元論文
Making Deep Neural Networks Robust to Label Noise: a Loss Correction Approach
CVPR2017に投稿された論文です。
概要
学習データにラベルノイズ、すなわち誤ったラベルの付与されたデータがあるときにノイズの影響を少なくしてネットワークを学習する手法を提案しています。ポイントは損失関数にラベル間違い確率の情報を付加する点です。損失に少し手を加えるだけで良いので簡単に実装できます。また、論文では複数のデータセットにおける実験結果も豊富に紹介されており、適応範囲の広さが感じられます。
手法
クラス数を$c$とする時、ノイズ発生確率を表す$c\times c$行列$T$を下記のように定義します。
$$
T_{i,j} = p(\tilde{y}=e^j|y=e^i)
$$
$y$は真のラベル、$\tilde{y}$は間違っている可能性のある観測できるラベルです。$e^i$は$i$番目の要素のみ1のone-hotなベクトルで$y=e^i$はラベル$y$がクラス$i$に相当しているということです。すなわち、$T_{i,j}$は真のクラス$i$のデータにクラス$j$のラベルが付与される確率を表しています。$T$の行ベクトルの総和は1になります。
$c=3$の場合について具体例を見てみます。
ノイズの発生確率が
$$
T = \left(
\begin{array}{ccc}
1.0 & 0.0 & 0.0 \
0.0 & 1.0 & 0.0 \
0.2 & 0.0 & 0.8
\end{array}
\right)
$$
で与えられる時、真のクラスがクラス0、クラス1の時に誤ったラベルが付与されることはありませんが、クラス2のときは20%の確率で誤ってクラス0のラベルが付与されてしまいます。
ノイズ発生確率が既知の場合
まずは行列$T$が既知という前提で損失関数を修正します。
まず
$$
l(e^i,p(y|x))=-(e^i)^{\mathrm{T}}log~\hat{p}(y|x)=-log~\hat{p}(y=e^i|x)
$$
を定義すると、通常のクロスエントロピーは$\mathbb{E}_{x,y}l(y,f(x,\theta))$とかけます。$f(x,\theta)$はネットワークの出力で、$i$番目の要素が$\hat{p}(y=e^i|x)$の$c$次元のベクトルです。
論文では、この損失を以下のように置き換える手法を提案しています。
$$
\mathbb{E}_{x,\tilde{y}}l(\tilde{y},T^{\mathrm{T}}f(x,\theta))
$$
これをforward correctionと呼びます。理論的な証明もなされていますが、今回は省略します。
定性的には間違え先のクラスに対しては損失を小さくし、間違え元のクラスに対しては損失を大きくすることで本来の分布に近づけていると考えることができます。
先程の例を使うと、クラス0のデータ$x$に対して
$$
f(x,\theta)=\left(
\begin{array}{ccc}
0.8 \
0.1 \
0.1
\end{array}
\right)
$$
のとき、通常であれば損失は
$$
l=-log
\left(
\begin{array}{ccc}
1 & 0 & 0
\end{array}
\right)
\left(
\begin{array}{ccc}
0.8 \
0.1 \
0.1
\end{array}
\right)
=-log~0.8
$$
ですが、forward correctionを行うと
$$
l=-log
\left(
\begin{array}{ccc}
1 & 0 & 0
\end{array}
\right)
\left(
\begin{array}{ccc}
1.0 & 0.0 & 0.0 \
0.0 & 1.0 & 0.0 \
0.2 & 0.0 & 0.8
\end{array}
\right)^{\mathrm{T}}
\left(
\begin{array}{ccc}
0.8 \
0.1 \
0.1
\end{array}
\right)
=-log~0.82
$$
となり、損失は小さくなります。
一方、クラス2のデータ$x$に対して
$$
f(x,\theta)=\left(
\begin{array}{ccc}
0.1 \
0.1 \
0.8
\end{array}
\right)
$$
のとき、通常であれば損失は
$$
l=-log
\left(
\begin{array}{ccc}
0 & 0 & 1
\end{array}
\right)
\left(
\begin{array}{ccc}
0.1 \
0.1 \
0.8
\end{array}
\right)
=-log~0.8
$$
ですが、forward correctionを行うと
$$
l=-log
\left(
\begin{array}{ccc}
0 & 0 & 1
\end{array}
\right)
\left(
\begin{array}{ccc}
1.0 & 0.0 & 0.0 \
0.0 & 1.0 & 0.0 \
0.2 & 0.0 & 0.8
\end{array}
\right)^{\mathrm{T}}
\left(
\begin{array}{ccc}
0.1 \
0.1 \
0.8
\end{array}
\right)
=-log~0.64
$$
となり損失は大きくなりす。このように間違え先のクラス0に対しては損失を小さくし、間違え元のクラス2に対しては損失を大きくなるよう修正していることがわかります。
ノイズ発生確率が未知の場合
実用的な応用を考えた時、ノイズ発生確率が既知のケースは殆どありません。論文では$T$を推定する方法を提案しています。
まず、ノイズありのデータで通常通りネットワーク$\theta_{c}$を学習します。このネットワークの出力$f(x,\theta_c)$は$\hat{p}(\tilde{y}|x)$とみなせます。
次に以下の手順で$T$の推定値$\hat{T}$を求めます。
$$
\begin{eqnarray}
\newcommand{\argmax}{\mathop{\rm arg~max}\limits}
\bar{x}^i &=& \argmax_{x\in X'} \hat{p}(\tilde{y}=e^i|x) \
\hat{T}_{i,j}&=&\hat{p}(\tilde{y}=e^j|\bar{x}^i)
\end{eqnarray}
$$
$X'$は学習データと分布の等しいデータ集合です。学習データでも構いません。$X'$の中で最もクラス$i$である確率の高いサンプル$\bar{x}^i$のネットワークの出力を$\hat{T}$の$i$行目とします。
論文には書かれていませんが、重要な注意点として、ネットワークにドロップアウトなどの過学習を抑制するファンクションがないとノイズラベルを過学習してしまい$\hat{T}$は単なる単位行列になっています。
実験
MNISTで以下のようにノイズ発生確率を設定し、実験を行いました。
$$
T=\left(
\begin{array}{cccccccccc}
0.4&0 &0 &0.1&0 &0 &0.1&0 &0.2&0.2\
0 &0.4&0 &0 &0 &0 &0.1&0.3&0 &0.2\
0.1&0 &0.4&0 &0 &0 &0 &0.2&0.2&0.1\
0.2&0 &0 &0.4&0 &0.1&0 &0 &0.3&0 \
0 &0.1&0 &0 &0.4&0 &0 &0.1&0.1&0.3\
0 &0 &0 &0 &0 &0.4&0.3&0 &0.2&0.1\
0.1&0 &0 &0.1&0 &0.2&0.4&0 &0.2&0 \
0 &0.3&0.1&0 &0 &0 &0 &0.4&0 &0.2\
0.1&0 &0 &0.3&0 &0 &0.1&0 &0.4&0.1\
0 &0.1&0.1&0.1&0.2&0 &0 &0.1&0 &0.4\
\end{array}
\right)
$$
ネットワーク構造は論文の実験と同じユニット数784-128-128-10のdense networkで、各層の間にドロップアウトを入れています。
結果は以下のようになりました。
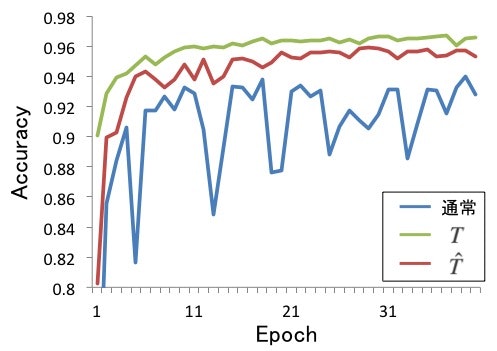
青線が通常のクロスエントロピーで学習した精度です。かなりノイズを加えたつもりでしたが、そのままでも意外と精度が出たことに驚きました。これはドロップアウトの貢献が大きく、ドロップアウトがないと精度は大きく下がります。
とはいえ、ノイズ発生確率$T$を既知とした場合(緑線)では最も精度がよく、推定値$\hat{T}$を用いた場合(赤線)も通常より精度が向上しました。
推定値$\hat{T}$は以下のようになりました。(少数第3位以下四捨五入)
$$
\hat{T}=\left(
\begin{array}{cccccccccc}
0.40 &0.00 &0.00 &0.12 &0.00 &0.00 &0.10 &0.00 &0.17 &0.22 \
0.00 &0.40 &0.00 &0.00 &0.00 &0.00 &0.10 &0.30 &0.00 &0.20 \\
0.10 &0.00 &0.45 &0.00 &0.00 &0.00 &0.00 &0.19 &0.21 &0.06 \
0.20 &0.00 &0.00 &0.45 &0.00 &0.06 &0.00 &0.00 &0.29 &0.00 \
0.00 &0.11 &0.00 &0.00 &0.40 &0.00 &0.00 &0.11 &0.13 &0.25 \
0.00 &0.00 &0.00 &0.00 &0.00 &0.42 &0.26 &0.00 &0.17 &0.16 \
0.10 &0.00 &0.00 &0.11 &0.00 &0.16 &0.45 &0.00 &0.18 &0.00 \
0.00 &0.34 &0.06 &0.00 &0.00 &0.00 &0.00 &0.41 &0.00 &0.19 \
0.03 &0.00 &0.00 &0.20 &0.00 &0.01 &0.10 &0.00 &0.63 &0.04 \
0.00 &0.08 &0.01 &0.01 &0.12 &0.00 &0.00 &0.10 &0.08 &0.59
\end{array}
\right)
$$
なかなか良い推定値が得られていると思います。
今回の実験はMNISTの問題が簡単すぎたこともありnoise correctionの恩恵が少なく感じられましたが、論文に載っているCIFAR10やCIFAR100の結果ではより大きな効果を発揮していることがわかります。