はじめに
みなさん、Salesforceへのデータの一括投入にはどんなツールを使っていますか?
SalesforceのCSVインポート機能や、公式データローダーなどいろいろツールがあると思いますが、これらのツールで10万件〜100万件といったデータ量を扱うのは結構きついところがあります。
この記事では、TROCCOというETL SaaSを使ってSalesforceに大量のデータを投入したり更新したりするときに気をつけるべきポイントについて記載します。
(この記事では特に新規作成と更新について区別しないのでどちらも一括投入と呼びます。)
そもそもTROCCOでデータ投入すると何が嬉しい?
SaaSだからこその便利さがあります。
- クラウド上で動かしっぱなしにできる
(ローカルだと勝手にPCがスリープになったり、ネットワークが切れたり…) - WEB上で転送エラーの確認や再実行ができて便利(属人性低下、再利用性もよい)
- 指定した時間に転送をスケジュールできる
そもそもどうやってTROCCOでSalesforceにデータ投入する?
TROCCOを使ってSalesforceにデータ投入する方法は無数に考えられますが、弊社では以下のステップで実施しています。
- 投入データ元となるCSVファイル等を用意する
- BigQueryにデータをインポートする
- (必要であればSQLを使ってデータを加工する)
- TROCCOでBigQuery→Salesforceの転送設定を作成する
BigQueryをかましているのは、SQLで加工したりフィルタできるので転送の前処理に便利なためです。
勘所1: フローを止めろ
Salesforceにはフローという自動で処理を行う機能があります。この機能を無効化せず一括投入すると、思わぬ副作用が起こり得るので気をつけましょう。
転送時間が伸びる程度ならいいですが、Slack通知や外部APIへの呼び出しなんかがあると阿鼻叫喚です。
オブジェクトに紐づくフローを確認するには、「設定> オブジェクトマネージャ > (対象のオブジェクト) > フロートリガー」を開くと、一覧できます。
バリデーションも止めろ
バリデーションも止めましょう。
「投入データに存在しないカラム」についてのバリデーションでも、データ投入時のレコードの更新をトリガにすべての項目に対してバリデーションが再実行されるので、エラーになってしまいます。
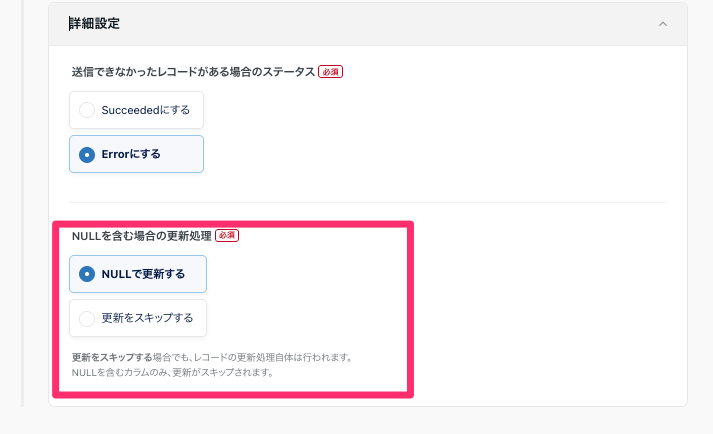
勘所2: NULLで上書きするか確認しろ
TROCCOの転送設定では、転送データにNULLがあった場合に値をNULLで上書きするか、更新をスキップするか設定することができます。
データ投入の要件に合わせて設定を行いましょう。
すでにあるデータを意図せずNULLで上書きしたらやばいです。
勘所3:ちょっとずつ入れろ
最初は10件くらいで試してみるのがいいでしょう。
リリース時間をとっていざやってみようと思ったら「項目名を間違えている」「書き込みに必要な権限が足りない」といったことが起こります。
その後も、100件、1000件、1万件と、区切り方はそれぞれですが、少しずつ入れていきましょう。
「イレギュラーデータがあって止まっちゃった」とか、前述のように「フローや思わぬ副作用で阿鼻叫喚」となるのが怖いです。
ちょっとだけ入れることで転送時間の見積もりにもなります。大量のデータを投入する時は、少量でリハーサルして時間を見積もりましょう。
勘所4:データはソートしろ
もし投入データをSQLのLIMITとOFFSETで区切ってちょっとずつ入れるなら、必ずIDのようなユニークなキーでソート(ORDER BY)をかけておきましょう。
2回目以降の転送をする時もずっと同じソート順であることを担保できないと、投入済みのデータと未投入のデータが区別不能になります。
まあ、ORDER BYを指定しない場合にデータの順序が不定になるかどうかは、転送元の仕様によると思いますがORDER BYは指定した方が念のためです。
まとめ
自分がTROCCOを使ってSalesforceへデータ投入する際に気をつけているポイントを列挙してみました。
参考になりましたら幸いです。