個人メモです。
CouldWatchの用途
AWSで使用しているサービスの稼働状況をモニタリングできるシステム。
閾値を設定しておけばアラート通知もできる。
表示するデータは折れ線や円グラフなど好きな形式を選択できる。
▼CloudWatchダッシュボード画面の例
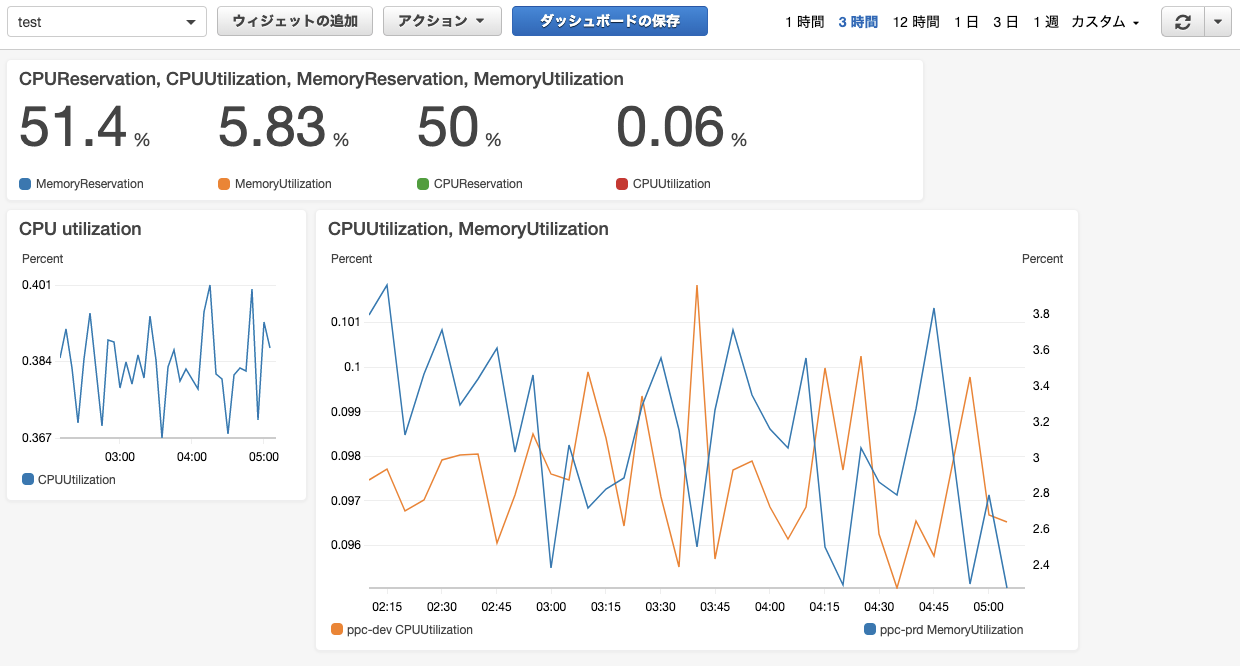
上記のようなグラフや数値などの好きなウィジェットを好きな場所に表示できる。
各ウィジェットの表示サイズの変更はドラッグで簡単にできる。
## CloudWatchと連携できるサービス一覧 EC2、ECS、S3などの多くのサービスのデータを集計できる。

## CloudWatchの関連用語
- Namespaces(名前空間)
- Widget(ウィジェット)
- Dimensions(ディメンション)
- Metrics(メトリクス)
- Statics(統計)
名前空間とは?(Namespaces)
ここでの名前空間は、EC2, ECSなどのAWSのサービス名を指す。
ウィジェットとは?(widget)
データの表示方法は折れ線、面積、数値、棒グラフなどが選択できる。これらをウィジェットとして選択する。

グラフの自由度はとても高い。例えば折れ線の場合、2軸表示、凡例の位置、グラフの最大値・最少値の設定、注釈の表示などができる。
ディメンションとは?(Dimensions)
ここでのディメンションは集計方法の切り分け方のこと。
例えば、EC2のメモリ使用率をグラフ化したい場合、各インスタンス毎のメモリ使用率を表示するか、EC2全体のメモリ使用率を出すかなど。

Auto Scalingグループ別や、イメージID別、すべてのインスタンスにわたり、などがディメンションとなる。
メトリクスとは?
集計するデータのこと。CPUの使用率、メモリの使用率、エラー発生数などのこと。
▼メトリクスの一例

メトリクス選択の流れ
ダッシュボードを選択する。今回はtestを選択

↓ ウィジェットの追加を選択

↓ 線を選択

↓ メトリクスを選択(これでメトリクスを使ってグラフ作成ができる)
↓ 名前空間はEC2を選択

↓ ディメンションはすべてのインスタンスにわたりを選択
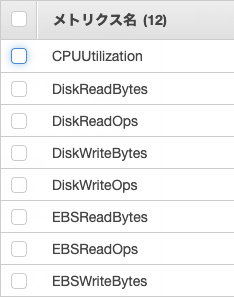
↓ メトリクスはCPU Utilization(CPU使用率)を選択
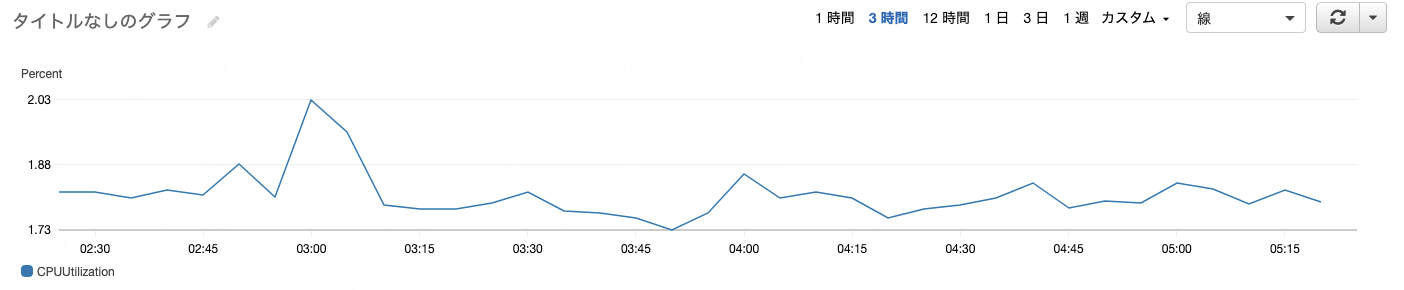
以上で指定したメトリクスでウィジェットの作成が完了。
## 周期とは?(Period) データの集計周期。例えば1時間、1日、1ヶ月(30日)単位とか。

## 統計とは?(Statistic) データの集計方法。例えば平均とか、最大値とか。
Sum
Max
Min
Average
Sample count
Percentile
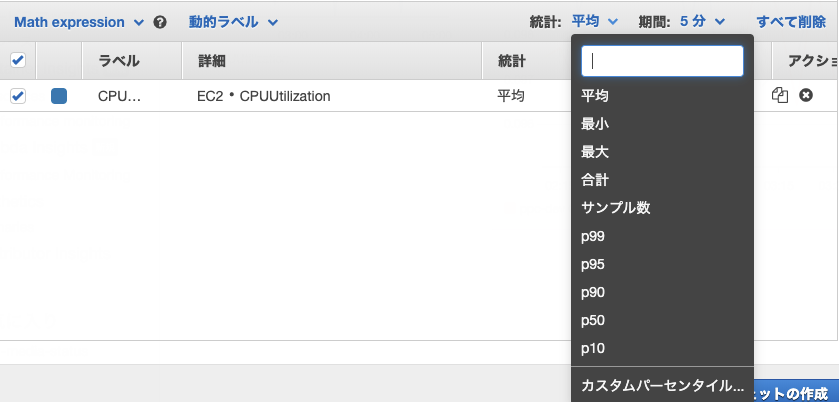
Percentileとは?
すべてのデータを小さい方から大きい方に並べ替え、全体を100%とした場合に、指定した%のデータ。
p10や、p85といった形で表す。(p10 = 10%)
例えば、指定期間でCPU使用率が100個のデータがあった場合に、p10だと、使用量の低い方から10%目に当たるデータとなる。
p50ならパーセンタイルでした場合の中央部のデータとなる。(平均値Averageの値とは異なる)
Percentileを使うメリット
Average(平均)だと、突発的な異常値も平均化されてしまい、実像が見えにくい場合がある。
%を使えば、より実際に近い値が得られる。
## アラーム ### アラームの状態 アラームの状態は3つある。
- OK
- NG
- Insufficient data(データ量不十分)
アラームの設定
アラームの設定には主に3つの指標がある。
- 期間(Period)
- 最新データを基点として期間(Evaluation Period)
- 設定した閾値を超えたデータ数(Datapoints to Alarm)
実際の設定例
例えば、以下のように設定した場合、直近の3つのデータすべてが閾値を超えたときにアラームが発動する。
・最新データを基点として期間(Evaluation Period)= 3
・設定した閾値を超えたデータ数(Datapoints to Alarm)= 3
データ欠損した場合
データが欠損している場合(送信されてこない場合)の対応以下から選択することができる。
- Good(not breaching): 欠損データは閾値内とする。
- Bad (breaching): 欠損データは閾値外とする。
- Ignore: 直近のアラーム状態をいじ
- Missing: 過去の期間に遡る
breachingとは違反状態。ここでは閾値を超えた状態のこと。
設定例としては、CPU使用率のようにクリティカルでなければGoodとし、エラーのように異常を即座に検知する必要があるものはBadと設定する。