はじめに
- 前回、可視化 / モニタリング / 標準化/リファクタリングのタスク(案)を列挙したところまで整理しました。
- 今回は、
モニタリングにフォーカスした内容を書きます。- 弊社が利用しているアーキテクチャの情報が載っていますが、適宜ご自分の環境に読み替えていただけますと幸いです
前提条件
- 弊社では、業務管理のツールとして、
Atlassian社のJIRA Softwareを利用している。- システムのモニタリングはDatadog、コミュニケーションツールはslackを利用
- 弊社では
作業というくくりで、以下を包括する。- 依頼作業
- インシデント対応
- 課題対応
- セキュリティ対応
- 業務改善
弊社における作業の流れ
- 基本的な作業発生から作業完了までの流れは以下の図の通り。
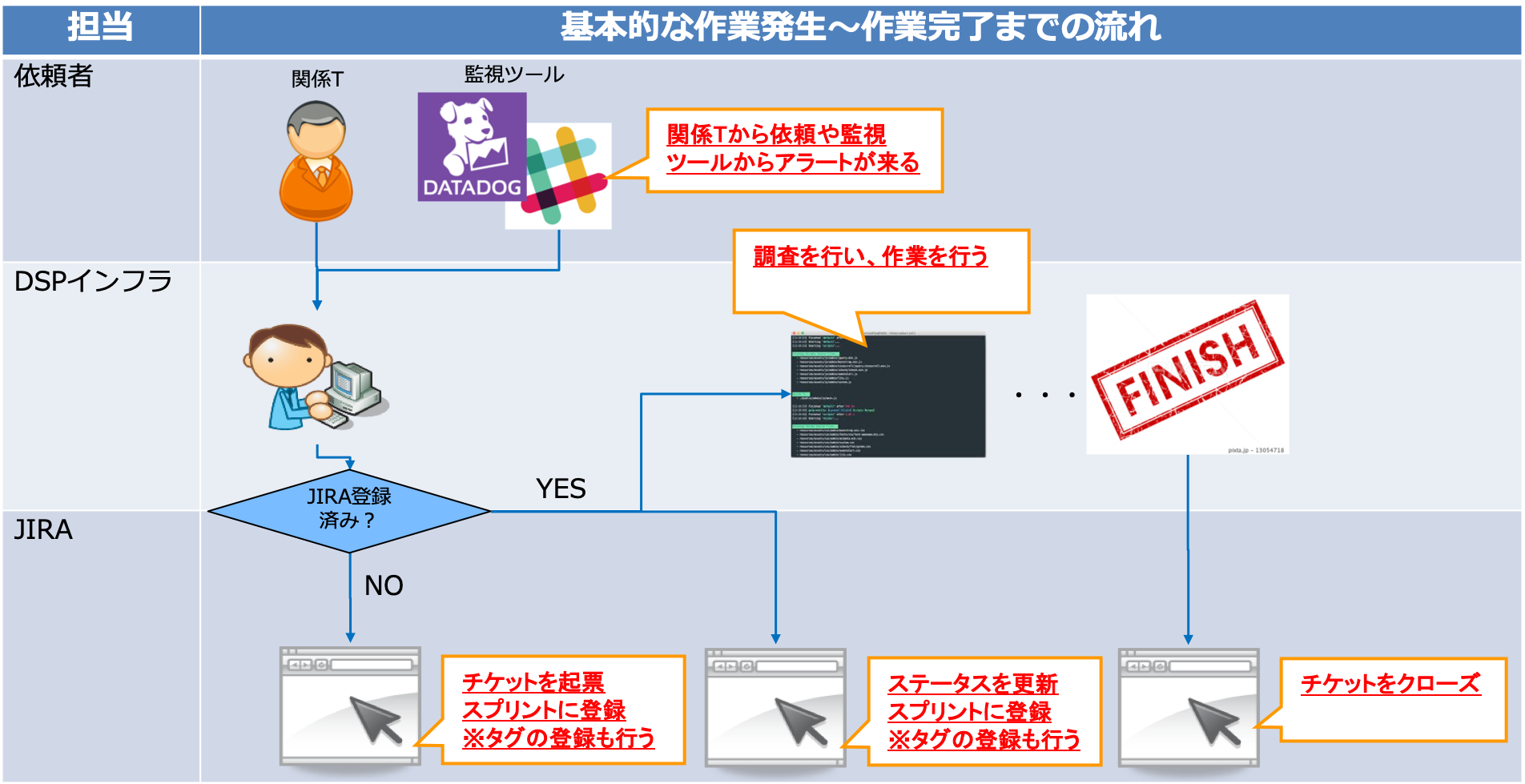
モニタリングの一例
-
JIRAのダッシュボード機能を用いて、月単位の各作業区分におけるチケット数を集計し、トレンドを把握する。
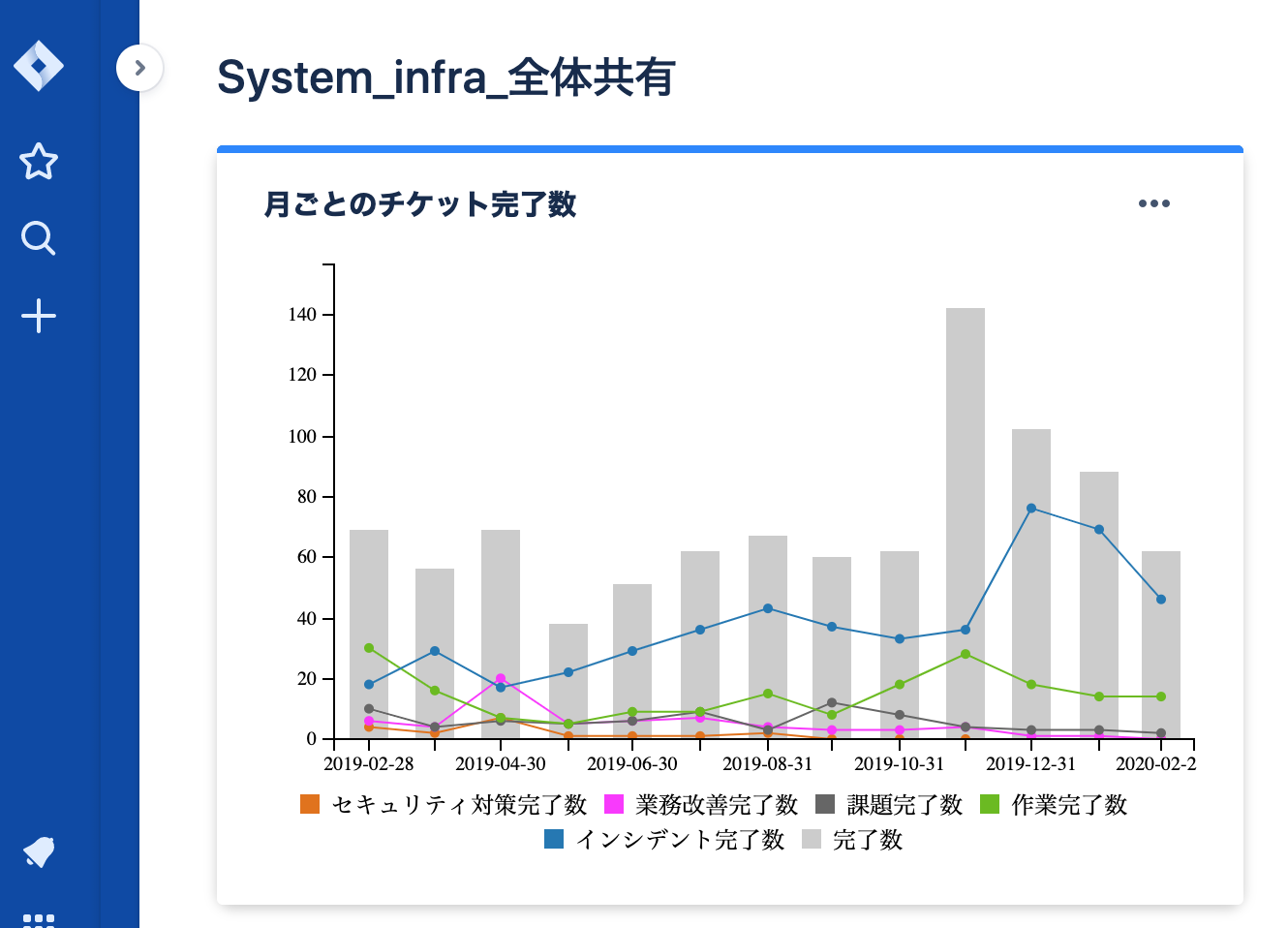
- 上記の例で言うと、例えば以下を読み取ることができる。
- 2019年12月のインシデント数が急激に増えている
- 調査したところ、
Hadoopクラスタの停止が12月に頻発していた
- 調査したところ、
- 2020年に入ってからはインシデント数が減少傾向にある
- 長期休暇の前後は依頼作業が増える傾向にある
- 2019年12月のインシデント数が急激に増えている
- 多角的に数値分析を可能にするために各作業区分に対応した
フィルターを用意する。- ステータスで分類する
- 完了
- 着手中
- 未着手
- 未解決
- ステータスで分類する

苦労・工夫した点
-
業務内容を全てJIRAチケット化するという文化を根付かせることからスタート。
- 過去はslackに依頼事項やインシデント情報が書かれるのみで、集計や分析ができる状態ではなかった
- このままでは
誰が何をしているのか?が可視化・共有できておらず、課題と捉えて改善を実施
- ダッシュボードのモニタリングのみでは課題・懸案を吸い上げることができない。
- 週次でJIRAチケットの状況を確認する会議体を設け、チケットベースでの進捗や課題・懸案事項を吸い上げる場を設定している
- Datadogが通知するアラートをトリガーにJIRAチケット起票を自動化した。
- インシデントの集計・分析ができないとプロアクティブな対策が取れず、ナレッジも残っていなかった
- 設定等は別で整理します
- インシデントの集計・分析ができないとプロアクティブな対策が取れず、ナレッジも残っていなかった