はじめに
本記事ではPythonで勾配ブースティングの実装を行います。データはscikit-learnのサンプルで登録されているデータセットを使用しています。
勾配ブースティングとは
勾配ブースティングは教師あり学習の1種です。繰り返し決定木を学習させてモデルの精度を高める手法となっており、アンサンブル学習に含まれます。なお、分類・回帰の両方で使用することができます。
-
アンサンブル学習
複数のアルゴリズムを用いた学習 -
分類
データがどのグループに属するかを分類する手法 -
回帰
連続した数値の予測する手法
決定木とは
決定木とはデータを基に樹形図を作成し、予測を行うアルゴリズムです。
-
分類で使用する場合のイメージ

-
回帰で使用する場合のイメージ

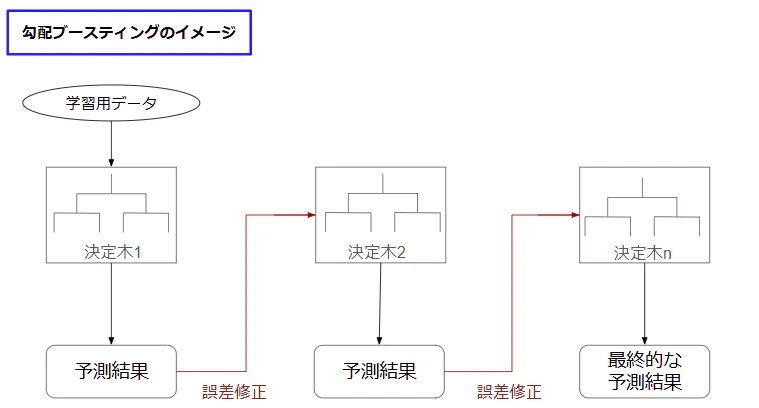
勾配ブースティングの流れ
勾配ブースティングは以下の流れで行います。
- 学習用データから決定木を作成する
- 決定木の予測値と実際の値の誤差を算出する
- 誤差を小さくする決定木を再作成する
- 2と4を繰り返しモデルの精度を高める
Python実行環境
python 3.10.4
Windows 11 Home
勾配ブースティング(分類)の実装
乳がんのデータセット「load_breast_cancer」を使用して勾配ブースティングの分類を行います。
使用するデータの構造
使用するデータの説明変数と目的変数は以下の通りとなっています。
-
説明変数
load_breast_cancerのdataset.dataを使用します。
データの中身は以下で確認することができます。(乳房塊の微細針吸引物のデジタル画像に含まれる細胞核の特徴が入っている模様)説明変数に使うデータの確認import pandas as pd from sklearn.datasets import load_breast_cancer dataset = load_breast_cancer() # 1.データの行数、列数を確認する print(dataset.data.shape) # 2.データのカラムを確認する print(dataset.feature_names) # 3.データのサンプルを表示する sanple_df = pd.DataFrame(dataset.data, columns=dataset.feature_names) print(sanple_df.head(10))実行結果「1.データの行数、列数を確認する」の実行結果(569行30列) (569, 30) 「2.データのカラムを確認する」の実行結果 ['mean radius' 'mean texture' 'mean perimeter' 'mean area' 'mean smoothness' 'mean compactness' 'mean concavity' 'mean concave points' 'mean symmetry' 'mean fractal dimension' 'radius error' 'texture error' 'perimeter error' 'area error' 'smoothness error' 'compactness error' 'concavity error' 'concave points error' 'symmetry error' 'fractal dimension error' 'worst radius' 'worst texture' 'worst perimeter' 'worst area' 'worst smoothness' 'worst compactness' 'worst concavity' 'worst concave points' 'worst symmetry' 'worst fractal dimension'] 「3.データのサンプルを表示する」の実行結果 mean radius mean texture ... worst symmetry worst fractal dimension 0 17.99 10.38 ... 0.4601 0.11890 1 20.57 17.77 ... 0.2750 0.08902 2 19.69 21.25 ... 0.3613 0.08758 3 11.42 20.38 ... 0.6638 0.17300 4 20.29 14.34 ... 0.2364 0.07678 5 12.45 15.70 ... 0.3985 0.12440 6 18.25 19.98 ... 0.3063 0.08368 7 13.71 20.83 ... 0.3196 0.11510 8 13.00 21.82 ... 0.4378 0.10720 9 12.46 24.04 ... 0.4366 0.20750
-
目的変数
load_breast_cancerのdataset.targetを使用します。
データの中身は以下で確認することができます。(悪性か良性かの情報が入っている)目的変数に使うデータの確認import pandas as pd from sklearn.datasets import load_breast_cancer dataset = load_breast_cancer() # 1.データの行数、列数を確認する print(dataset.target.shape) # 2.データの対応を確認する print(dataset.target_names) # 3.データのサンプルを表示する(先頭10件は全て0だったため、末尾を表示) sanple_df = pd.DataFrame(dataset.target, columns=['乳がん診断結果']) print(sanple_df.tail(10))実行結果「1.データの行数、列数を確認する」の実行結果(569行1列) (569,) 「2.データの対応を確認する」の実行結果(0が悪性、1が良性) ['malignant' 'benign'] 「3.データのサンプルを表示する」の実行結果 乳がん診断結果 559 1 560 1 561 1 562 0 563 0 564 0 565 0 566 0 567 0 568 1
作成プログラム
Pythonで勾配ブースティングの分類を実装したプログラムは以下になります。
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import xgboost as xgb
import pandas as pd
import numpy as np
def main():
dataset = load_breast_cancer() #乳がんのデータセットを読み込む
x_train, x_test, y_train, y_test = split_data_set(dataset)
calculate_accuracy(dataset, x_train, x_test, y_train, y_test)
#乳がんのデータを学習用とテスト用に分割する
def split_data_set(dataset):
x = dataset.data #説明変数
y = dataset.target #目的変数
#学習用データ(train)を8割、テストデータ(test)を2割に分ける
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, stratify = y)
return x_train, x_test, y_train, y_test
#勾配ブースティングを使用し、テストデータの正解率を算出する
def calculate_accuracy(dataset, x_train, x_test, y_train, y_test):
model_XGB = make_model(x_train, y_train, dataset)
pred_binary = predict_data(x_test, y_test, dataset, model_XGB)
output_feature_importances(model_XGB)
#正解データと予測データを比較して正解率を算出する
score = accuracy_score(y_test, pred_binary)
print("テストデータの正解率:" + str(score))
#勾配ブースティングを使用しモデルを作る
def make_model(x_train, y_train, dataset):
dtrain = xgb.DMatrix(x_train, label=y_train, feature_names = list(dataset.feature_names))
param = {'max_depth': 8, #決定木の最大深度
'objective': 'binary:logistic' #学習目的
}
num_round = 50 #何回学習を行うか
model_XGB = xgb.train(param, dtrain, num_round)
return model_XGB
#テストデータにモデルを適用し、悪性か良性かを予測する
def predict_data(x_test, y_test, dataset, model_XGB):
dtest = xgb.DMatrix(x_test, label=y_test, feature_names = list(dataset.feature_names))
pred = model_XGB.predict(dtest)
#model_XGB.predictは少数で値が返されるため、四捨五入し2値に変換する
pred_binary = np.where(pred > 0.5, 1, 0)
return pred_binary
#どの説明変数が重要だったかを出力する
def output_feature_importances(model_XGB):
fscore_dict = model_XGB.get_fscore()
feature_names = list(fscore_dict.keys())
dataMatrix = list(fscore_dict.values())
df = pd.DataFrame({"説明変数":feature_names, "重要度":dataMatrix})
df = df.sort_values("重要度", ascending=False)
print(df)
if __name__ == '__main__':
main()
実行結果
-
テストデータの正解率
テストデータの正解率:0.9824561403508771約98%は正解(悪性のデータを正しく悪性、良性のデータを正しく良性と算出)となりました。よって今回作成したモデルの精度は高いと言えます。また、ランダムフォレストでの予測と比較すると正解率が2%向上したため、今回使用したデータに関してはランダムフォレストよりも勾配ブースティングの方が優れていることが分かりました。
-
どの説明変数が重要だったかを出力した結果
説明変数 重要度 worst texture 29.0 worst area 25.0 area error 19.0 mean concave points 14.0 worst concavity 12.0 以降説明変数が続く 以降重要度が続く worst textureが悪性、良性の予測に最も影響していることが分かります。
※train_test_splitで作られる学習用データとテストデータは毎回変わるため、テストデータの正解率、説明変数の重要度も毎回変化します
勾配ブースティング(回帰)の実装
カリフォルニア住宅価格のデータセット「fetch_california_housing」を使用して勾配ブースティングの回帰を行います。
使用するデータの構造
使用するデータの説明変数と目的変数は以下の通りとなっています。
-
説明変数
fetch_california_housingのdataset.dataを使用します。
データの中身は以下で確認することができます。(地域をブロックごとに分けて算出した情報が入っている)説明変数に使うデータの確認import pandas as pd from sklearn.datasets import fetch_california_housing dataset = fetch_california_housing() # 1.データの行数、列数を確認する print(dataset.data.shape) # 2.データのカラムを確認する print(dataset.feature_names) # 3.データのサンプルを表示する sanple_df = pd.DataFrame(dataset.data, columns=dataset.feature_names) print(sanple_df.head(10))実行結果「1.データの行数、列数を確認する」の実行結果(20640行8列) (20640, 8) 「2.データのカラムを確認する」の実行結果 ['MedInc', 'HouseAge', 'AveRooms', 'AveBedrms', 'Population', 'AveOccup', 'Latitude', 'Longitude'] 「3.データのサンプルを表示する」の実行結果 MedInc HouseAge AveRooms AveBedrms Population AveOccup Latitude Longitude 0 8.3252 41.0 6.984127 1.023810 322.0 2.555556 37.88 -122.23 1 8.3014 21.0 6.238137 0.971880 2401.0 2.109842 37.86 -122.22 2 7.2574 52.0 8.288136 1.073446 496.0 2.802260 37.85 -122.24 3 5.6431 52.0 5.817352 1.073059 558.0 2.547945 37.85 -122.25 4 3.8462 52.0 6.281853 1.081081 565.0 2.181467 37.85 -122.25 5 4.0368 52.0 4.761658 1.103627 413.0 2.139896 37.85 -122.25 6 3.6591 52.0 4.931907 0.951362 1094.0 2.128405 37.84 -122.25 7 3.1200 52.0 4.797527 1.061824 1157.0 1.788253 37.84 -122.25 8 2.0804 42.0 4.294118 1.117647 1206.0 2.026891 37.84 -122.26 9 3.6912 52.0 4.970588 0.990196 1551.0 2.172269 37.84 -122.25
-
目的変数
fetch_california_housingのdataset.targetを使用します。
データの中身は以下で確認することができます。(住宅価格の中央値が入っている)目的変数に使うデータの確認import pandas as pd from sklearn.datasets import fetch_california_housing dataset = fetch_california_housing() # 1.データの行数、列数を確認する print(dataset.target.shape) # 2.データの対応を確認する print(dataset.target_names) # 3.データのサンプルを表示する sanple_df = pd.DataFrame(dataset.target, columns=['住宅価格の中央値']) print(sanple_df.head(10))実行結果「1.データの行数、列数を確認する」の実行結果(20640行1列) (20640,) 「2.データの対応を確認する」の実行結果 ['MedHouseVal'] 「3.データのサンプルを表示する」の実行結果 住宅価格の中央値 0 4.526 1 3.585 2 3.521 3 3.413 4 3.422 5 2.697 6 2.992 7 2.414 8 2.267 9 2.611
作成プログラム
Pythonで勾配ブースティングの回帰を実装したプログラムは以下になります。
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_absolute_error
import xgboost as xgb
import pandas as pd
def main():
dataset = fetch_california_housing() #カリフォルニア住宅価格のデータセットを読み込む
x_train, x_test, y_train, y_test = split_data_set(dataset)
check_model_accuracy(dataset, x_train, x_test, y_train, y_test)
#乳がんのデータを学習用とテスト用に分割する
def split_data_set(dataset):
x = dataset.data #説明変数
y = dataset.target #目的変数
#学習用データ(train)を8割、テストデータ(test)を2割に分ける
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
return x_train, x_test, y_train, y_test
#勾配ブースティングで作成したモデルの精度を確認する
def check_model_accuracy(dataset, x_train, x_test, y_train, y_test):
model_XGB = make_model(x_train, y_train, dataset)
pred = predict_data(x_test, y_test, dataset, model_XGB)
output_feature_importances(model_XGB)
#正解データと予測データを比較(平均絶対誤差)してモデルの精度を確認する
score = mean_absolute_error(y_test, pred)
print("平均絶対誤差:" + str(score))
#勾配ブースティングを使用しモデルを作る
def make_model(x_train, y_train, dataset):
dtrain = xgb.DMatrix(x_train, label=y_train, feature_names = list(dataset.feature_names))
param = {'max_depth': 8, #決定木の最大深度
'objective': 'reg:squarederror' #学習目的
}
num_round = 50 #何回学習を行うか
model_XGB = xgb.train(param, dtrain, num_round)
return model_XGB
#テストデータにモデルを適用し、住宅価格を予測する
def predict_data(x_test, y_test, dataset, model_XGB):
dtest = xgb.DMatrix(x_test, label=y_test, feature_names = list(dataset.feature_names))
pred = model_XGB.predict(dtest)
return pred
#どの説明変数が重要だったかを出力する
def output_feature_importances(model_XGB):
fscore_dict = model_XGB.get_fscore()
feature_names = list(fscore_dict.keys())
dataMatrix = list(fscore_dict.values())
df = pd.DataFrame({"説明変数":feature_names, "重要度":dataMatrix})
df = df.sort_values("重要度", ascending=False)
print(df)
if __name__ == '__main__':
main()
実行結果
-
平均絶対誤差
平均絶対誤差:0.3065048385948936平均絶対誤差は約0.31となりました。 平均絶対誤差は0に近いほど正解データと予測データの誤差が小さくモデルの精度が高いと言えます。そのため今回作成したモデルの精度は高いと言えそうです。また、ランダムフォレストでの予測と比較すると平均絶対誤差が約0.08減少したため、今回使用したデータに関してはランダムフォレストよりも勾配ブースティングの方が優れていることが分かりました。
-
どの説明変数が重要だったかを出力した結果
説明変数 重要度 MedInc 1670.0 Latitude 1212.0 Longitude 1146.0 AveOccup 1112.0 HouseAge 1032.0 以降説明変数が続く 以降重要度が続く MedInc(ブロックの所得中央値)が住宅価格の予測に最も影響していることが分かります。
※train_test_splitで作られる学習用データとテストデータは毎回変わるため、平均絶対誤差、説明変数の重要度も毎回変化します
終わりに
Pythonで勾配ブースティングを実装しました。
分類・回帰ともにランダムフォレストより勾配ブースティングの方が良い結果となったため、基本的には勾配ブースティングを優先して使うのが良さそうと感じました。ランダムフォレスト、勾配ブースティングのメリット・デメリットについては別途調査しようと思います。
参考
この記事は以下の動画・記事を参考にして執筆しました。
・Pythonで勾配ブースティング(xgboost)を作ってみよう【Python機械学習#9】
・勾配ブースティング決定木 - 金融エンジニアリング・グループ