この記事は以下の記事の続きです
おいしそうな料理のレシピって沢山ありますよね。
しかし、ネットサイトのレシピは投稿者が不特定多数なので、何人分の材料表記かまちまちです。
4人分のレシピでも、自分が作るのは2人分となると、
レシピの材料をすべて ×1/2 しなければなりません。
それに合わせて、材料も買うとなると・・・
さらに複数のレシピ分のお買い物となると・・・
面倒くさい! となることもあります。
このアプリでは、ユーザーが何人分の材料を買いたいかに合わせて量を表示したいので、そもそも、レシピが何人分のものであるかの情報が必要になります。
買い物リスト作成アプリの概要はこちら
★このページは以下項目で構成されています★
| 項番 | ページ内リンク |
|---|---|
| 1 | 何人分のレシピであるかの情報を取得する |
| 2 | コード説明 |
| 3 | Excelを開く |
| 4 | URL情報取得 |
| 5 | BeautifulSoupで解析 |
| 6 | find_allメソッドで情報抽出 |
| 7 | さらに数字のみ抽出する |
| 8 | 全コード |
何人分のレシピであるかの情報を取得する
楽天レシピのAPI では 何人分のレシピであるかの情報は取れないので、beautifulsoupを使ってスクレイピングをします。
こちらのURLが載っているExcelファイルを使います。(D列は人数を入れるために空欄にしています)

この画像では3件しか写せていませんが、こちらのファイルに約2000件の楽天レシピのURLを載せています。
コード説明
準備
#ライブラリを準備
import requests
from bs4 import BeautifulSoup
import openpyxl
まず、必要なライブラリを準備します。
requestsモジュールは、Pythonには標準で付属していないので、コマンドプロンプトなどで
pip install requests
を入力して別途インストールする必要があります。
beatifulsoupは、取得したHTMLデータから必要な情報のみを抽出するモジュールです。
こちらもPython 標準装備ではないので、requests同様にコマンドプロンプトなどで
pip install beautifulsoup4
こちらを入力して別途インストールします。
openpyxlは、Excelファイルを読み書きするためのPythonライブラリです。これもPython標準装備でないので上記同様
pip install openpyxl
をコマンドプロンプトなどで入力してインストールします。
Excelを開く
先ほどの楽天レシピのURLが載ったExcelファイルを開きます。
openpyxlでExcelを操作するには3つの段階を踏む必要があります。
①Excelファイルの指定
②操作するシートの指定
③セルの指定
Excelファイルと操作するシートの指定
#Excelファイルの指定
#load_workbook("パス名")でExcelファイルの読み込み
wb = openpyxl.load_workbook ("recipe_index.xlsx")
#シートの指定
ws = wb.worksheets[0] #このインデックスはシートの左から順に降られ、数字は0から開始。
操作するセルの指定
このExcelファイルであるとURLのC列(3列目)と人数を入れたいD列(4列目)を操作したい
かつ、2行目以降のすべてのURLで行いたいので、for文を使います。
#URLとのセルを人数を入れるセルを指定
for row in ws.iter_rows (min_row=2, min_col=3, max_col=4): #操作するセル範囲指定
url = row[0].value #URLのセルを指定し、変数urlに代入

iter_rows(min_row=, max_row=, min_col=, max_col=) で特定のセル範囲のデータが読み取れます。
今回は赤枠の範囲のセルを扱いたいので (min_row=2, min_col=3, max_col=4) でセル指定、
for文で、青枠の1行を取得できます。
さらに、URLのセルは青枠の index=0 なのでrow[0].value となり、変数urlに代入しておきます。
URL情報取得
request.get関数を使い、webページを取得し、取得した結果を変数resに格納します。
res = requests.get(url) #()内にURL指定する
取得した情報を表示すると・・・
print(res.text)

このように、沢山のHTMLの情報が取得出来ていることが分かります。
この情報をBeautifulSoupを使って、解析していきます。
BeautifulSoupで解析
BeautifulSoupの記述方法は
BeautifulSoup(解析対象のHTML/XML, 利用するパーサー)
1つ目の引数には、解析対象のHTML/XMLを渡します。
2つ目の引数として解析に利用するパーサー(解析器)を指定します。
| パーサー | 引数での指定方法 | 特徴 |
|---|---|---|
| Python’s html.parser | “html.parser” | 追加ライブラリが不要 |
| lxml’s HTML parser | “lxml” | 高速に処理 |
| lxml’s XML parser | “xml” | XMLに対応し、高速に処理 |
| html5lib | “html5lib” | 正しくHTML5を処理 |
この中でも、今回はPythonの標準ライブラリに入っている html.parserを利用します。
soup = BeautifulSoup(res.text, "html.parser")
find_allメソッドで情報抽出
欲しい情報は楽天レシピの青枠の数字だけです。そのためにまず、赤枠の情報を取ります。
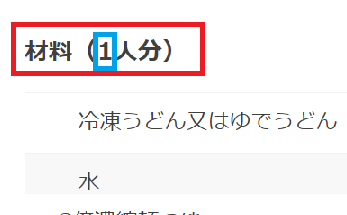
レシピページにアクセスして「要素の検証」を使って、赤枠のHTML タグを調べます。

すると、 "contents_title contents_title_mb" というclassであることが分かります。
このクラスとfind_allメソッドを使うと
#「材料:○人数分」を入手
elems = soup.find_all(class_ = "contents_title contents_title_mb")
以下の様に、"contents_title contents_title_mb" がclassとして使われているタグすべてが抽出されます。

赤枠の文字は上記の結果の一番目にあるので、elems[0]と指定して、get_text()で文字のみ抽出します。
elem = elems[0].get_text()
これで、赤枠の情報を抽出できました。

さらに数字のみ抽出する
楽天レシピはユーザーが自由にレシピを投稿できるため、赤枠情報が
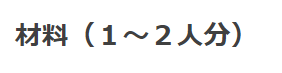
このような時もあります。
そこで、とりあえず
材料(1人分)
材料(1~2人分)
こちらの「(」から「人」の間の 「数字」と「~」で構成される部分だけ抽出することにしました。(「~」はあとでExcel上で加工します)
まず、文字をスライスして「(」の「1人分)」または「1~2人分)」にします。
 画像引用サイトはこちら:Python 文字列の一部を取得する(スライス)
画像引用サイトはこちら:Python 文字列の一部を取得する(スライス)
スライスは以下の構文を取ります。また、上の画像の通り、最初の1文字目の位置は0となります。
文字列[ 開始位置:終了位置]
elem[3:] #終了位置を指定しないことで、文字列の最後まで抽出できる。
こちらで、「1人分)」または「1~2人分)」の文字が抽出できます。
さらに、split()メソッドで文字を分割します。以下の構文を取ります。
文字列.split()
引数は分割したい文字で、空欄であれば空白で区切ります。戻り値はstr型の配列です。これを当てはめると
ninzu = elem[3:].split("人")[0] #人で分割した文字列の1番目の数字が欲しいので、[0]でindex指定します。
この数字を、こちらの赤枠の2列目(D列)に格納したいので、
変数ninzu を空白のセルに順番に格納して、ファイルを保存します。
row[1].value = ninzu #空白セルに格納
wb.save("recipe_index.xlsx") #ファイル保存
すると、このようにpeopleの列に、何人分のレシピであるか、格納することが出来ました。

しかし、people列の数字は「~」や「、」が入っていたり、全角だったり半角だったり、まちまちです。
これはデータ加工編で修正していきます。
全コード
#ライブラリを準備
import requests
from bs4 import BeautifulSoup
import openpyxl
# recipe_indexファイルを開き、シートを取得
wb = openpyxl.load_workbook ("recipe_index - コピー.xlsx")
ws = wb.worksheets[0]
#wsのurl列のサイトから順番に人数を入力していく
#操作するセル指定
for row in ws.iter_rows (min_row=2, min_col=3, max_col=4):
url = row[0].value
#urlページの情報を取得
res = requests.get(url)
#beautifulsoup で解析
soup = BeautifulSoup(res.text, "html.parser")
#「材料:○人数分」を入手
elems = soup.find_all(class_ = "contents_title contents_title_mb")
elem = elems[0].get_text()
#数字のみ入手
ninzu = elem[3:].split("人")[0]
#空白セルに格納
row[1].value = ninzu
#1行ずつ保存
wb.save("recipe_index - コピー.xlsx")
長いので、次回に続きます。
次回、seleniumを使って、各レシピの材料と量を集めていきます!