xgboostは、決定木モデルの1種であるGBDTを扱うライブラリです。
インストールし使用するまでの手順をまとめました。
様々な言語で使えますが、Pythonでの使い方について記載しています。
GBDTとは
- 決定木モデルの一種
- 勾配ブースティング木
- Gradient Boosting Decision Tree
同じ決定木モデルではランダムフォレストが有名ですが、下記記事が違いを簡潔にまとめられていました。
【機械学習】決定木モデルの違いをまとめてみた - Qiita
GBDTの特徴
- 簡単に良い精度が出やすい
- 欠損値を扱える
- 扱えるのは数値データ
使いやすく精度も良いことから、機械学習コンペティションのKaggleで人気があります。
[1] 使い方
scikit-learnのデータセットの1つである、irisデータ(アヤメの品種データ)を利用しました。OSはAmazon Linux2です。
[1-1] インストール
私が利用しているAmazon Linux2では次の通りです。環境ごとのインストール手順は公式に載っています。
Installation Guide — xgboost 1.1.0-SNAPSHOT documentation
pip3 install xgboost
[1-2] インポート
import xgboost as xgb
[1-3] irisデータの取得
特別な手順はありません。irisデータを取得して、pandasのDataFrameとSeriesを作成します。
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
iris_data = pd.DataFrame(iris.data, columns=iris.feature_names)
iris_target = pd.Series(iris.target)
[1-4] 訓練データとテストデータの取得
ここも特別な手順はなく、scikit-learnのtrain_test_splitでデータを訓練用とテスト用に分割します。
from sklearn.model_selection import train_test_split
train_x, test_x, train_y, test_y = train_test_split(iris_data, iris_target, test_size=0.2, shuffle=True)
[1-5] xgboost用の型に変換する
xgboostではDMatrixを使用します。
dtrain = xgb.DMatrix(train_x, label=train_y)
DMatrixはnumpyのndarrayやpandasのDataFrameから作成できるので、データの扱いに苦労することは無いでしょう。
扱えるデータの種類は公式に詳しく載っています。
Python Package Introduction — xgboost 1.1.0-SNAPSHOT documentation
[1-6] パラメータの設定
各種パラメータの設定を行います。
param = {'max_depth': 2, 'eta': 1, 'objective': 'multi:softmax', 'num_class': 3}
各パラメータの意味は次の通りです。
| パラメータ名 | 意味 |
|---|---|
| max_depth | 木の最大深度 |
| eta | 学習率 |
| objective | 学習目的 |
| num_class | クラス数 |
'objejective'に学習目的(回帰、分類等)を指定します。
今回は多クラス分類なので'multi:softmax'を指定しています。
詳細は公式に詳しく載っています。
XGBoost Parameters — xgboost 1.1.0-SNAPSHOT documentation
[1-7] 学習
num_roundは学習回数です。
num_round = 10
bst = xgb.train(param, dtrain, num_round)
[1-8] 予測
dtest = xgb.DMatrix(test_x)
pred = bst.predict(dtest)
[1-9] 精度の確認
scikit-learnのaccuracy_scoreで正解率を確認します。
from sklearn.metrics import accuracy_score
score = accuracy_score(test_y, pred)
print('score:{0:.4f}'.format(score))
# 0.9667
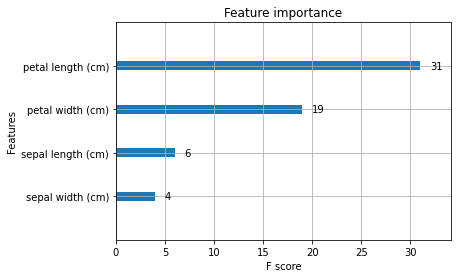
[1-10] 重要度の可視化
どの特徴量が予測結果に寄与したのかを可視化します。
xgb.plot_importance(bst)
[2] 学習中のバリデーションとアーリーストッピング
検証用データを用いた学習中のバリデーションと、アーリーストッピング(学習の打ち切り)も簡単に行うことができます。
[2-1] データの分割
学習用データの一部を検証用データとして使用します。
train_x, valid_x, train_y, valid_y = train_test_split(train_x, train_y, test_size=0.2, shuffle=True)
[2-2] DMatrixの作成
dtrain = xgb.DMatrix(train_x, label=train_y)
dvalid = xgb.DMatrix(valid_x, label=valid_y)
[2-3] パラメータの追加
バリデーションを行う場合には'eval_metric'をパラメータに追加します。'eval_metric'には、評価指標を指定します。
param = {'max_depth': 2, 'eta': 0.5, 'objective': 'multi:softmax', 'num_class': 3, 'eval_metric': 'mlogloss'}
[2-4] 学習
evallistにバリデーションで監視するデータを指定します。検証用データの名称は'eval'、学習用データの名称は'train'を指定します。
xgb.trainの引数としてearly_stopping_roundsを追加しています。early_stopping_rounds=5は5回連続して評価指標が改善しなかったら学習を中断する、ことを意味しています。
evallist = [(dvalid, 'eval'), (dtrain, 'train')]
num_round = 10000
bst = xgb.train(param, dtrain, num_round, evallist, early_stopping_rounds=5)
# [0] eval-mlogloss:0.61103 train-mlogloss:0.60698
# Multiple eval metrics have been passed: 'train-mlogloss' will be used for early stopping.
#
# Will train until train-mlogloss hasn't improved in 5 rounds.
# [1] eval-mlogloss:0.36291 train-mlogloss:0.35779
# [2] eval-mlogloss:0.22432 train-mlogloss:0.23488
#
# 〜〜〜 途中省略 〜〜〜
#
# Stopping. Best iteration:
# [1153] eval-mlogloss:0.00827 train-mlogloss:0.01863
[2-5] 検証結果の確認
print('Best Score:{0:.4f}, Iteratin:{1:d}, Ntree_Limit:{2:d}'.format(
bst.best_score, bst.best_iteration, bst.best_ntree_limit))
# Best Score:0.0186, Iteratin:1153, Ntree_Limit:1154
[2-6] 予測
検証結果のうち最も結果が良かったモデルで予測を行います。
dtest = xgb.DMatrix(test_x)
pred = ypred = bst.predict(dtest, ntree_limit=bst.best_ntree_limit)
終わりに
pandasのDataFrame, Seriesが使えるので、今まで機械学習をやってきた人にとって敷居は低いように感じられました。
今回試したのは多クラス分類ですが、二値分類や回帰にも使用できるので、様々な場面で使うことができるでしょう。