はじめに
こんにちは、ゆうやです。初めて投稿します。
僕は個人開発でAIシステムを作っています。
元々はLINEで応対させていたのですが、Obsidianに触れてから、Slackをメインインターフェースとして、毎朝の挨拶、日記の自動生成、知識検索、情報収集など、
生活のあらゆる場面をAIがサポートしてくれるシステムです。
この記事では、システムの全貌を技術的に詳しく解説します。
- なぜ作ろうと思ったのか
- どんな技術を使っているのか
- どんな機能があるのか
- インフラ構成はどうなっているのか
個人開発でここまで作れるんだ、という参考になれば嬉しいです。
🎯 作ろうと思ったきっかけ
Obsidianで日記を書き始めた
2025年7月から、Obsidianで日記を書き始めました。
1日1ファイル、Markdownで記録していく。
最初は手動で書いていましたが、すぐに「めんどくさい」と思うようになりました。
- 毎日ファイルを作成するのが面倒
- フォーマットを統一するのが面倒
- 後から見返すのが面倒
「これ、自動化できないかな?」
そう思ったのが、このシステムを作り始めたきっかけです。
Slackで完結させたかった
Slack使うのって、なんかかっこいいじゃないですか。(!)
「日記を書くためにObsidianを開く」という行為が、地味にハードルが高い。
でも、Slackで話しかけるだけで日記が自動生成されるなら、続けられると思いました。
AIを活用したかった
2023年にChatGPTに出会い、AIの可能性に衝撃を受けました。
「AIを使えば、もっと賢く、もっと効率的に日記が書ける」
- 1日の会話を要約してくれる
- 感情の変化を分析してくれる
- 過去の日記から関連する情報を引っ張ってきてくれる
そんなシステムを作りたいと思いました。
🏗️ システムアーキテクチャ
全体構成図
┌─────────────────────────────────────────────────────────────────┐
│ ユーザー (僕) │
│ │ │
│ Slack │
│ │ │
│ ┌────────────────────────┴────────────────────────┐ │
│ │ │ │
│ ▼ ▼ │
│ ┌────────────────────┐ ┌───────────────────────┐ │
│ │ slack-event-handler│ │ Cloud Scheduler │ │
│ │ (Python) │ │ (定期実行) │ │
│ │ ・RAG検索 │ └──────────┬────────────┘ │
│ │ ・AI対話 │ │ │
│ │ ・レポート生成 │ ▼ │
│ └────────┬───────────┘ ┌────────────────────────┐ │
│ │ │ Go マイクロサービス群 │ │
│ │ │ ・daily_checkin_go │ │
│ │ │ ・daily_reflection_go │ │
│ │ │ ・weekly_report_go │ │
│ │ │ ・process_rss_go │ │
│ │ │ ・cost_report_go │ │
│ │ │ ・on_this_day_go │ │
│ │ └──────────┬─────────────┘ │
│ │ │ │
│ ▼ ▼ │
│ ┌────────────────────────────────────────────────────────┐ │
│ │ Gemini API │ │
│ │ (gemini-2.5-flash-lite) │ │
│ └────────────────────────────────────────────────────────┘ │
│ │ │
│ ┌────────────────────────┴────────────────────────┐ │
│ ▼ ▼ │
│ ┌────────────────────┐ ┌────────────────────────┐ │
│ │ Cloud Storage │ │ Firestore │ │
│ │ (GCS) │ │ ・会話履歴 │ │
│ │ ・Markdown日記 │ │ ・RSS既読管理 │ │
│ │ ・画像 │ │ ・キャッシュ │ │
│ │ ・支出CSV │ └────────────────────────┘ │
│ └────────────────────┘ │
└─────────────────────────────────────────────────────────────────┘
データ同期フロー(Obsidian → GCS)
Obsidianで書いた日記が、GCSとFile Search Storeに同期されるまでの流れです。
┌─────────────────────────────────────────────────────────────────────────────┐
│ │
│ 📱 ローカル(Mac / iPhone) │
│ │
│ ┌──────────────────────┐ │
│ │ Obsidian │ │
│ │ (iCloud同期) │ │
│ │ │ │
│ │ ・日記を書く │ │
│ │ ・メモを作成 │ │
│ │ ・既存ノートを編集 │ │
│ └──────────┬───────────┘ │
│ │ │
│ │ iCloud Drive 自動同期 │
│ ▼ │
│ ┌──────────────────────┐ │
│ │ iCloud Drive │ │
│ │ (Mac ローカル) │ │
│ └──────────┬───────────┘ │
│ │ │
│ │ Git commit & push │
│ ▼ │
└─────────────────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────────────┐
│ │
│ 🐙 GitHub │
│ │
│ ┌──────────────────────┐ ┌──────────────────────────────────────┐ │
│ │ hogehoge/Obsidian │────────▶│ GitHub Actions │ │
│ │ (Private Repo) │ push │ ・sync-knowledge-base.yml │ │
│ │ │ trigger │ ・scheduled-jobs.yml │ │
│ └──────────────────────┘ └──────────────────┬───────────────────┘ │
│ │ │
└───────────────────────────────────────────────────────┼─────────────────────┘
│
│ gsutil rsync
▼
┌────────────────────────────────────────────────────────────────────────────┐
│ │
│ ☁️ Google Cloud Platform │
│ │
│ ┌──────────────────────────────────────────────────────────────────────┐ │
│ │ Cloud Storage (GCS) │ │
│ │ hogehoge-knowledge-base │ │
│ │ │ │
│ │ knowledge-base/ │ │
│ │ ├── 02_note/02_doing/2025年12月/20251225_今日の出来事.md │ │
│ │ ├── 04_bookmarks_x/... │ │
│ │ ├── 07_rss/... │ │
│ │ └── ... │ │
│ └────────────────────────────────────┬─────────────────────────────────┘ │
│ │ │
│ │ Eventarc トリガー │
│ │ (ファイルアップロード時) │
│ ▼ │
│ ┌──────────────────────────────────────────────────────────────────────┐ │
│ │ import_to_file_search (Cloud Run) │ │
│ │ │ │
│ │ ・Markdownファイル検知 │ │
│ │ ・ディレクトリに基づいてStore振り分け │ │
│ │ ・REST APIでFile Search Storeにアップロード │ │
│ │ ・Firestoreにメタデータ保存 │ │
│ └────────────────────────────────────┬─────────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌──────────────────────────────────────────────────────────────────────┐ │
│ │ Gemini File Search Store │ │
│ │ │ │
│ │ ┌─────────────────────┐ ┌─────────────────────┐ │ │
│ │ │ obsidian-vault │ │ obsidian-vault2 │ │ │
│ │ │ │ │ │ │ │
│ │ │ ・日記 │ │ ・Xブックマーク │ │ │
│ │ │ ・メモ │ │ ・YouTube │ │ │
│ │ │ ・思考 │ │ ・RSS │ │ │
│ │ │ ・X投稿 │ │ │ │ │
│ │ └─────────────────────┘ └─────────────────────┘ │ │
│ └──────────────────────────────────────────────────────────────────────┘ │
│ │ │
│ │ RAG検索で参照 │
│ ▼ │
│ ┌──────────────────────────────────────────────────────────────────────┐ │
│ │ slack-event-handler (Cloud Run) │ │
│ │ │ │
│ │ Slackでメンションされたら、File Search Storeを検索して回答 │ │
│ └──────────────────────────────────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────────────────────┘
技術スタックまとめ
| カテゴリ | 技術 | 用途 |
|---|---|---|
| メイン言語 | Python 3.11 | AI処理、複雑なロジック |
| サブ言語 | Go 1.21 | 定期ジョブ、高速処理 |
| AIモデル | Gemini 2.5 Flash Lite | テキスト生成、要約、画像解析 |
| インフラ | Google Cloud (GCP) | フルサーバーレス構成 |
| IaC | Terraform | インフラのコード管理 |
| データベース | Firestore | 会話履歴、メタデータ |
| ストレージ | Cloud Storage (GCS) | Markdown、画像、CSV |
| メインUI | Slack | ユーザーインターフェース |
| 知識ベース | Obsidian | Markdownベースのノート |
🔧 コアサービス詳解
1. slack-event-handler (Python)
システムの心臓部です。
Slackからのイベント(メンション、メッセージ)を受け取り、適切な処理に振り分けます。
# 主なエンドポイント
POST / # Slackイベント受信
POST /process-diverse-news # 多様なニュース配信
POST /spend/weekly # 週次支出レポート
POST /spend/monthly # 月次支出レポート
POST /insight/daily # 日次洞察生成
主な機能:
- RAG検索: 過去の日記やWikiを検索し、文脈を踏まえた回答
- AI対話: Gemini APIを使った自然な会話
- レポート生成: 日次・週次・月次・四半期レポート
- 支出管理: CSVから予算残高を計算
ファイル構成:
slack_event_handler/
├── main.py # エントリーポイント (382KB!)
├── rag_handlers.py # RAG検索ロジック
├── report_generators.py # レポート生成
├── conversation_handlers.py # 対話処理
├── budget_manager.py # 予算管理
├── spend_analyzer.py # 支出分析
├── insight_miner.py # 洞察生成
├── slack_helpers.py # Slack API操作
├── mcp_tools/ # MCPツール群
│ └── google_calendar/ # Googleカレンダー連携
└── utils/ # ユーティリティ
├── error_handler.py
├── logger.py
└── cache.py
リソース設定:
# Terraform (cloud_run.tf)
resources {
limits = {
cpu = "1000m"
memory = "1Gi"
}
cpu_idle = true # コスト最適化
}
timeout = "900s" # 15分タイムアウト
2. daily_checkin_go (Go)
毎朝7:30に実行される、朝の挨拶ジョブです。
// 主な処理
1. 昨日の日記をGCSから取得
2. 天気情報を取得(OpenWeatherMap API)
3. Googleカレンダーから今日の予定を取得
4. 健康データ(睡眠、歩数)を取得
5. Gemini APIで朝の挨拶メッセージを生成
6. Slackに送信
Slack通知例:
おはようございます、ゆうやさん!☀️
【今日の天気】
松江市:晴れ、最高気温 15℃
【今日の予定】
・10:00 定例ミーティング
・14:00 歯医者
【昨日の振り返り】
・睡眠時間: 7.5時間
・歩数: 6,234歩
・主な出来事: VBA開発が完了しました
今日も良い一日を!💪
3. daily_reflection_go (Go)
毎日22:00に実行される、日記自動生成ジョブです。
// 主な処理
1. Slack APIでその日の会話履歴を取得
2. 健康データを取得(睡眠、歩数、心拍数)
3. Gemini APIで1日の要約を生成
4. Markdownフォーマットで日記を作成
5. GCSに保存
6. GitHubにバックアップ同期
生成される日記の例:
---
created: 2025-12-25 00:00:00
updated: 2025-12-25 00:00:00
tags:
- 仕事完了
- 達成感
- VBA
---
# 2025年12月25日 - VBA開発完了の日
## 📋 今日のサマリー
### 主な出来事
1. 開発が完了
2. 年末までの仕事が実質終了
### ヘルスケア記録
- 睡眠時間: 8.0時間
- 歩数: 3,467歩
- 平均心拍: 85 bpm
## 🌟 今日の気づき
...
4. weekly_report_go (Go)
毎週日曜11:00に実行される、週次レポート生成ジョブです。
// 主な処理
1. 過去7日分の日記をGCSから取得
2. RSS通知のサマリーを取得
3. 健康データの週間推移を集計
4. Gemini APIで週次レポートを生成
5. Slackに送信 + GCSに保存
週次・月次・四半期の3種類:
-
weekly: 毎週日曜11:00 -
monthly: 月末11:00 -
quarterly: 3/6/9/12月末11:00
5. process_rss_go (Go)
1日3回(8時、12時、17時)実行される、情報収集ジョブです。
もちろんQiita、Zennもチェックしています。
下記記事を参考にSlack版でも作りました。
// 主な処理
1. 登録済みRSSフィードをチェック
2. キーワードに関連する記事をチェック
3. Gemini APIが重要度判定
4. 一番上の重要度のものをSlackに通知
5. Firestoreに既読フラグを保存
購読しているフィード:
- https://zenn.dev/feed
- https://qiita.com/popular-items/feed.atom
- https://www.lifehacker.jp/feed/index.xml
- 技術ブログRSSアグリゲーター
キーワードフィルタ:
AWS, 生成AI, Python, Javascript, GAS,
Docker, メンタル, Git, Cursor, Claude, Obsidian
6. cost_report_go (Go)
毎朝8:00に実行される、GCPコスト通知ジョブです。
// 主な処理
1. BigQueryの課金エクスポートテーブルにクエリ
2. 昨日のGCP利用料を集計
3. Slackに通知
通知例:
📊 GCPコストレポート(昨日分)
Cloud Run: ¥32
Cloud Storage: ¥8
Gemini API: ¥156
合計: ¥196
⏰ 定期ジョブスケジュール
Cloud Schedulerで管理している定期ジョブ一覧です。
| 時間 (JST) | ジョブ名 | 内容 |
|---|---|---|
| 07:30 | daily_checkin_go |
朝の挨拶、天気、予定確認 |
| 08:00 | process_rss_go |
朝の技術ニュースチェック |
| 08:00 | on_this_day_go |
1年前の今日の日記を通知 |
| 08:00 | cost_report_go |
前日のGCPコスト通知 |
| 08:00 | diverse-news |
多様なニュース配信 |
| 12:00 | process_rss_go |
昼の技術ニュースチェック |
| 14:00 | diverse-news |
多様なニュース配信 |
| 17:00 | process_rss_go |
夕方の技術ニュースチェック |
| 21:00 | insight-daily |
日次簡易洞察生成してSlackに送信 |
| 22:00 | daily_reflection_go |
1日のまとめ、日記生成 |
| 毎週金曜 22:30 | generate_weekly_journal_audio |
(後述します) |
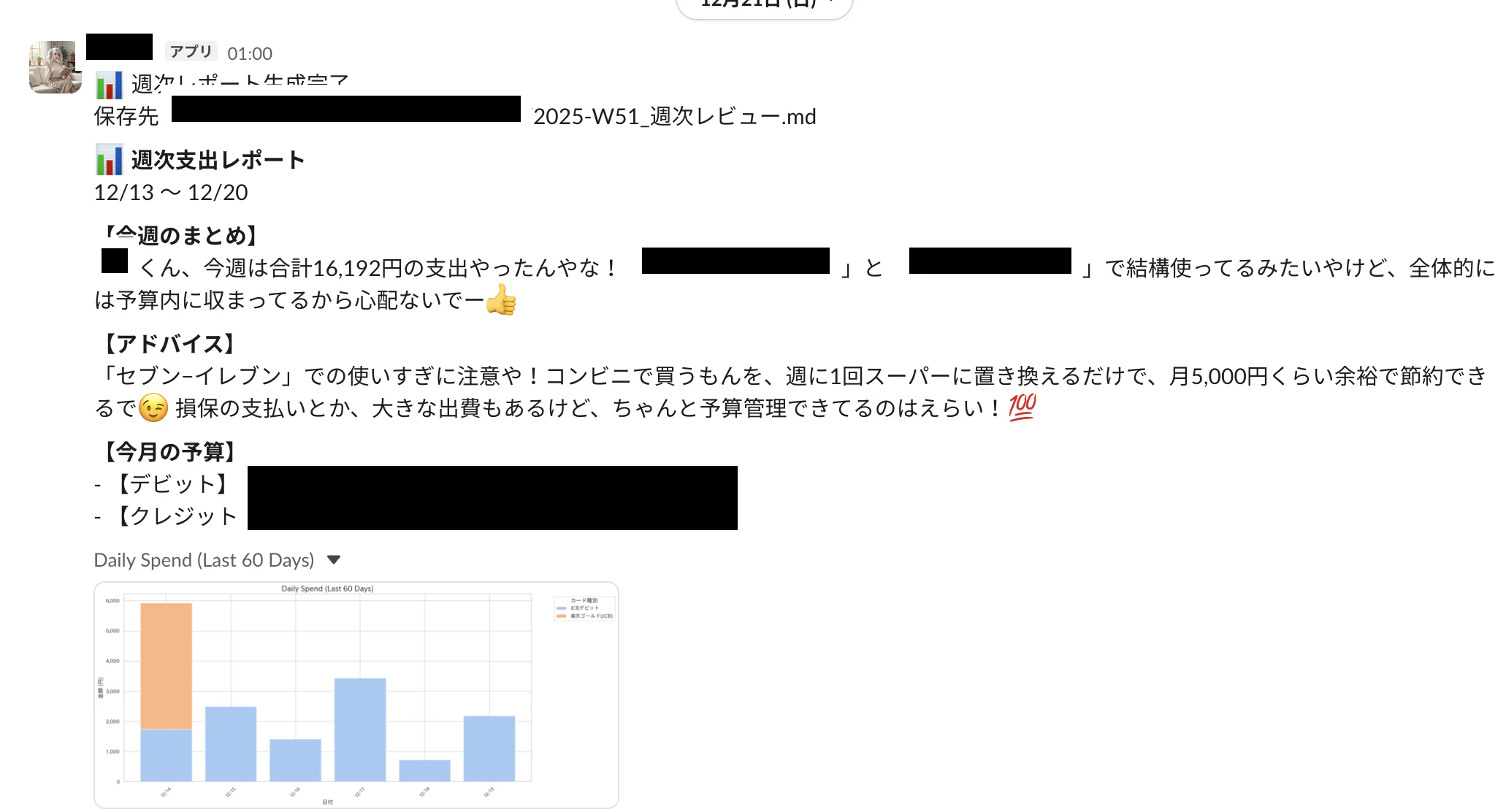
| 日曜 01:00 | spend-weekly |
週次支出レポート |
| 日曜 11:00 | weekly_report_go |
週次レビュー生成 |
| 月末 11:00 | monthly_report_go |
月次レビュー生成 |
| 四半期末 11:00 | quarterly_report_go |
四半期レビュー生成 |
📂 Terraform によるインフラ管理
IaC ディレクトリ構成
IaC/
├── cloud_run.tf # Cloud Runサービス定義 (591行)
├── scheduler.tf # Cloud Schedulerジョブ定義 (307行)
├── storage.tf # GCSバケット定義
├── iam.tf # IAM権限設定
├── apis.tf # API有効化
├── variables.tf # 変数定義
└── versions.tf # プロバイダ設定
Cloud Run サービス例
# slack-event-handler (メインサービス)
resource "google_cloud_run_v2_service" "slack_event_handler_tokyo" {
name = "slack-event-handler"
location = "asia-northeast1"
ingress = "INGRESS_TRAFFIC_ALL"
template {
containers {
image = "gcr.io/${var.project_id}/slack-event-handler:latest"
resources {
limits = {
cpu = "1000m"
memory = "1Gi"
}
cpu_idle = true # 使用していない時はCPUを解放
}
# 環境変数 (抜粋)
env {
name = "GCP_PROJECT"
value = var.project_id
}
env {
name = "CHANNEL_2_AI_ASSISTANT_ID"
value = "ABC"
}
}
timeout = "900s" # 15分
}
}
Cloud Scheduler ジョブ例
# 定期ジョブ定義 (mapで管理)
locals {
scheduler_jobs = {
"daily-reflection-go" = {
schedule = "0 22 * * *"
description = "日記自動生成(毎日22時)"
target_service = "daily-reflection"
path = "/"
},
"shinmizuki-weekly-report" = {
schedule = "0 11 * * 0"
description = "週次レビュー生成(毎週日曜11時)"
target_service = "weekly-report"
path = "/"
}
}
}
resource "google_cloud_scheduler_job" "jobs_tokyo" {
for_each = local.scheduler_jobs
name = each.key
schedule = each.value.schedule
time_zone = "Asia/Tokyo"
http_target {
http_method = "POST"
uri = "${google_cloud_run_v2_service...uri}${each.value.path}"
}
}
💾 データストレージ
Cloud Storage (GCS)
バケット: hogehoge-knowledge-base
hogehoge-knowledge-base/
├── 02_note/
│ ├── 02_doing/
│ │ └── 2025年12月/
│ │ ├── 20251225_今日の出来事.md
│ │ └── ...
│ └── 03_published/
├── 09_reviews/
│ ├── weekly/
│ ├── monthly/
│ └── quarterly/
├── 10_healthcare/
│ ├── sleep/
│ ├── steps/
│ └── heart_rate/
├── 11_spend/
│ ├── 2025_12_クレジットカード.csv
│ └── ...
└── integrations/
└── google_calendar/
└── token.json
Firestore
コレクション構成:
firestore/
├── conversations/ # 会話履歴
│ └── {user_id}/
│ └── {timestamp}/
├── rss_read_status/ # RSS既読管理
│ └── {feed_url_hash}/
└── cache/ # 一時キャッシュ
🧠 AI処理の詳細
Gemini API の使い方
使用モデル: gemini-2.5-flash-lite
選定理由:
- 高速: レスポンスが速い
- 安価: コスト効率が良い
- 十分な性能: 日記要約や会話には十分
# Pythonでの使用例 (slack_event_handler)
from google import genai
client = genai.Client()
response = client.models.generate_content(
model="gemini-2.5-flash-lite",
contents=[
{"role": "user", "parts": [{"text": prompt}]}
],
config={
"temperature": 0.7,
"max_output_tokens": 2048,
}
)
// Goでの使用例 (daily_checkin_go)
import "github.com/google/generative-ai-go/genai"
client, _ := genai.NewClient(ctx, option.WithAPIKey(apiKey))
model := client.GenerativeModel("gemini-2.5-flash-lite")
resp, _ := model.GenerateContent(ctx, genai.Text(prompt))
RAG(検索拡張生成)
過去の日記や知識ベースを検索して、文脈を踏まえた回答を生成します。
# RAG検索の流れ
1. ユーザーの質問を受け取る
2. 質問をベクトル化
3. GCS内のMarkdownファイルを検索
4. 関連する文書を上位5件取得
5. 検索結果 + 質問をGeminiに送信
6. 文脈を踏まえた回答を生成
📚 Gemini File Search Store 自動インポート
概要
import_to_file_search は、Cloud StorageにアップロードされたMarkdownファイルを、自動的にFile Search StoreにインポートするCloud Functionです。
これにより、Obsidianに書いた日記やメモが、リアルタイムでRAG検索の対象になります。
アーキテクチャ
┌─────────────────────────────────────────────────────────────┐
│ Cloud Storage (yuyayoshiok-knowledge-base) │
│ │ │
│ │ ファイルアップロードイベント │
│ ▼ │
│ ┌────────────────────────────────────────┐ │
│ │ import_to_file_search (Python) │ │
│ │ ・ファイル内容を取得 │ │
│ │ ・File Search Storeを選択 │ │
│ │ ・REST APIでアップロード │ │
│ │ ・Firestoreにメタデータ保存 │ │
│ └────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌────────────────────────────────────────┐ │
│ │ Gemini File Search Store │ │
│ │ ・obsidian-vault (日記、メモ) │ │
│ │ ・obsidian-vault2 (ブックマーク、RSS) │ │
│ └────────────────────────────────────────┘ │
└────────────────────────────────────────────────────────────┘
File Search Storeの振り分けロジック
ファイルパスに基づいて、適切なStoreに振り分けます。
def _select_store_by_path(file_path: str) -> str:
"""
ファイルパスに基づいて適切なFile Search Storeを選択
"""
# obsidian-vault2に追加するディレクトリ
vault2_dirs = ["04_bookmarks_x", "06_youtube", "07_rss"]
path_parts = file_path.split("/")
if len(path_parts) >= 2:
dir_name = path_parts[1]
if dir_name in vault2_dirs:
return "obsidian-vault2"
# デフォルトはobsidian-vault(日記、メモ、思考など)
return "obsidian-vault"
| Store名 | 対象 |
|---|---|
obsidian-vault |
日記、メモ、思考、X投稿 |
obsidian-vault2 |
Xブックマーク、YouTube、RSS |
アップロード処理
Gemini File Search Store REST APIを使用してアップロードします。
def upload_to_file_search_store(
api_key: str,
store_name_full: str,
display_name: str,
content: str,
mime_type: str = "text/markdown",
) -> dict:
"""ファイル内容をFile Search Storeにアップロード"""
url = f"{UPLOAD_BASE_URL}/{store_name_full}:uploadToFileSearchStore"
params = {"key": api_key, "uploadType": "multipart"}
metadata = {
"displayName": display_name,
"mimeType": mime_type,
}
files = {
"metadata": ("metadata", json.dumps(metadata), "application/json"),
"file": (display_name, content.encode("utf-8"), mime_type),
}
resp = requests.post(url, params=params, files=files, timeout=300)
resp.raise_for_status()
# 非同期オペレーションの完了を待つ
operation_name = resp.json().get("name")
# ... ポーリング処理 ...
無料版 + 有料版の並行インポート
API制限を回避するため、無料版と有料版の両方のAPIキーでインポートします。
api_keys_to_use = [
{"secret_id": "gemini-api-key", "type": "free"},
{"secret_id": "gemini-api-key-paid", "type": "paid"}
]
for key_info in api_keys_to_use:
api_key = access_secret(key_info["secret_id"], project_id)
store_name_full = get_or_create_file_search_store(api_key, store_name)
upload_to_file_search_store(api_key, store_name_full, ...)
Firestoreへのメタデータ保存
インポート結果はFirestoreに保存し、重複チェックやエラー追跡に活用します。
doc_data = {
"file_path": file_path,
"bucket_name": bucket_name,
"file_size": blob.size,
"content_hash": hashlib.sha256(content.encode()).hexdigest(),
"uploaded_at": datetime.utcnow(),
"store_name": store_name,
"status": "completed", # or "failed"
}
db.collection("rag_metadata").document(doc_id).set(doc_data, merge=True)
効果
- リアルタイム同期: ファイルをアップロードするだけでRAG検索対象に
- 自動振り分け: ディレクトリ構造に基づいて適切なStoreへ
- 冗長性: 無料版 + 有料版の両方にインポート
- 追跡可能: Firestoreでメタデータ管理
🎤Gemini TTS による音声生成
概要
週刊ジャーナルの音声版を、Gemini TTSで生成しています。
毎週金曜22:30に、1週間のSlack会話を分析して「編集長コラム」を生成し、音声ファイルをSlackに投稿します。
ユースケース
- 週刊ジャーナル音声版: 1週間の振り返りを音声で確認
- AI編集長のコラム朗読: 雑誌の巻頭コラム風のテキストを読み上げ
- MP3でSlack投稿: 音声ファイルをダウンロードして通勤中に聴ける
処理フロー
1. チャンネルから1週間分のメッセージを取得
2. Gemini APIで分析(頻出キーワード、感情傾向など)
3. AI編集長として巻頭コラムを生成
4. Gemini TTSで音声に変換(PCM → MP3)
5. SlackにMP3ファイルをアップロード
実装コード
def generate_weekly_journal_audio(journal_text: str, project_id: str) -> Optional[bytes]:
"""週刊ジャーナルの音声版を生成(Gemini TTS使用)"""
# テキストからマークダウン記法を除去
audio_text = journal_text
audio_text = re.sub(r'^#+\s+.*$', '', audio_text, flags=re.MULTILINE)
audio_text = re.sub(r'^---.*$', '', audio_text, flags=re.MULTILINE)
audio_text = audio_text.strip()
# Gemini TTS APIを使用
from google.genai import types
response = client.models.generate_content(
model="gemini-2.5-flash-preview-tts",
contents=audio_text,
config=types.GenerateContentConfig(
response_modalities=["AUDIO"],
speech_config=types.SpeechConfig(
voice_config=types.VoiceConfig(
prebuilt_voice_config=types.PrebuiltVoiceConfig(
voice_name='Kore', # 日本語対応の音声
)
)
)
)
)
# PCMデータを取得
pcm_data = response.candidates[0].content.parts[0].inline_data.data
# PCMをMP3に変換(pydub使用)
from pydub import AudioSegment
import io
audio_segment = AudioSegment(
pcm_data,
frame_rate=24000, # Gemini TTSは24kHz
channels=1, # モノラル
sample_width=2 # 16bit
)
mp3_buffer = io.BytesIO()
audio_segment.export(mp3_buffer, format="mp3")
return mp3_buffer.getvalue()
Slackへのアップロード
生成したMP3ファイルは、Slack Files APIでアップロードします。
# Slackに音声ファイルをアップロード
if audio_content:
files = {
"file": ("weekly_journal.mp3", audio_content, "audio/mpeg")
}
response = requests.post(
"https://slack.com/api/files.upload",
headers={"Authorization": f"Bearer {slack_token}"},
data={"channels": channel_id},
files=files
)
print(f"✅ Audio version posted to #2_ai-assistant")
週刊ジャーナルの特徴
- 2段階生成: まず分析、次にコラム執筆
- ヘルスケア・天気連携: 睡眠、歩数、天気情報も参照
🔐 セキュリティ
Secret Manager
機密情報はすべてSecret Managerで管理しています。
secrets/
├── slack-bot-token # Slack Bot Token
├── slack-app-token # Slack App Token
├── gemini-api-key # Gemini API Key
├── github-pat-token # GitHub PAT
└── openweathermap-api-key # 天気API
IAM設計
# サービスアカウント
resource "google_service_account" "cloud_run_sa" {
account_id = "cloud-function-sa"
display_name = "Cloud Run Service Account"
}
# 必要な権限のみ付与
# - GCS読み書き
# - Firestore読み書き
# - Secret Manager読み取り
# - BigQuery読み取り
💰 コスト
月間コスト概算
・Cloud Scheduler →20個くらいあるので1日数十円くらいかかっている
・Gemini →無料枠でレート制限になったら有料APIにフォールバックするようにしている
〜以下省略〜
ざっと月¥500〜1000円くらいで運用できています!
コスト最適化のポイント
- cpu_idle = true: 使用していない時はCPUを解放
- 冷却時間を短く: 定期ジョブは最小限のメモリで実行
- Gemini flash-lite: 安価なモデルを使用
- Firestore: 読み書きを最小限に
まとめ
システムの価値
- 毎日の日記が自動生成される: 継続のハードルが劇的に下がった
- 過去の自分を検索できる: RAGで「あの時どうしたっけ?」に即答
- 情報収集が自動化: RSSで技術トレンドをキャッチアップ
- 健康・支出を可視化: データドリブンな生活改善
- ファイルを自動バックアップ: Github、Cloud Storageにもバックアップしています
技術的なポイント
- Python + Go の使い分け: 適材適所で言語を選択
- フルサーバーレス: 維持コストを最小化
- Terraform管理: インフラをコードで管理
- Gemini API: 安価で高速なAI処理
個人開発でここまでできる
クラウドサービスとAIの進化で、個人でも本格的なシステムが作れる時代になりました。
この記事が、同じように「自分だけのAIアシスタント」を作りたい人の参考になれば嬉しいです。
いいね、コメントお待ちしています!