Neural Ordinary Differential Equation の理解を助けるための練習問題を作り、TensorFlow+ScipyのODEソルバーを使って問題を解いてみます。
動機
Neural ordinary differential equation という論文が国際会議 NeurIPS 2018 の優秀論文賞をとり、話題になっています.一般向けの盛った記事がこちらに出ていたりします.
一言で言うと,離散的な層を重ねてなにがしかの計算をする代わりに,常微分方程式を使って計算を行うニューラルネットモデルです.qiita に既に論文紹介などの記事がありますが、ここでは Neural ODE を実装して使いこなすための準備もかねて、あえてNeuralでも機械学習でもなさそうな問題を Neural ODE と同じ原理で解くことで,その仕組みをわかりやすい形で示してみたいと思います.後々のことを考えて実装には極力 TensorFlow を使います.
想定読者
- なんとなく最急降下法や誤差逆伝搬法についてはわかる.
- なんとなく微分方程式はわかる.
- Neural ODE についてはよくわからない.
問題設定と定式化
レーザービーム
まずはイチローのレーザービームをみてみましょう。画像をクリックすると動画に飛びます。

すばらしいですね。
さて、イチローからキャッチャーのミットまで、正確に投げるには、適切な初速度と射出角度でボールを投げなければなりません。
問題の定式化

ボールが飛ぶ水平方向を $x$軸、垂直方向を $y$ 軸として、ボールが手から離れた位置を原点 $(0,0)$, キャッチャーのミットの位置を $(x^*,y^*)$, ボールの初速度の絶対値を $v_0>0$, 投げたときの上向きの角度を $\phi$ とします。
問い: ボールが手を離れて $T$ 秒後にちょうどミットに収まるには、 $v_0$ と $\phi$ をどう設定すればよいか?
空気抵抗はないとします。これは高校の物理の知識で答えを解析的に求めることができる問題ですが、今回はこれを最急降下法を使って数値的に解を求めてみます。(空気抵抗がある場合への拡張は容易です。)
運動方程式
ボールを投げてから $t$ 秒後のボールの位置と速度をそれぞれ $\boldsymbol{x}(t)=(x(t), y(t))$, $\boldsymbol{v}(t) = (v_x(t), v_y(t))$ とします. 速度は微分なので
\frac{dx}{dt}=v_x ,\ \ \ \frac{dy}{dt}=v_y
いま抵抗を無視しているので,飛んでいるボールにかかる力は鉛直方向の重力のみですから,ニュートンの運動法則から
\frac{dv_x}{dt}=0 ,\ \ \ \frac{dv_y}{dt}=-g,
$g$ は重力加速度です.
1階4次元常微分方程式方程式
$x, y, v_x, v_y$ をまとめて1階の4次元常微分方程式に直します。
\boldsymbol{z}(t) = \left( z_1(t), z_2(t), z_3(t), z_4(t)\right)^T = (x(t),y(t),v_x(t),v_y(t))^T
として, $\boldsymbol{z}$ の時間発展は
\begin{equation}
\frac{d\boldsymbol{z}}{dt} = f(\boldsymbol{z}) =
\begin{pmatrix}
z_3 \\
z_4 \\
0 \\
-g
\end{pmatrix}\tag{1}
\end{equation}
と表すことができます.
初期条件を決定するパラメータ $v_0$ と $\phi$ をまとめて
\boldsymbol{c} = (c_1,c_2)^T = (v_0, \phi)^T
とします.
初期条件は
\begin{equation}
\boldsymbol{z}(0) = \begin{pmatrix}
0 \\
0 \\
v_0 \cos{\phi} \\
v_0 \sin{\phi}
\end{pmatrix} =
\begin{pmatrix}
0 \\
0 \\
c_1 \cos{c_2} \\
c_1 \sin{c_2}
\end{pmatrix}\tag{2}
\end{equation}
となります.
損失関数
ボールを投げて $T$ 秒後のボールの位置 $(z_1(T), z_2(T))$ が、目標点 $(x^*,y^*)$ に近ければ近いほどよいので,$T$ 秒後のボールと目標点の距離の差の2乗を損失関数 $L$ として定義して,これの最小化を目的とします.
\begin{equation}
L=\left(z_1(T)-x^* \right)^2 + \left(z_2(T)-y^* \right)^2 \tag{3}
\end{equation}
損失関数の勾配の計算
さて,いま $\boldsymbol{c}$ (つまり $v_0$ と $\phi$) を適切に選んで, $L$ を最小化したいわけです. 最適な $\boldsymbol{c}$ を最急降下法によって探すことを考えます. すなわち $\varepsilon$ を学習係数として
\begin{equation}
\boldsymbol{c} := \boldsymbol{c} - \varepsilon \frac{\partial L}{\partial \boldsymbol{c}}
\tag{4}
\end{equation}
と $\boldsymbol{c}$ を逐次更新していくことにより,徐々に $L$ を極小値に持っていくわけです. ここで $:=$ は代入です.
$\boldsymbol{c}$ から $L$ までの順方向の計算の流れ(計算のグラフ)は図の青系の流れのようになります.
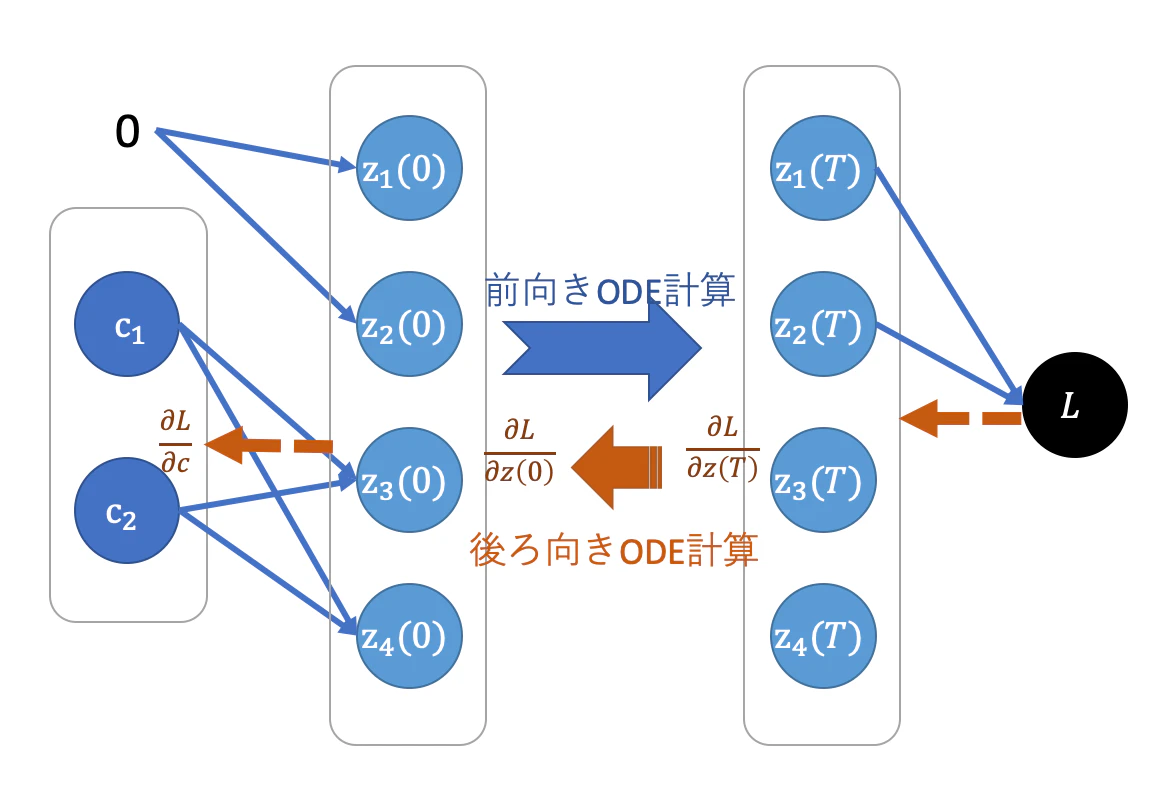
誤差逆伝播法と同様に,$L$から逆向きに計算を進め $\partial L/ \partial\boldsymbol{c} $ を求めるにはどうすればよいでしょうか(茶系の流れ).
まず $\partial L/{\partial \boldsymbol{z}(T)}$ は (3)式の微分から求められます.また最初の部分の $\partial \boldsymbol{z}(0)/\partial \boldsymbol{c}$ は (2)式の微分から求めることができます. 問題はODEを計算している部分です. この部分でどうやって $\partial L/{\partial \boldsymbol{z}(T)}$ から $\partial L/{\partial \boldsymbol{z}(0)}$ を求めていけばよいでしょうか?
Adjoint 法
ここで変分の計算に使われている手法であるポントリャーギンのadjoint vector (随伴ベクトル) を使います.最適制御などに使われている手法です.
まず,論文にしたがって
\boldsymbol{a}(t) = \frac{\partial L}{\partial \boldsymbol{z}(t)}
をadjoint vectorとします.
このとき,$\boldsymbol{a}$ の時間発展は
\begin{equation}
\frac{d \boldsymbol{a}(t)}{dt} = -D_{f}(\boldsymbol{z}(t))^{T} \boldsymbol{a}(t) \tag{5}
\end{equation}
となります,ここで$D_{f}(\boldsymbol{z}(t))$ は $f$ のヤコビ行列の$\boldsymbol{z}(t)$ での値です.上式はneural ode 論文の式(4)に相当します.
余記
この導出は論文など読めばいいのですが,直感的な理解としては$\Delta(t)$ を, $\boldsymbol{z}(t)$ に対して時刻$t_0$ で無限小の摂動 $\Delta(t_0)$ を与えて時間発展させた際の摂動の時間変化だとすると,時刻 $t_0$で 摂動 $\Delta(t_0)$ を与えた際の$L$ への影響と,時刻 $t_1$で $\Delta(t_1)$ の摂動を与えた際の影響は無限小では同じなので, $\langle \cdot,\cdot \rangle$ を内積として
\langle\boldsymbol{a}(t_0), \Delta(t_0) \rangle = \langle \boldsymbol{a}(t_1), \Delta(t_1) \rangle
が成り立ち,一方$\Delta$ の時間発展は
\frac{d \Delta}{dt} = D_{f}(\boldsymbol{z}) \Delta
であることから,自然に理解できるかなと思います.
アルゴリズムまとめ
今求めたい値 $\boldsymbol{a}(0) = {\partial L}/{\partial \boldsymbol{z}(0)}$ は,式(5)を時刻 $T$ から時刻0に後ろ向きに積分することによって数値的に求めることができます.ただ時間変化するヤコビアンの計算には各時刻での $\boldsymbol{z}(t)$ の値が必要なので,元論文では式(1)と(5)を同時に逆向きに解くことを行っています.
まとめると、前向き計算時の最後の値 $\boldsymbol{z}(T)$ と損失関数から計算した ${\partial L}/{\partial \boldsymbol{z}(T)}$ を初期値に設定し,式(1)と式(5)を逆向きにODEソルバーに解かせることで,誤差逆伝播に必要な $ {\partial L}/{\partial \boldsymbol{z}(0)}$ を得ることができます.あとは
\frac{\partial L}{\partial \boldsymbol{c}} = \frac{\partial L}{\partial \boldsymbol{z}(0)} \frac{\partial \boldsymbol{z}(0) }{\partial \boldsymbol{c}}
を計算して最急降下法による重み更新をすればよいわけです.
実装
上記の流れを TensorFlow で実装してみます.オリジナル論文の実装はみてないので,それとは大分違ってるかもしれません.
関数など準備
関数 $f$ をTensorFlowで定義します.
ヤコビアンは過去の記事で説明したので説明省略します.
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from scipy.integrate import solve_ivp
def f(t,z):
"""
definition of rhs of ode using tensorflow
args z: 4 dim tensor
returns: 4dim tensor
"""
g = 9.8
return (tf.concat( [z[2:4],[0,-g]],axis=0))
def jacobian(t, f, x):
""" return jacobian matrix of f at x"""
n = x.shape[-1].value
fx = f(t, x)
if x.shape[-1].value != fx.shape[-1].value:
print('For calculating Jacobian matrix',
'dimensions of f(x) and x must be the same')
return
return tf.concat([tf.gradients(fx[i], x) for i in range(0, n)], 0)
def Df(t,f,z):
return jacobian(t,f,z)
次にODEソルバーに渡すODEの関数, (1)式の $f$ と, 逆向きに(1)(5)式を同時に解く時の関数f_with_adjointを作ります.
あとでニューラルネットに置き換えやすいように,計算はTensorFlowで行うようにします.このため,クラスを定義し,セッションやTensorなどを初期化時にメンバ変数に持たせておきます.
class F_np:
''' calc rhs of ode (numpy)'''
def __init__(self,sess,f,z_ph):
self.f_tf=f(0,z_ph)
self.sess=sess
self.z_ph=z_ph
def __call__(self,t,z):
return( self.sess.run(self.f_tf,
feed_dict={self.z_ph:z}) )
class F_with_adjoint_np:
'''calc ode and adjoint ode (numpy function)'''
def __init__(self,sess,f,z_ph, a_ph):
"""
args:
sess : session
f: main function of ode
z_ph: placeholder of main variable z
a_ph placeholder of ajoint variable a
"""
self.dim = 4
self.fz=f(0,z_ph)
self.Df=Df(0,f,z_ph)
self.sess=sess
self.z_ph=z_ph
self.a_ph=a_ph
self.Df_a=-tf.linalg.matvec(self.Df, self.a_ph, transpose_a=True)
def __call__(self,t,za):
fzv,dav = self.sess.run([self.fz, self.Df_a],
feed_dict={self.z_ph:za[0:self.dim], self.a_ph:za[self.dim:2*self.dim]})
return np.concatenate([fzv,dav])
イチローのビデオを参考に,到達時間 $T$ は3[s],距離は100[m]としておきます.
xy_target = (100,0) # target
t_end = 3 # duration of integration
ts=np.arange(0,t_end+0.1,0.1) # time step for displaying orbit
dim=4 # dimension of ode
グラフと損失関数
$\boldsymbol{c}$, $ \boldsymbol{z}(0)$, $ \boldsymbol{z}(T)$, $L$ を定義します.
$ \boldsymbol{z}(T)$ はtensorflow外でodeを解いた値を入れるのでplaceholderにします.
初速度と角度の初期値は, 35[m/s], $\pi/4$[rad] と適当に決めておきます.
c = tf.Variable([35,np.pi/4], dtype=tf.float64,
name='c') # set initial speed and angle here
z_0 = tf.concat([tf.Variable([0,0,],dtype=tf.float64), [c[0]*tf.cos(c[1])], [c[0]*tf.sin(c[1])]], axis=0)
z_T= tf.placeholder(shape=[dim],dtype=tf.float64)
L = tf.reduce_sum(tf.square(z_T[0:2]-xy_target) )
次は誤差逆伝播用のグラフです. トリックですがダミーの損失関数としてLdummy0 を
L_{dummy} = \langle \frac{\partial L}{\partial \boldsymbol{z}(0)} , \boldsymbol{z}(0) \rangle
と用意し, $\frac{\partial L}{\partial \boldsymbol{z}(0)}$ はplaceholderにしておいて,ODEを逆に解いた値 $a(0)$ を代入します.
こうしておけば TensorFlow上で$\frac{\partial L}{\partial \boldsymbol{z}(0)}$ を定数とみなして $L_{dummy}$ を偏微分した値は $L$ を偏微分した値と同じになり,誤差逆伝播をTensorFlow内でODEの手前のグラフでも行うことができます.
dLdz_T = tf.gradients(L, z_T)[0]
dLdz_0 = tf.placeholder(shape=[dim],dtype=tf.float64)
# Ldummy
Ldummy0 = tf.reduce_sum(dLdz_0* z_0)
オプティマイザは上の理由により, $L_{dummy}$ を最小化するようにしておけばよいです.学習係数は大きいと収束しません.
opt = tf.train.GradientDescentOptimizer(1e-5)
train_op = opt.minimize(Ldummy0, var_list=[c])
odeを解く準備
odeのための関数や変数の準備です.
## tensors etc used in ODE solvers
z_ph = tf.placeholder(shape=[dim],dtype=tf.float64)
a_ph = tf.placeholder(shape=[dim],dtype=tf.float64)
sess = tf.Session()
f_np = F_np(sess,f,z_ph)
f_with_adj = F_with_adjoint_np(sess,f,z_ph,a_ph)
# variables of numpy arrays end with _val
z_val = np.zeros(shape=[dim], dtype=np.float64)
za_val = np.zeros(shape=[dim*2],dtype=np.float64)
sess.run(tf.initializers.global_variables())
前向き計算
モデルの前向き計算をする関数を作ります.
計算の流れを表した図の左から右に計算が進みます. ODEの部分では関数 $f$ (実態はF_npクラスのインスタンス,そのcallが関数として使われる)をODEソルバーsolve_ivpに渡しています.
def forward(ts=None):
z0_val, c_val = sess.run([z_0,c])
sol = solve_ivp(fun=f_np,
t_span=[0, t_end], y0=z0_val, t_eval=ts) #,
zt_val = sol['y']
z_T_val = sol['y'][:,-1] # ODEを解いた最後の値 z(T)を取り出す.
L_val = sess.run(L,feed_dict = {z_T:z_T_val})
return L_val, z_T_val, zt_val,
後ろ向き計算
続いて誤差逆伝播計算をし, $\boldsymbol{c}$ を更新する関数を作ります.同じ図の右から左への流れに沿って計算します. f_with_adj をODEソルバーに渡します.このとき時間は $T$ から$0$ に逆向きに解くように指定しています.
def backward(z_T_val):
[dLdz_T_val] = sess.run([dLdz_T],feed_dict={z_T:z_T_val})
za_val[0:dim] = z_T_val[0:dim]
za_val[dim:2*dim] = dLdz_T_val[:]
# backward integration
sol_back = solve_ivp(fun=f_with_adj,
t_span=[t_end, 0], y0=za_val, t_eval=ts[::-1]) #,
za_0_val = sol_back['y'][:,-1]
dLdz_0_val = za_0_val[dim:2*dim]
#update c
_,c_val = sess.run([train_op,c], feed_dict={dLdz_0:dLdz_0_val})
return c_val, dLdz_T_val, dLdz_0_val, za_0_val
学習進行状況のチェック
学習のループに入ります. 本格的に回す前に,10回だけ $\boldsymbol{c}$ の更新を行い,結果が改善されていく様子を見てみます.
orbits = []
n_itr = []
for i in range(11):
L_val,z_T_val, zt_val = forward()
c_val, *other = backward(z_T_val)
L_val,z_T_val, zt_val = forward(ts=ts)
print('iteration:{}'.format(i))
print('(v_0[m/s], phi[deg]) = ({:.10}, {:.10})'.format(c_val[0], 360*c_val[1]/(2*np.pi)))
print('L= {:.4}'.format(L_val))
print('z(T)={}'.format(z_T_val))
orbits.append(zt_val)
n_itr.append(i)
iteration:0
(v_0[m/s], phi[deg]) = (34.99981365, 40.24403416)
L= 957.5
z(T)=[80.146 23.734 26.715 -6.789]
iteration:1
(v_0[m/s], phi[deg]) = (34.99980291, 36.52096533)
L= 582.0
z(T)=[84.382 18.387 28.127 -8.571]
iteration:2
(v_0[m/s], phi[deg]) = (34.99989946, 33.62470728)
L= 355.2
z(T)=[ 87.431 14.044 29.144 -10.019]
iteration:3
(v_0[m/s], phi[deg]) = (35.0000608, 31.38027123)
(略)
iteration:10
(v_0[m/s], phi[deg]) = (35.0017249, 25.02229195)
L= 23.62
z(T)=[ 95.15 0.314 31.717 -14.595]
最初の10回で $L$ は大きく減少し,ボールも距離95m, 高さ31cmのところまで来るように改善されたことがわかります.
最初の10回のボールの軌道を描いてみます.
orbits[0].shape
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
for ( i,orb) in zip(n_itr,orbits):
ax.plot(orb[0],orb[1], label=i)
ax.legend(loc = 'upper left')
ax.set_xlabel('x')
ax.set_ylabel('y')
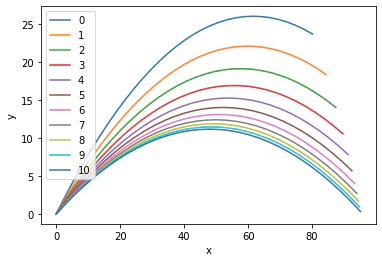
最初は山なりすぎて距離も不十分だったのが,回を追うごとに改善され距離が伸びていっているのがわかります.
メインループ
学習率の最適化はとくに行なっていませんが,10000回学習してみます.
for i in range(11, 10001):
L_val,z_T_val, zt_val = forward()
c_val, *other = backward(z_T_val)
if i % 1000 ==0:
L_val,z_T_val, zt_val = forward(ts=ts)
print('iteration:{}'.format(i))
print('(v_0[m/s], phi[deg]) = ({:.10}, {:.10})'.format(c_val[0], 360*c_val[1]/(2*np.pi)))
print('L= {:.4}'.format(L_val))
print('z(T)={}'.format(z_T_val))
iteration:1000
(v_0[m/s], phi[deg]) = (35.23499705, 23.79747929)
L= 12.87
z(T)=[ 96.718 -1.448 32.239 -15.183]
(略)
iteration:10000
(v_0[m/s], phi[deg]) = (36.19416377, 23.79747929)
L= 0.5038
z(T)=[ 99.351 -0.286 33.117 -14.795]
計算結果
print('(v_0[m/s], phi[deg]) = ({:.10}, {:.10})'.format(c_val[0], 360*c_val[1]/(2*np.pi)))
print('L= {:.4}'.format(L_val))
print('z(T)={}'.format(z_T_val))
(v_0[m/s], phi[deg]) = (36.19416377, 23.79747929)
L= 0.5038
z(T)=[ 99.351 -0.286 33.117 -14.795]
ボールの位置は,ミットまで65cmのところまできたようです.もっと回数を増やせば,より近づきます.
解析的に求めた最適解と比較します.
v0_ana = np.sqrt( (100.0/3.0)**2 + (9.8*t_end/2.0)**2 ) #analytical solution of v_0
print('v_0_ana = {}'.format(v0_ana))
phi_ana = np.arctan2(9.8*3/2, 100.0/3)
print('phi_0_ana = {:.10}[rad]={:.10}[deg]'.format(phi_ana, 360*phi_ana/(2*np.pi)))
# error
er_v_0 = c_val[0]-v0_ana
er_phi = c_val[1]-phi_ana
print('error = {:.8}, {:.8}'.format(er_v_0,er_phi))
v_0_ana = 36.430771486630796
phi_0_ana = 0.4153443673[rad]=23.79747929[deg]
error = -0.23660771, -2.220446e-16
角度は非常に高い精度で一致してますね.
最終的なボールの軌道をみてみます.
L_val,z_T_val, zt_val = forward(ts=ts)
plt.plot(zt_val[0,:],zt_val[1,:])
plt.xlabel('x')
plt.ylabel('y')
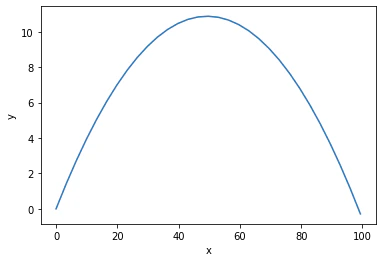
縦横比のせいで全然レーザーに見えない...
まとめ
neural ode の論文とに載っているものと本質的には同じ手法で,損失関数を最小化する最適なパラメータ $\boldsymbol{c}$ を求めることができました. ニューラルネットのような離散的な層の代わりにODEが入ったとしても誤差逆伝播ができるということをみました. Neural ODE では $f$ をニューラルネットで実装し,そのパラメータ $\theta$ を学習することが主要な課題になりますが,今回はODEの $f$ は固定し,パラメータ更新は行わなかったので,それは次回の課題とします. $f$ を適宜ニューラルネットに置き換えて問題を適切に設定すれば,neural ode となります.
code
githubにてjupyter notebook を公開しています.
https://github.com/yymgch/ode_tf/blob/master/laser-beam-neural-ode.ipynb
TODO
- バッチ処理化
- GPU上で微分方程式を解く
- TensorFlow 2.0 への対応