はじめに
こんにちは!下野祐太です.
最近プラグインも開放されて注目度は増すばかりの「ChatGPT」を活用して,毎日の論文サーベイを効率化する機能を実装しました.
今回はどのように実装したのかを,サンプルコードも交えながら紹介したいと思います.
また実装コードも公開しているため,詳細な内容はそちらを参照いただけると幸いです.
概要
動機
毎日最新の論文をサーベイしているのですが,以下の課題を感じていました.
- 毎日論文を検索してチェックしていくのが面倒くさい
- タイトルだけで論文を判断すると精度が悪いが,アブストラクトまできちんと読むとそれなりに時間がかかる
- Twitter等でホットな論文を紹介してくれる人もいるが,自分の興味分野と完全に一致している訳では無い
このような課題を解決するために,以下の機能を実装しました.
- arXivから特定のキーワードで最新論文を検索し,ChatGPTで3行要約してSlackに投稿する
- Slackで確認するだけだと流れていくため,サマリーをNotionのデータベースに保存する
主な手順
では次に,具体的な手順について説明します.
以下の図は大まかな手順を表したもので,大きく上段のpaper letterと下段のsummarize paperに分かれます.
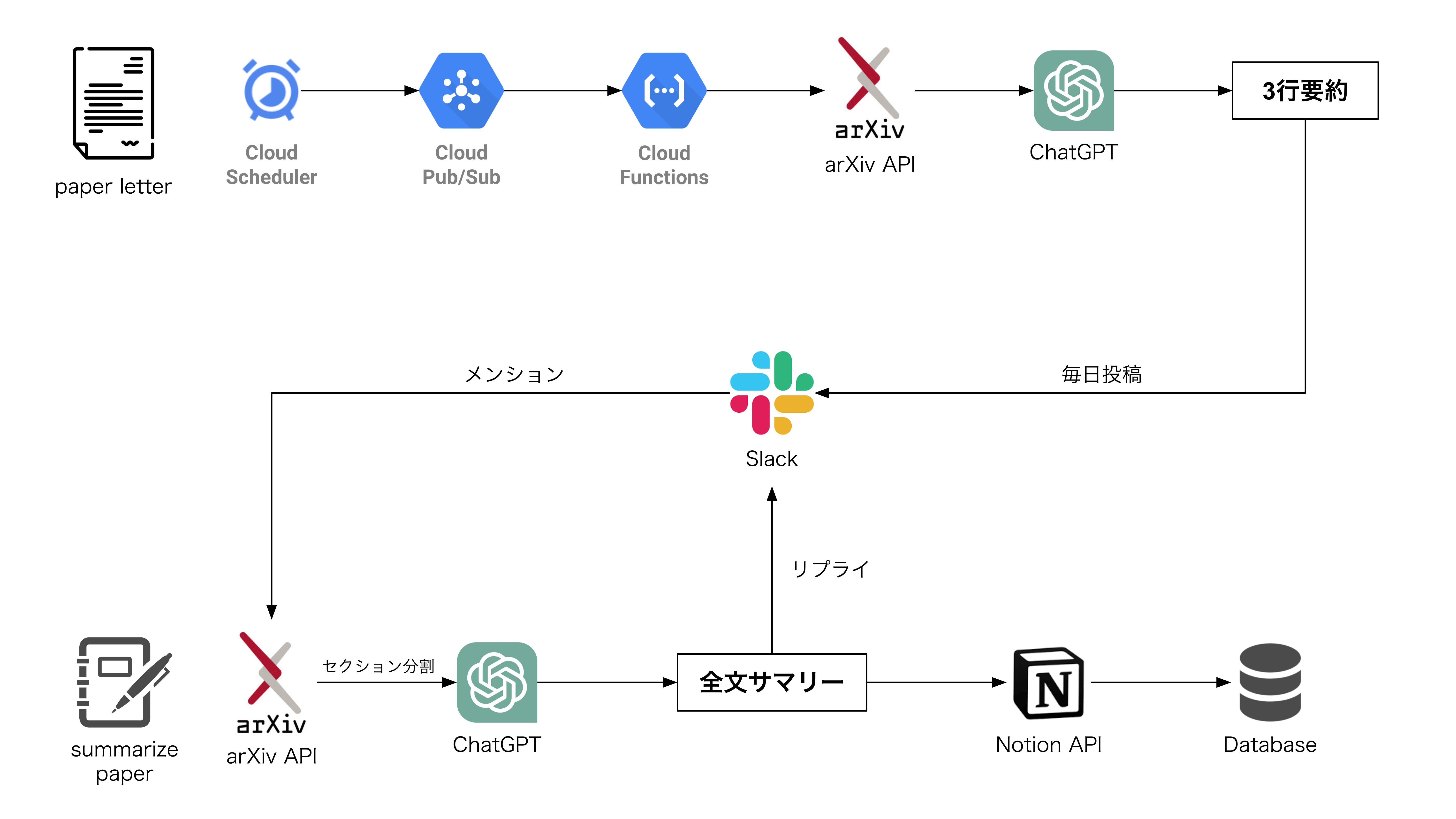
-
paper letter
毎朝アブストラクトの3行要約を,Slackにお届けしてくれます.
詳細なフローは以下の通りです.- GCPのCloud Schedulerが決まった時間に発火し,Cloud Functionsを実行
- 事前に設定したキーワードで,arXivから最新論文を検索
- ChatGPTでアブストラクトを3行要約
- 結果をSlackに投稿
-
summarize paper
投稿された論文から興味があるものを選択して,全文要約をNotionのデータベースに保存します.
詳細なフローは以下の通りです.- 興味がある論文の投稿に対して,ボットにメンションをつけてリプライを送信
- 取得した論文をセクション分割
- 各セクションごとにChatGPTを用いて要約を作成
- Notionのデータベースに保存
実装
ここからはコードを交えて具体的な実装方法を説明します.
1. Paper Letter
1-1. arXivから最新論文を検索
今回は論文を取得するために,arXiv APIを用いています.
検索時に指定している条件は,以下の通りです.
- 検索したいキーワードをタイトルかアブストラクト中に含む論文
- 期間はarXivの更新の関係上,1週間前を指定
# テンプレートを用意
QUERY_TEMPLATE = '%28 ti:%22{}%22 OR abs:%22{}%22 %29 AND submittedDate: [{} TO {}]'
# arXivの更新頻度を加味して,1週間前の論文を検索
today = dt.datetime.today() - dt.timedelta(days=7)
base_date = today - dt.timedelta(days=N_DAYS)
query = QUERY_TEMPLATE.format(keyword, keyword, base_date.strftime("%Y%m%d%H%M%S"), today.strftime("%Y%m%d%H%M%S"))
search = arxiv.Search(
query=query, # 検索クエリ
max_results=MAX_RESULT * 3, # 取得する論文数の上限
sort_by=arxiv.SortCriterion.SubmittedDate, # 論文を投稿された日付でソートする
sort_order=arxiv.SortOrder.Descending, # 新しい論文から順に取得する
)
arXiv APIのユーザーマニュアルは,以下を参照してください.
arXiv API User's Manual - arXiv info
1-2. 検索結果の格納
検索結果から,興味のある分野とは関係のないカテゴリの論文を事前に消去します.
# 興味があるカテゴリー群
CATEGORIES = {
"cs.AI",
...,
}
# searchの結果をリストに格納
result_list = []
for result in search.results():
# カテゴリーに含まれない論文は除く
if len((set(result.categories) & CATEGORIES)) == 0:
continue
result_list.append(result)
カテゴリーの一覧は以下を参照してください.
1-3. ChatGPTでアブストラクトを3行要約
1-2で抽出された論文に対して,ChatGPTを用いた3行要約を行います.
SYSTEM = """
### 指示 ###
論文の内容を理解した上で,重要なポイントを箇条書きで3点書いてください。
### 箇条書きの制約 ###
- 最大3個
- 日本語
- 箇条書き1個を50文字以内
### 対象とする論文の内容 ###
{text}
### 出力形式 ###
タイトル(和名)
- 箇条書き1
- 箇条書き2
- 箇条書き3
"""
def get_summary(result):
text = f"title: {result.title}\nbody: {result.summary}"
response = openai.ChatCompletion.create(
model=MODEL_NAME,
messages=[
{'role': 'system', 'content': SYSTEM},
{'role': 'user', 'content': text}
],
temperature=TEMPERATURE,
)
プロンプトは以下の記事を参考にしています.
ChatGPTと協創!arXiv論文要約ツールを作ってみた - Qiita
1-4. Slackに通知
得られた3行要約からメッセージを作成し,指定したSlackのチャンネルに投稿します.
# Slack APIクライアントを初期化する
client = WebClient(token=SLACK_API_TOKEN)
# Slackにメッセージを投稿する
response = client.chat_postMessage(
channel=SLACK_CHANNEL,
text=message
)
slack botの設定は,以下を参照してください.
1-5. GCPの設定
1-4までで実装したコードを,GCPのCloud Functionsに設定します.
定期実行するためには,Cloud Schedulerを利用してCloud Pub/Sub経由で関数を呼び出します.
詳細な設定方法は,以下の記事を参照してください.
サーバーレス + Pythonで定期的にスクレイピングを行う方法 - ガンマソフト
1-6. 実行結果
最後に定期実行されて,Slackに通知された結果を紹介します.
以下のように,興味のある分野に絞って,毎朝最新の論文をお届けしてくれます!

2. Summarize Paper
2-1. Slackからmentionを受け取る
今回はソケットモードでアプリを起動して,Slackからメンションを受け取ります.
# ボットトークンとソケットモードハンドラーを使ってアプリを初期化
app = App(token=os.environ.get("SLACK_BOT_TOKEN"))
# メンション時に情報を取得
@app.event("app_mention")
def handle_app_mention_events(body, logger, say):
logger.info(body)
bot_user_id = body['authorizations'][0]['user_id']
text = body['event']['text']
user = body['event']['user']
# アプリの起動
if __name__ == "__main__":
SocketModeHandler(app, os.environ["SLACK_APP_TOKEN"]).start()
以下はメンションを飛ばしているイメージです.

ソケットモードの始め方については,以下の記事を参照してください.
Slack ソケットモードの最も簡単な始め方 - Qiita
2-2. 論文のPDFをダウンロード
2-1で実装したメンションを受け取るだけでは,データベースに保存したい論文の情報を取得することができません.
そのためメンションが飛ばされたスレッドの情報を読み取り,論文のURLを取得します.
def get_thread_messages(channel_id, thread_ts):
result = app.client.conversations_replies(
channel=channel_id,
ts=thread_ts,
limit=1000,
)
thread_messages = result["messages"]
こちらは,以下の実装を参考にしています.
AI-LaBuddy/slack-qa at main · kenoharada/AI-LaBuddy
得られたテキストから論文のidを抽出し,以下のようにダウンロードします.
paper = next(arxiv.Search(id_list=[arxiv_id]).results())
pdf_file_name = paper.title.replace(' ', '_')
os.makedirs(f"./pdf/{pdf_file_name}", exist_ok=True)
pdf_file_path = paper.download_pdf(dirpath=f"./pdf/{pdf_file_name}", filename=f"{pdf_file_name}.pdf")
2-3. 論文をセクション分割
論文全文を一度にChatGPTに入力する場合,トークン長の制限やモデル自体の精度の問題から,期待する精度の要約を得ることが難しいです.
そのため論文を各セクションごと(Introduction, Method等)に分割し,それぞれ要約しました.
今回はgrobidというライブラリを使用してxmlファイルを生成し,セクション分割を実施しています.
def section_splitting(pdf_file_name):
cp = subprocess.run(
f"java -Xmx4G -jar /path/to/grobid/grobid-0.7.2/grobid-core/build/libs/grobid-core-0.7.2-onejar.jar -gH /workspace/grobid/grobid-0.7.2/grobid-home -dIn /path/to/pdf/{pdf_file_name}/ -dOut /path/to/xml -exe processFullText",
shell=True,
)
file_name = os.path.splitext(pdf_file_name)[0]
xml_path = f"./xml/{file_name}.tei.xml"
tree = ET.parse(xml_path)
root = tree.getroot()
sections = []
for div in root[1][0]:
section = Section("", "")
for element in div:
if (element.tag == "{http://www.tei-c.org/ns/1.0}head"):
section.title = element.text
if (element.tag == "{http://www.tei-c.org/ns/1.0}p"):
section.body += get_text(element)
if section.body != "":
sections.append(section)
return sections
実装は以下の記事を参考にしています.
OpenAIのGPT-3.5系APIを使って論文を自動で要約する - Qiita
2-4. 論文を要約
2-3でセクションごとに分割した文章について,要約を行います.
ただしセクションによっては分量が十分ではない可能性があるため,分量ごとに処理を変更しています.
本来はセクションの階層ごとに”#”の数を指定していますが,下記コード例では割愛していることに注意してください.
summarizer = pipeline("summarization", model="kworts/BARTxiv")
translator = pipeline('translation', model='staka/fugumt-en-ja')
markdown_text = ""
start = 0
for section in tqdm(sections):
markdown_text += f"\n\n### {section.title}"
# 144文字以下の場合は,全文を翻訳する
if len(section.body.split(" ")) < 144:
translated_text = translator(section.body)[0]['translation_text']
# 144〜500文字の場合は,全文を踏まえて要約する
elif len(section.body.split(" ")) < 500:
summary = summarizer(section.body)[0]['summary_text']
translated_text = translator(summary)[0]['translation_text']
# 500文字以上の場合は,全文を踏まえて要約する
else:
response = openai.ChatCompletion.create(
model=MODEL_NAME,
messages=[
{'role': 'system', 'content': SYSTEM},
{'role': 'user', 'content': section.body}
],
temperature=TEMPERATURE,
)
translated_text = translator(response['choices'][0]['message']['content'])[0]['translation_text']
markdown_text += "\n" + translated_text
2-5. Notionページの作成
arXiv APIから得られる論文の情報を用いて,Notionページを作成します.
以下の画像のように,「タイトル・日付・3行要約・タグ・URL・著者・アブストラクト」をカラムとして設定しています.
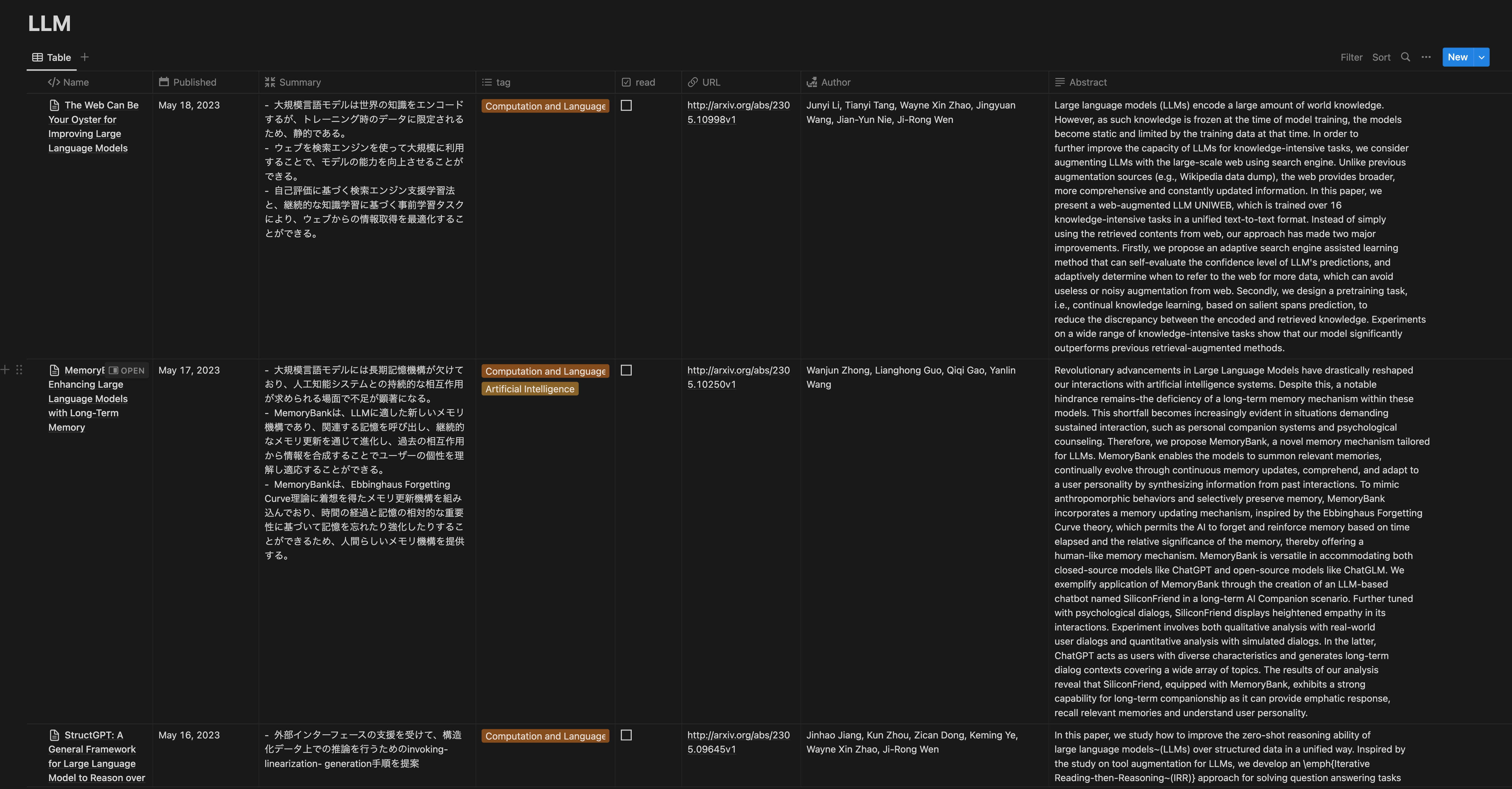
実装は以下の通りです.
def create_page(paper, summary, database_id: str, is_debug=False):
# プロパティの設定
PROPERTIES["Name"]["title"][0]["text"]["content"] = paper.title
PROPERTIES["Published"]["date"]["start"] = paper.published.strftime("%Y-%m-%d")
PROPERTIES["URL"]["url"] = paper.entry_id
PROPERTIES["Author"]["rich_text"][0]["text"]["content"] = ", ".join([author.name for author in paper.authors])
PROPERTIES["tag"]["multi_select"] = [
{'name': CATEGORY_LABELS[category]}
for category in paper.categories
if category in CATEGORY_LABELS
]
PROPERTIES["Summary"]["rich_text"][0]["text"]["content"] = summary
PROPERTIES["Abstract"]["rich_text"][0]["text"]["content"] = paper.summary
create_url = "https://api.notion.com/v1/pages"
payload = {"parent": {"database_id": database_id}, "properties": PROPERTIES}
response = requests.post(create_url, headers=HEADERS, json=payload)
if is_debug:
assert response.status_code == 200, f"{response.content}"
Notion APIを利用してデータベースを操作する方法は以下が詳しいので,適宜参照してください.
2-6. Notionページに全文要約を記載
作成したNotionのページに対して,各セクションごとに要約した内容を記載していきます.
文章の始めにある”#”の数に応じて,見出しを調整しています.
また最後に,元の論文のPDFを貼り付ける処理を実施しています.
def write_to_notion_page(markdown_text, paper, page_id, is_debug=False):
payload = {"children": []}
for sentence in markdown_text.split("\n"):
if "#" in sentence:
n_head = len(sentence.split(" ")[0])
if n_head >= 4:
payload["children"].append({"paragraph": {"rich_text": [{"text": {"content": " ".join(sentence.split(" ")[1:])}}]}})
else:
payload["children"].append({f"heading_{n_head}": {"rich_text": [{"text": {"content": " ".join(sentence.split(" ")[1:])}}]}})
else:
payload["children"].append({"paragraph": {"rich_text": [{"text": {"content": sentence}}]}})
payload["children"].append({"heading_1": {"rich_text": [{"text": {"content": "元論文"}}]}})
payload["children"].append({"pdf": {"type": "external", "external": {"url": f"https://arxiv.org/pdf/{paper.entry_id.split('/')[-1]}.pdf"}}})
url = f"https://api.notion.com/v1/blocks/{page_id}/children"
response = requests.patch(url, json=payload, headers=HEADERS)
if is_debug:
assert response.status_code == 200, f"{response.content}"
2-7. 実行結果
データベースに作成されたページは,以下のようになります.

利用シーンとしては,気になった論文が自分の求めてるものかを判断する場面や,精読前に内容をざっくり理解する場面が挙げられます.
まとめ
指定したキーワードに関して,arXivから最新論文の3行要約をSlackに毎日投稿し,気になったものは全文要約してNotionのデータベースに保存する機能を実装しました.
コード全文は以下のリポジトリで公開しているため,適宜活用していただけますと幸いです.
https://github.com/yuta0821/paper_bookshelf
また質問や改善提案などがありましたら,是非IssueやPRを作成してください.
日々の論文サーベイにおいて,少しでもお役に立てれば嬉しいです.
長くなってしまいましたが,最後まで読んでいただきありがとうございました!
参考文献
以下の文献を参考にさせていただきました.ありがとうございました.
- 最新の論文をChatGPTで要約して毎朝Slackに共有してくれるbotを作る!
- arXiv API User's Manual - arXiv info
- Category Taxonomy
- ChatGPTと協創!arXiv論文要約ツールを作ってみた - Qiita
- Slack API を使用してメッセージを投稿する
- サーバーレス + Pythonで定期的にスクレイピングを行う方法 - ガンマソフト
- ElixirでSlack botを作って楽しむ (2021/12/09) - Qiita
- Slack ソケットモードの最も簡単な始め方 - Qiita
- AI-LaBuddy/slack-qa at main · kenoharada/AI-LaBuddy
- OpenAIのGPT-3.5系APIを使って論文を自動で要約する - Qiita
- Notion API を使用してデータベースを操作する