブ内のcontent scriptsのグローバルに読み込まれてるので注意。
service workerのグローバルじゃないよ。
何回も押すと何回も読み込みなおされると思うけど気にするな。
元に戻す方法は用意してない。ページを再読み込みするか、改良よろしく。
一部分だけ読みたいならコピペしてテキストエディタに貼ればOK。
とりあえず...