2025/12/17現在、本記事の設定は experimental です。
仕様は変わる可能性があります。
2025年12月12日にリリースされた GPT-5.2 では、Reasoning Effort を low / medium / high / xhigh の 4 段階で指定できます。
Reasoning Effort をタスクの難易度によって切り替えることで、簡単なタスクは高速に、複雑なタスクはじっくりと推論させることができます。
Cursor や Codex ではモデル選択画面で GPT-5.2 Extra High や xhigh を選べますが、VS Code の GitHub Copilot では Reasoning Effort がモデル選択画面に表示されません。
一見すると、VS Code では Reasoning Effort を指定できないように見えます。
実は、VS Code の GitHub Copilot では settings.json に次の設定を書くと、Reasoning Effort を選べます。
{
"github.copilot.chat.useResponsesApi": true,
"github.copilot.chat.responsesApiReasoningEffort": "high"
}
github.copilot.chat.responsesApiReasoningEffort には default / low / medium / high が指定できます。xhigh を指定すると、エディター上ではエラーが出ます。
しかし、xhigh を指定しても GitHub Copilot のリクエスト時にエラーが出ず、xhigh 相当の推論が有効化される ことを確認しています。
xhighを指定した場合、GitHub Copilot による会話履歴の圧縮が頻繁に発生し、性能が落ちていると体感しているため、github.copilot.chat.summarizeAgentConversationHistory.enabledを false に設定することをおすすめします。
xhigh を指定すると、OpenAI 系モデルのうち xhigh 対応ではないものはリクエストするとエラーになります。
以下は GPT-5-mini に xhigh を指定した場合のエラー例です。
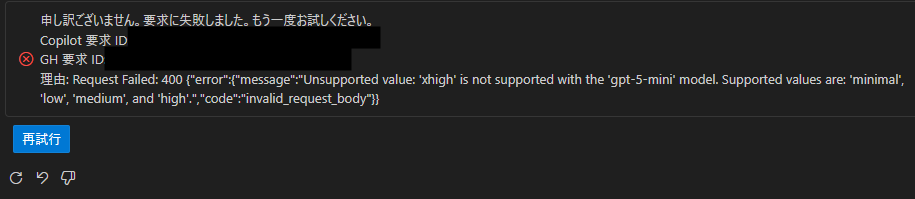
どのように使い分けるべきか?
原則として、Reasoning Effort は xhigh に近づくほどレスポンスが遅くなり、使用するトークン数も増えます。
GitHub Copilot をエージェントとして使う場合はトークン数をあまり気にしなくてよい一方で、レスポンスが遅くなるのは(並列で作業していない限り)時間の無駄になります。
個人的におすすめしたいのは、Reasoning Effort は high(もしくは xhigh)を指定し、軽いタスクは GPT-5.2 を使わずに Claude Haiku 4.5 や Grok Code Fast 1 などの(OpenAI 系以外の)高速モデルを使うことです。
これらのモデルには github.copilot.chat.responsesApiReasoningEffort の設定が影響しないため、通常どおり高速に動きます。
一方で、GPT-5.2 を medium で使いたい場合は、その都度 settings.json を書き換える必要があります。
また、xhigh を指定している場合、 Auto モデルで OpenAI 系モデルを使用した時に、エラーになる場合があります。
おわりに
本記事では VS Code の GitHub Copilot で Reasoning Effort を xhigh に設定する方法を紹介しました。
個人的に、今の Reasoning Effort の設定方法は不便だと感じています。
特に、カスタムエージェントに軽いタスクを任せる場合に OpenAI 系のモデルを指定すると動作しなくなる可能性があるのは問題です。
今後、モデル選択画面から Reasoning Effort を選択できるようになると嬉しいと考えています。