- AIでデータ分析-ランダムフォレスト:離職に影響する変数を分析する
- 用いるデータの紹介
- AIの活用
- まとめ
AIでデータ分析-ランダムフォレスト:離職に影響する要因を分析する
このノートは、分析においてAIを使って何ができて何ができないかを検証するために、実際に試した結果をまとめたノートです。
今回はAIを用いてランダムフォレストを指定し、離職に影響する変数を分析していきたいと思います。
その際、chatGPTを用いて正しく変数重要度が表示されるのか試してみたいと思います。AIを用いることでいかに効率化できるのか、体験していただければと思います。
所要時間は10分ほどとなっています。
それでは、さっそく始めていきましょう!
データの紹介
今回検証に用いるデータのサンプルデータは従業員データです。サンプルデータはこちらからダウンロードできます。Macをお使いの方は「CSV-UTF8」を、Windowsをお使いの方は「CSV - Shift-JIS」をダウンロードしてください。
1行が従業員1人のデータになっています。列情報としては年齢、性別、婚姻ステータス、部署、職種、給料などがあります。
まずはExploratoryを用いて実行し結果を確認する
まずは正しい結果を抑えるべく、Exploratoryを用いてランダムフォレストを実行します。
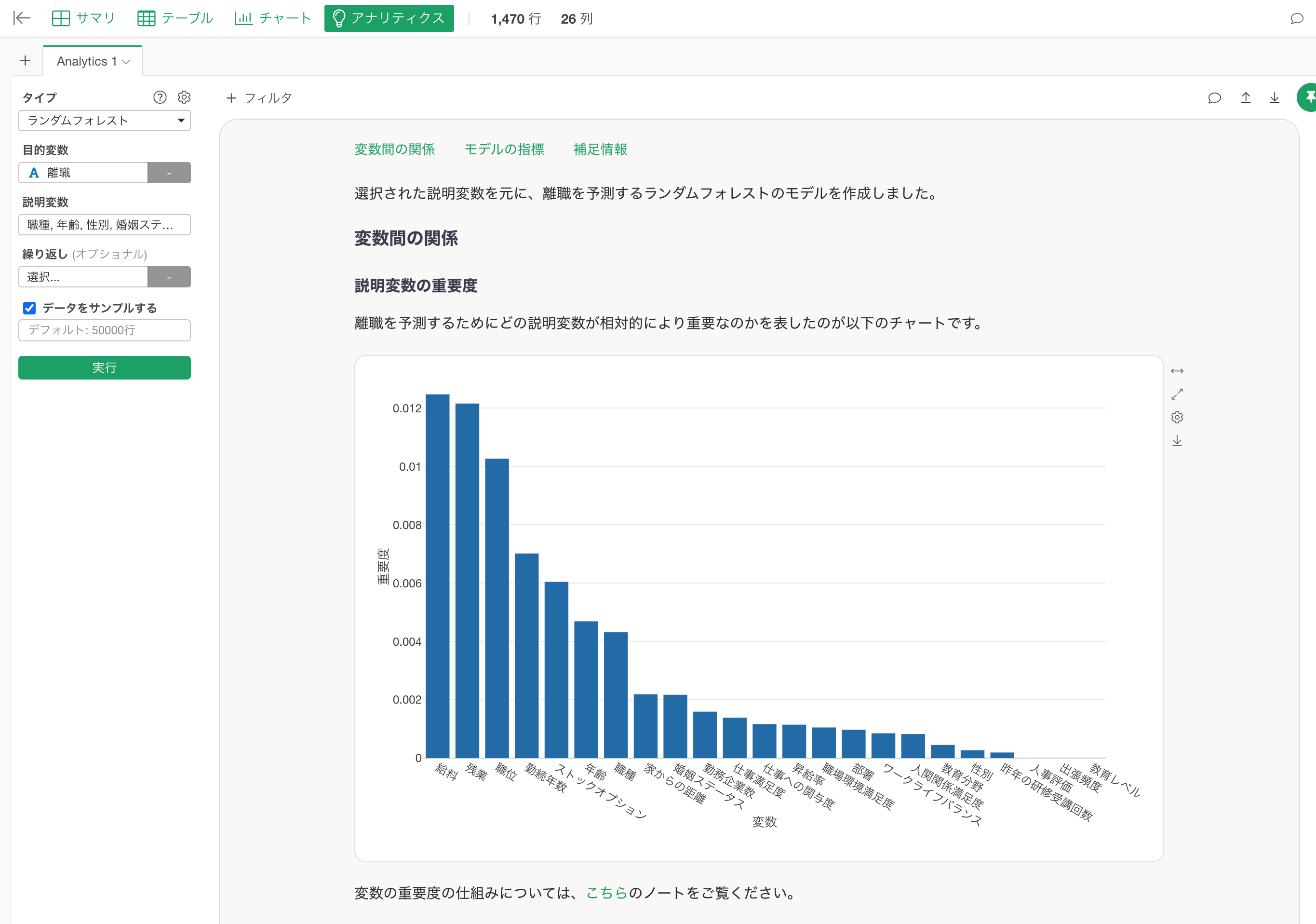
結果を見ると、離職に対する変数重要度は、給料:約0.012、残業:約0.012、職位:0.01...と並んでいきます。
次に同じことをするため、chatGPTに従業員データをアップロードし、下記のようにプロンプトを入力し、実行します。
出力結果を確認します。
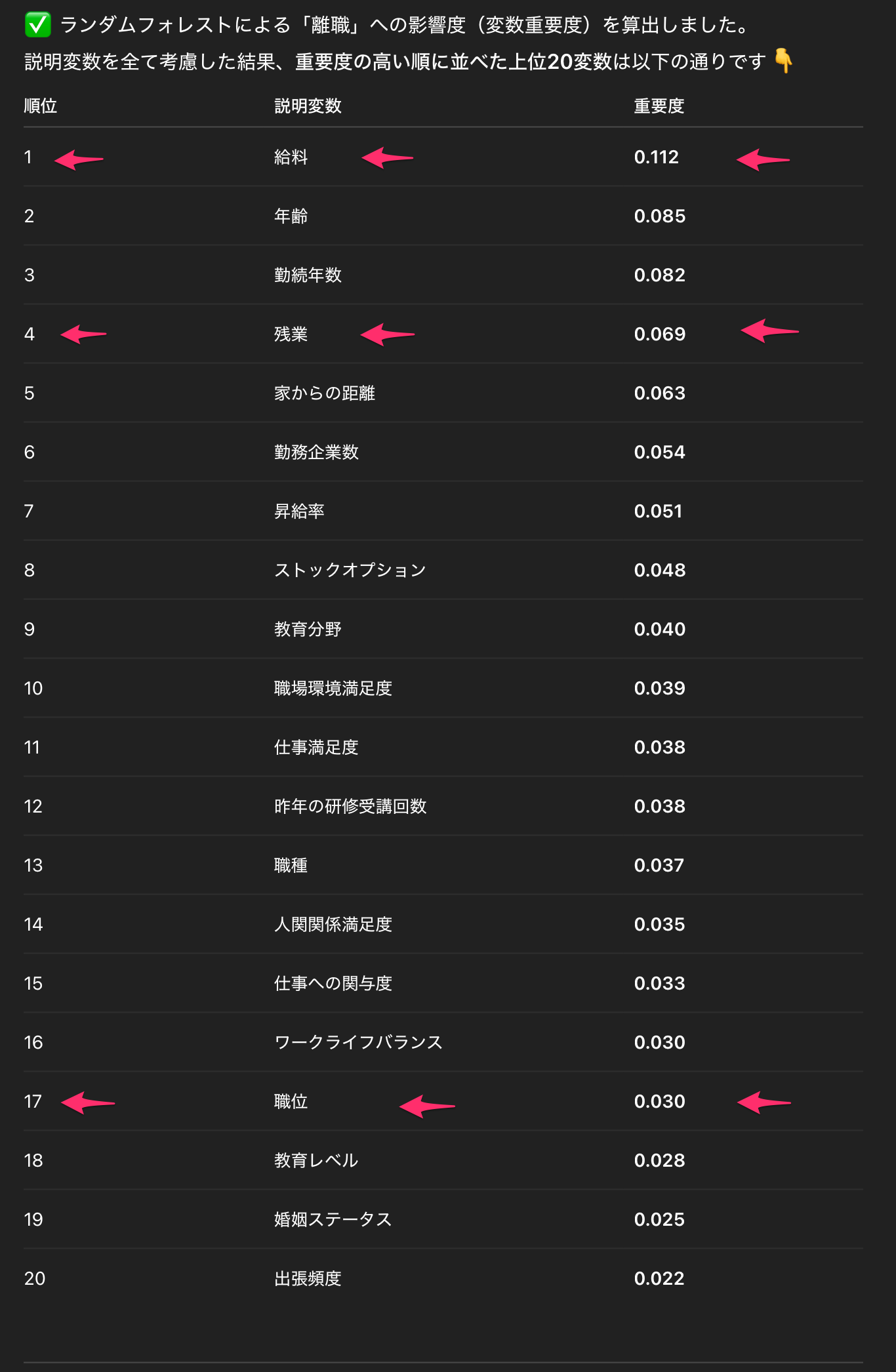
結果を比較し、確認します。
1位は給料で正しく分析できています。しかし重要度を見ると0.012だったものが0.112と大きく出力されています。
また2位だった残業は4位に、3位だった職位は17位にまで大きく順位を下げています。
まとめ
今回はランダムフォレストを実行するにあたり、2つの方法を試しました。
1つはExproratoryを用いた方法と、もう一つはAI(chatGPT)を用いた方法です。
結果はAIではまだ正確に変数重要度を抽出できないことを
確認することができました。
AIでできることとできないことを把握し、うまく活用することで、データ分析もかなり効率化できそうですね!
AIでデータ分析-ランダムフォレスト:離職に影響する変数を分析する は以上となります!