これは「Happiness Chain Advent Calendar 2024」の20日目の記事です。
はじめに
こんにちは。ゆうと申します!
この記事では、ツイートアプリの基本的なモデル定義・API作成を例に、GraphQLの基礎を理解する内容になっています。また、馴染み深いREST APIとどのように違うのかも、簡単ではありますが触れていきたいと思います。
実務でAmplify (AppSync, DynamoDBなどなど) を利用していると、色々とよしなにやってくれることが多いので実際に内部的にどのような挙動になっているのかが見えにくく、勉強がてら実際のGraphQLを使ってAPI構築をしてDBにデータを登録したいと思ったのですが、そんな中以下のような疑問が湧いてきました。
- GraphQLとはそもそも何?何を実装する為の言語なの?
- 通信の際のリクエスト方法は、REST APIと同様にHTTP/HTTPSを利用するのか?
- リゾルバーってなんやねん?なんで必要なん?
- GraphQLにもAPIサーバーとしての機能はあるの?別途Apollo (Apollo Client, Apollo Server) とか入れないとサーバーとしての機能をまかなえないのか?
- Apollo serverを使用した際のは、RDB (PostgreSQL, MySQL)が使用されて、DBとのやりとりにPrismaを使う?その時にリゾルバはどのような役割を果たすのか?
- getUsers、getUser等でユーザーデータ取得するときに「emailを含まない」みたいなのってtypeで指定するのか、リゾルバで指定するのかどっち?それともクライアントからAPIをコールする時に指定するの?
- N+1問題はどのように考慮するのか?
- 自分でGraphQLの実行環境やRDBなどのデータベース環境を用意する場合
- Amplify (AppSync, DynamoDB etc) のマネージドサービスを使用する場合
GraphQLとは?
GraphQLとは、Meta社 (旧Facebook) によって開発されたAPIを実装するためのクエリ言語あるいはそのランタイム (実行環境) のことで、欲しいデータのみを複数のリソースを跨いで一回のリクエストで取得することができます。また、スキーマによるAPIドキュメントとしても役割も担っています。
そもそもAPIとは?
APIとは、リソース間でデータのやりとりをする際の規約のようなもので、「どのようなリクエストがあったら、◯◯のデータを返すのか?」みたいなのを定義している。要は仲介役の事
ex1) レストランのウェイターは、客から入った注文を厨房に伝えたり、出来上がった料理を客に届けたりと、仲介役を果たしている
ex2) キーボードやマウスは、自分の書きたい文字や、クリックしたいサイトなどを、コンピュータに反映することができ、コンピュータと自分自身を繋いでいるインターフェースとなっている
また、GraphQLはREST同様に、HTTP/HTTPSプロトコル上で動作する
- HTTPとは、クライアントとサーバー間の通信プロトコル (取り決め) の事
- HTTPSとは、上記のHTTPにSSL/TLS暗号化を追加したもの
GraphQLの登場で何が変わった?
GraphQLが登場するまで主流だったRESTfulなAPIだと以下のような問題がありました。
- オーバーフェッチングやアンダーフェッチングで実際に使わないカラムまで取得したり、足りないデータがある為に複数のリクエストをおこなう必要がある (パフォーマンスの低下問題)
- リソース毎にエンドポイントが必要なので、複数のリソースをまたいだデータ取得では、複数のリクエストを走らせる必要がある
- データ形式や構造が変わるたびに新しいバージョンのエンドポイントが必要になる (APIのバージョニング問題)
- エンドポイントの設計が、クライアントが必要とするデータ構造に依存してしまう (クライアント・サーバー密結合問題)
GraphQLが登場してから、上記のようなRESTful APIを使用していた際に起こっていた問題を以下のように改善してくれました!
- 複数のリソースをまたぎ必要なフィールドを指定して一回のリクエストでデータ取得できることによって、ネットワークの使用効率・リソースの浪費削減につながる (APIの柔軟性・パフォーマンスの向上)
- スキーマ定義によって、GraphQL APIの構造が明確に記述されたドキュメントとして機能します。そのため、モデル、クエリ・ミューテーション・サブスクリプション、そしてそれらのレスポンスの型が明確になります。また、これらの型定義からTypeScriptの型を自動生成するcodegenツールも存在します。
REST APIとどのように違う?
- REST API
- リソース毎にURLを分割してエンドポイントが存在 (/users, /posts, /comments など)
- HTTPメソッドを活用したCRUD操作 (GET, POST, PUT, DELETE) をおこなう
- GraphQL
- 一つのエンドポイント (/graphql) に対してのリクエストで済む
- 取得したいデータを指定できるので、余計なデータを取得せずに済む
- スキーマによる型付けにより、堅牢な開発ができる (エラーを早急に検知したりなど)
- データの読み取りには
Queryを使用して、追加・変更・削除にはMutationを使用する
REST APIに関しては、拙著で大変恐縮ですが、以下の記事で基礎的な内容をまとめております
REST WebAPI 設計の基礎を簡潔にまとめてみた - Qiita
GraphQLにおけるモデル定義
以下に、ツイートアプリ機能を実装する上で必要なモデルを作成してみました。
# ユーザー定義
type User {
id: ID!
name: String!
email: String!
posts: [Post!]!
comments: [Comment!]!
}
# 投稿定義
type Post {
id: ID!
title: String!
content: String!
createdAt: String!
updatedAt: String!
author: User!
comments: [Comment!]!
}
# コメント定義
type Comment {
id: ID!
content: String!
createdAt: String!
post: Post!
author: User!
}
# クエリ定義
type Query {
getUser(id: ID!): User
getUsers: [User!]!
getPost(id: ID!): Post
getPosts: [Post!]!
getUserPosts(userId: ID!): [Post!]!
getComment(id: ID!): Comment
getComments(postId: ID!): [Comment!]!
}
# ミューテーション定義
type Mutation {
# User操作
createUser(input: CreateUserInput!): User!
updateUser(input: UpdateUserInput!): User!
deleteUser(id: ID!): User!
# Post操作
createPost(input: CreatePostInput!): Post!
updatePost(input: UpdatePostInput!): Post!
deletePost(id: ID!): Post!
# Comment操作
createComment(input: CreateCommentInput!): Comment!
updateComment(input: UpdateCommentInput!): Comment!
deleteComment(id: ID!): Comment!
}
# 入力型定義
input CreateUserInput {
name: String!
email: String!
}
input UpdateUserInput {
id: ID!
name: String
email: String
}
input CreatePostInput {
title: String!
content: String!
authorId: ID!
}
input UpdatePostInput {
id: ID!
title: String
content: String
}
input CreateCommentInput {
content: String!
postId: ID!
authorId: ID!
}
input UpdateCommentInput {
id: ID!
content: String
}
実際のデータ取得イメージ
上記のようなモデル定義を行なって、実際に一回のリクエストで以下のようにユーザーデータと関連するポストやコメントのデータを以下のように取得できます (GraphiQLというクライアントアプリで動作テストできます。画像は、stackblitzのjson-graphql-serverを使って動作テストしています )
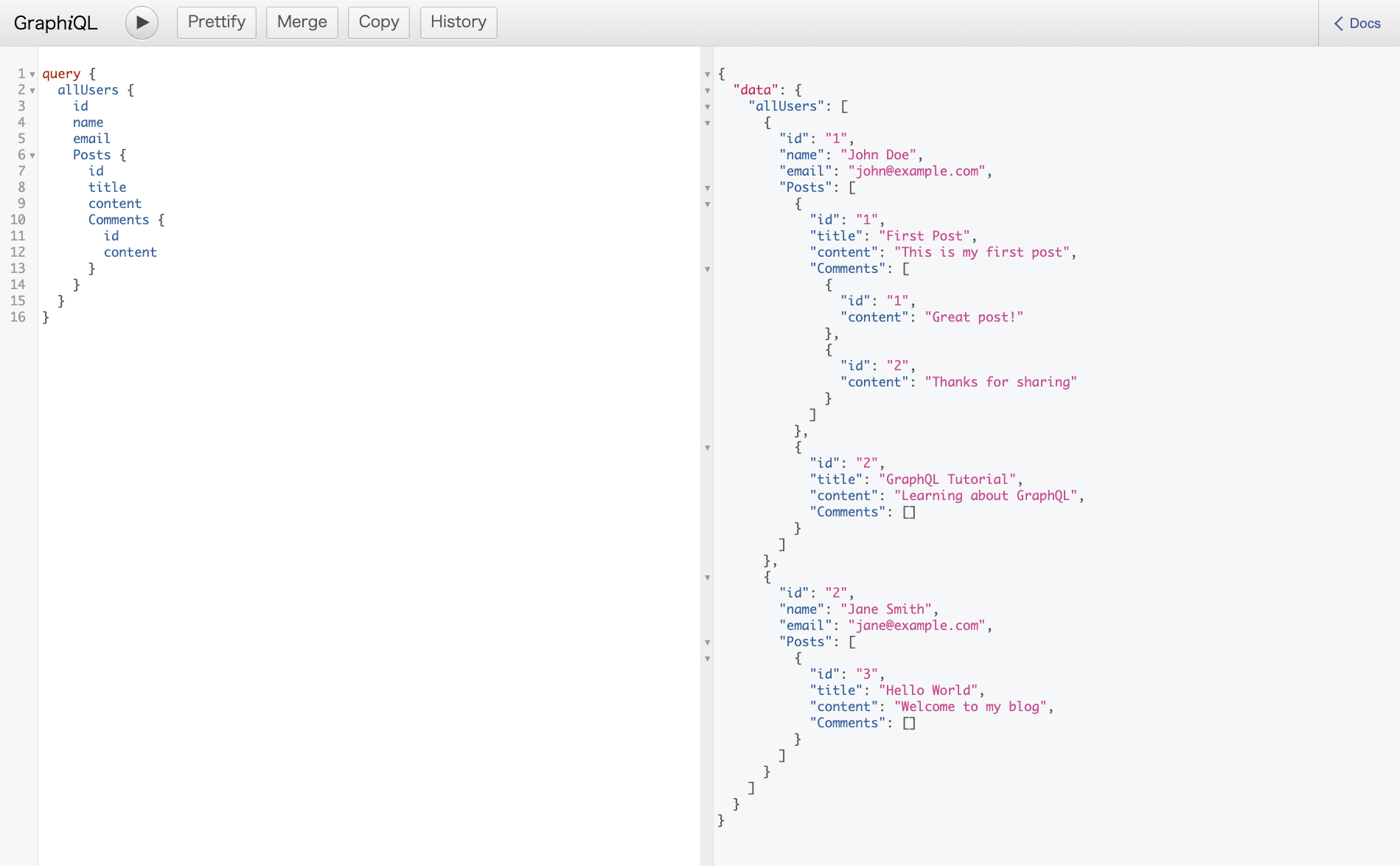
どのようにデータを永続化するのか?
実際に一番イメージが湧かなかったのが、「GraphQLを使ってどのような流れでデータベースにデータを登録するか?」というところです。冒頭に挙げた疑問について簡単に調べた上でまとめさせていただきます。
- リゾルバって何?
- リゾルバとは、実際にサービスに対してリクエストが送信されたときに実装のデータ操作を行う一連の処理をマッピングしている関数の事
- 簡単にいうと、定義したQueryやMutationを実際に実行して、処理が完結するまでの一連の流れ
- GraphQLにもAPIサーバーとしての機能はあるの?別途Apollo (Apollo Client, Apollo Server) とか入れないとサーバーとしての機能を賄えないんか?
- GraphQL自体もランタイムとしての役割 (クエリの解析・バリデーション・クエリの実行・型システムの管理・リゾルバの実行) があるが、これらの機能だけではWeb APIとしては機能せず、別途HTTPリクエスト/レスポンスの処理などを担うサーバーとして機能するライブラリ (Apollo Serverなど) を用意する必要があります
- Amplify (AppSync) を利用する場合は、GraphQLサーバーとしての機能がすでに内包されているので別途サーバー用のライブラリのインストールは不要
- N+1問題について
- prismaのfindManyを使用する場合は、includeを指定して関連するデータも取得するようにできます。また、findUniqueは内部でN+1問題を解決する機構を備えているみたいですが、リレーションが発生するデータモデルの場合はバッチ処理が行われないみたいなので、今回は明示的にincludeを指定しています
- Amplify (AppSync, DynamoDB etc) を使用した場合は、関連データの取得時に個別のクエリではなくBatchGetItemを使用してくれているみたいです
サンプルコード (Apollo Server, Apollo Client, prismaを使用)
実際にクライアントからGraphQL操作を処理するJSのGraphQLサーバーとして Apollo Server を、Apollo Serverに対して、クエリやミューチェーションを実行するJSのGraphQLクライアントとして Apollo Client 、ORMとしてTypeScript用のORMとしてPrismaを使用しています。本当にざっくりと流れを記載しているので、詳細の実装などは参考文献の Apollo ServerとPrismaではじめるGraphQL API開発入門 をご参照ください
型定義
const typeDefs = gql`
// 上記で定義したモデル
`
Apollo Serverの初期化処理
const server = new ApolloServer({
typeDefs, // GraphQLスキーマ定義
resolvers, // リゾルバ関数群 (実際のデータ取得・操作ロジック)
context: { prisma } // リゾルバで使用する共有リソース
});
Apollo Client (フロント側からAPI Call)
// Apollo Clientでのクエリ
// フロントエンド側で取得したいカラムを指定できる (この場合、emailは取得しない)
const GET_USERS = gql`
query GetUsers {
allUsers {
id
name
posts {
id
title
}
}
}
`;
リゾルバの定義 (ここで実際にデータを永続化するための一連の流れを定義)
const resolvers = {
Query: {
// findManyを使用する場合は、includeでN+1問題を考慮
getUsers: async (_, __, { prisma }) => {
const users = await prisma.user.findMany({
include: {
posts: true
}
});
return users;
},
// findUniqueは内部的にバッチ処理されるため、includeは不要
getUser: async (_, { id }, { prisma }) => {
const user = await prisma.user.findUnique({
where: { id: Number(id) }
});
return user;
},
getPosts: async (_, __, { prisma }) => {
const posts = await prisma.post.findMany({
include: {
author: true,
comments: true
}
});
return posts;
},
getPost: async (_, { id }, { prisma }) => {
const post = await prisma.post.findUnique({
where: { id: Number(id) }
});
return post;
},
getUserPosts: async (_, { userId }, { prisma }) => {
const posts = await prisma.post.findMany({
where: { authorId: Number(userId) },
include: {
comments: true
}
});
return posts;
},
getComments: async (_, { postId }, { prisma }) => {
const comments = await prisma.comment.findMany({
where: { postId: Number(postId) },
include: {
author: true
}
});
return comments;
}
}
};
findManyではincludeを使用して、ユーザーに関連するポストを取得する際に各ユーザーに対して個別のクエリが発行されてしまう (N+1問題) ので、1回のクエリで関連データをまとめて取得するようにしています
以下にクライアント側からのAPIの実装呼び出しのコード例になります
const GET_USERS = gql`
query GetUsers {
getUsers {
id
name
posts {
id
title
content
}
}
}
`;
const GET_USER = gql`
query GetUser($id: ID!) {
getUser(id: $id) {
id
name
}
}
`;
const GET_POSTS = gql`
query GetPosts {
getPosts {
id
title
content
author {
id
name
}
comments {
id
content
}
}
}
`;
const GET_POST = gql`
query GetPost($id: ID!) {
getPost(id: $id) {
id
title
content
}
}
`;
const GET_USER_POSTS = gql`
query GetUserPosts($userId: ID!) {
getUserPosts(userId: $userId) {
id
title
content
comments {
id
content
}
}
}
`;
const GET_COMMENTS = gql`
query GetComments($postId: ID!) {
getComments(postId: $postId) {
id
content
author {
id
name
}
}
}
`;
最後に
いかがだったでしょうか?今回は実際にGraphQLを使用する上での疑問を、ツイートアプリに必要なよくあるモデルを参考に疑問を解消してみました!これからGraphQLを触る方でRESTとの違いだったり、実際にどのようなライブラリを使ってサーバーを立てたりデータの永続化を行うのかざっくりとした流れをイメージしていただけましたら幸いです。
参考文献