はじめに
今回は、僕自身も現在駆け出しエンジニア (2年目) で、開発の中でバックエンドの実装を担当する中で、「RESTを理解していないな...」って多々痛感することがあったので、REST WebAPI 設計の基本的な部分を簡潔にまとめさせていただきました
Webサービスの基本
-
Web
- HTTPなどのインターネット関連技術を利用してメッセージ送受信を行う技術、または、それら技術を適用して展開されたサービス
-
API
- 機能やデータを外部から呼び出して利用できるよう定めた規約
-
WebAPI
- HTTPなどのインターネット関連技術を利用して、プログラムが読み書きしやすい形でメッセージ送受信を行えるよう定義した規約、または規約を実装して展開されるサービス
- WebAPIを学ぶとは、規約の作り方・サービスの実装方法を学ぶことを指す
- できる事
- 第3者が情報を利活用して新たな機能を開発できる
- 何が嬉しいか?
- APIエコノミーの実現による自サービスの発展(①から③のサイクル)
- ①WebAPIを提供する
- ②関連サービスができる(スマホアプリ・ガジェット・プラグイン・システム間連携)
- ③自サービスがより成長する
- APIエコノミーの実現による自サービスの発展(①から③のサイクル)
- 価値あるもの(機能やデータ)は全て公開する
- 例えば、飲食店口コミサイトのだと以下の機能
- 飲食店の検索、予約
- 人気店の検索
- 口コミの検索、投稿、修正、削除
- 例えば、飲食店口コミサイトのだと以下の機能
- 価値のないものは公開しない
- 例えば、郵便番号検索などの、他のサービスでも大体できてしまうようなもの
-
WebAPIは、独自の機能を公開するようにする
- 例えば、「生年月日から年齢を算出する機能」は、一般的な機能となる
- 独自性のないものを公開しても価値のない、意味のないものになる
-
WebAPI公開によるリスクと対策
- 一番のリスクは、入るはずの利益が入らなくなる事で以下の2つがあげられる
- ①ユーザーが減る
- 他のサービスが優れている場合は、ユーザー獲得している他サービスの機能を取り込む
- 他サービスで劣っている機能があり、自サービスも同様に評判が落ちている場合は、該当サービスに対して発行していたAPIキーを停止し、WebAPIの提供を停止する
- ②リソースが圧迫される
- API化することで機械的にデータ取得ができるようになったことが原因で、対策としては、該当サービスに対してWebAPIの利用制限をかける(レートリミット)
- →時間あたりに一定のリクエストしか出せないようにする
- API化することで機械的にデータ取得ができるようになったことが原因で、対策としては、該当サービスに対してWebAPIの利用制限をかける(レートリミット)
- ①ユーザーが減る
- データが盗まれるリスクに関しては、そもそもWebAPIでデータを利活用してもらうために公開しているので、あまり考える必要はない
- 一番のリスクは、入るはずの利益が入らなくなる事で以下の2つがあげられる
-
①リクエストライン
- メソッド、リクエストURI、HTTPバージョンで構成される
-
HTTPリクエスト
- リクエストは3要素で構成される
- ①リクエストライン
- メソッド
- リクエストURI
- HTTPバージョン
- ②ヘッダー
- サーバーに対する追加情報を送信
- リクエストラインに続くさまざまなメタデータが含まれる
- Content-Typeには、送信データのフォーマットが入る
- User-Agentには、クライアントのブラウザ情報が入る
- Cookieもヘッダーの中に含まれる
- ③ボディ
- Content-Typeの内容に従って、様々なデータが入る
- prefから始まる
-
メソッドの種類 : CRUDに相当する4メソッドが重要
- Create (作成)
- POST : リソース名が未定
- PUT : リソース名が決まっている
- Read (読み取り)
- GET
- Update (更新)
- PUT
- Delete (削除)
- DELETE
- Create (作成)
-
HTTPレスポンス
- レスポンスは、以下の3要素で構成される
- ①ステータスライン
- 受信に関する基本情報が入る
- HTTPバージョン、ステータスコード、フレーズで構成される
- ステータスコード
- 1xx (Informational) : リクエストは受け入れられたので処理を継続
- 2xx (Success) : リクエストが受け入れられて正常処理された
- 3xx (Redirection) : リクエスト完了のために追加操作が必要
- 4xx (Client Error) : リクエストに誤りがある
- 5xx (Server Error) : サーバー処理失敗
- ②ヘッダー
- ③ボディ
-
安全性と冪等性
-
副作用 : リソース(データ)が改変されること
-
副作用あり
- 実行の都度違う結果になる場合(安全でも冪等でもない)
- POSTメソッド
- 何度実行しても同じ結果になる場合(冪等)
- PUT, DELETEメソッド
- 実行の都度違う結果になる場合(安全でも冪等でもない)
-
副作用なし
- 実行の都度違う結果になる場合(安全でも冪等でもない)
- なし
- 何度実行しても同じ結果になる場合(安全・冪等)
- GET, HEADメソッド
メソッド 安全 冪等 GET ⚪︎ ⚪︎ HEAD ⚪︎ ⚪︎ POST × × PUT × ⚪︎ DELETE × ⚪︎ - 実行の都度違う結果になる場合(安全でも冪等でもない)
-
REST制約
- RESTful
- RESTで求められる原則に従っていること
- REST (REpresentational State Transfer)
- 直訳すると、「分散型システムにおける設計原則群」という意味で、Webサービスの設計モデルや設計原則のことを指す
- クライアント/サーバー間の情報のやりとりの方法に関する指針を提供するが、それだけではなく、Webアプリケーションやサービスのアーキテクチャ全体に関する広範な設計原則や制約を提供するものと理解するのが大事
- Roy Fieldingという人が、2000年に発表した論文の中で定義した
- REST原則は、クライアント/サーバー、ステートレス、キャッシュ制御、統一インターフェース、階層化システム、コードオンデマンドの6種類が定義されている
クライアント/サーバー
- ネットワークベースのアプリケーションではよくある構成(特徴2つ)
- 画面(UI)とデータで関心事を分離
- クライアント側がトリガー、サーバー側は受け身(2000年代当時)
- 最近だとサーバーPUSHもある
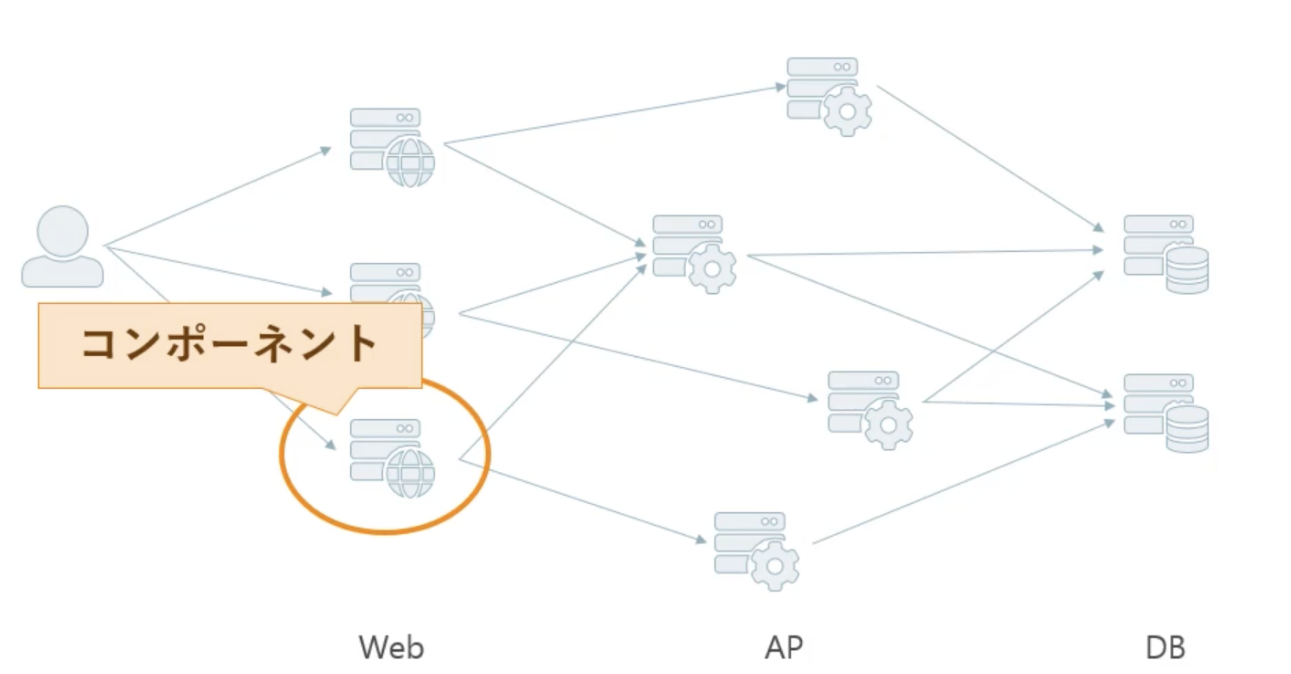
階層化システム
- 多層アーキテクチャ構成
- 複雑な構成になった時の一つのサーバーの事をコンポーネントと呼ぶ
- メリット
- 各システム(コンポーネント)に役割を決めて独立させる(カプセル化する)ことで、進化と再利用が促進できる
- 例えば、レガシーシステムのカプセル化やマイクロサービスのような概念
- 各システム(コンポーネント)に役割を決めて独立させる(カプセル化する)ことで、進化と再利用が促進できる
- デメリット
- データ処理に負荷が掛かる(ユーザーから見ると応答が悪く見える)
- キャッシュを利用すると改善が見込める
- データ処理に負荷が掛かる(ユーザーから見ると応答が悪く見える)
コードオンデマンド
- クライアントがサーバーから実行可能なコードをダウンロードし、ローカルで実行することができる概念のこと
- リリース後にクライアントコードを変更できる
- javaScriptの例でいえば、ポップアップを表示したり、フォームの入力値をチェックしたり、といった機能を追加できる
- メリット
- リリース済みのクライアントに対して機能追加ができる
- サーバーの負荷が下がる(クライアントに処理を譲ることができるため)
- デメリット
- 評価環境が複雑になる(SafariやChromeなど)
- ネットワーク通信におけるプロトコルの可視性が低下する
- 通常のHTTPレスポンスには、ボディにリソースの表現が含まれるが、コードオンデマンドにより表現をクライアント側で決定する場合はそうではない
統一インターフェース
- URIで示したリソースに対する操作を、統一した限定的なインターフェースで行うアーキテクチャスタイルのこと
- 以下の4つの制約で成り立っている
- ①リソースの識別
- URIを用いてサーバーに保存されたデータを識別する
- URIに動作は含まない
- 名前がつけられたあらゆるものがリソース(ドキュメント、画像、人、情報、サービス、状態)
- ある断面(4月1日の天気)や、最新(今日の天気)などの抽象的な定義も含む
- URIを用いてサーバーに保存されたデータを識別する
- ②表現を用いたリソース操作
- 表現とは、リソース(サーバーに保持されたデータ)のある断面のこと
- クライアントへ返されるレスポンスやサーバーへPOSTするデータなど
- 断面情報を利用してサーバー上のデータを操作する
- クライアントからサーバーへ編集リクエストをする際、認証情報などの追加情報(メタデータ)を付与する
- 表現とは、リソース(サーバーに保持されたデータ)のある断面のこと
- ③自己記述メッセージ
- メッセージ内容が何であるか、ヘッダーに記述されている
- レスポンスに含まれるメタ情報(ヘッダー情報)で、内容がどのようなものかわかる
- メッセージ内容が何であるか、ヘッダーに記述されている
- ④アプリケーション状態エンジンとしてのハイパーメディア (HATEOAS)
- HATEOAS (Hypermedia as the Engine of Application State)
- レスポンスに現在の状態を踏まえて関連するハイパーリンクが含まれている
- 例 : 検索結果ページにおける「次のページ」
- HATEOAS (Hypermedia as the Engine of Application State)
- ①リソースの識別
- メリット
- システムアーキテクチャ全体が簡素化されてわかりやすくなる
- 提供するサービスに集中でき、独自の進化ができる
- 異なるブラウザでも同じような画面を表示できる
- デメリット
- 標準化によって効率が犠牲になる
ステートレス
- サーバーはリクエストだけでコンテキストを理解できる
- サーバーに保存されたコンテキスト情報は使わない(サーバーセッションは使わない)
- 状態はクライアント上に保存される(リクエストに全て含める)
- ステートフルとステートレスの違い
- ステートフルは、前の状態を保存しているので、前の会話と次の会話が関連している
- ステートレスは、前の状態を保存せず、それぞれの会話が独立して成立する
- メリット
- 単一のリクエスト以外見る必要がないので、監視が容易
- 障害発生したリクエストだけ回復すれば良いので、障害復旧が容易
- リクエスト全体でサーバーリソースを共有する必要がないので、スケールが用意
- デメリット
- 単一のリクエストで完結させるため、リクエストデータに重複がある
- アプリを複数バージョン同時提供し、状態をクライアントに置いておくとアプリ制御が複雑になる
キャッシュ制御
- クライアント側でレスポンスをキャッシュできるようにしてくださいという制約
- レスポンスは明示的または暗黙的にキャッシュ可能
- キャッシュを適切に行うことで、クライアント/サーバー間の通信が排除され、ユーザー体験の向上、リソース効率の向上、拡張性の向上が見込める
- 古いデータを戻すと、データの不整合が起こってしまい、システムの信頼性の低下につながる
REST API 設計レベル
-
設計レベルは4段階存在し、レベル0〜レベル3まである
-
レベル0 : HTTPを使っている
- REST APIの基本レベルで、RPC (Remote Procedure Call)スタイルのXML通信のようなものを定義している
- RPCは、ネットワーク越しに別コンピュータ上のプログラムを実行する仕組みのこと
- HTTPは、単なる通信手段として利用
- 1URLで全て完結
- リクエストボディに処理と引数が含まれる
- REST APIの基本レベルで、RPC (Remote Procedure Call)スタイルのXML通信のようなものを定義している
-
レベル1 : リソースの概念を導入
- リソースごとにURLを分割する
- HTTPメソッドは活用できていないので、GETかPOSTのみ
-
レベル2 : HTTPの動詞を導入
- レベル1に加えて、HTTPメソッドを活用する
- リソースに対して、HTTPメソッドを活用したCRUD操作が行われている
- REST APIというと、大体このレベルのものが多い
-
レベル3 : HATEOASの概念を導入
- レベル2に加えて、レスポンスにリソース感のつながりが含まれる
- レスポンスに現在の状態に関連するハイパーリンクが含まれている
- → HATEOASに相当する情報がレスポンスに含まれる
- レベル2に加えて、レスポンスにリソース感のつながりが含まれる
REST WebAPI サービス設計
URIの設計
- 短く入力しやすい (冗長なパスを含まない)
- シンプルで覚えやすいものにすることで入力ミスを防ぐ
- NG
GET http://api.example.com/service/api/search
- OK
GET http://api.example.com/search
- 人間が読んで理解できる (省略しない)
- 例えば、そのプロジェクトのみでしか通じない省略記号などは使わない
- 国や文化が変わっても不変な表記にすることで誤認識を防ぐ
- NG
GET http://api.example.com/sv/m
- OK
GET http://api.example.com/movies
- 大文字・小文字が混在していない (全て小文字)
- 統一するなら一般的に小文字
- 単語はハイフンで繋げる
- 「単語を繋ぐ」という意味ではハイフンが適切
- アンダースコアは使わない
- 単語の連結をするくらいなら、そもそもURIを見直すことを考える必要がある
- 単語は複数形を利用する
- URIで表現しているのは「リソースの集合」
- エンコードを必要とする文字を使わない
- URIから意味を理解できない
- サーバー側のアーキテクチャが反映されていない
- 悪意あるユーザーに脆弱性を突かれる危険性がある
- NG
GET : http://api.example.com/cgi-bin/get_user.php?id=12345
- 改造しやすい (Hackable)
- システム依存の設計や、不規則なID、ユーザー固有のトークンやセッション情報を含むURIだと意味が理解できない
- NG
GET : http://api.example.com/products/aif0239fisodif02..03GET : http://api.example.com/session/1234ab/products/5678GET : http://api.example.com/endpointTypeA/operation234
- OK
GET : http://api.example.com/products/12345
- ルールが統一されている
- パスパラメータを使うのかクエリパラメータを使うのかなどを予め決めておく
クエリとパスの使い分け
- クエリパラメータ
- URIの末尾にある
?につづくキーバリューのこと - 省略が可能
GET http://api.example.com/users?page=3
- URIの末尾にある
- パスパラメータ
- URL中に埋め込まれるパラメータのこと
- 一意なリソースを表すのに必要
GET http://api.example.com/users/123
movieをリソースとした場合のCRUD操作のURI、HTTPメソッドの定義
上記のURI設計指針を踏まえた上で、movieをリソースとして、CRUD操作のURI、HTTPメソッドを定義すると以下のようになります
| URI | HTTP method | 操作内容 |
|---|---|---|
| /v1/movies | GET | movieデータ一覧を取得 |
| /v1/movies | POST | 新規のmovieデータを作成 |
| /v1/movies/{id} | GET | 特定のmovieデータを取得 |
| /v1/movies/{id} | PUT | 特定(既存)のmovieデータを更新 |
| /v1/movies/{id} | DELETE | 特定のmovieデータを削除 |
ポイント
- URIは、リソースを示している
- 今回の場合だと「movie」
- HTTPメソッドは、リソースに対する操作
- 今回の場合だと「GET, POST, PUT, DELETE」
ステータスコード
- 処理結果 (HTTPレスポンス)の概要を把握するために使う
- 処理結果の概要は以下の5分類
- 1xx (情報)
- 100 Continue
- サーバーがリクエストの最初の部分を受け取り、まだサーバーから拒否されていないことを示す
- 101 Switching Protocol
- プロトコルの切り替え要求を示す
- 100 Continue
- 2xx (成功)
- 200 OK
- リクエストが成功したことを示す
- 本文にデータが含まれる
- 201 Created
- リクエストが成功し、新しいリソースが作成されたことを示す
- ヘッダーのLocationに新しいリソースへのURLを含める
- 202 Accepted
- 非同期ジョブを受け付けたことを示す
- 処理は完了しておらず、実際の処理結果は別途受け取る
- 204 No Content
- リクエストは成功したが、返すべき内容 (レスポンスデータ)がないことを示す
- クライアント側のビューを変更する必要がないことを意味する
- 200 OK
- 3xx (リダイレクト)
- API利用者はリダイレクトを実装していないことが多いので、REST API では基本的に3xxは利用しない
- 4xx (クライアントサイドエラー)
- 400 Bad Request
- その他エラー
- サーバーは、リクエストを理解できないことを示す
- 401 Unauthorized
- 認証されていないことを示す
- 403 Forbidden
- クライアントのリソースに対するアクセスが許可されていない(認可されていない)ことを示す
- リソースの存在を隠したいときは以下の404を使用する
- 404 Not Found
- リクエストされたリソースが存在しないことを示す
- 409 Conflict
- リソースが競合して処理が完了しなかったことを示す
- 429 Too Many Requests
- アクセス回数が制限回数 (レートリミット)を超えていたため処理できなかったことを示す
- 400 Bad Request
- 5xx (サーバーサイドエラー)
- 500 Internal Server Error
- サーバーサイドのアプリケーションエラーが発生して、リクエストが処理できなかったことを示す
- 503 Service Unavailable
- サーバーが一時的にリクエストを処理できておらず、サービスが利用できないことを示す
- メンテナンス期間や過負荷で応答できないようなケース
- 500 Internal Server Error
- 1xx (情報)
データフォーマット
XML (eXtensible Markup Language)
- タグを使用してデータを構造化するマークアップ言語
- タグは入れ子にすることができ、属性を付与できる
サンプルコード
HTTP/1.1 200 OK
Content-Type: application/xml
<?xml version="1.0" encoding="UTF-8"?>
<movie>
<title>クレヨンしんちゃん 嵐を呼ぶ モーレツ!オトナ帝国の逆襲</title>
<year>2001</year>
<director>渡邊武志</director>
</movie>
JSON (JavaScript Object Notation)
- JavaScriptを元にしたフォーマット
- XMLに比べてデータ量が減らせる (XMLはタグがあるため冗長)
- オブジェクトは入れ子にできる
サンプルコード
HTTP/1.1 200 OK
Content-Type: application/json
{
"movie": {
"title": "クレヨンしんちゃん 嵐を呼ぶ モーレツ!オトナ帝国の逆襲",
"year": 2001,
"director": "渡邊武志"
}
}
JSONP (JSON with Padding)
- JSONPは、データフォーマットのようなJavaScriptコードで、データを関数呼び出しの形式で使う
- クロスドメインでデータを受け渡すことができる
- JSONPを利用する際は、セキュリティ的なリスクが生じるので、現代のフロントエンド開発では、CORS(Cross-Origin-Resource Sharing)という手法を用いる
サンプルコード
HTTP/1.1 200 OK
Content-Type: application/javascript
callbackFunction({
"movie": {
"title": "クレヨンしんちゃん 嵐を呼ぶ モーレツ!オトナ帝国の逆襲",
"year": 2001,
"director": "渡邊武志"
}
});
データの内部構造で考慮すること6つ
エンベロープは使わない
- エンベロープとは、レスポンスボディ内のメタ情報のこと
- 以下のようにするとヘッダー情報と被るので使わないようにする
HTTP/1.1 200 OK
Content-Type: application/json
..省略..
▼NG
{
"header": {
"status": "success",
"errorCode": 0,
},
"response": {
"name": "田中 太郎"
}
}
ーーーーーーーーーーーーーーーーーーーーーー
▼OK
{
"name": "田中 太郎"
}
オブジェクトはできるだけフラットにする
- レスポンス容量を減らすため
▼NG
{
"id": "123",
"name": "田中 太郎",
"profile": {
"birthday": "3/21",
"gender": "male"
}
}
ーーーーーーーーーーーーーーーーーーーーーー
▼OK
{
"id": "123",
"name": "田中 太郎",
"birthday": "3/21",
"gender": "male"
}
ページネーションをサポートする情報を返す
- データが更新 (追加/削除) されたりする可能性があるため
- 「次どこから取得するのか?」というキーとなる情報を返すようにする
{
"movies": [
{
"id": "12345",
"title": "クレヨンしんちゃん 嵐を呼ぶ モーレツ!オトナ帝国の逆襲"
}
],
"hasNext": true,
"nextPageToken": "sirF43Cp"
}
プロパティの命名規則はAPI全体で統一する
- 利用者が混乱しないようにするため
- スネークケースかキャメルケースを使うようにする
日付はRFC3339 (W3C-DTF) 形式を使う
- インターネットで標準的に用いられているため
- ex) :
2023-10-17T09:00:00+09:00
大きな整数 (64bit整数) は文字列を返す
- 通常の整数は32bitで、64bit整数は処理できないため
エラー表現で考慮すること3つ
エラー詳細はレスポンスボディに入れる
- エラーの詳細などの足りない情報は、基本的にはレスポンスボディに追加する
HTTP/1.1 400 Bad Request
Server: api.example.com
Date: Sat, 28 Mar 2020 01:57:25 GMT
Content-Type: application/json
Content-Length: 77
{
"code": "1234567890",
"message": "不正な検索条件です"
}
エラーの際にHTMLが返らないようにする
- レスポンスフォーマットが変わると、クライアントアプリ側で処理できないケースがあるため
- Content-Typeには、application/jsonを指定する
サービス閉塞時は"503" + "Retry-After"で返してあげる
- クライアント側から見て、「いつ再開して良いか」が分かる
HTTP/1.1 503 Service Temporary
Server: api.example.com
Date: Sat, 28 Mar 2020 01:57:25 GMT
Content-Type: application/json
Content-Length: 77
Retry-After: Mon, 6 Apr 2020...
{
"code": "3456789012",
"message": "サービス利用できません"
}
APIバージョンの表現
- 広く世間一般に公開するようなサービスであれば、利用者の利便性を考慮してAPIバージョンを含めたURLの設計を行う
- バージョンを入れる場所は、以下の3種類
- パス
http://api.example.com/v1/movies/
- クエリ
http://api.example.com/movies?version=1
- ヘッダー
GET http://api.example.com/movies X-Api-Version: 1
- パス
- セマンティックバージョニングを前提に、バージョンは後方互換しなくなるメジャーバージョンである
1だけを利用する
OAuthとOpenID Connect
- 認証とは、本人特定のことで、「あなたは本当にあなたですか?」という質問に答えるプロセスのこと
- 認可とは、アクセス制御のことで、「あなたはこれを行う権限がありますか?」という質問に答えるプロセスのこと
- OAuthもOpenID Connectも認可の仕組み
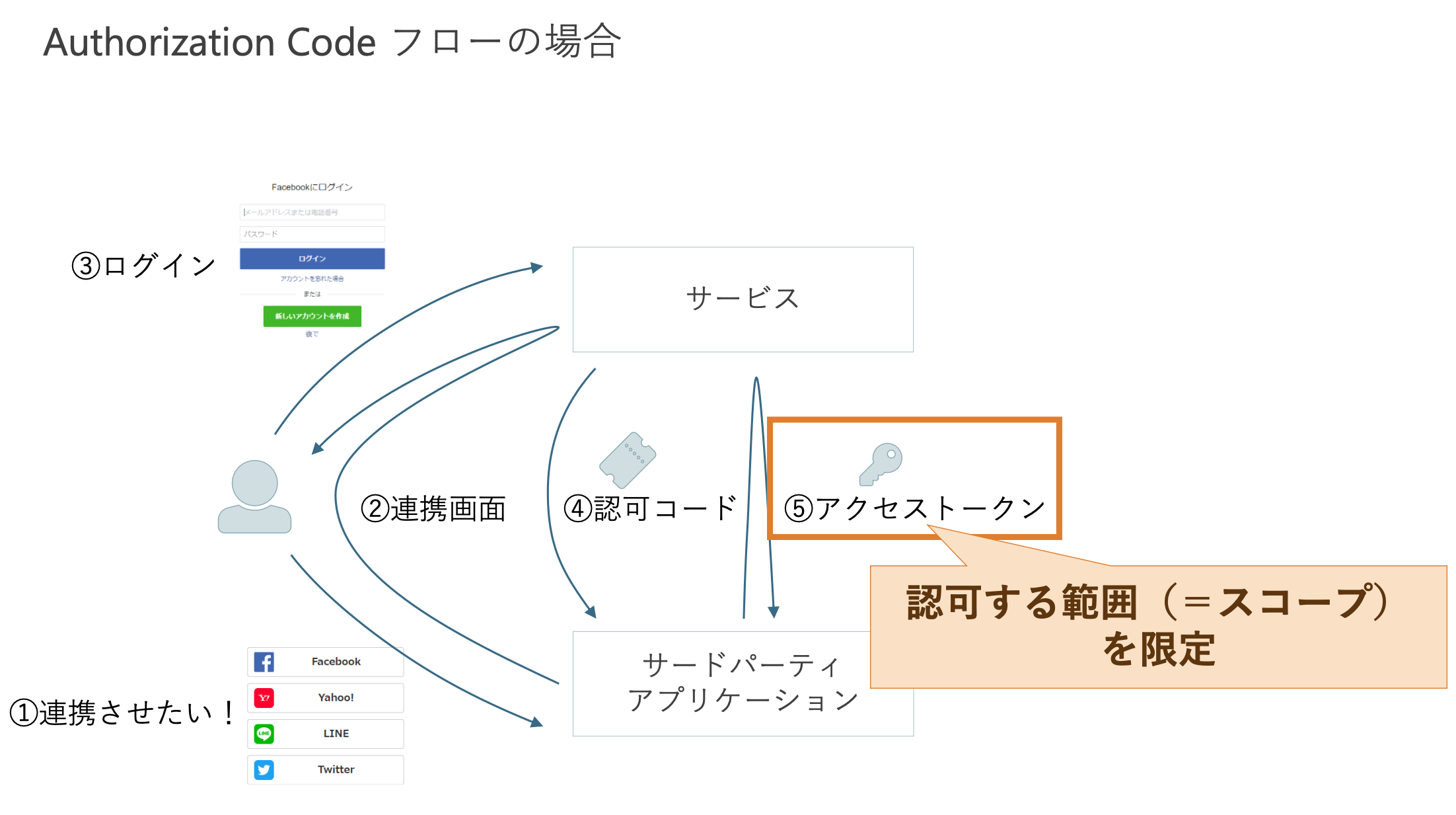
OAuth
- 認可のためのプロトコル
- アクセストークン (認可に必要) のみが使用される
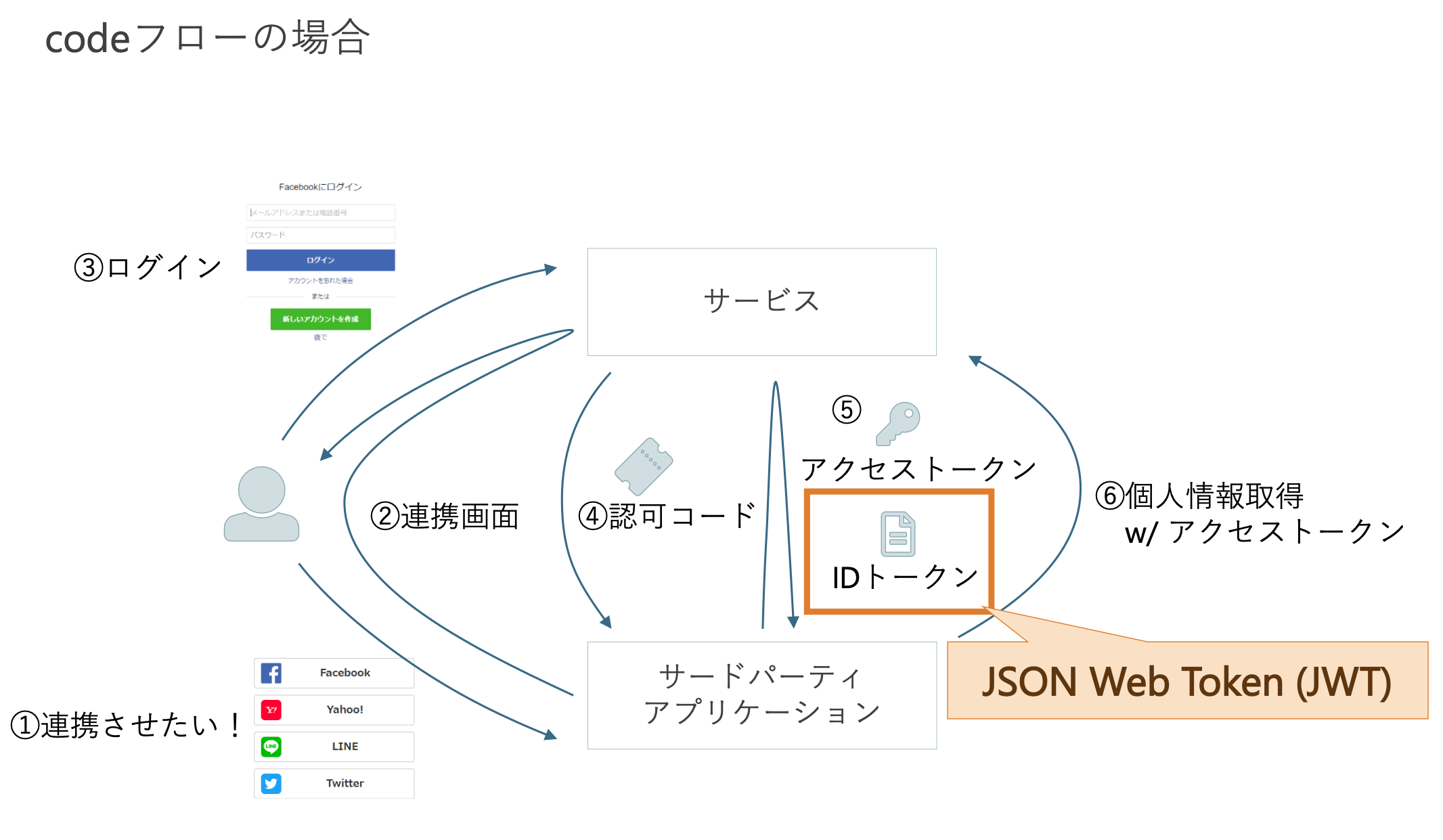
OpenID Connect (OIDC)
- 認証のためのプロトコルとして設計されているが、OAuth2.0の上に構築されているので、OAuth2.0が提供する認可の機能も継承している
- アクセストークンに加えて、認証に必要なIDトークン (JWT) も使用される
JSON Web Token (JWT)
- ジョットと読む
- 関係者間で、情報をJSONオブジェクトとして安全に送信するためのコンパクトで自己完結型の方法を定義するオープン標準 (RFC 7519) のこと
- 特に認証や情報の交換に使用される
- 用途としては、認証結果をサーバー側で保存せずに、クライアント側の保持 (ステートレスな通信の実現)
- JWTの使い方は、これまでのWebアプリでいうところのセッションにデータを保存して使うイメージ
- OpenID Connect (OIDC) の認証を行うためのIDトークンは、ユーザーの身元情報をエンコード (暗号化) したJWTである
- JWTの公式サイト▼
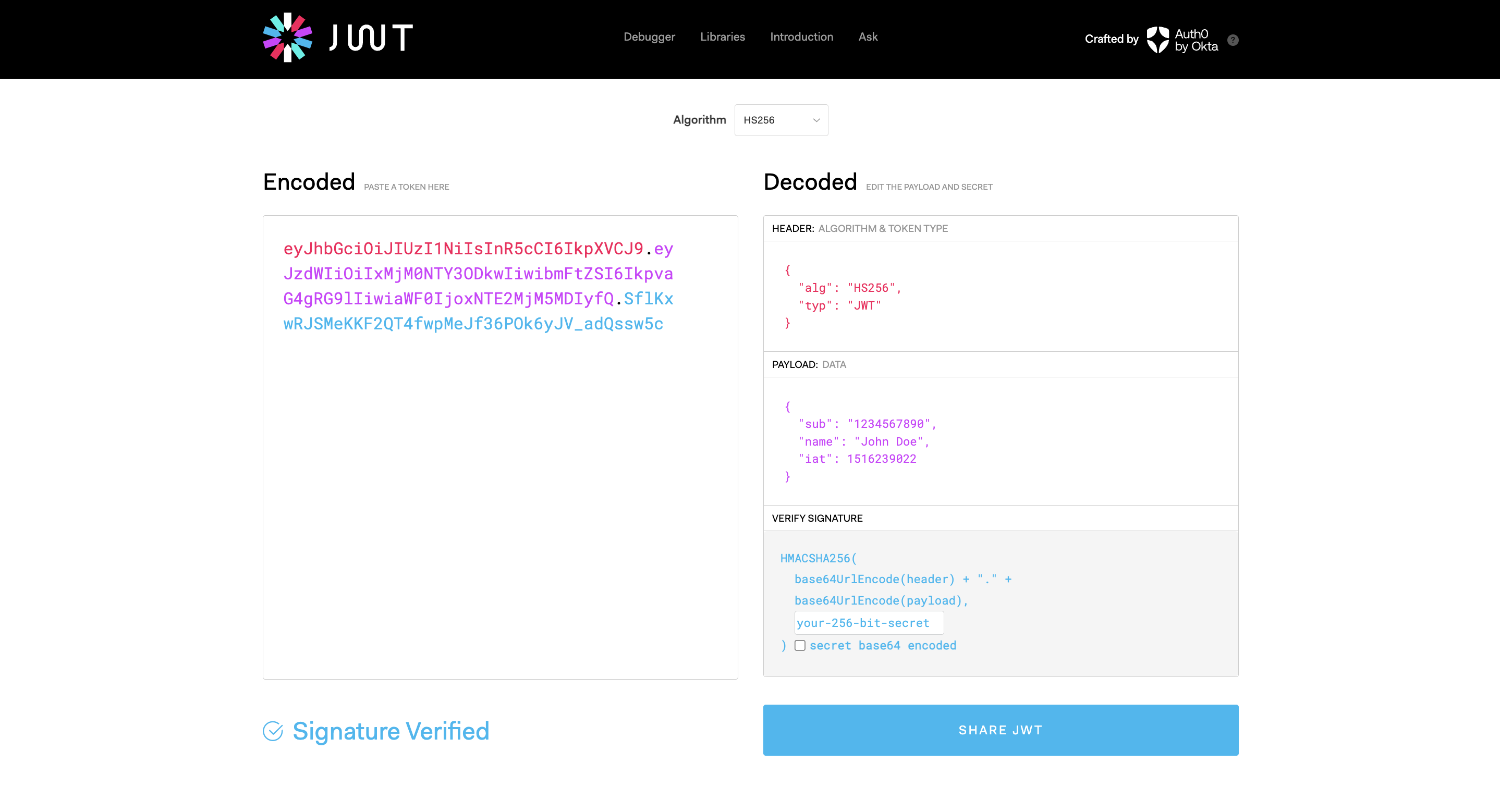
- ヘッダー
- 署名で利用するアルゴリズムなどを定義
-
typeには、JWTを指定する -
algには、どういう暗号化形式にするかを指定し、noneは偽装できてしまうので指定しないようにする
-
- 署名で利用するアルゴリズムなどを定義
- ペイロード
- 実際のデータを指定する (保存したいデータの実態)
- このデータは、クレームとして表現され、ユーザーとそれに関連するデータを表現するステートメントのことである
- クレームには、「予約済みクレーム」と「プライベートクレーム」がある
- 署名
- 改ざんされていないかを確認するためのもの
- base64を用いて、ヘッダーとペイロードを、シークレットキーを用いて署名することができる
- 署名を用いることで、生成したランダムな文字が「誰かから改ざんされてしまったかどうか?」を確認することができる
JWTを使った認証の流れ
- ①元の情報を暗号化 (エンコード) して、ログインするときは復号化 (デコード) する
- ②復号化するときに、シークレットキーを使うことによって、元のペイロードの情報が確認できる
Authorizationヘッダー
- 認証で利用するヘッダーのこと
- JWTを実際に利用する際は、このAuthorizationヘッダーに埋め込んで利用する
- 具体的な記述方法は、
Authorization: <type> <credentials>のようにする - 認証の型としては、以下のようなものがある
- Basic
- ベーシック認証 (IDとパスワードを平文で送信)
- Bearer
- OAuth2.0 (JWTを使う場合はこちらを使用する)
- Digest
- ダイジェスト認証 (IDとパスワードをハッシュ化して送信する)
- OAuth
- OAuth1.0
- Basic
-
<credentials>には、認証情報を記述する- 記述内容は、認証方法によって異なる
- JWTの場合、JWTの実態がcredentialに記載される
- 上記を踏まえ、JWTを送信する場合は、以下のようなヘッダーになる
Authorization: Bearer <JWT credential>
大量アクセス対策
- WebアプリをAPI化することで、簡単に大量アクセスするプログラムが書けてしまう
- →意図しないプログラマーの不注意で、大量アクセスが発生してしまう...
レートリミット
- 上記の対応策として、時間あたりのアクセス制限をかける (レートリミット)
- レートリミットで考慮する事は、「誰に対して」「何に対して」「制限回数」「単位時間」の4点
- 代表的なレートリミット実現方法は、以下の3種類 (30回リクエスト/10分のレートリミットの例)
- Fixed Window
- 時間を均等なウィンドウに分ける
- 境界前後にアクセスが集中してしまう問題点がある
- sliding Log
- 各リクエストのタイムスタンプをログで管理
- メモリの使用量が増加したり、ログを管理するなどの問題点が存在する
- sliding Window
- 上記の二つのやり方を合わせたような方法
- リクエストがあった過去10分間に対して特定の計算を行い、30回を超えているかを判断する
- 仕組み上は一番適切なアルゴリズムといえる
- Fixed Window
キャッシュさせる方法
キャッシュ制御に利用するヘッダーは2分類3パターン
- 有効期限による制御
- Expires
Expires: Sun, 03 May 2023 10:20:00 GMT- キャッシュとしていつまで利用可能かの期限を指定
- 過去日を指定すると、「リソースが有効期限切れ」であることを意味する
- Cache-Controlが同時指定されている場合、Expireは無視する
- Cache-Control + Date
Cache-Control: public, max-age=604800 Date: Sun, 03 May 2023 10:20:00 GMT- Cache-Controlでキャッシュの「可否」と「期限」を指定する
- キャッシュ可否は、
public, private, no-cache, no-storeの4種類のどれかを指定 - キャッシュ期限は、
max-age=<秒>を指定
- キャッシュ可否は、
- Cache-Controlでキャッシュの「可否」と「期限」を指定する
- Expires
- 検証による制御
- Last-Modified + ETag
Last-Modified: Sun, 03 May 2023 10:20:00 GMT Etag: "33sjg38fksfod8573lsd3le49si9382032sdi9os4"- Last-Modifiedにリソースの最終更新日時を指定する
- ETagに特定バージョンを示す文字列を指定する
- 指定する文字列の例として、「コンテンツのハッシュ」「バージョン番号」「最終更新日時」などがある
- Last-Modified + ETag
キャッシュさせる単位
- 例えば、「応答言語によってキャッシュを分けたい」など、キャッシュさせる単位を指定する際は、
Varyを用いる- Varyは、HTTPのレスポンスヘッダーの一つで、キャッシュされたレスポンスが後続のリクエストにどのような状況で適切かを示すために使用する
HTTP/1.1 200 OK
Content-Type: application/json
Content-Length: 212
Cache-Control: public
Content-language: ja
Date: Sun, 03 May 2023 10:20:00 GMT
Server: api.sample.com
Vary: Content:Language ←キャッシュ判断に利用するヘッダーを指定
セキュリティ
APIはどこから呼ばれるのか?
- 呼び出し元としては、スマホアプリ、Webページ (scriptタグ、JavaScript) 、 外部システム (バッチ処理)などが挙げられる
- → 悪意あるユーザーが紛れてくる恐れがある
- なので、WebAPIにも、Webサービスと同じようにセキュリティ対策が必要
代表的な脆弱性対策
- WebAPIで代表的な脆弱性対策として、以下の4つが存在する
XSS
- 悪意あるユーザーが、正規のWebサイトに不正なスクリプトを挿入することで、正規ユーザーの情報を不正に引き出したり操作できてしまう問題
- 実行される場所は、Webブラウザ (Client)
対策
- レスポンスヘッダーの追加
- X-XSS-Protection
- "1"で、XSSフィルタリング有効化
- X-Frame-Options
- "DENY"で、frameタグ呼び出しを拒否
- X-Content-Type-Options
- "nosniff"で、IE脆弱性対応
- X-XSS-Protection
CSRF
- 本来拒否しなければいけないアクセス元 (許可しないアクセス元) からくるリクエストを処理してしまう問題
- 実行される場所は、Webアプリサーバー (Server)
- XSSとCSRFの違いについては、こちらのQiita記事をご参照下さい
対策
- 許可しないアクセス元からのリクエストを拒否
- X-API-Key
- システム単位で実行可否判断
- Authentication
- ユーザー単位で実行可否判断
- X-API-Key
- 攻撃者に推測されにくいトークンの発行/照合処理を実装
- X-CSRF-TOKEN
- トークンを使って実行可否判断
- X-CSRF-TOKEN
HTTP
- 通信経路が暗号化されないので盗聴されやすい
対策
- 常時HTTPSを利用した通信にする
- TLS
- 安全に通信を行うためのプロトコル
- SSLの後継
- HTTPS
- HTTP + TLS
- Webで安全に通信するプロトコル
- TLS
JSON Web Token (JWT)
- クライアント側で内容の確認/編集が簡単にできるため、サーバー側の検証が不十分だと改ざんされた情報を正規として受け入れてしまう
対策
- ヘッダーのalgに、"none"以外を指定して署名を暗号化する
- ペイロードのaudに想定する利用者を指定して、受信時に検証する
参考記事