推論性能を上げるテクニックに関するLLMの論文を2つ紹介します。
1. 逆思考問題を解くことによる推論性能の向上「RevThink」
2. マルチエージェントLLMトレーニングによる推論性能の改善「MALT」
逆思考問題を解くことによる推論性能の向上「RevThink」
Reverse Thinking Makes LLMs Stronger Reasoners
逆思考 とは、問いに対して答えを導くのではなく答えから問いを求めることです。小学校の算数のカリキュラムなどでも思考を鍛える方法としてで注目されいます。
例えば、次のようなものです
通常の問題: Aさんはリンゴを2個、Bさんは3個持っています。あわせていくつのリンゴがあるでしょう?
逆思考の問題: 5個のリンゴがあります。Aさんがリンゴを2つ持っていたらBさんはいくつもっているでしょう?
これをLLMに適応します。
上の例を使って、リンゴの合計が5ではなく6と推論してしまった場合、これを答えとして逆思考の問題を解くとBさんが4個のリンゴを持っていなければいけません。
このような、順方向の推論と逆方向の推論の思考の一貫性や矛盾を扱うことでパフォーマンスの向上が見込めます。
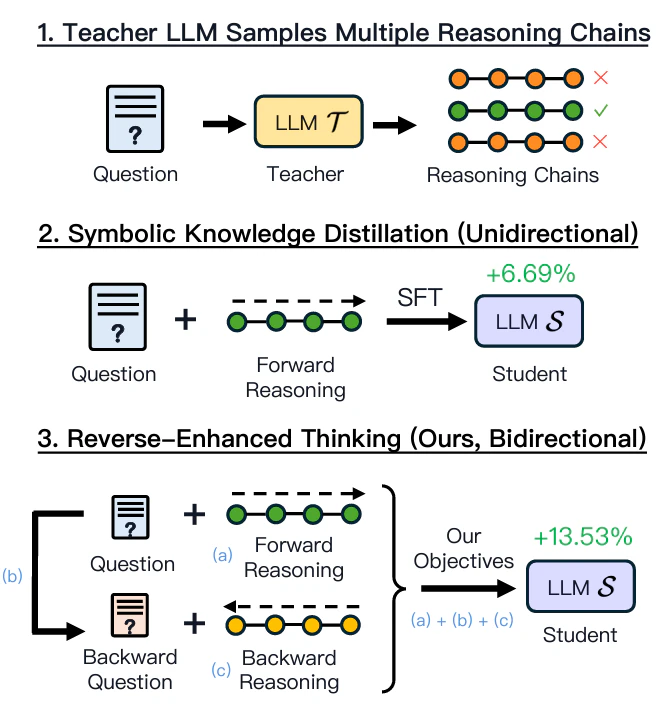
Reverse-Enhanced Thinking (RevThink)
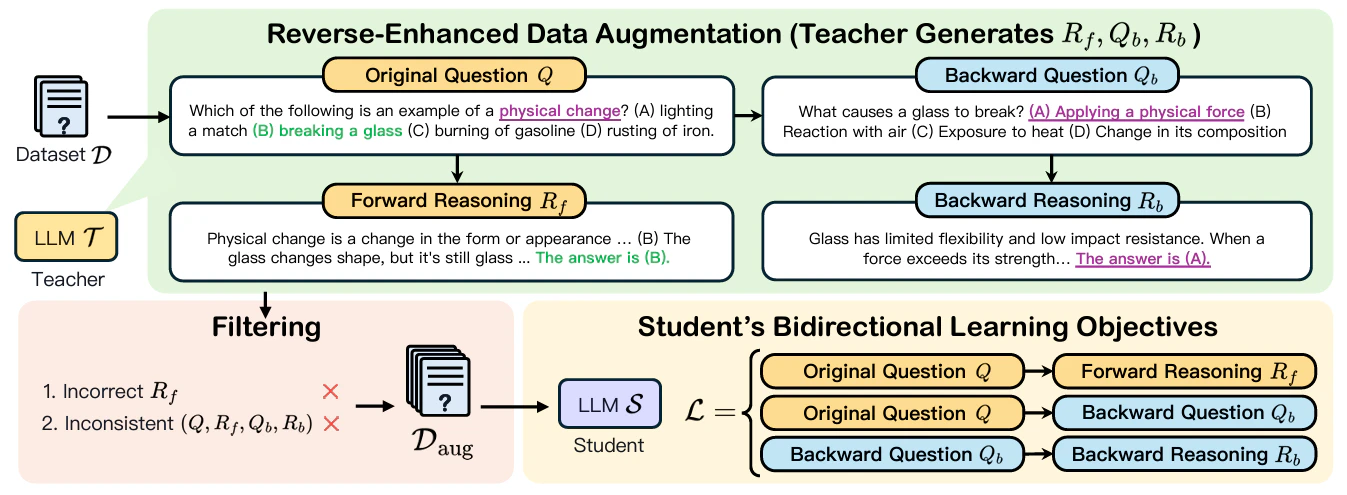
LLMが逆思考を実行できるようなフレームワークがRevThinkです。具体的には教師モデルから順方向・逆方向の推論を収集してデータセットを拡張します。
- 順方向の推論 (2+3=5)
- 質問から逆方向の質問の生成 (5=2+?)
- 逆方向の質問から逆方向の推論 (5=2+3)
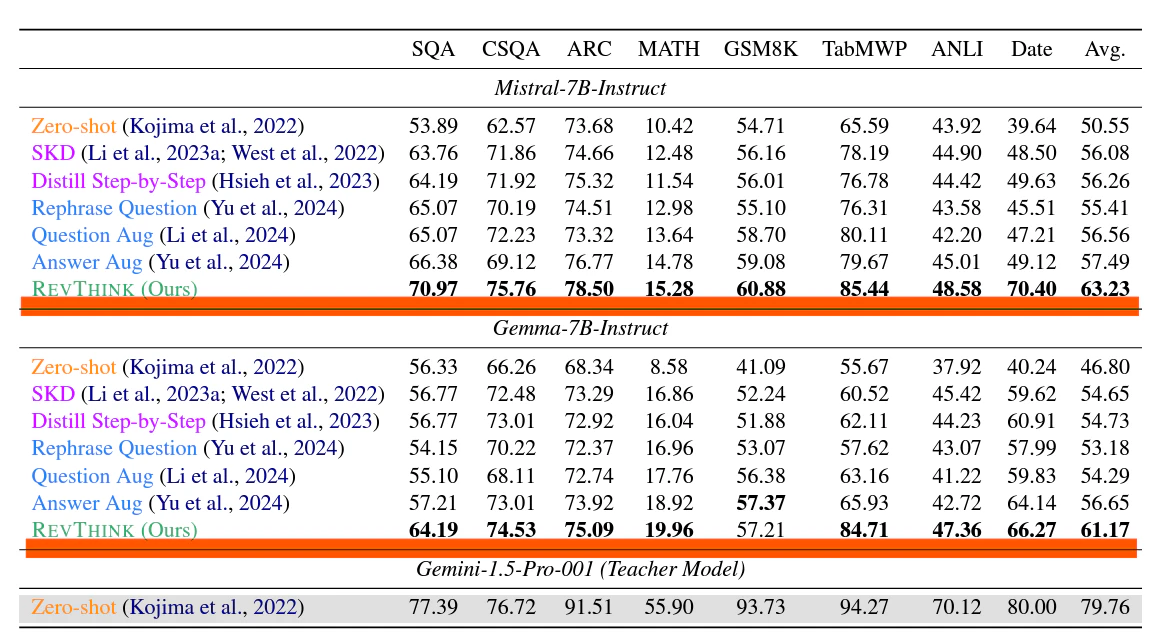
これによってZero-shotのパフォーマンスと比べて平均 13.53% の向上が見られました。
マルチエージェントLLMトレーニングによる推論性能の改善「MALT」
MALT: Improving Reasoning with Multi-Agent LLM Training
LLMは通常、人間がその出力を評価して洗練させますが、複数のLLMが協調することで性能の向上が期待できます。
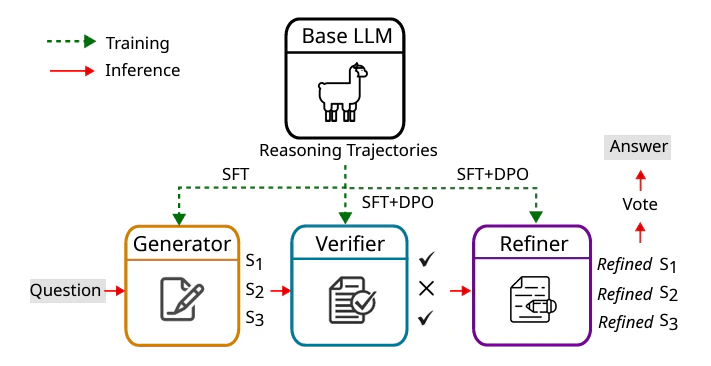
図のように、このモデルはLlama をベースとして、ジェネレーター(Generator) と 検証者(Verifier)、調整者(Refiner) の3つの異種のLLMによるマルチエージェントが共同で働きます。
それぞれの簡単な役割は以下の通りです。
- Generator: 質問に対する最初の答えの生成
- Verifier: 評価の提供
- Refiner: 最終的な出力のため、評価に応じて答えを統合
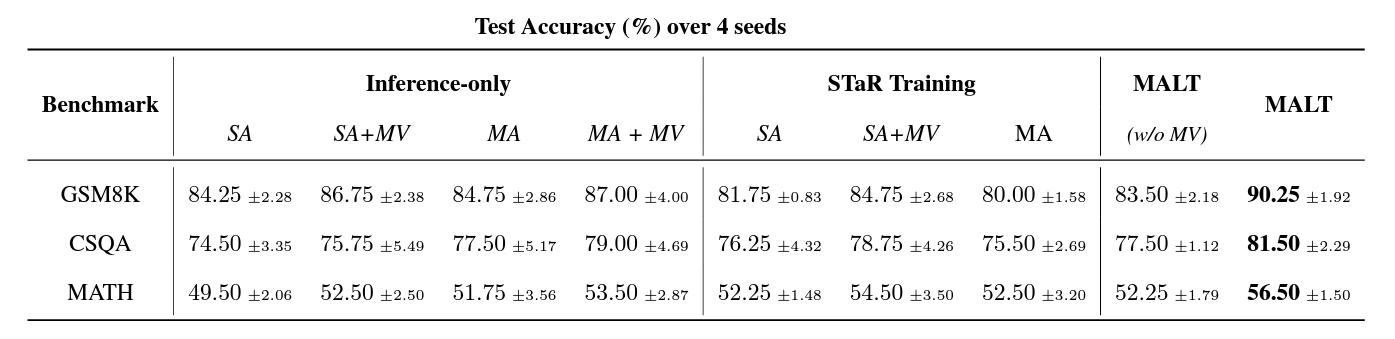
実際に、ベースラインに対して 7~14% 改善が見られました。
参考
各arXiv論文はこちらです。
- Reverse Thinking Makes LLMs Stronger Reasoners
- MALT: Improving Reasoning with Multi-Agent LLM Training
- DPOについて