はじめに
本記事はAWS、java(ほぼ)初心者がLambda@javaでS3オブジェクトをEC2のDB(SQL Server)にINSERTするまでにやったことの備忘録となります。
初投稿三部作(+α)の最終盤です。
ここはこうしたほうがいい、などご指摘あればお願いします!!
1 : AWS編
2 : Java編[前編]
3 : Java編[後編]
3.5: Java編[続] <-- 本編
Lambdaのロールとネットワーク設定
IAMロールの設定
ソースを最終的な段階に編集する前に、Lambdaの設定を行いましょう。
LambdaがVPC内にあるEC2やRDSなどの他のサービスにアクセスする場合、Lambdaで実行するファンクションそのものもVPCの中に所属させる必要があります。
そのためにIAMロールの設定などを行う必要がありますが、完了すると、Lambdaがトリガーとなるイベントを検知した際にVPC内へのアクセスを可能とするロールにより、ENI(Elastic Network Interface)が自動で割り振られるため、LambdaファンクションがVPC内のリソースへのアクセスを行うことができるようになります。
(知れば知るほど、AWSすげえ・・・ってなる)
注意) ソースのバージョンは mssql-jdbc-7.0.0.jre8.jar にする。
Lambdaのマネジメントコンソールから、作成済みの lambda_s3_exec_role を選択肢、ポリシーを追加します。
VPC内のリソースにアクセスするためのポリシー、「AWSLambdaVPCAccessExecutionRole」を追加しましょう。
先ほどのCloudWatchLogsへのアクセス権限もアタッチされて入れば、準備は完了です。
ネットワーク設定
Lambdaコンソールを開き、実行環境をJava8にして新規に関数を作成します。
関数の詳細ページを開き、[実行ロール]をlambda_s3_exec_roleにしましょう。

続いて、[ネットワーク]ではAWS編で作成済みの"test_vpc"を選択(正確には、EC2やRDSなど、「アクションの対象となるリソースが所属するVPC」を選択)します。*1
これにより、LambdaファンクションがVPCに所属し、ENIが発行されるようになります。
合わせて、サブネット、セキュリティグループも適切なものを選択しましょう。

ネットワーク設定まで完了したら、ファンクションの設定を保存しておきましょう。
注意
ここで一つ、注意しなければならない部分があります。
VPC内のリソース(EC2, RDSなど)にアクセスするため、前回までの流れでLambdaファンクションをVPCに登録する必要がありました。
しかし、LambdaファンクションがVPC内のリソースとなると、今度はVPC外部のサービス(S3,Kinesisなど)にアクセスすることができなくなります。
詳細は以下の記事を参照してください。
VPC内のLambdaから外部サービスにアクセスする方法
これを回避するための手段に、
- NATゲートウェイの作成
- エンドポイントの作成
がありますが、今回は簡単なので後者で設定を進めていきたいと思います。
エンドポイントの作成
VPCマネジメントコンソールのナビゲーションバーから"エンドポイント"を選択し、[エンドポイントの作成]をクリックします。
今回はS3以外へのアクセスは不要なので、以下のような状態になります。

次に、VPCの選択を行います。
LambdaファンクションやEC2インスタンスが所属するVPCを選択すると、ルートテーブルを選択することができます。
ルートテーブルが複数ある場合は、適切な物を選択しましょう。

ここまで来ると概ねの設定は完了です。
現在までに加えた変更をまとめたAWSの構成図は以下のようになります。
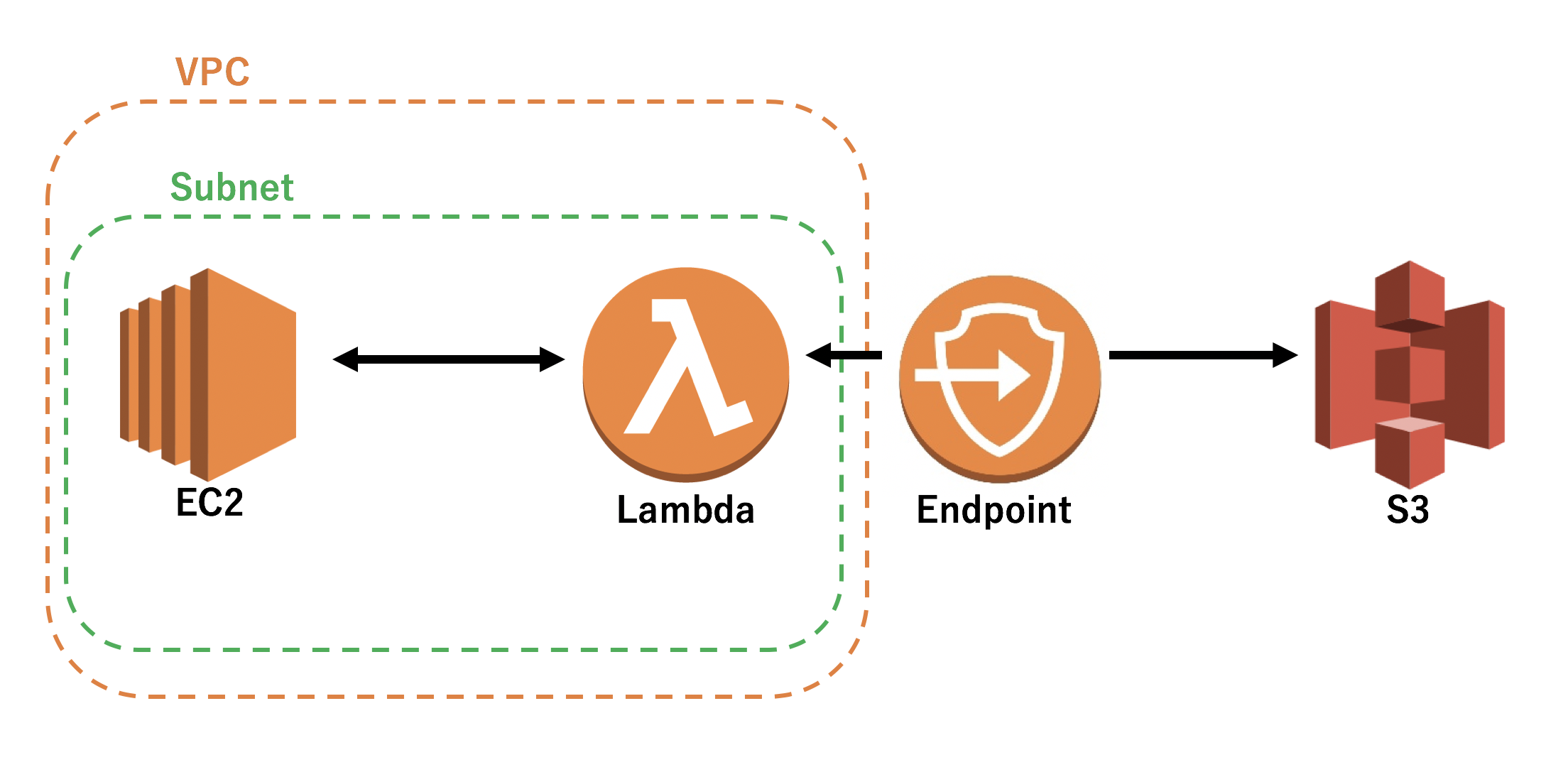 1. EC2はVPCに所属しており、一つのサブネット内にあります。EIPも割り当て済み。
2. LambdaはEC2と同じサブネット内に所属しています。
3. VPC内のLambdaとVPC外のS3での通信を成立させるために、Endpointを使用しています。
4. Endpointは、EC2及びLambdaが所属するサブネットのルートテーブルに設定してあります。
1. EC2はVPCに所属しており、一つのサブネット内にあります。EIPも割り当て済み。
2. LambdaはEC2と同じサブネット内に所属しています。
3. VPC内のLambdaとVPC外のS3での通信を成立させるために、Endpointを使用しています。
4. Endpointは、EC2及びLambdaが所属するサブネットのルートテーブルに設定してあります。
ソースの編集
それでは、改めて「CSVファイルのS3へのアップロードをトリガーに、Lambdaファンクションを実行し、該当のファイルを読み込める」ことを確認してみます。
package lambdaTest.S3toLambda;
/* import省略 */
public class DetectS3Event implements RequestHandler<S3Event, Object>
{
LambdaLogger lambdaLogger = null;
public AmazonS3 createS3Client() throws Exception
{
AWSCredentials credentials = new BasicAWSCredentials("<accessKey>","<secretKey>");
AmazonS3 client = AmazonS3ClientBuilder.standard()
.withCredentials(new AWSStaticCredentialsProvider(credentials))
.build();
return client;
}
@Override
public Context handleRequest(S3Event event, Context context) {
context.getLogger().log("Input: " + event);
lambdaLogger = context.getLogger();
// ===== get event information (S3 Put) =====
S3EventNotificationRecord record = event.getRecords().get(0);
String bucketName = record.getS3().getBucket().getName(); // s3 bucket name
String key = record.getS3().getObject().getKey(); // s3 object key
lambdaLogger.log("bucketName = " + bucketName);
lambdaLogger.log("object key = " + key);
try {
AmazonS3 client = createS3Client();
// Get target object of event
S3Object object = client.getObject(new GetObjectRequest(bucketName, key));
lambdaLogger.log("S3 client = " + client.toString());
BufferedInputStream bis = new BufferedInputStream(object.getObjectContent());
BufferedReader br = new BufferedReader(new InputStreamReader(bis));
String line = "";
// Output contents of object line by line
while((line = br.readLine()) != null) {
lambdaLogger.log(line);
}
} catch (IOException e) {
lambdaLogger.log("IOException error message : " + e.getErrorMessage());
} catch (AmazonServiceException e) {
lambdaLogger.log("AWSException error message : " + e.getErrorMessage());
} catch (Exception e) {
lambdaLogger.log("Exception error message : " + e.getMessage());
}
return null;
}
}
上記のファイルを作成したら、Mavenなどでjarパッケージ化した物をLambdaにアップロードしておきます。
S3に、以下のようなCSVをアップロードします。
1001,Dean,28
1002,Sam,25
1003,John,51
1004,Bobby,54
1005,Meg,26
CloudWatchに接続し、ログを確認してみましょう。

上記CSVが1行ずつログに出力されていることがわかります。
ではいよいよ、このCSVをEC2上のDBにINSERTしてみましょう。
DBへのINSERT
データベース及びテーブルは、前回のJava編[後編]で作成したLambdaTestDBのemployeeテーブルを使用します。
テーブルにレコードが存在しないことを確認しておきます。
1> SELECT * FROM employee;
2> go
emp_id emp_name age
----------- -------------------- -----------
(0 rows affected)
それでは、先ほどのソースを編集していきましょう。
package lambdaTest.S3toLambda;
/* import省略 */
public class DetectS3Event implements RequestHandler<S3Event, Object>
{
LambdaLogger lambdaLogger = null;
Connection mssqlCon = null;
public AmazonS3 createS3Client() throws Exception
{
AWSCredentials credentials = new BasicAWSCredentials(
"<accessKey>",
"<secretKey>");
AmazonS3 client = AmazonS3ClientBuilder.standard()
.withCredentials(new AWSStaticCredentialsProvider(credentials))
.build();
return client;
}
@Override
public Context handleRequest(S3Event event, Context context) {
context.getLogger().log("Input: " + event);
lambdaLogger = context.getLogger();
// ===== get event information (S3 Put) =====
S3EventNotificationRecord record = event.getRecords().get(0);
String bucketName = record.getS3().getBucket().getName(); // s3 bucket name
String key = record.getS3().getObject().getKey(); // s3 object key
lambdaLogger.log("bucketName = " + bucketName);
lambdaLogger.log("object key = " + key);
try {
AmazonS3 client = createS3Client();
S3Object object = client.getObject(new GetObjectRequest(bucketName, key));
lambdaLogger.log("S3 client = " + client.toString());
BufferedInputStream bis = new BufferedInputStream(object.getObjectContent());
BufferedReader br = new BufferedReader(new InputStreamReader(bis));
ResourceBundle sqlServerResource = ResourceBundle.getBundle("sqlServer");
DatabaseInfo sqlServerInfo = new DatabaseInfo(sqlServerResource.getString("driver"),
sqlServerResource.getString("url"),
sqlServerResource.getString("user"),
sqlServerResource.getString("pass"));
/* ======== SQL Server connection ======== */
lambdaLogger.log("SQL Server Session creating...");
SqlServer sqlServer = new SqlServer();
mssqlCon = sqlServer.openConnection(sqlServerInfo);
lambdaLogger.log("SUCCESS : SQL Server session created !!");
String line = "";
Statement insertStmt = mssqlCon.createStatement();
while((line = br.readLine()) != null) {
String[] values = line.split(",");
String insertRecord = "INSERT INTO employee VALUES("
+ values[0] + ", '"
+ values[1] + "', "
+ values[2] + ");";
insertStmt.executeUpdate(insertRecord);
}
if (insertStmt != null) insertStmt.close();
if (mssqlCon != null) sqlServer.closeConnection(mssqlCon);
if (br != null) br.close();
} catch (IOException e) {
e.printStackTrace();
} catch (AmazonServiceException e) {
lambdaLogger.log("Error message : " + e.getErrorMessage());
} catch (Exception e) {
lambdaLogger.log("Exception error message : " + e.getMessage());
}
return null;
}
}
while文では1行ずつ読み込んだCSVをカンマ区切りで配列にし、それぞれをレコードの各列の値としてINSERTします。
DBへ接続するためのコネクションが必要となるので、以下のファイルを新たに作成しましょう。
package lambdaTest.db;
/* import省略 */
public class SqlServer {
public SqlServer() {
super();
}
public Connection openConnection(DatabaseInfo dbInfo)
{
Connection con = null;
try {
Class.forName(dbInfo.getDriver());
con = DriverManager.getConnection(dbInfo.getUrl(), dbInfo.getDbUser(), dbInfo.getDbPass());
} catch (SQLException | ClassNotFoundException e) {
System.out.println("anything Exception : " + e);
}
return con;
}
public void closeConnection(Connection con) {
try {
con.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
このクラスへDBへのコネクション管理を委譲します。
接続用URL、ユーザ名、パスワードなど接続に必要な各パラメータは、ハードコーディングでも問題ありませんが
再利用性を重視してpropertiesファイルとして外に出します。
driver=com.microsoft.sqlserver.jdbc.SQLServerDriver
url=jdbc:sqlserver://<EC2-privateIP>:<portNo>;databaseName=<databaseName>
user=<userName>
pass=<password>
また、propertiesファイルを紐づけるためのクラスが必要になるため、下記のクラスも合わせて作成しましょう。
package lambdaTest.S3toLambda;
final public class DatabaseInfo {
String driver;
String url;
String dbUser;
String dbPass;
public String getDriver() {
return driver;
}
public String getUrl() {
return url;
}
public String getDbUser() {
return dbUser;
}
public String getDbPass() {
return dbPass;
}
public DatabaseInfo(String driver, String url, String dbUser, String dbPass) {
this.driver = driver;
this.url = url;
this.dbUser = dbUser;
this.dbPass = dbPass;
}
}
最後に、外に出したpropertiesファイルをMavenで正しく読み込ませるために、pom.xmlに数行追記します。
ここでは、追記対象のbuildセクションのみ抜粋し、追記行には★マークをつけています。
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.3</version>
<configuration>
<encoding>UTF-8</encoding>
<createDependencyReducedPom>false</createDependencyReducedPom>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<archive>
<manifest>
<mainClass>com.gmail.greencoffeemaker.MainApp</mainClass>
<addClasspath>true</addClasspath>
</manifest>
<manifestEntries>
<Class-Path>./src/resources/</Class-Path>
</manifestEntries>
</archive>
</configuration>
<executions>
<execution>
<phase>package</phase>
<!-- 追記部分 -->
<configuration>
<target>
<!-- コピー: /src/main/resources => /target/resources -->
<mkdir dir="${project.build.directory}/resources" />
<copy todir="${project.build.directory}/resources">
<fileset dir="${project.basedir}/src/main/resources" />
</copy>
</target>
</configuration>
<!-- ここまで -->
<goals>
<goal>shade</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
これで編集は完了です。ビルド後、jarをLambdaにアップロードして、emp_values.csvを改めてS3に置いてみます。
EC2上のSQL Server に接続して表をみてみると。。。
1> SELECT * FROM employee;
2> go
emp_id emp_name age
----------- -------------------- -----------
1001 Dean 28
1002 Sam 25
1003 John 51
1004 Bobby 54
1005 Meg 26
(5 rows affected)
できました!!!
まとめ
この記事を書くにあたって、Javaに触れたのは数年振り&AWSは初めて
という予習ほぼゼロのボロボロ状態でしたが、なんとかやりたいことが実現できてホッとしました。
マニュアル読んだり、ナレッジ探したり、諸々含めて1日辺りの作業時間は3h未満、期間にしておよそ2週間というくらいの作業感でした。
途中つまずいたエラーを回避する作業が大半を占めていた気がします。
もっと作業効率上げていきたい。切実。