TL;DR
私がコードレビューで見ているポイント
- 関数名・変数名は動作と一意に対応しているか
- 型は取りうる値を正しく表現しているか
- 関数は1つの責任に絞られているか
- ネストは浅く整理されているか
- 重複処理は共通化されているか
- ドキュメントとコードに齟齬はないか
- 実装・ライブラリの使い方に一貫性があるか
コードレビューの観点
色々と見る観点はあると思いますが、私が見ている代表的な項目を紹介します。
良いコードの定義はプロジェクト要件や各個人によって異なって当然であるため、
この記事の内容を盲目的に信じないでください。
関数名・変数名
snake_case や CamelCase といった命名ルールは linter で確認できるため、目では見ません。
私が確認するのは、その変数名・関数名が英語として直感的にわかるものになっているか、意味が一意になっているかの観点です。
以下で足し算をする関数を例を考えてみます。
![]() Not good
Not good
/* - x, y のどちらが底で冪指数か変数名から読み取れない
- 何を計算する関数なのか関数名からわからない */
int calc(int x, int y)
{
// r がどういう意図で宣言された変数かわからない
int r = 1;
for (int i = 0; i < y; ++i)
{
r *= x;
}
return (r);
}
![]() Good
Good
int calc_pow(int base, int exp)
{
int result = 1;
for (int i = 0; i < exp; ++i)
{
result *= base;
}
return (result);
}
どちらの関数も、処理を全て読めば何をする関数かは理解できます。
しかし、関数名や変数名だけを見て、それがどういう役割を持っているものなのか理解できるとコードを読む人の認知負荷が下がります。
英語での命名については、以下のような工夫も考えられます。
- 現在完了形の関数名にする際は動詞を過去分詞に変化させる
- 戻り値で配列が返る場合は名詞を複数形にする
型
型は、その変数が取りうる値のみ表現できる方が分かりやすいと考えています。
以下で、偶奇判定をする関数を例に見てみます。
![]() Not good
Not good
/* 戻り値が int 型だと、どの戻り値がどの状態を表現しているのか分かりづらい */
int is_even (int num)
{
if (num % 2 == 0)
return (0);
return (1);
}
![]() Good
Good
#include <stdbool.h>
/* 戻り値が bool だと、true or false の 2 値のみ取りうることが
明確にわかるので、今回のケースに適している */
bool is_even (int num)
{
if (num % 2 == 0)
// 関数名 is_even が true を返すので、関数名との対応もOK
return (true);
return (false);
}
単一責任
「一つの関数は一つの処理のみ請け負う」のが綺麗で読みやすいです。これは、単一責任の原則という言葉で知られています。
以下で最小公倍数を求める関数を例に見てみます。
前提として、a と b の最小公倍数は、a / (a と b の最大公約数) * b で求めることができるので、これを使います。
![]() Not good
Not good
int calc_lcm(int a, int b)
{
// 最大公約数の計算
int gcd = a;
int temp = b;
while (temp != 0)
{
int remainder = gcd % temp;
gcd = temp;
temp = remainder;
}
// 最小公倍数の計算
int lcm = a / gcd * b;
return (lcm);
}
![]() Good
Good
// 最大公約数の計算
int calc_gcd(int a, int b)
{
int gcd = a;
int temp = b;
while (temp != 0)
{
int remainder = gcd % temp;
gcd = temp;
temp = remainder;
}
return (gcd);
}
int calc_lcm(int a, int b)
{
int gcd = calc_gcd(a, b);
// 最小公倍数の計算
int lcm = a / gcd * b;
return (lcm);
}
これくらいのコード量だと差を感じにくいですが、コードベースが大きくなればなるほどその可読性や保守性は下がって行きます。
ネスト
ネストが深いと大変読みづらいです。
以下で、年齢を入力としてカテゴライズ結果を表示するコードを例に見てみます。
![]() Not good
Not good
#include <stdio.h>
void categorizeAge(int age)
{
if (age >= 0)
{
if (age < 13)
{
printf("Child\n");
}
else
{
if (age < 20)
{
printf("Teenager\n");
}
else
{
if (age < 65)
{
printf("Adult\n");
}
else
{
printf("Senior\n");
}
}
}
} else {
printf("Invalid age\n");
}
}
![]() Good
Good
#include <stdio.h>
void categorizeAge(int age)
{
if (age < 0)
{
printf("Invalid age\n");
return ;
}
if (age < 13)
{
printf("Child\n");
return ;
}
if (age < 20)
{
printf("Teenager\n");
return ;
}
if (age < 65)
{
printf("Adult\n");
return ;
}
printf("Senior\n");
}
ロジック
レビュイーが、関数に要求する動作を明記できていて、それを実装で実現できているかを確認します。
一般的には、以下のような方法で確認します。
- 関数名が動作を一意に示している
- 例えば、
bool is_even(int)という関数はtrueを返せば引数は偶数、falseを返せば引数は奇数だと分かります
- 例えば、
- 動作を保証するためのテストコードがあって、テストを通っている
- 期待する戻り値についてコメントが書かれている
関数の動作では、境界値、異常値の扱いや、副作用などについてもコメントやテストを記述すると、より良くなります。
DRY(Don't repeat yourself) 原則
同じ処理を違う場所で書いているコードは、共通化します。
1, 2 行のコードを共通化しても逆にコードがかさばるので、全てを共通化する必要はありません。
今後も同じ処理が出てきそうだったり、共通処理が長めだったり、共通化するメリットが十分な場合に共通化を検討します。
![]() Not good
Not good
#include <stdio.h>
void print_admin_user()
{
printf("Name: admin\n");
printf("Role: Administrator\n");
}
void print_guest_user()
{
printf("Name: guest\n");
printf("Role: Guest\n");
}
int main()
{
print_admin_user();
print_guest_user();
return (0);
}
![]() Good
Good
#include <stdio.h>
void print_user(const char *name, const char *role)
{
printf("Name: %s\n", name);
printf("Role: %s\n", role);
}
int main()
{
print_user("admin", "Administrator");
print_user("guest", "Guest");
return (0);
}
ドキュメント
コードの修正に注力しすぎて、ドキュメントの修正を忘れることはよくあります。
コードとドキュメントで言ってることに食い違いがあると、プロジェクトに新規参入してきたメンバーは結構困ると思います。
ドキュメントの修正は生成 AI に手伝ってもらうと捗ります。
テストケース
単体テストで必要なテストケースは割と明確ですが、結合テスト以降は書く人の経験値によって結構差が出ると思います。特に自分より経験の浅いレビュイーのテストコードを見る際は、カバレッジ等も確認しつつテスト漏れがないか想像力を働かせて確認します。
実装の一貫性
外部ライブラリや標準ライブラリの使い方、関数の呼び出し方、データ構造の扱い方などが一貫性を持っていることを確認します。プロジェクト内で複数のライブラリやモジュールが使われている場合、同じ処理を異なる方法で実装していると保守性の低下につながります。
シンプルな例で見てみます。
![]() Not good
Not good
#include <stdio.h>
#include <string.h>
// プロジェクト内で複数の文字列操作関数を使い分けている
void print_string_v1(char *str)
{
printf("%s\n", str);
}
void print_string_v2(char *str)
{
puts(str);
}
void function1()
{
// ...
print_string_v1("string1");
// ...
}
void function2()
{
// ...
print_string_v2("string2");
// ...
}
int main()
{
function1();
function2();
return (0);
}
![]() Good
Good
#include <stdio.h>
#include <stdlib.h>
// プロジェクト内で一貫した文字列出力関数を使う
void print_string(const char *str)
{
printf("%s\n", str);
}
void function1()
{
// ...
print_string("string1");
// ...
}
void function2()
{
// ...
print_string("string2");
// ...
}
int main()
{
function1();
function2();
return (0);
}
番外編:本当にあった怖い Pull Request
これが来たときは震えて泣きました。
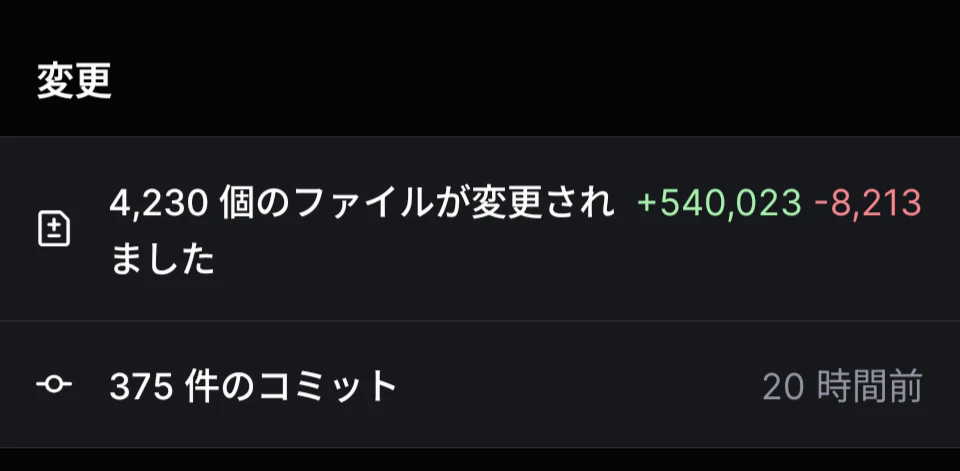
この Pull Request が怖かった理由は二つあります。
一つは「単純にデカすぎる」、もう一つは「全てが生成 AI によって書かれ、レビュイーはそのレビューをしていない」ことです。
-
大規模な Pull Request
- 大量の変更が来る Pull Request はレビュー負荷が高く、レビュアーのモチベ、作業効率を下げる
- 可読性や品質の観点からも小さな粒度で分割して提出するのがベター
- 個人的に Pull Request を作成する際の変更は、10 ファイル以下、1000行以下を意識している
- Pull request が大きくなりすぎる原因の多くは、適切な粒度でタスク分解ができていないことにある
-
生成 AI に書かせたコード
- 生成 AI が書いたコードはなんだか問題なく動くように見える
- 例外処理が雑
- 値をハードコードしてくる
- 見落としや誤りが含まれている場合が多い
- .env とか全然 commit してくる
- テストを通すために、落ちているテストケースをコメントアウトしてくる
- いらんコメントが多すぎる
結論:AI に書かせてもいいけど、レビュイーがコードに責任を持って Pull Request を出そう‼️
まとめ
この記事を書いていて思いましたが、大体リーダブルコードに書いてあることでした。
リーダブルコードを読もう。