【実録】APIの「無駄遣い」を防ぐためにジョブキューを自作したら、Cloud Runのタイムアウトと堅牢性問題まで解決した話
1. はじめに:きっかけは「もったいない」という懸念
最近、YouTube動画のコメントをAIで分析するアプリを個人開発しています。
構成はフロントエンドにReact、バックエンドにCloud Run (FastAPI) + Supabaseというモダンなサーバーレス構成です。
開発当初は、「ユーザーがボタンを押す → サーバーで分析する → 結果を返す」という、ごくシンプルな同期処理で作っていました。しかし、開発が進むにつれてある一つの「懸念」が頭をよぎりました。
「これ、同じ動画に対して連打されたらどうなる?」
例えば、話題の動画などでAさんが分析ボタンを押した直後、まだ処理が終わらないうちにBさんも同じ動画の分析ボタンを押す。あるいは、一人のユーザーが「あれ?動いてるかな?」とボタンを連打してしまう。
単純な作りだと、リクエストの数だけ裏側でYouTube APIへの問い合わせが走り、AI推論も重複して実行されてしまいます。
APIの利用枠(クォータ)には限りがありますし、Cloud Runの課金も馬鹿になりません。「キャッシュがない状態の同じ動画に対して、無駄にリクエストを消費してしまう」というのは、どうしても許容できない設計でした。
そこで導入したのが、「ジョブ(Job)」 という概念を使ったリクエスト制御システムです。
2. システムの全体像:ハイブリッド・ジョブキュー
「APIの節約」から始まったアイデアでしたが、結果として 「Cloud Runのタイムアウト回避」 と 「システム障害時の自動復旧」 まで実現する、システムの要(かなめ)となりました。
イメージ画像
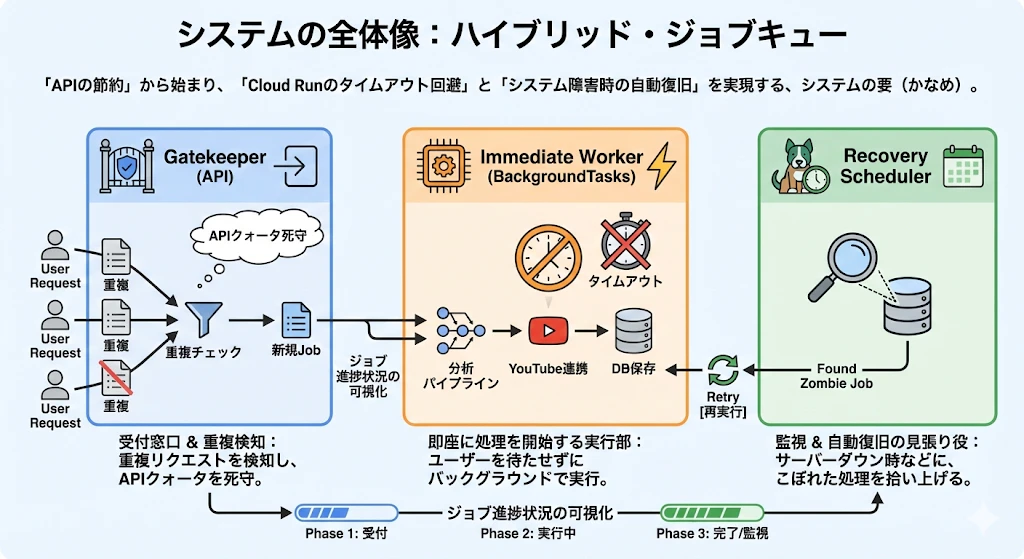
今回構築したアーキテクチャは、以下の3つの要素で構成されています。
-
Gatekeeper (API): 重複リクエストを検知し、APIクォータを死守する受付窓口。
-
Immediate Worker (BackgroundTasks): ユーザーを待たせずに即座に処理を開始する実行部。
-
Recovery Scheduler: サーバーダウン時などに、こぼれた処理を拾い上げる見張り役。
ジョブを作成後、処理が進行して行くことにジョブのステータスを変更していき、現在どの時点の処理をしているのかというのを分かりやすくします。
データフロー図
3. 実装詳細:コードで見る工夫ポイント
ここからは、実際に稼働しているPython (FastAPI) のコードをベースに、どう実装したかを解説します。
Phase 1: 重複を許さない「受付コントローラー」
まず、リクエストを受け取るエンドポイントです。ここで「いきなり処理しない」のが最大のポイントです。
Python
@router.post("/analyze", status_code=status.HTTP_202_ACCEPTED)
async def accept_youtube_analysis_request(
request: AnalysisRequest,
background_tasks: BackgroundTasks, # FastAPI標準の非同期タスク機能
http_request: Request
):
video_id = request.video_id
# 1. まずキャッシュ(過去の分析結果)があるか確認
# あれば即座に完了データを返して終了(API節約!)
cached_data = await get_valid_video_cache(video_id)
if cached_data:
return JSONResponse(content=cached_data, status_code=200)
# 2. 現在進行中のジョブがあるか確認 (ここが重要)
# 同じ動画に対する処理が走っていれば、新規作成せずにそのJob IDを返す
# これにより、リクエストが100回きても、実際の分析処理は1回だけになる
existing_job = await check_active_job(video_id)
if existing_job:
return {"job_id": existing_job.id, "status": "PROCESSING", "message": "既存の処理に相乗りします"}
# 3. ここまできて初めて「新規ジョブ」として登録
job_id = await register_new_job_transaction(video_id=video_id)
# 4. 「裏側」で処理を開始するよう登録
# ここでメイン処理を呼ぶとタイムアウトするので、BackgroundTasksに投げる
background_tasks.add_task(
run_full_analysis_workflow,
job_id=job_id,
video_id=video_id
)
# 5. フロントエンドには「受け付けました」とだけ伝えて即レスポンス
return {
"video_id": video_id,
"job_id": job_id,
"status": "PENDING",
"message": "解析リクエストを受け付けました。"
}
この設計により、「最初にボタンを押した人の処理」に、後から来た人全員が相乗りする 形になります。これでYouTube APIのリクエスト数を最小限に抑えることができました。
Phase 2: 堅牢性を担保する「リカバリスケジューラ」
FastAPIの BackgroundTasks は便利ですが、一つ弱点があります。処理中にCloud Runのインスタンスが落ちたり再起動したりすると、処理が中途半端に中断され、DB上のステータスが「PROCESSING」のまま永遠に残ってしまう ことです。
そこで、これらを回収するためのスケジューラを実装しました。
ただし、常にDBを監視(ポーリング)し続けるとCPUリソースが無駄なので、「普段は寝ていて、リクエストが来た時だけ起きる」スマートスリープ機能 を搭載しています。
# application/jobs/recovery_scheduler.py (抜粋)
class RecoveryScheduler:
def __init__(self):
self._wakeup_event = asyncio.Event()
self._is_running = False
async def start(self):
"""監視ループ:アプリ起動時に開始"""
self._is_running = True
logger.info("Recovery Scheduler Started")
while self._is_running:
# 1. 待機ロジック
# ジョブがない時はCPUを使わず完全にスリープする(コスト削減)
if self._empty_streak >= MAX_EMPTY_STREAK:
logger.info("ジョブがないためスリープします...")
await self._wakeup_event.wait() # 外部から起こされるまでここで停止
self._empty_streak = 0
# 2. リカバリ処理 (ここが防止策!)
# 'PROCESSING' のまま10分以上放置されたゾンビジョブを探して再実行
processed_count = await JobRecoveryService.process_jobs()
# 3. インターバル
await asyncio.sleep(60)
def notify_activity(self):1緒に選定権か
"""
API側から呼ばれる「再開合図」
新しいリクエストが来たら、叩き起こして監視を再開させる
"""
if not self._wakeup_event.is_set():
logger.info("新規リクエスト検知 -> スケジューラ起動")
self._wakeup_event.set()
このスケジューラのおかげで、もし処理が途中で死んでしまっても、最長で10分後には自動的に検知され、リトライが行われます。
「処理が延々と残ってしまうのではないか?」という懸念も、この自動回収ロジックによって完全に払拭されました。
4. 導入して感じた効果
最初は「APIリクエストの重複を防ぐ」というアイデアから始まったこの機能ですが、実装してみると想定以上のメリットがありました。
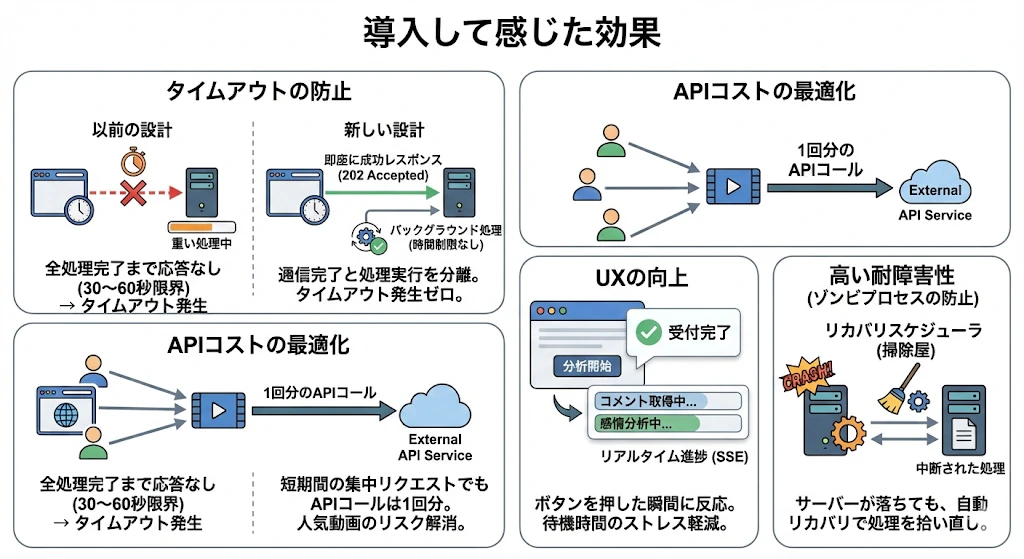
タイムアウトの防止
以前の設計では、分析ボタンを押すと、サーバー側での全処理が終わるまでブラウザへの返事が保留され続けていました。
Webブラウザや通信経路には「待機時間の限界(通常30〜60秒)」があり、AI分析などの重い処理がこれを超えると、サーバーがまだ計算中であっても「応答なし」とみなされ、強制的に通信エラー(タイムアウト)が発生します。
そこでサーバーはリクエストを受け取ると、処理を開始する前にまず**「受け付けました(202 Accepted)」という成功レスポンスを即座に返します**。
これにより、ブラウザとの通信はわずか数ミリ秒で正常に完了します。その後、実際の重い分析処理は、通信が終了した後にサーバーのバックグラウンドで開始されます。
この「通信の完了」と「処理の実行」を切り離す方式(非同期処理)にしたことで、処理に何分かかろうとも通信上のタイムアウトが発生する可能性はゼロになりました。また、万が一バックグラウンド処理が長引いても、前述のリカバリスケジューラが監視しているため、処理が迷子になることもありません。
APIコストの最適化:
同じ動画に対するリクエストが短期間に集中しても、APIコールは1回分で済みます。人気動画を分析する際のリスクがなくなりました。
UXの向上:
ユーザーはボタンを押した瞬間に「受付完了」の反応が得られます。その後はSSE(Server-Sent Events)で進捗状況(「コメント取得中...」「感情分析中...」)をリアルタイムに表示できるため、待機時間のストレスも軽減できました。
高い耐障害性(ゾンビプロセスの防止):
自作したリカバリスケジューラが「掃除屋」として機能するため、サーバーが突然落ちても、再起動後に自動で処理を拾い直してくれます。
5. おわりに
「重い処理は『ジョブ』として登録して、後から来たリクエストは待ってもらう」
きっかけはAPIの節約という単純なアイデアでしたが、結果的に「エラーが起きても自動でやり直せる」「今何をしてるか画面に出せる」など、アプリ全体を支える重要な仕組みになりました。
Cloud Runのようなサーバーが記憶を持てない環境で時間のかかる処理を作る場合、複雑な処理を構築しないといけないのかと考えていましたが、思ったよりシンプルにできました。
今回のように「普段使っているデータベースをタスク置き場にする」ことと、「FastAPIの便利な機能(BackgroundTasks)」を組み合わせて、十分に丈夫なシステムが作れたのではないかなと思います。
この技術を使って作成したので、良かったら見てみてください。
https://emo-reader.jp/