1.この記事の背景
今回の記事ではどのレコメンドエンジンでも利用できそうな埋め込み表現(embedding)について書きます。
今回は実装より基礎知識を整理するイメージです。また、今回は各埋め込み表現は細かく紹介しませんので、参考文献や論文を提示します。興味がある方はこちらご参照ください。
※レコメンドエンジンとは、ECサイトやWebサイト上で、ユーザにおすすめの商品やコンテンツを表示するためのシステムです。
2.埋め込み表現(分散表現)とは?
前提としてコンピュータでデータ解析を行う場合、ベクトル演算が基本となります。そのため文字や画像などのデータを特徴持ちのベクトルを変換する必要があります。(類似しているのitemはベクトル間の距離も近い、itemの潜在関係を示すこともできます。)
ディープラーニングの出現以前に単語(item)をベクトルで表現する方法としてBoW(Bag of Words)やOne-hotと呼ばれる手法が使われてきました。
※自然言語処理の分野ではWord2Vec出現以前と言えます。
Word2Vecによる単語の足し算・引き算の例でよく用いられるのが以下の式です。
$$V_{king} -V_{man} + V_{women} \cong V_{queen}$$
「King(王様)」から「Man(男)」という意味を引いて「Woman(女)」という意味を足すと「Queen(女王)」という答えが出るような計算を行うことができます。
ベクトル空間表現のイメージ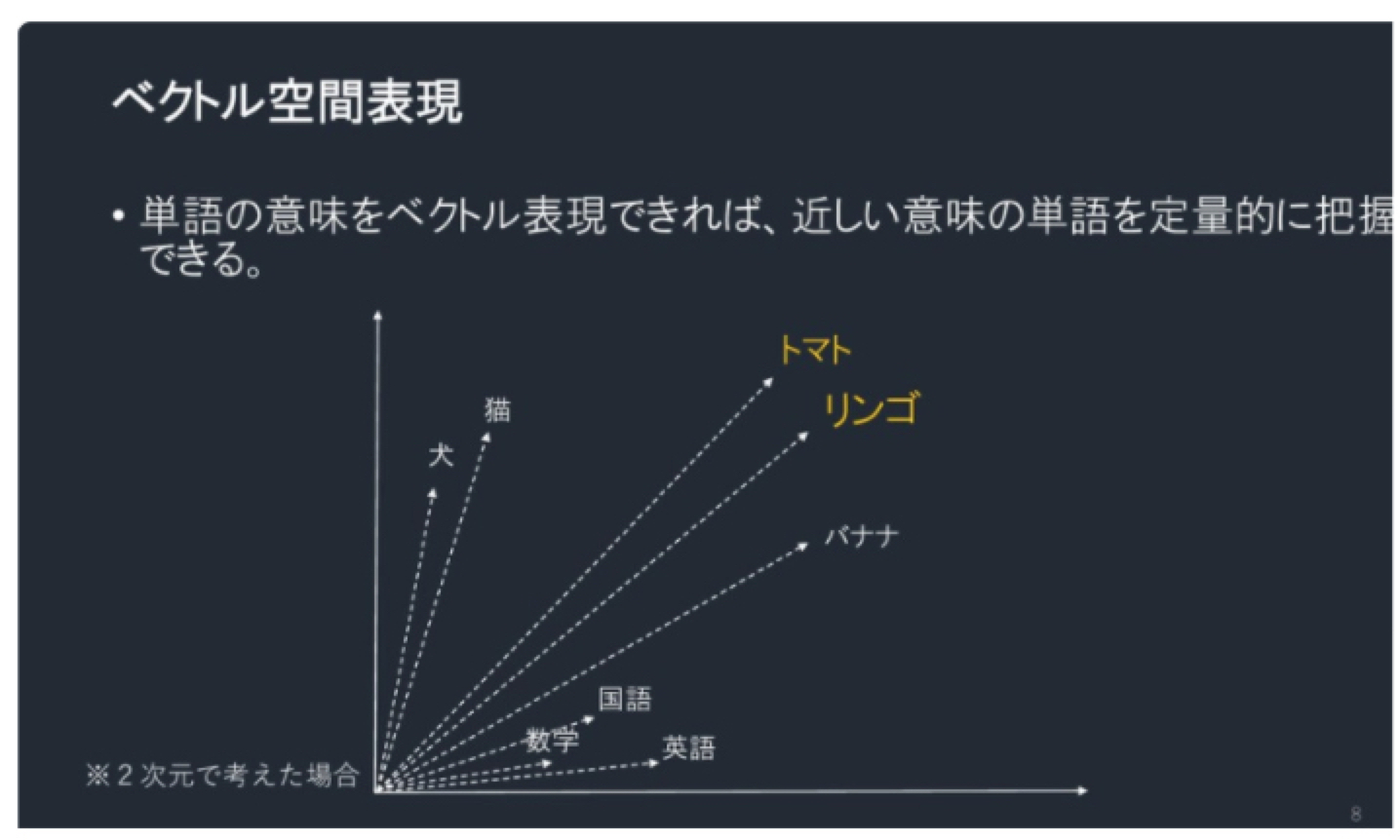
埋め込み表現を説明する記事は他にはいくつかがありますので、今回はあくまでもレコメンドエンジンの埋め込み表現がどのように利用されているかを説明します。なお埋め込み表現の理論的な部分(どの損失関数を利用しているかなどや何層のニューラルネットワークによって構成されているかなど)の説明は省略しようと思います。
3.レコメンドエンジン中で埋め込み表現に変換する重要さ
1.次元の呪いを避ける
伝統的なone-hot encodingは離散特徴に対して効果がありません、なぜならone-hot encodingではベクトルのサイズ=itemの合計であるからです。
例えば Amazonの全商品をone-hot encodingするのなら、数千万サイズのベクトルが得られます。このベクトルの特徴は極端にまばらです。そのようなまばらなベクトルを深層学習モデルに投入した場合、過学習や次元の呪いが発生しやすくなります。
以上から深層学習(レコメンドの計算ロジック)を行う際に、低次元の密なベクトルを投入することで、精度向上に役に立てることができます。
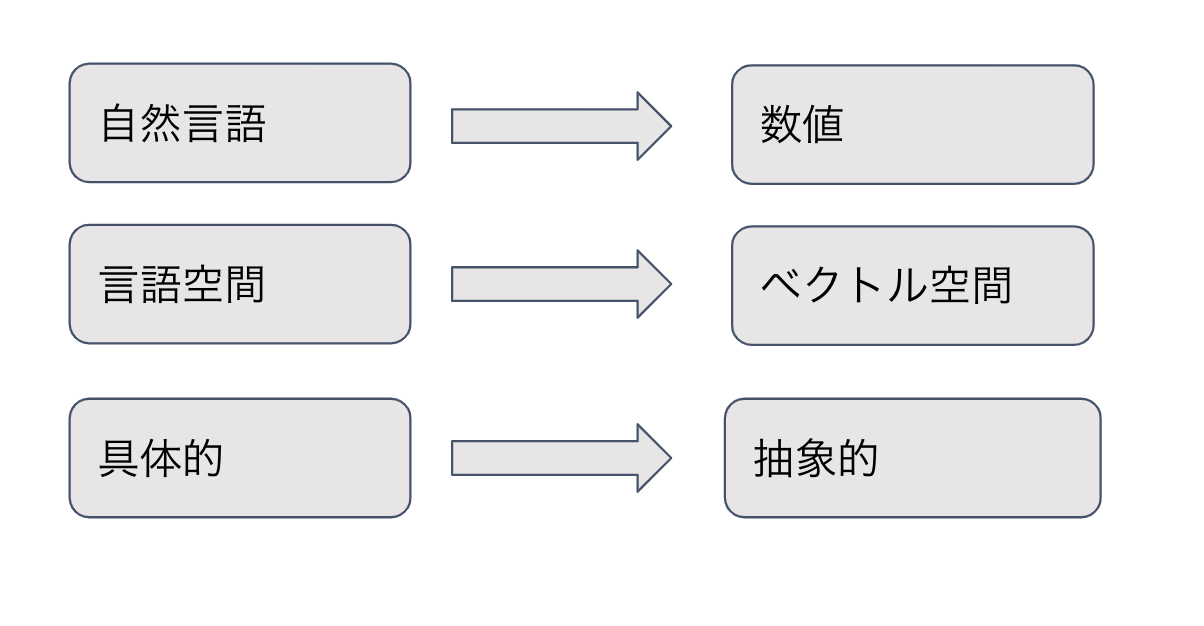
図のように埋め込み表現に変換するとコンピュータで解析しにくい文字(item)データを元の意味を持つ低次元ベクトルに変換できます。
2.埋め込み表現(embedding)自体はデータの特徴が表せる
※後文中埋め込み表現をEmbeddingとして書く
MF(Matrix Factorization)など伝統的な手法で作成した特徴ベクトルよりEmbedding手法から作成した特徴ベクトルの方がデータ自体の特徴の表現力が強いです。
特にGraph Embeddingが提案されて以降、Embeddingはほとんどすべてのデータに対してencoding可能になり、Graph Embeddingによって作成されたEmbeddingは元データの特徴(Item間の関係性など)を大量に含めるようになりました。
Embedding技術に基づいて、Embeddingベクトルとレコメンドエンジンの特徴量と一緒にdeep learning学習ネットワークに投入し、学習させることになります。
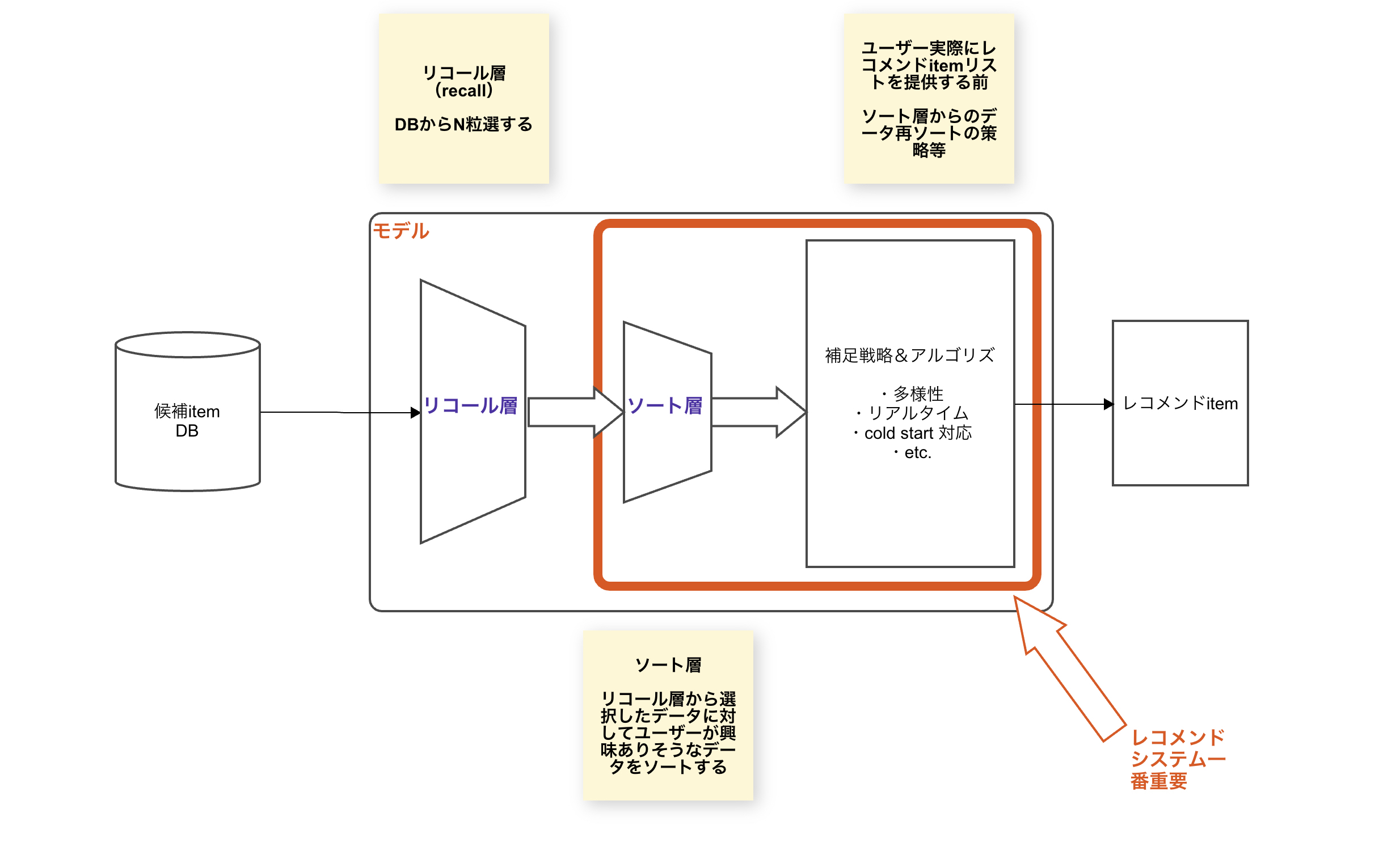
3.レコメンドエンジンのリコール層によく使われている
レコメンドエンジンのリコール層機能は、候補Item DBから少ない情報を利用して、ユーザへ推薦候補itmeリストを選出することにあります。(itemの"予備審査"の感じ)
Embeddingの利用例を挙げると、itemのEmbeddingを使って商品間(item)もしくはユーザ間の類似度を計算して、推薦候補itmeリストを選出後に次のソート層に投入します。
それによりレコメンドの深層学習ネットに入る前に、ある程度候補データから粒選でき、学習コストを減らせれます。
※さっくり作成したレコメンドモデル部分のアーキテクチャイメージ
4.現在レコメンドエンジンでよく利用されている分散表現を構築する手法の紹介
それでは深層学習のレコメンデーションでよく使われているEmbedding手法をいくつか見ていきましょう。
1.Sequentialより分類されるEmebdding作成技術
Sequentialという手法は自然言語処理の分野と強い相関があります。
自然言語処理では、単語の並ぶ方向からID化した単語をembeddingします。レコメンドエンジンではユーザの商品への行動履歴からアイテム情報をembeddingしていきます。
今回は2つ手法を紹介したいと思います。
1.1 Item2Vec
(論文リンク:https://arxiv.org/abs/1603.04259)
Item2Vecは、Word2Vecのロジックから発展したものです。
Word2Vecは自然言語処理の文脈から単語を統一空間内にembedding処理を行います。
Item2Vecではユーザの行動履歴からitemのembeddingを行います。
Item2Vecの特徴は、任意のシーケンシャルデータから対象のEmbeddingを作成できますが、一方でシーケンシャルではないデータの場合、Item2Vecの学習方法では対応ができなくなります。
1.2 Bert4Rec
(論文リンク:https://arxiv.org/pdf/1904.06690.pdf)
Bert4Recの「Bert」はあの自然言語処理で有名なBert(Bidirectional Encoder Representations from Transformers)です。Item2Vecと同じく自然言語処理から発展したものです。
Sequentialデータに対してBertという技術をレコメンドシステムのembedding層に応用して、より良い質のEmbeddingを作成することが可能になります。
モデルのアーキテクチャはこちらになります
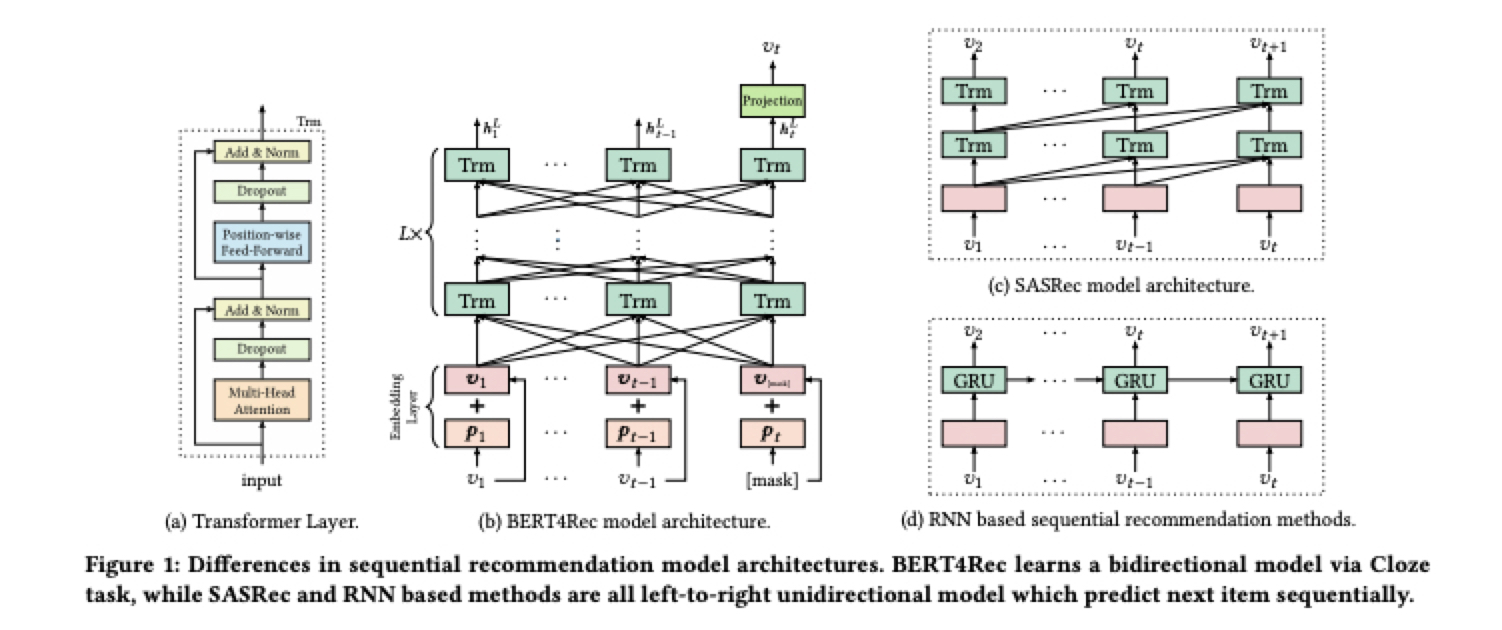
Bert4Recは、N個の方向ありTransformerレイヤーによってスタックされています。各レイヤーで、Transformerレイヤーと並行して前のレイヤーのすべての位置に関する情報を交換し、各位置のEmbeddingを繰り返し変更します。
この論文では、レコメンド問題をユーザーの再生履歴(購入など)のシーケンス「item1、item2、item3」を把握した上で、次に再生されるアイテムを予測することが定義されています。
モデルを訓練する時にマスクLMタスクを使用して、多数のユーザ行動シーケンスでモデルをトレーニングします。予測するときは、シーケンスの最後に「MASK」を挿入し、「MASK」の埋め込みを予測して、ユーザーがどのアイテムを再生(購入)するかを予測します。
2 Graph Embedding
Sequentialから作成したEmbeddingでシーケンシャルなデータに対して効果ありますが、非Sequentialのデータに応用出来ません。
そこで、Graph Embeddingが提案されました。
上記で紹介したItem2Vec, Bert技術はシーケンシャルデータの対応が強いですが、そもそもSNSでは人と人とのつながりは巨大なグラフで表現することできます。通信ネットワークの構造やルート自体は根本的にグラフになっています。
そこで、Graph Embeddingが提案されました。
後ほど2つの手法を軽く紹介します(DeepWalk, Node2Vec)
2.1 DeepWalk
論文 → https://arxiv.org/pdf/1403.6652.pdf
DeepWalkではすごくシンプルにNLPで用いられているSkip-gramをそのままグラフに応用したものです。
グラフ構造のデータにSkip-gramモデルをそのまま適用することはできないため、Random Walkという方法でデータを生成してからSkip-gramにかけます。
- DeepWalkの大まかな流れ
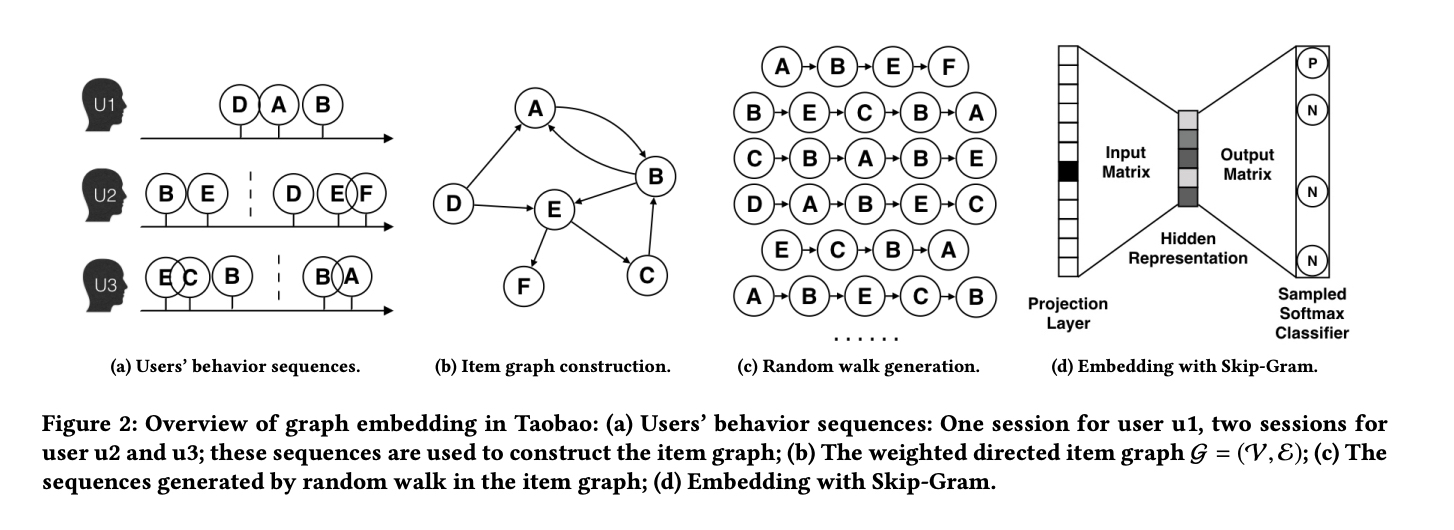
https://arxiv.org/pdf/1803.02349.pdf
a. 図(a)ユーザ行動sequences。
b. 図(a)中のユーザ行動sequencesよりitem間のGraphを作成。
c. Random Walkによってランダムで開始点を選択、新たなItem sequences作成。
d. 生成したシーケンシャルをSkip-gramモデルに投入、Item Embedding生成する。
2.2 Node2Vec
論文 → https://cs.stanford.edu/~jure/pubs/node2vec-kdd16.pdf
2016年Stanfordの研究者たちはDeepWalkに基づいてNode2Vecモデルを提案しました。
Node2VecはRandom Walkを調整してGraph Embeddingの結果によりグラフネットワークのhomophily(ホモフィリー: 同じ特性) もしくはstructural equivalence(構造的同等性)を表示できます。
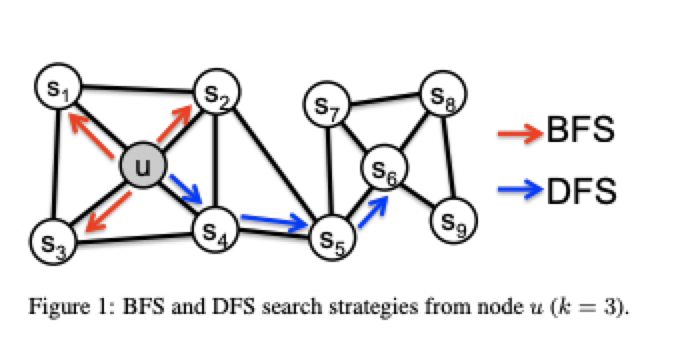
具体的には単なるRandom Walkではグラフ上のノードが(近隣にあるもののうち)ランダムに取得されていくわけですが、論文のサンプリングの方法としてBreadth-first Sampling(BFS)とDepth-first Sampling(DFS)の2つが提案されています。
これらはそれぞれ以下のように説明されています
Node2Vecより現われたグラフネットワークのhomophily & structural equivalenceの特性はレコメンドシステム中に直感的に解釈可能です。
homophilyとstructural equivalenceを直感的に解釈すると
- homophilyの類似性は図の中の「U→S6」と「S2→S6」の距離が同じく直感的(例:東京から静岡市と横浜から静岡市までの距離とほぼ同じ)。
- structural equivalenceではUとS6のステータスが類似している、他のノードに行く際にU(S6)を経由としなければなりません。例を挙げると羽田空港と成田空港のステータスと同様に、この二つ空港から全世界行けますが(個人そう思っています、実際に調査していない)他の空港はそうではありません。
どちらもレコメンドシステム中で非常に重要なEmbedding表現です。Node2Vecの柔軟性とさまざまな機能を探索することで、Node2Vecによって生成されたEmbeddingが後続の深層学習ネットワークに統合して、アイテムのさまざまな機能情報を保持することも可能です。
今ではGraph Embeddingは産業および学術研究と実践のホットスポットであります。
先ほど紹介したDeepWalkやNode2Vec以外にも、EGES (Enhanced Graph Embedding with side Inofrmation)やLINE(Large-scale Information Network Embedding)、SDNE (Structural Deep Network Embedding)などの手法もGraph Embeddingとして提案されています。こちらの紹介は省略しようと思います。
5.Embeddingのまとめ
今回は深層学習を使用したレコメンドエンジンのコアな部分である**「Embedding技術」**を紹介しました。
Word2Vecからレコメンドシステムに展開されたItem2Vec、Bert4rec、そしてより多くの構造情報と補足情報を統合したGraph Embeddingという形で提案されてきました。
現在Embedding技術は理論と工学の実践の両方でますます成熟しています。
| Embedding手法 | 原理 | 特徴 | limitation |
|---|---|---|---|
| Word2Vec | センテンスの相関性を利用して 、一つの隠れ層を持つニューラルネットワーク(Single hidden layer neural network)から単語のEmbeddingのベクトルを得る | クラシックなEmbedding手法 | シーケンスデータのみ |
| Item2Vec | Word2Vecのアイデアを任意シーケンスデータに拡張 | Word2Vec技術をレコメンド領域に応用 | シーケンスデータのみ |
| Bert4rec | NLPで有名的なBERT技術をレコメンド領域に応用し、トレーニングの際にユーザ行動の一部をMASKしてitemのベクトルを得る | ユーザの長期と短期の好みを両方考慮可能 | シーケンスデータのみ |
| DeepWalk | Graph構造でランダムウォークという手法を用いてシーケンスデータを作成でき、そしてWord2Vecのアイデアを利用してEmbeddingモデルを作成 | ターゲットを絞ってさまざまなネットワーク特性をマイニング可能 | ランダムウォークより作成したシーケンスデータなので、データの特徴性を表現することが弱い(ランダム性なので) |
| Node2Vec | DeepWalkに基づいてランダムウォークの重みを調整することにより、Embedding結果のhomophilyとstructural equivalenceが現せる | DeepWalkのLimitationを改善 | 表現したい特徴よりパラメーター調整作業が多い |
全体のレコメンドシステムに対してレコメンドモデルの部分は不可欠なものでした、モデル部分も複数の仕組みから構成されます。
より良いレコメンドシステムを構築するために良いEmbeddingを作成できれば、同じモデルに投入するにあたって精度向上に有効です。
6.Embeddingが深層学習(Deep Learning)レコメンドにおける応用
先ほどEmbeddingの原理とその発展プロセスを紹介しました。
しかしレコメンドシステムを作る際には、ItemのEmbeddingとレコメンドエンジンや他のモデルと協同して全レコメンドのプロセスを完成させます。
深層学習に基づいてレコメンドシステムに不可欠なモノのEmbeddingは主に三つの方向に応用されています。
- 深層学習ネットワークのEmbedding層として高次元の疎な特徴ベクトルから低次元の密な特徴ベクトルの変換
- 事前訓練済みEmbeddingとして、他の特徴量を連結した後に学習ネットワークへ投入してネットワークを学習させる(特にGraph Embeddingの訓練)
- Embeddingそのまま使ってitem(ユーザ)間の類似性を計算して、その結果をリコール層もしくはリコール策略に使います。(DNN for YouTube Recommendations)
おわりに
Embeddingを詳しく理解できれば、より良いレコメンドエンジンを構築する際に、有力な武器になるかと思います。
しかしリコール層やソート策略、Cold Start問題など、レコメンドリストの出力に影響している部分があるので、良いレコメンド結果を得られるシステム作成にあたって上記のことを考慮しないといけません。
今後レコメンドシステムのリコール、ソート策略、Cold Start問題も紹介したいと思います。
参考にした記事など
https://techblog.zozo.com/entry/deep-learning-recommendation-improvement
https://qiita.com/michi_wkwk/items/32def413fa0bdd6394f4
https://zhuanlan.zhihu.com/p/166016979
https://arxiv.org/pdf/1603.04259.pdf
https://www.zhihu.com/search?type=content&q=%E6%8E%A8%E8%8D%90%E7%B3%BB%E7%BB%9F%20embedding
https://arxiv.org/pdf/1706.02216.pdf