この記事では、BigQuery に搭載されている Query execution graphs を用いて、なんとなくクエリのパフォーマンスを最適化する方法を説明します。
ほとんどの項目が経験と憶測で書かれているので、あくまで参考程度にお願いします。
Query execution graphs とは
Query execution graphs とは、BigQuery が SQL クエリを解釈して実行計画を作成する際に生成される内部表現です。Execution graphs は、クエリの各ステップをノードとして表し、ノード間のデータフローをエッジとして表します。また、グラフを見ることで、クエリの実行順序や依存関係、並列度やリソース消費などを把握することができます。
主に以下のようなノード(ステージ)があります。
- Input: データセットからデータを読み込むノード。テーブルデータの統計情報が表示できます。
- Aggregate: 集約関数 や GROUP BY 句を適用する
- Sort: ORDER BY 句を適用する
- Compute: 式の評価や SQL 関数などのオペレーション
- Top: LIMIT 句を適用する
- Output: 結果をテーブルなどに出力する
ステージについては公式ドキュメントも参考にしてください。
クエリの記述からステージを特定する
BigQuery の中間言語は静的単一代入のような独特な記法をしています。そのため、クエリのどの部分に対応させるかがわからないかもしれません。正直、これといった方法はないのですが、ヒントとして以下のようなものがあります。
- ステージ内の FILTER に着目する:これは、WHEREやCASEなどの条件文に対応します。式に変換してみると、対応するSQLの式があらわれるので特定しやすいです。
-
greater(subtract(multiply($100,$101), multiply($100,$200)), 0)=>?*? - ?*? > 0の形をしているとわかる。
-
- 定数に着目する:文字列や定数値があれば対応する箇所を見つけやすいです。
- COMPUTEからの特定は難しいですが、特徴的な関数を使っていればわかりやすいです。
- AGGREGATE は SQL とは異なり、定義の「前」に書かれることに注意しましょう。
なお、1つのステージが1つのCTEやサブクエリに対応する、といったことは基本的にないです。1つのサブクエリが複数のステージに分かれることもありますし、まとまることもあります。
基本的に重いステージの中間表現からSQLの箇所を特定するという作業のため、なんとなくこの辺だな、というのはつかめると思います。逆(SQLからステージを特定)は割と大変です、最適化で消えていることもあります。
たとえば、以下のクエリを見てみましょう。
WITH
ob AS ( SELECT
gsod.*,
name
FROM `bigquery-public-data.noaa_gsod.gsod2023` gsod
JOIN `bigquery-public-data.noaa_gsod.stations` stations
ON gsod.stn = stations.usaf AND gsod.wban = stations.wban
WHERE
stations.country = 'JA' AND DATE(date) = CURRENT_DATE() - INTERVAL 5 day )
SELECT
DATE(date) AS date, name, MAX(temp) AS max_temp
FROM ob
GROUP BY 1, 2
ORDER BY 3 DESC
LIMIT 10
このグラフを見てみます。
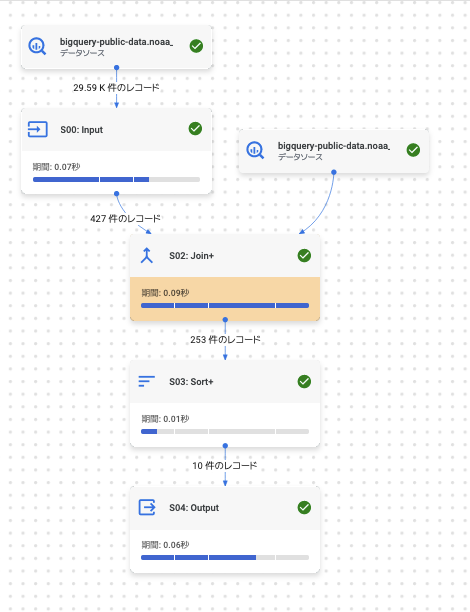
各ステージの記述はこうなっています。
S00: Input
$10:usaf, $11:wban, $12:name, $13:country
FROM bigquery-public-data.noaa_gsod.stations
WHERE equal($13, 'JA')
$10, $11, $12
TO __stage00_output
S02: Join+
$1:stn, $2:wban, $3:date, $4:temp
FROM bigquery-public-data.noaa_gsod.gsod2023
WHERE equal(CAST(date($3) AS DATETIME), 2023-11-27 00:00:00)
$10, $11, $12
FROM __stage00_output
GROUP BY $60 := $40, $61 := $52
$30 := MAX($51)
$40 := date($50)
$50 := $3, $51 := $4, $52 := $12
INNER HASH JOIN EACH WITH ALL ON $1 = $10, $2 = $11
$61, $30, $60
TO __stage02_output
BY HASH($60, $61)
S03: Sort+
$61, $30, $60
FROM __stage02_output
$20 DESC
LIMIT 10
GROUP BY $70 := $60, $71 := $61
$20 := MAX($30)
$80, $81, $82
TO __stage03_output
S04: Output
$80, $81, $82
FROM __stage03_output
$81 DESC
LIMIT 10
$90, $91, $92
TO __stage04_output
細かいところはともかく、以下のようなことがわかります。
- S00: stations から JA のみをフィルタしているので、ob の
stations.country = 'JA'の部分だな - S01: bigquery-public-data.noaa_gsod.gsod2023 から取ってきて、S01:
GROUP BYで JOIN している部分だな。 - S03: MAXをとってるから、最後のクエリの部分だな
- S04: ここで ORDER BY と LIMIT をしているな(ソート2回やってるけど…)
このようにして、だいたいのアタリを付ける作業が第一歩です。
パフォーマンスを向上させるテクニック
グラフの高さを抑えて、横に広げる
BigQueryのクエリ実行グラフにおいて、グラフが縦長に表示される場合、これは一連の処理がシーケンシャルに実行されている傾向にあることを意味します。つまりこのような場合、クエリの各ステップは、前のステップが完了するまで待機する必要があります。この場合、計算に待ちが発生してあまり効率的ではないです。
処理を分散させる観点からは、グラフは横に広くノードの終端に向かってJOINで収束していく逆ピラミッドの方が一般的には好ましいといえます。(状況によってはスロットを大量消費することやデータのシャッフルが増加することでむしろパフォーマンスは劣化する可能性もあるので、注意は必要)
以下は、ジョブステージの依存関係を分析して先端から終端までの最大長さをジョブIDごとにを計算するクエリです。これを使って、複雑なクエリを特定することができます。
CREATE TEMP FUNCTION findLongestPathLength(dependencies ARRAY<STRUCT<id INT64, stages ARRAY<INT64>>>)
RETURNS INT64
LANGUAGE js AS """
function calcDepth(node, graph, depthCache) {
if (depthCache.has(node)) return depthCache.get(node);
let maxDepth = 1;
const deps = graph.get(node) || [];
deps.forEach(dep => {
maxDepth = Math.max(maxDepth, calcDepth(dep, graph, depthCache) + 1);
});
depthCache.set(node, maxDepth);
return maxDepth;
}
const graph = new Map();
dependencies.forEach(dep => {
graph.set(dep.id, dep.stages);
});
const depthCache = new Map();
let maxPath = 0;
graph.forEach((_, node) => {
maxPath = Math.max(maxPath, calcDepth(node, graph, depthCache));
});
return maxPath;
""";
SELECT
job_id,
findLongestPathLength(ARRAY_AGG(STRUCT(job_stage.id, job_stage.input_stages AS stages)))
FROM
`region-us`.INFORMATION_SCHEMA.JOBS,
-- region は適宜書きかえ
UNNEST(job_stages) AS job_stage
WHERE DATE(creation_time) > CURRENT_DATE() - INTERVAL 1 DAY
AND job_id IN (...) -- 列挙 or 外す
GROUP BY job_id
ステージがグラフ上で分散できているかを確認する
同様の理由で、「処理別の上位のステージをハイライト表示する」したときに黄色くなっている処理が直列に並んでいるときは、そこがボトルネックになりやすいと言えます。できるだけ重い処理は並列に並んでいるほうがよいです(後述のように、パイプライン化されていたら問題ないこともあります。)
クエリ最適化ができているか確認する
たとえば次のself-joinのクエリを見てみます
WITH
joint AS (
SELECT A.user_id, B.user_id, A.value
FROM `user_access` A
JOIN `user_access` B
ON A.value = B.value )
SELECT * FROM joint WHERE BETWEEN 100 AND 200
単純に見ると、AとBのJOINを計算し、それに対してフィルタをするようなステージ構成になると思います。ただし、実際には以下のようなグラフになります。
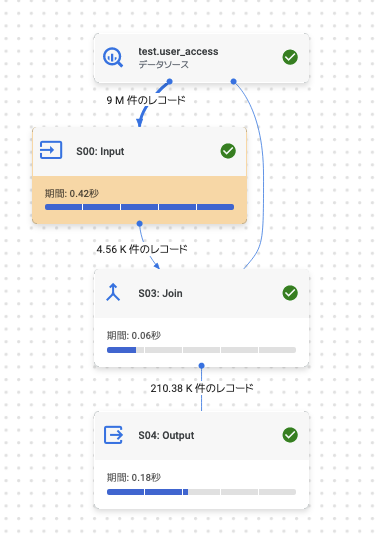
JOINする時点で9M→4.5Kとフィルタされていますね。
実際の実行計画を見てみると
S00 Input: (読み取り済みレコード: 9000000, 書き込み済みレコード: 4557)
$10:user_id, $11:value
FROM test.user_access
WHERE between($11, 100, 200)
$10, $11
TO __stage00_output
S02: Coalesce (読み取り済みレコード: 4557, 書き込み済みレコード: 4557)
FROM __stage00_output
S03: Join (読み取り済みレコード: 9410130, 書き込み済みレコード: 210377)
$1:user_id, $2:value
FROM test.user_access
WHERE between($2, 100, 200)
$10, $11
FROM __stage02_output
$20 := $1, $21 := $2, $22 := $10
INNER HASH JOIN EACH WITH ALL ON $2 = $11
$20, $21, $22
TO __stage03_output
初見だとわかりづらいかもしれませんが、SQLの記述とは違い、まず Input の時点で BETWEEN 100 AND 200 が評価され、レコードが 4557 に削減されていることがわかります。そしてその後に JOIN が行われています。
これは、このような計算が効率であるとクエリ解析エンジンが判断し条件の最適化を行なっている様子がうかがえます。
そのため、最初から最適化しようとせずに(たとえば、AとBそれぞれに事前にWHEREをした中間テーブルをつくって……のようなことをする)まずはクエリ計画を見てみるのが重要といえます。
ステージ間の転送量に着目する
上のように、ステージ間の転送量に着目することで、色々な気付きを得ることができます。
パーティションクエリができているか確認: パーティションへのクエリはパーティションフィールドに対する式の評価によって効いたり効かなかったりすることがします。それは、READから出ている量がテーブル全体か一部かによって確認ができます。
インデックスやクラスタによる最適化: 同様に、クラスタリングや最近導入されたインデックスによる最適化も確認できます。スキャン量予測で単純になんとなく確認できるパーティションと違い、こちらの最適化は実行計画を確認する必要があります。
不適切なJOINによるデータ爆発: データ転送が入力より出力の方が大きくなるのはJOINです。最終的にフィルタがされるので結果としては正しいけど、処理の途中で大量のレコードが吐きだされてしまうことがあります。通常の上記のようなクエリ最適化でなんとかなる場合が多いのですが、条件が複雑だと効かないことがあります。複雑なクエリで処理が遅い場合、多くのJOINでレコード数が爆発していることが多いので、そちらの確認が必要です。
グラフの依存関係は、実時間での依存関係ではないことに注意
クエリが依存しているからといって、前の処理を待つわけではありません。たとえば GROUP BY 〜 HAVING や QUALIFY を使わないような単純なクエリについては前ステージの終了を待たずに次のステージの処理を開始することがあります。この場合、グラフの依存関係よりも、ステージごとのstartMsやendMsを着目したほうがいいことがありあす。
以下にステージごとに可視化してみるPythonコードを示します。
import matplotlib.pyplot as plt
from google.cloud import bigquery
JOB_ID = "ジョブID"
bq = bigquery.Client(location="ロケーション")
stages = bq.get_job(JOB_ID).query_plan
# ジョブ情報を解析
labels = {}
data = []
dependency = []
for stage in stages:
stage_id = int(stage.entry_id)
data.append(
(
stage_id,
int(stage.start.timestamp() * 1000),
int(stage.end.timestamp() * 1000),
)
)
labels[stage_id] = stage.name
for i in stage.input_stages:
dependency.append((i, stage_id))
# 開始を0に合わせる
total_start = min(d[1] for d in data)
data = [(job, start_ms - total_start, end_ms - total_start) for job, start_ms, end_ms in data]
data.sort(key=lambda t: t[1])
# チャートの初期設定
fig, ax = plt.subplots()
ax.set_xlabel("Time (ms)")
ax.set_title("Job Execution Timeline")
ax.grid(False)
# y軸のラベルを非表示にする
ax.set_yticks([])
# 各ジョブの位置を保存するための辞書
positions = {}
# 各ジョブを描画し、ラベルを配置
for i, (job_id, start_ms, end_ms) in enumerate(data):
positions[job_id] = i # ジョブのインデックスを保存
print(job_id, end_ms - start_ms, start_ms)
duration = end_ms - start_ms
ax.barh(i, duration, left=start_ms, height=1)
# ラベルをバーの中央あたりに配置
job_name = labels[job_id]
ax.text(
start_ms + duration / 2,
i,
f"{job_name}: {duration} ms",
ha="center",
fontsize=5,
va="center",
color="black",
)
# 依存関係に基づいて線を描画
for dep_from, dep_to in dependency:
from_index = positions[dep_from]
to_index = positions[dep_to]
from_end_time = [end_ms for job, start_ms, end_ms in data if job == dep_from][0]
to_start_time = [start_ms for job, start_ms, end_ms in data if job == dep_to][0]
plt.plot(
[from_end_time, to_start_time],
[from_index, to_index],
color="red",
linestyle="-",
linewidth=0.5,
)
# y軸の反転を設定
ax.invert_yaxis()
# 描画を表示
plt.show()
以下のように表示されます。
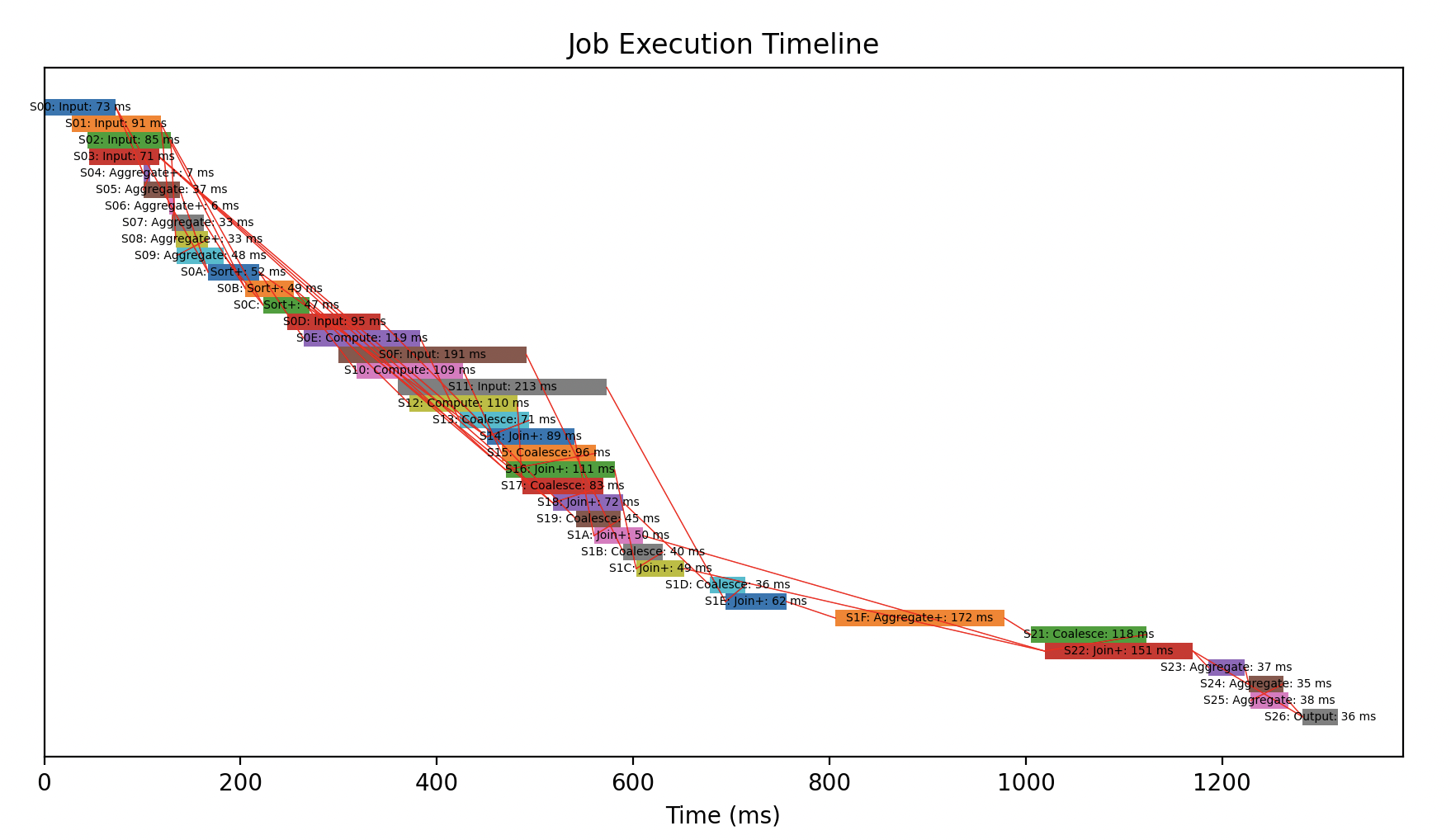
依存関係があってもジョブ自体が実行開始しているものがあるのが可視化されました。
また、これでボトルネックとなっている処理もわかります。上の例だと S1F: Aggregate+ や S22: Join+ を重点的に調査すればよいですね。
以上です。