はじめに
現在AI・機械学習ブームが到来しており、AI・機械学習を使っててっとり早く成果がほしい!って考えている人が多いのではないでしょうか。ネットで調べてみると、何を勉強し始めればよいのか大量の情報が出てきます。そして言っていることもほぼ同じです。私もこれらの意見に同意です。
とはいえ、勉強するものが多すぎて機械学習を使うだけなのになんでこんなに勉強しなきゃなんないんだよ!と思う方もいらっしゃると思います。そこで、本記事では、機械学習をある程度理解できて、すぐ取り掛かれるようになることを目的としています。そのことを理解してもらいながら読んでいただけると幸いです。
目次
- 機械学習とは何か
- 教師あり学習・教師なし学習は最低限知っておく
- データ分析はscikit-learnが定番
- Deep Learningは?
- 最後に
0. 機械学習とは何か
機械学習(きかいがくしゅう、英: machine learning)とは、人工知能における研究課題の一つで、人間が自然に行っている学習能力> と同様の機能をコンピュータで実現しようとする技術・手法のことである (wikipedia)
wikipediaに書いてあるとおりで、データから特徴を見つけ出し学習するのをコンピューターで実現しようというものです。
これができると何がよいかというと、コンピューターに何かさせるときにルールを全て記述する必要がないということです。例えば、ネコの画像を認識させるときにルールを書いていたら記述しきれません。機械学習なら、ネコというものを学習し認識することができるということです。
1. 教師あり学習・教師なし学習は最低限知っておく
世の中の機械学習適用案件は、教師あり学習・教師なし学習どちらかに分類されるはずです。そのため、これらは機械学習を使うには絶対に知っておかなければいけない項目でしょう。ここでは教師あり学習、教師なし学習についてわかりやすく解説します。
1.1 教師あり学習とは
教師あり学習とは、文字通り教師(正解)を与えてあげてコンピュータに学習させることです。つまり、すでに正解データが複数個ある状態で未知のデータを当ててくれるのが教師あり学習となります。例えば、猫画像と犬画像にそれぞれ「猫」と「犬」という正解データがついて、そこから学習していく場合は教師あり学習となります。教師あり学習は扱いやすい問題ではありますが、教師(正解あり)データを用意しないといけないという欠点もあります。後述しますが、教師データは一定数用意しなければならず、問題によってはここがボトルネックになることもあります。
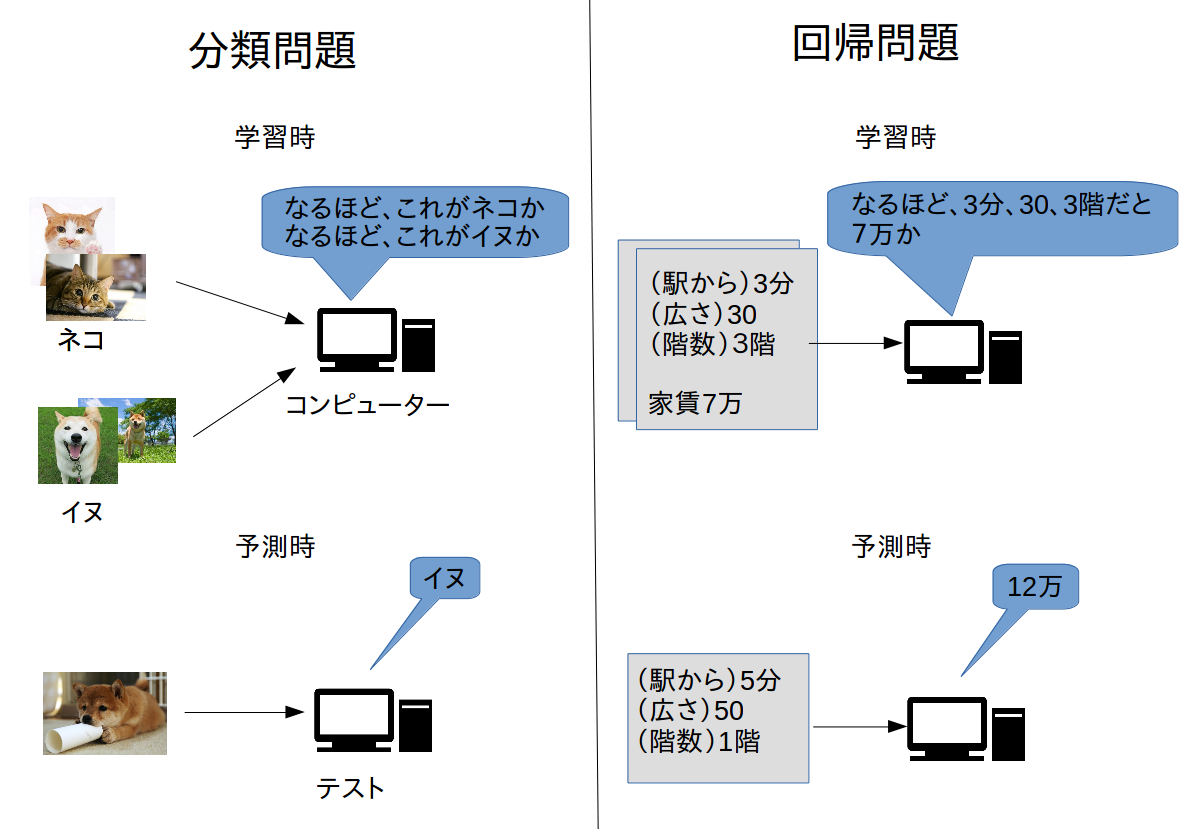
分類と回帰
教師あり学習の中でも、分類問題と回帰問題があります。分類問題とは、与えられたデータがどの分類に属するかを当てるというものです。先程の例の犬猫の画像をあてる問題は、「犬」というカテゴリか「猫」というカテゴリを当てるので分類問題となります。一方で回帰問題は、アウトプットとして数値が出力される問題となります。例えば、ある物件の「駅からの時間・面積・階数」という情報が与えられた時に、家賃を予測するといったものが回帰問題となります。
1.2 教師なし学習
教師なし学習とは、正解がないデータからデータの規則性等を発見する手法です。例えば、大量のデータから仲間同士を見つけてグループ化したり(クラスタリング)、高次元のベクトルを情報ができるだけ落ちないように低次元に変換したり(次元削減)することができます。異常検知もこちらに分類されますね。教師あり学習に比べて出現頻度は低いですが、覚えておくべきでしょう。教師なし学習の注意点としては、人間の意図とは違うように動いてしまうことがあるということです。
2. データ分析はscikit-learnが定番
scikit-learnと呼ばれる強力なpythonライブラリがあります。機械学習・AIはpythonが今の所最大勢力であり、ライブラリも充実しているのでpythonを使うことをおすすめします。(Rもなかなか充実していますけど、システム組込みとかになった場合は面倒かと思います。)scikit-learnには強力なアルゴリズムが多々実装されていてかつ使いやすいです。python環境を用意し、scikit-learnをインストールすればすぐに機械学習を始めることができます。anacondaと呼ばれるpythonパッケージを導入すれとscikit-learnが入っていますのでおすすめです。
2.1 アルゴリズム選定はどうすればよいか
scikit-learnというライブラリがあって、それを使えば機械学習による解析ができることはわかりました。では、どのアルゴリズムを使えばよいでしょうか。うれしいことに、scikit-learnにはチートシートと呼ばれるものがあるのです。これにしたがってチャートをたどっていけば、どのアルゴリズムを使えばよいかが一瞬でわかります。
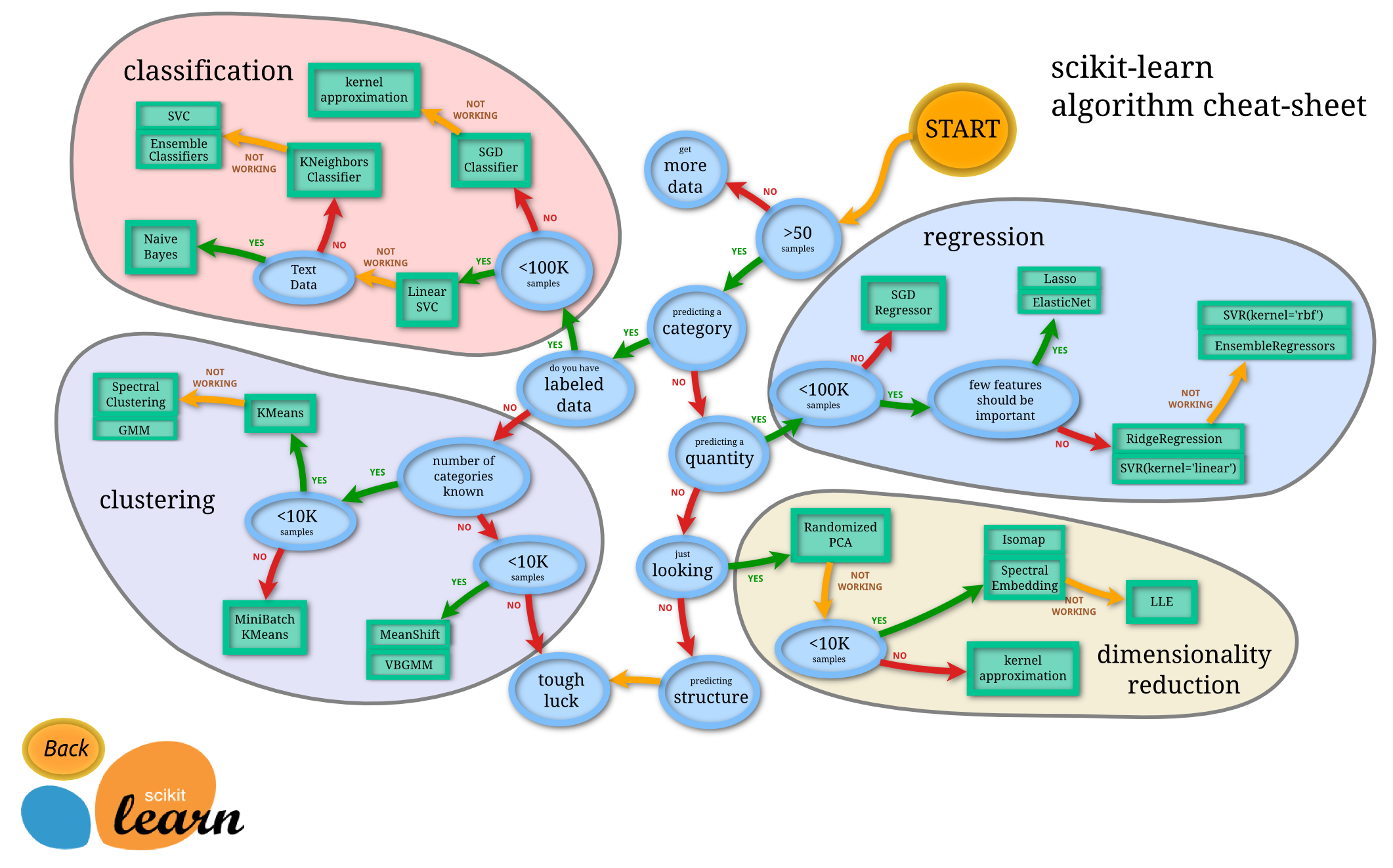
緑色の四角がアルゴリズム名です。自分のタスクに対するアルゴリズムが決まったら、そのアルゴリズムのリファレンスやサンプルを見てみましょう。英語で少し大変かもしれませんががんばってください。英語がどうしても苦手でしたら、そのアルゴリズムでググると日本語のサンプルが出てきますのでそちらを参考にするのが良いと思います。
検索したサンプルでもscikit-learnのサンプルでも良いですが、サンプルコードが見つかったら自分のもっているデータをサンプルコードのscikit-learnに食わせる前の状態と一緒にしましょう。基本コードはあまり変えずに、データだけ変えて動かすイメージですね。素早く成果を出したいなら、それで十分だと思います。
参考にSVMのサンプルのリンクを記述しておきます。
2.2 パラメーターはどう選定するか
scikit-learnの各アルゴリズムにはパラメーター設定がたくさんあります。パラメーターによって精度が変わってきますので、うまく選んでやる必要があります。具体的には、「グリッドサーチ」と呼ばれる関数がscikit-learnに存在するのでそれを使うとうまくパラメータを選ぶことができます。グリッドサーチとは簡単にいうと、パラーメーターを総あたりで試してみて、精度が一番よかったものを選ぶ手法です。これを使えば最適なパラメーターが選べますね。
精度について
機械学習モデルができたら、次は精度を算出します。個人的にはクロスバリデーションが良いと思いますが、自分でテストデータを準備しても良いと思います。(もちろんデータが偏ってない前提で)学習に用いてないデータを別に用意するってことですね。新しく用意するのではなく、元あるデータを学習データ:テストデータ=7:3もしくは8:2くらいにしてもいいと思います。
分類問題で最低限知っておく精度指標は、accuracy,precision,recall,f1-scoreですかね。こちらが参考になると思います。
回帰問題はMAE(Mean Absolute Error)とかMSE(Mean Squared Error)とか知っていれば問題ないと思います。
こちらが参考になると思います。
3. Deep Learningは?
Deep Learningはここ数年で勢いを増してきましたね。人工知能=Deep Learningといっても過言でないほどです。精度も従来の機械学習手法よりも大幅に上回っていますしね。では、なんでもDeep Learningにいけばよいかというとそういうわけでもありません。もちろん研究が進んでいる分野(画像系等)なら、DLを選択すべきだと思いますが、異常検知や需要予測にDeep Learningを持ちだしてくるのはあまりよろしくないと思います。その理由としては、GPU積んだようなマシンが必要になってしまうこと・チューニングが難しいことが挙げられます。例えば、隠れ層をいくつにすれば良いのか、単純なNNで良いのか等気にしなければたくさんあります。特に今回のテーマのような素早く成果を出したい場合にはDeep Learningに触れない方が良いと思います。とはいってもDLは超強力なので、時間があったら是非勉強してみてください。
4. 最後に
大分おおざっぱになりましたが、本記事内の知識があれば機械学習のタスクは一応できると思います。環境構築はググればたくさん出てきますのでそちらを参考にしてみてください。人間的にみて予測可能なデータはだいたいの成果が出るのではないかと思います。しかし王道は確率統計・線形代数・微積から徐々に積み上げていき、それぞれのアルゴリズム・理論を学ぶことだと思います。AIの民主化が進み、高レベルのライブラリが実装され、これからも誰でもデータ分析はできるようになっていくと思われます。その中で差別化するには、理論を知りチューニングできる力をつけること以外道はないのではないかと思います。