はじめに
ラズパイの測定情報をbig queryに入れ、metabaseでグラフに可視化している書き込みがあったので、試してみました。しかし、データの取り込みをするための操作で、クレジットカードの登録が必要ということが分かったので、途中であきらめることにしました。試してみる際に、やったことをまとめてみます。
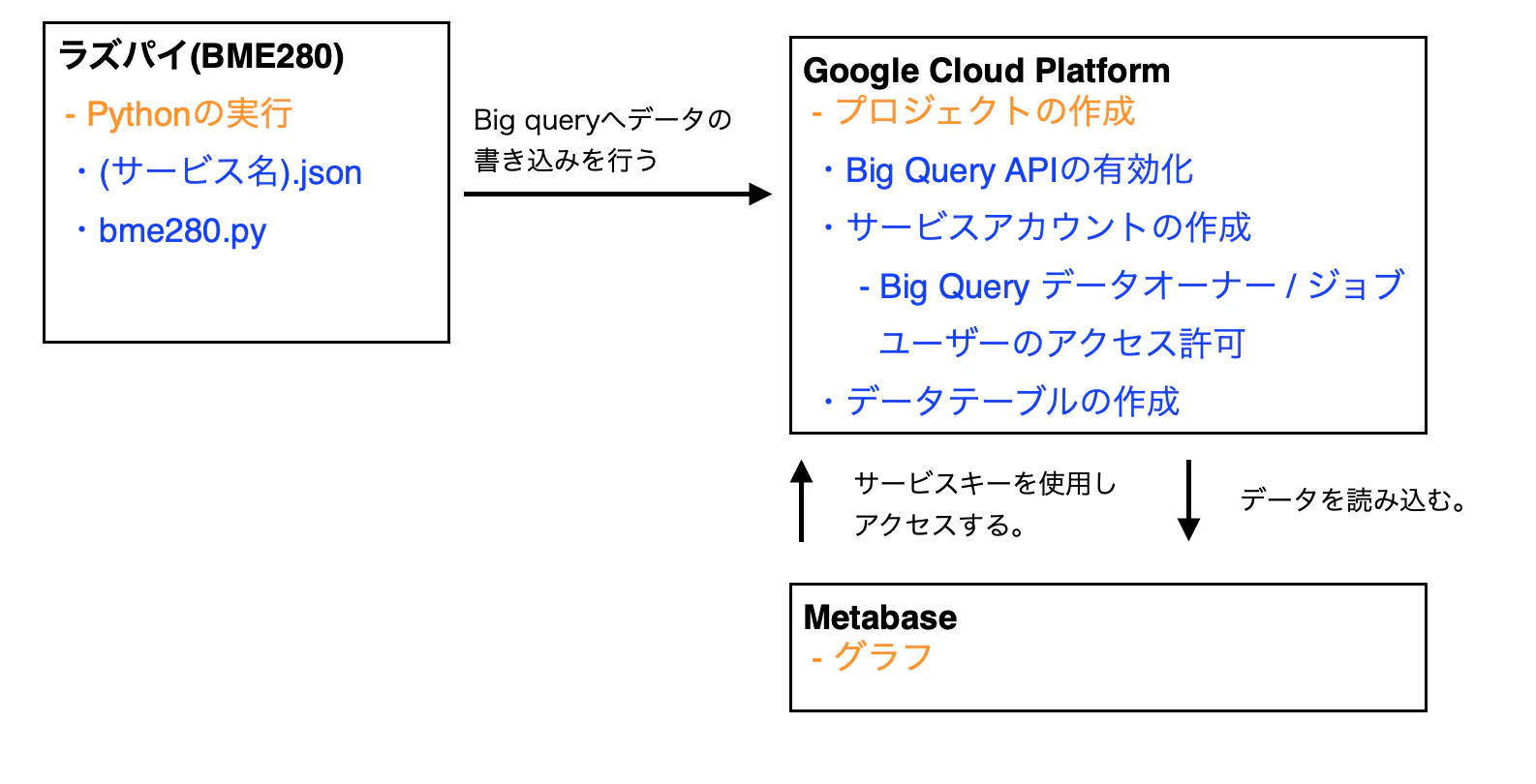
イメージ
今回行うのは、ラズパイにBME280をつけて、湿度、温度、気圧のデータを取得し、Big Queryのデータテーブルに書き込みを行います。そのデータをグラフで確認するためにmetabaseで見れるようにします。そのためには、Google Could Platform内で、Big Query APIの有効化、サービスアカウントを作成し、Big Queryのアクセス権限、データテーブルの作成が必要になります。また、ラズパイやMetabaseがBig Queryへアクセスするためには、サービスアカウントで作成したxxx.jsonファイルを使います。ただ、今回は、Big Queryへのデータの取り込みをするために必要なクレジットカードの登録の手続きをしていません。
環境
Python version:3.9.7
OS: windows: 10.0
Linux raspberrypi: 5.10.63+
1.GCPの設定
1.1 サービスアカウントの発行
Big QueryからMetabase接続を行うため、サービスアカウントを作成します。
- IAMと管理 -> サービスアカウント -> サービスアカウントを作成をクリックします。
- 適当にサービスアカウント名を入力し、作成して続行を押す。今回、big-query-userとしています。

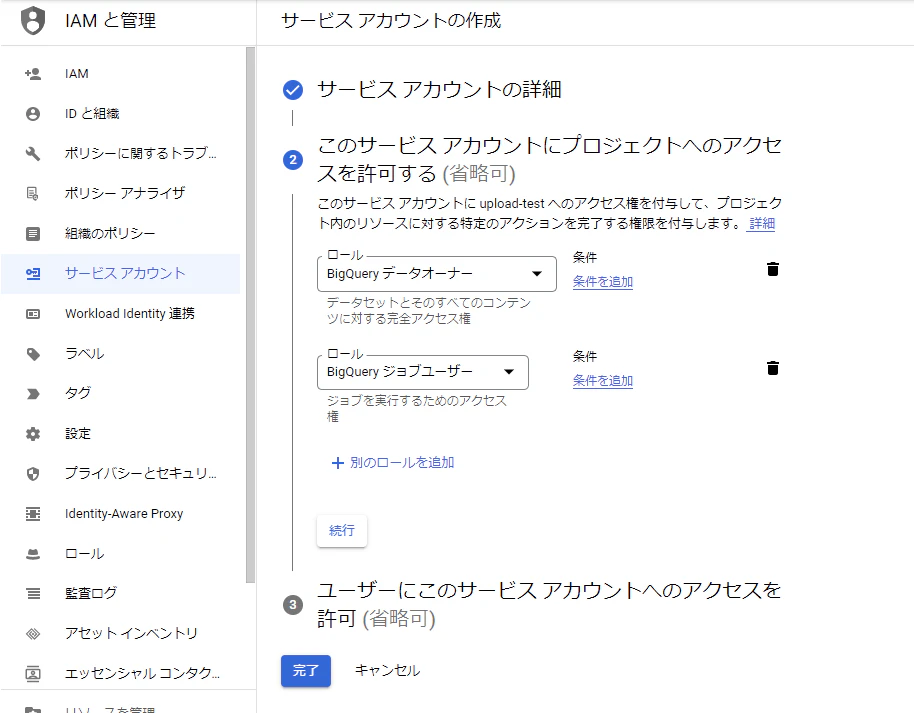
- 下記2つのプロジェクトへのアクセス権限を与え、完了をクリックします。
- Big Query データオーナー
- Big Query ジョブユーザー
- 作成したサービスアカウントの右側に操作という欄があり、そこの3つの点の部分をクリックして、「鍵を作成」をクリックします。ここで作成したjsonファイルは、後ほど使用します。これを使用することで、Big Queryへアクセスできるようになります。
1.2 Big Queryのデータセット作成
- GCPのサイトにアクセスします。APIとサービス -> ライブラリで-> BigQuery APIを有効化します。
- BigQuery -> SQL ワークスペースをクリックします。プロジェクト名の横にある点々の部分にカーソルを置くと、データセットを作成が出てきます。データセットID、データロケーションを設定し、データセットを作成をクリックします。
1.2.1 tabel作成
プロジェクトIDの横の点三つの部分をクリックすると、データセットの作成ができます。適当な名前を入力してください。私は、mydatasetとしました。作成後、データセットを選択し、右にあるクエリを新規作成をクリックし、下記のように入力してください。mydatasetの部分は、自分が作成したデータセット名に変更して下さい。これで、テーブルの作成ができます。
CREATE TABLE
mydataset.bme280
(
datetime timestamp
, Temperature FLOAT64
, Humidity FLOAT64
, Pressure FLOAT64
)
2. Metabaseのインストール
2.1 Javaの確認
1.下記コマンドをコマンドプロンプトに打ち込み、Javaが入っているか確認する。あれば、java version “xx.x.xx”と表示される。
java -version
2.2 Java、Metabaseのインストール
- 表示されなかった場合、ダウンロードします。こちらのサイトに飛び、「Install Java JRE」の「Eclipse Temurin」からダウンロードを行います。
- 再度、こちらのサイトに飛び、「Download Metabase」の「Metabase download page 」をクリックします。
- ダウンロードしたファイルを特定の場所に置きます。コマンドプロンプトは、置いたディレクトリまで移動し、下記コマンド入力します。
// metabase.jarの置いたディレクトリへ移動
cd C:\xxxx\xx\metabase
// コマンドの実行
java -jar metabase.jar
2.3 ブラウザの起動(Metabase)
- 走行のlogをみると、下記の黄色で塗りつぶしたメッセージが出てくるので、これを、ブラウザのURLに入力し、アクセスします。
// このリンクをブラウザで開く
http://localhost:3000/setup/

6. データ追加するの部分まで適当に入力し、Big Queryを選びます。表示名は、何でもよく、Project IDは、Google Cloud Platformで作成したjsonファイルを選択します。そのあとは、適当に入力してください。
3.ラズパイでの操作
3.1google-cloud-bigqueryのインストール
- 下記コマンドでライブラリをインストールしてください。
pip install --upgrade google-cloud-bigquery
3.2 pythonファイルの作成
ラズパイにbme280.pyとjsonファイルを置き、pythonを走行させます。ただ、クレジットカードの登録をしていないので、後半に示すようなエラーが出ます。
from smbus2 import SMBus
import time
from google.cloud import bigquery
import os
import datetime
from pathlib import Path
credentials_json = './upload-test.json'
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = credentials_json
bus_number = 1
i2c_address = 0x76
bus = SMBus(bus_number)
digT = []
digP = []
digH = []
t_fine = 0.0
def writeReg(reg_address, data):
bus.write_byte_data(i2c_address,reg_address,data)
def get_calib_param():
calib = []
for i in range (0x88,0x88+24):
calib.append(bus.read_byte_data(i2c_address,i))
calib.append(bus.read_byte_data(i2c_address,0xA1))
for i in range (0xE1,0xE1+7):
calib.append(bus.read_byte_data(i2c_address,i))
digT.append((calib[1] << 8) | calib[0])
digT.append((calib[3] << 8) | calib[2])
digT.append((calib[5] << 8) | calib[4])
digP.append((calib[7] << 8) | calib[6])
digP.append((calib[9] << 8) | calib[8])
digP.append((calib[11]<< 8) | calib[10])
digP.append((calib[13]<< 8) | calib[12])
digP.append((calib[15]<< 8) | calib[14])
digP.append((calib[17]<< 8) | calib[16])
digP.append((calib[19]<< 8) | calib[18])
digP.append((calib[21]<< 8) | calib[20])
digP.append((calib[23]<< 8) | calib[22])
digH.append( calib[24] )
digH.append((calib[26]<< 8) | calib[25])
digH.append( calib[27] )
digH.append((calib[28]<< 4) | (0x0F & calib[29]))
digH.append((calib[30]<< 4) | ((calib[29] >> 4) & 0x0F))
digH.append( calib[31] )
for i in range(1,2):
if digT[i] & 0x8000:
digT[i] = (-digT[i] ^ 0xFFFF) + 1
for i in range(1,8):
if digP[i] & 0x8000:
digP[i] = (-digP[i] ^ 0xFFFF) + 1
for i in range(0,6):
if digH[i] & 0x8000:
digH[i] = (-digH[i] ^ 0xFFFF) + 1
def readData():
data = []
for i in range (0xF7, 0xF7+8):
data.append(bus.read_byte_data(i2c_address,i))
pres_raw = (data[0] << 12) | (data[1] << 4) | (data[2] >> 4)
temp_raw = (data[3] << 12) | (data[4] << 4) | (data[5] >> 4)
hum_raw = (data[6] << 8) | data[7]
sensor_data = []
sensor_data.append(compensate_T(temp_raw))
sensor_data.append(compensate_P(pres_raw))
sensor_data.append(compensate_H(hum_raw))
return sensor_data
def compensate_P(adc_P):
global t_fine
pressure = 0.0
v1 = (t_fine / 2.0) - 64000.0
v2 = (((v1 / 4.0) * (v1 / 4.0)) / 2048) * digP[5]
v2 = v2 + ((v1 * digP[4]) * 2.0)
v2 = (v2 / 4.0) + (digP[3] * 65536.0)
v1 = (((digP[2] * (((v1 / 4.0) * (v1 / 4.0)) / 8192)) / 8) + ((digP[1] * v1) / 2.0)) / 262144
v1 = ((32768 + v1) * digP[0]) / 32768
if v1 == 0:
return 0
pressure = ((1048576 - adc_P) - (v2 / 4096)) * 3125
if pressure < 0x80000000:
pressure = (pressure * 2.0) / v1
else:
pressure = (pressure / v1) * 2
v1 = (digP[8] * (((pressure / 8.0) * (pressure / 8.0)) / 8192.0)) / 4096
v2 = ((pressure / 4.0) * digP[7]) / 8192.0
pressure = pressure + ((v1 + v2 + digP[6]) / 16.0)
pressure = pressure/100
return pressure
def compensate_T(adc_T):
global t_fine
v1 = (adc_T / 16384.0 - digT[0] / 1024.0) * digT[1]
v2 = (adc_T / 131072.0 - digT[0] / 8192.0) * (adc_T / 131072.0 - digT[0] / 8192.0) * digT[2]
t_fine = v1 + v2
temperature = t_fine / 5120.0
return temperature
def compensate_H(adc_H):
global t_fine
var_h = t_fine - 76800.0
if var_h != 0:
var_h = (adc_H - (digH[3] * 64.0 + digH[4]/16384.0 * var_h)) * (digH[1] / 65536.0 * (1.0 + digH[5] / 67108864.0 * var_h * (1.0 + digH[2] / 67108864.0 * var_h)))
else:
return 0
var_h = var_h * (1.0 - digH[0] * var_h / 524288.0)
if var_h > 100.0:
var_h = 100.0
elif var_h < 0.0:
var_h = 0.0
hum = var_h
return hum
def setup():
osrs_t = 1 #Temperature oversampling x 1
osrs_p = 1 #Pressure oversampling x 1
osrs_h = 1 #Humidity oversampling x 1
mode = 3 #Normal mode
t_sb = 5 #Tstandby 1000ms
filter = 0 #Filter off
spi3w_en = 0 #3-wire SPI Disable
ctrl_meas_reg = (osrs_t << 5) | (osrs_p << 2) | mode
config_reg = (t_sb << 5) | (filter << 2) | spi3w_en
ctrl_hum_reg = osrs_h
writeReg(0xF2,ctrl_hum_reg)
writeReg(0xF4,ctrl_meas_reg)
writeReg(0xF5,config_reg)
def insert_table(data):
## Set Project ID
project = "upload-test-342900"
## Set Dataset
dataset = "mydataset"
## Set Table
table = "bme280"
bigquery_client = bigquery.Client()
query = "INSERT INTO `{0}.{1}.{2}` values('{3}',{4},{5},{6})".format(project, dataset, table,datetime.datetime.now(),data[0],data[1],data[2])
rows = bigquery_client.query(query).result()
setup()
get_calib_param()
if __name__ == '__main__':
try:
data = readData()
insert_table(data)
except KeyboardInterrupt:
pass
今回作成したプログラムを走行させると、下記のようなエラーが出ました。このエラーは、クレジットカードの登録ができていないときに出るそうです。リンクを参照してください。
google.api_core.exceptions.Forbidden: 403 Billing has not been enabled for this project. Enable billing at https://console.cloud.google.com/billing. DML queries are not allowed in the free tier. Set up a billing account to remove this restriction.
語句
仕事でデータベースを扱うことがないので、知らない言葉が多いため、用語について調べてみました。
Metabase
Metabase(メタベース)は、Metabaseプロジェクトによって開発されているオープンソースのデータ可視化ツール(BIツール)です。当初Metabaseは、Uberの共同創業者Garrett Campが2013年に設立したスタートアップスタジオ、Expaが開発した内製ツールでした。
Metabaseは外部のデータソース(BigQurery, Google Analytics, MongoDB, MySQL, etc...)を参照してデータを分析します。Metabase自身には分析対象となるデータを保存する必要はなく、この外部データソースを元にして分析に必要な情報やキーワードをMetabase上で問い合わせることで、チャートやグラフなどによりデータが可視化されます。
BigQuery は Google Cloud にて提供されているプロダクトで、ビッグデータを超高速で解析することができるサービスです。
おわりに
今回、Big Query,Metabaseを操作してみて、データベース周りを理解してみたくなりました。時間があるときに調べてみるつもりです。
link
今回、参照させていただいたリンク集です。
Google スプレッドシートで管理しているデータを BigQuery から参照して SQL で集計してみた。
MetabaseからGoogle BigQueryのデータを可視化する。
ラズパイで温度・湿度・気圧センサー(HiLetgo BME280)からpython3で値を取得し、 Google BigQueryに記録する。(後編)