はじめに
こんにちは、今日はGCPのCloud Composerの練習のために作成したデータパイプラインを紹介したいと思います。
今回作成したデータパイプラインは、定期的にYoutube APIを叩き、特定のYoutuber(東海オンエア)の登録者数を取得し、Bigqueryにデータを格納するものになっています。
まずは、今回使用していくツールについて簡単に触れたいと思います。
Cloud ComposerとBigqueryの基本
ここは世の中に分かりやすい説明をしているサイトがたくさん存在しているので、特に説明が分かりやすかったサイトの紹介をします。
では、次に各種ツールに基本的な設定を行っていきたいと思います。
Youtube APIの初期設定
Youtube APIを叩けるように初期設定を行います。基本はGCPのServices項目の中からYouTube Data APIを探し、有効化すれば扱えるようになります。その後、Youtube API keyの保存をしておきます。
ここら辺は、公式サイトを見ればわかると思います。
GCPサービスの環境設定
以下のサイトを参考に諸々設定すれば問題ないです。ただ、私はUIを使って設定する方が楽なのでUIを使用してCloud ComposerとBigqueryの設定を行っています。
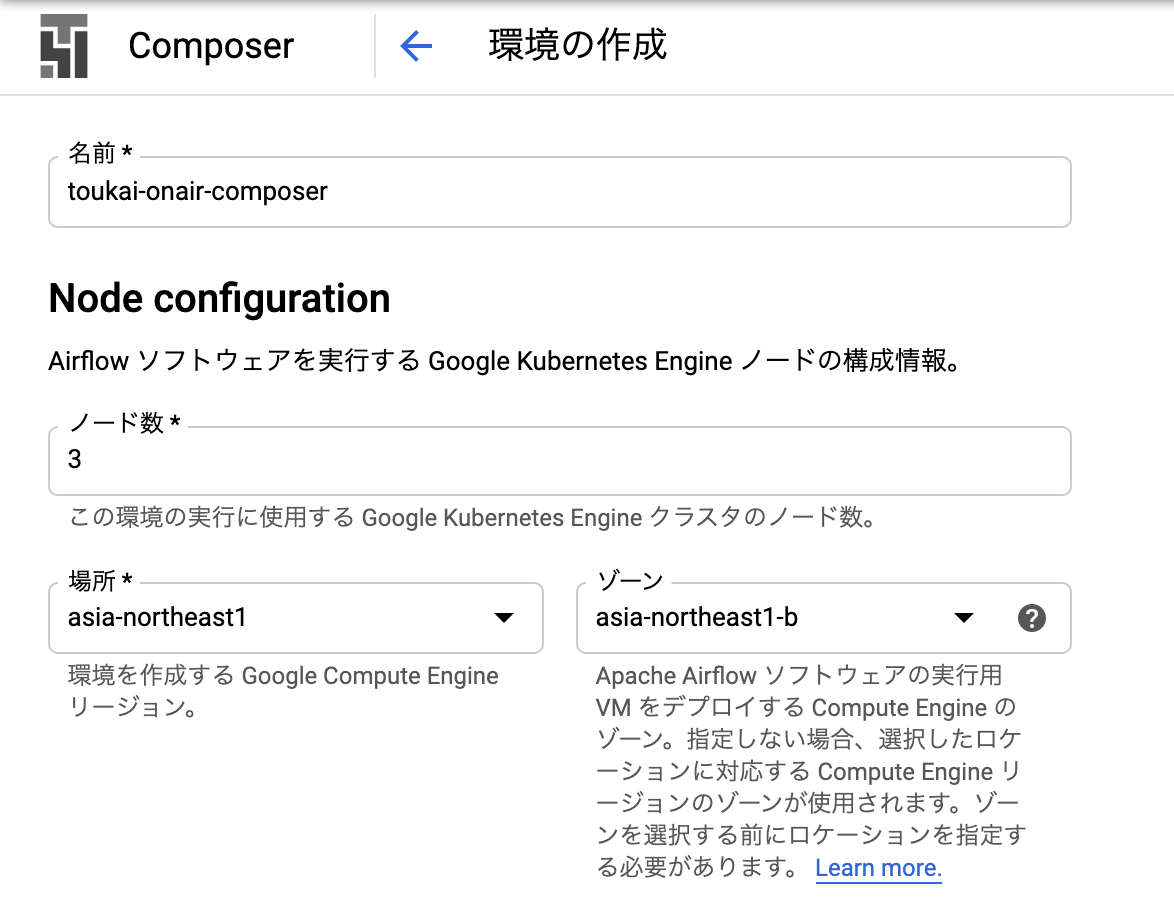
Cloud Composer
以下の部分だけ設定し、あとは何も設定せずで「作成」を押します。composerの作成にはかなり時間かかります。
ライブラリのインストール
composerの作成が完了したら以下の作業に進みます。
ここでは、composerにyoutube-APIをインストールしないと、後々composer上からYoutubeAPIが叩けるようにならないので、予めcomposerにYoutubeAPIをインストールします。
まずは、以下のような中身のファイルを作成しておきます。
youtube-data-api
こちらのファイルをCloud Shellにアップロードします。アップロードは公式サイトを参考にすればできます。
そして以下のコードをCloud Shell上で実行します。
gcloud config set core/project プロジェクト名
gcloud composer environments update composer名(toukai-onair-composer) --update-pypi-packages-from-file requirements.txt --location ロケーション名(asia-northeast1)
Bigquery
以下のサイトに記載されている通りに、テーブルを作成します。
ComposerのDAG定義を作成
環境設定は大体終わったので、YoutubeAPIを叩いて、Bigqueryに格納するコードを書いていきます。
Youtube APIを叩くコード
以下は、channel_idとapi_keyを与えると、特定のチャンネルの総再生回数とチャンネル登録者数を返すコードです。
from apiclient.discovery import build
class Youtubeapi:
def __init__(self, channel_id, api_key):
self.channel_id = channel_id
if not channel_id:
raise Exception("need channel_id")
self.api_key = api_key
if not api_key:
raise Exception("need api_key")
def get_statistics_data(self):
youtube = build('youtube', 'v3', developerKey=self.api_key)
search_response = youtube.channels().list(
part='statistics',
id=self.channel_id,
).execute()
return search_response['items'][0]['statistics']
ちなみにchannel_idはYoutubeでお好きなYoutuberをぐぐり、そこに入った時のURLリンクに記載されています。東海オンエアだと以下のようなリンクになっているので、channel_idはUCutJqz56653xV2wwSvut_hQになります。
https://www.youtube.com/channel/UCutJqz56653xV2wwSvut_hQ
api_keyはYoutube APIを有効化したタイミングでも取得できますが、以下の認証情報のところからも確認できます。

Bigqueryへ格納するDAG定義
以下は、Youtubeapiクラスを利用してYoutubeAPIを叩き、Bigqueryにデータを格納するDAGのコードです。
from airflow import DAG
from airflow.operators.dummy_operator import DummyOperator
from airflow.operators.python_operator import PythonOperator
from datetime import datetime
from google.cloud import bigquery
from lib import youtubelib
start = DummyOperator(task_id='start')
GCP_PROJECT = プロジェクト名
BQ_YOUTUBE_DATASET = データセット名.テーブル名
YOUTUBE_CHANNEL_ID = 東海オンエアのチャンネルID('UCutJqz56653xV2wwSvut_hQ')
YOUTUBE_API_KEY = YoutubeのAPIKey
# see https://cloud-textbook.com/69/#_start_dateschedule_intervalcatchup
default_args = {
'owner': 'airflow',
'start_date': datetime(2020, 5, 18),
'retries': 0,
'max_active_runs': 1,
}
schedule_interval = '0 17 * * *'
# define dag
dag = DAG('toukai_trends', default_args=default_args,
schedule_interval=schedule_interval, catchup=False)
youtubeapi = youtubelib.Youtubeapi(channel_id=YOUTUBE_CHANNEL_ID, api_key=YOUTUBE_API_KEY)
def pull_youtube_statistics_api(ds, **kwargs):
statistics = youtubeapi.get_statistics_data()
dt = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
print('dt', dt)
viewcount = statistics['viewCount']
print('viewCount', viewcount)
subscribercount = statistics['subscriberCount']
print('subscriberCount', subscribercount)
videocount = statistics['videoCount']
print('videoCount', videocount)
bigquery_client = bigquery.Client()
query = '''
INSERT
`{0}.{1}`
SELECT
CAST("{2}" AS timestamp) AS datetime,
CAST("{3}" AS INT64) AS viewcount,
CAST("{4}" AS INT64) as subscribercount,
CAST("{5}" AS INT64) as videocount
'''.format(GCP_PROJECT, BQ_YOUTUBE_DATASET, str(dt), str(viewcount), str(subscribercount), str(videocount))
rows = bigquery_client.query(query).result()
return 'ok'
job_transactiondetail_puller = PythonOperator(
task_id='pull_youtube_statistics_api',
provide_context=True,
python_callable=pull_youtube_statistics_api,
dag=dag,
)
composerの定期実行(define dagの部分)に関しては色々ややこしいところがあるのでクラウドサービス徹底比較・徹底解説 (2020年版)の定期実行に関するややこしい話 (start_date・schedule_interval・catchup 等) 編を確認してみてください。
DAGの定義をCloud Composerにアップロード
dag.pyをCloud Shellにアップロードし、Shell上で以下を行います。
gcloud composer environments storage dags import --environment=composer名
(toukai-onair-composer) --location=asia-northeast1 --source=./dag.py
実行するとGCS上にファイルができており、そこにyoutubelib.pyも置いておきます。
動作確認
GCP Cloud ComposerでBigQueryのテーブルを操作するワークフローを作る手順のCloud ComposerのDAGの実行状況確認と同じように確認すれば問題ありません。
Airflow内のview logsから実行結果のログも確認できます。
価格感
実行してみて実感したのですが、やっぱり高いです。
僕のお小遣いだと痛いレベルだったので、長期間実行はやめました、、、
値段感はクラウドサービス徹底比較・徹底解説 (2020年版)の料金編をみてみてください。
まとめ
作ってみたものの、値段が高すぎて個人で使うのは難しそうでした、、、
次はCloud Finctionの定期実行とかで行ってみることでもっと安く同じデータパイプラインが作れるかなと思っていますので、試してみようかなと思っています!