はじめに
「このプロジェクト、どこから読めばいいんだろう」
自分が良く知らないコードを調査する際、問題は「どこに何があるか分からない」という点では無いだろうか、また、整ったプロジェクトではIDEで調査、ドキュメントで全体把握できるが、そうもいかないときが有る。
IDEを自由に導入できない環境も有る。
そういった時、ある程度、コマンドを使いこなせると、調査がはかどると思う。
本記事では、Pythonプロジェクトを題材に、ターミナルだけでコードを追いかける手順をまとめました
前提環境
- Linux / macOS(bashまたはzsh)
- 対象: Pythonプロジェクト(他言語でも基本は同じ)
- 使うコマンド:
grep,sed,head,tail,find,awk,wc
1: プロジェクトの全体像を掴む
まず、何がどこにあるのかを把握する。
これをやらずにいきなりgrepしても、出力の意味が分からない。
find . の . は「カレントディレクトリを起点に」という意味で、子、孫、ひ孫…と深さの制限なく探索する。
# ディレクトリ構造を俯瞰する(不要ディレクトリは除外)
find . -type f -name "*.py" -not -path "./.venv/*" -not -path "./__pycache__/*" | sort
ファイル数が多い場合は、ディレクトリ単位で把握するほうが早いかもしれない。
# ディレクトリだけ表示(深さ2まで)
find . -maxdepth 2 -type d -not -path "./.venv/*" | sort
treeコマンドが入っていれば、もっと見やすい。
-
-L 2と有るのは、表示する深さの上限 -
-I '__pycache__|.venv|node_modules|.git': 除外するディレクトリ/ファイルのパターンを指定する。ignoreのIと覚えると良いかと思う
tree -L 2 -I '__pycache__|.venv|node_modules|.git'
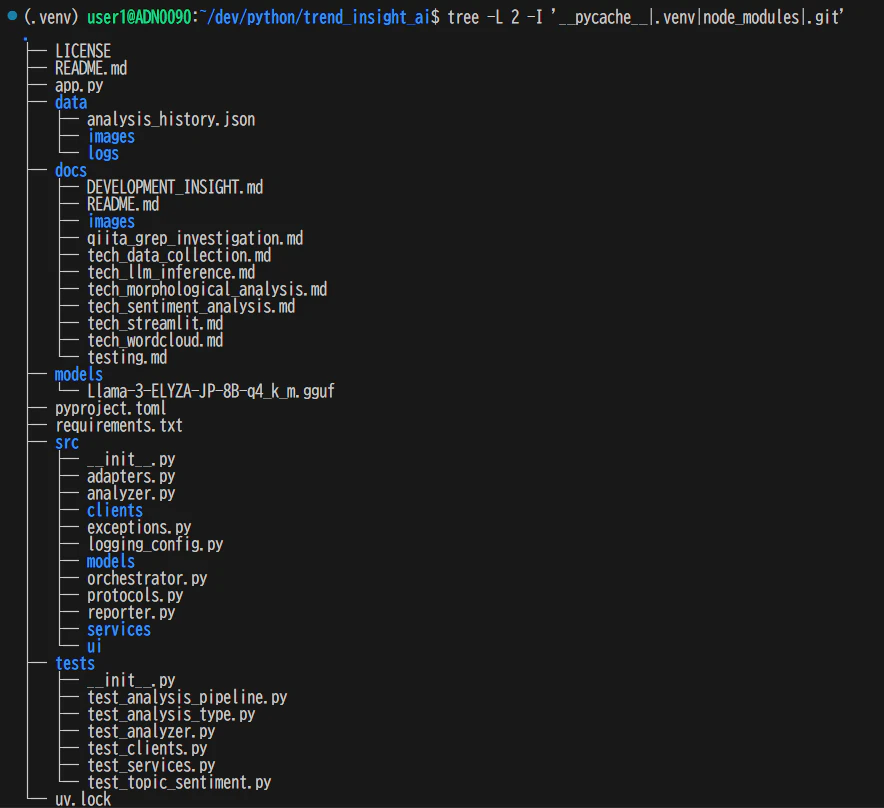
ファイルの規模感も掴んでおくと、どこが「重い」モジュールか分かる。
# 各Pythonファイルの行数を昇順で表示
find . -name "*.py" -not -path "./.venv/*" | xargs wc -l | sort -n
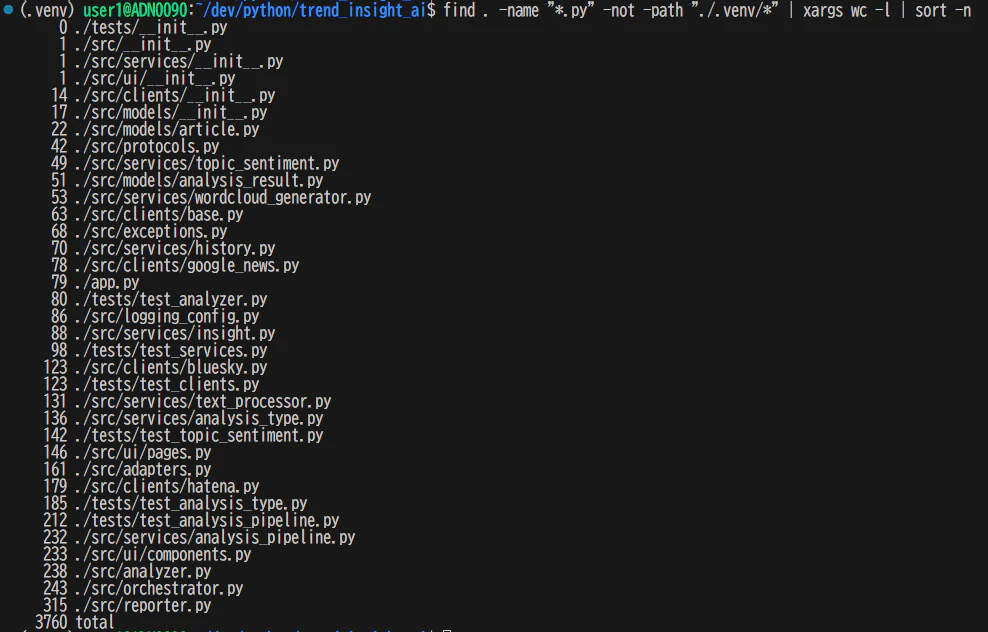
行数が多いファイルはロジックの中心であることが多い。逆に短いファイルはモデル定義やユーティリティだったりする。
2: キーワードで「場所」を特定する
プロジェクトの構造が分かったら、次は「知りたいこと」をキーワードにして検索する。これがコード調査の核心である。
基本のgrep
# プロジェクト全体から "topic_sentiment" を含む行を検索
grep -rn "topic_sentiment" --include="*.py"
-rは再帰検索、-nは行番号表示。--includeで対象ファイルを絞る。これだけで「定義場所」「import文」「呼び出し箇所」等を確認できる
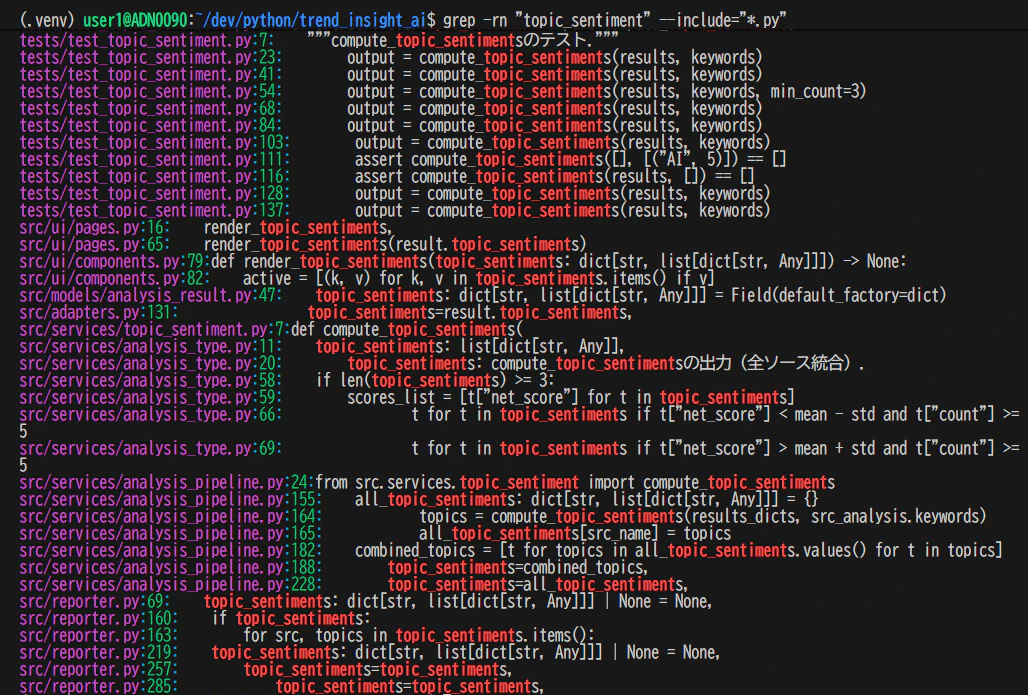
出力を読み解く
上記コマンドの出力がこうなったとする。
src/services/topic_sentiment.py:7:def compute_topic_sentiments(
src/services/analysis_pipeline.py:24:from src.services.topic_sentiment import compute_topic_sentiments
src/services/analysis_pipeline.py:164: topics = compute_topic_sentiments(results_dicts, src_analysis.keywords)
3行の出力から、以下が読み取れる。
- 定義は
src/services/topic_sentiment.pyの7行目 -
analysis_pipeline.pyがimportして164行目で呼んでいる - つまりパイプラインの一部として使われている
IDEを開かなくても、この関数の「立ち位置」が分かった。
grepの実用オプション
状況に応じてオプションを使い分ける。
ファイル名だけ欲しい(どのファイルに書いてあるか一覧)場合
-l : マッチしたファイルのパスだけを表示(行内容は出さない)
grep -rl "DataCollectorProtocol" --include="*.py"
ある程度、検索結果の目途が付いておりリスト化したい場合に使用する

大文字小文字を無視して検索したい場合
-i : 大文字小文字を区別しない(Error, ERROR, error すべてヒット)
grep -rni "error" --include="*.py"
大文字小文字がはっきりしない場合は併せて出力してくれるので便利
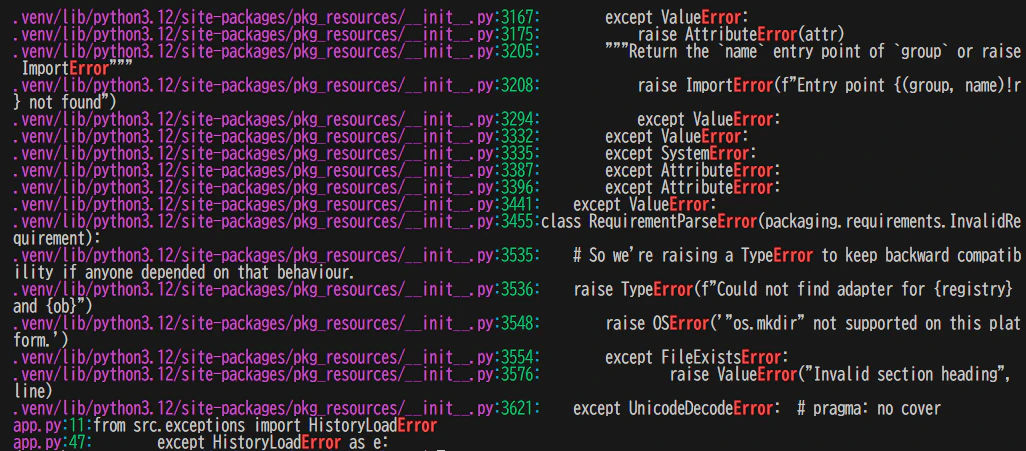
前後3行も表示(関数の文脈を掴む)したい場合
-C 3 : マッチ行の前後3行(Context)も合わせて表示する
grep -rn -C 3 "compute_divergences" --include="*.py"
検索にヒットした行だけでなく、周辺の行も出力してくれるので、文脈を把握するのに便利
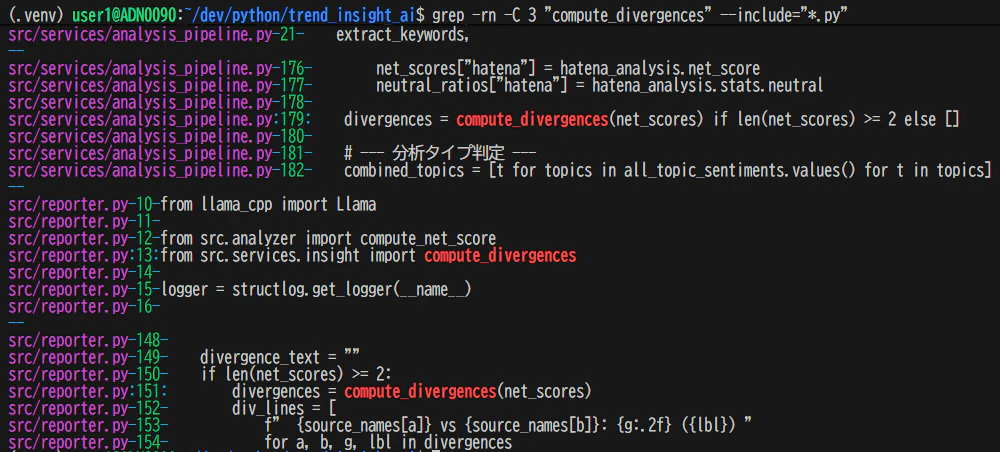
正規表現で関数定義だけ抽出したい場合
\| : OR条件(「^def 」または「^class 」で始まる行にマッチ)
grep -rn "^def \|^class " --include="*.py" src/services/
このコマンドは特に便利で、ファイルを開かずに「このモジュールにはどんな関数/クラスがあるか」が一覧できる。
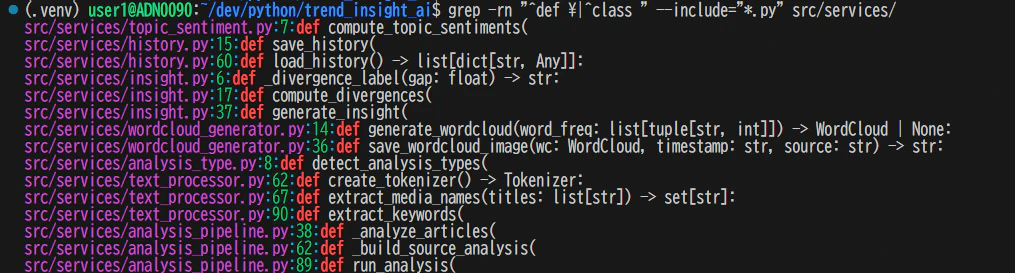
3: 見つけた場所の「中身」を読む
grepで場所が分かったら、次はその周辺を読む。ファイル全体を開く必要はない。
sedで範囲指定して読む
# 214行目から243行目まで表示
sed -n '214,243p' src/analyzer.py
範囲指定して出力してくれるので、ファイルを開く必要が無い。
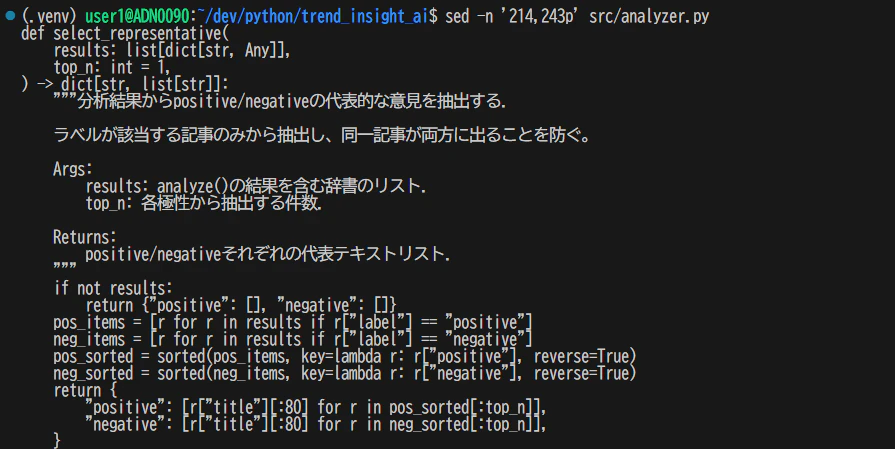
関数の開始行が分かっていれば、そこから30〜50行読めば大抵の関数は全体が見える。
headとtailで端を読む
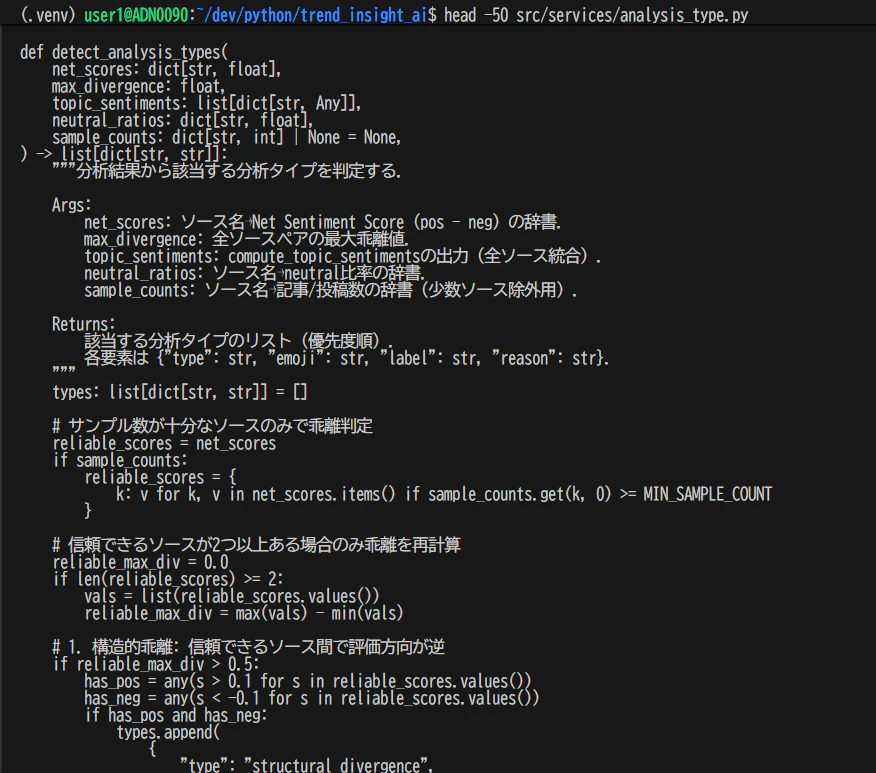
# ファイルの先頭50行(import文やモジュールdocstringを確認)
head -50 src/services/analysis_type.py
Pythonファイルの先頭にはimport文が集まっているので、headで読むだけで「このモジュールが何に依存しているか」が分かる。
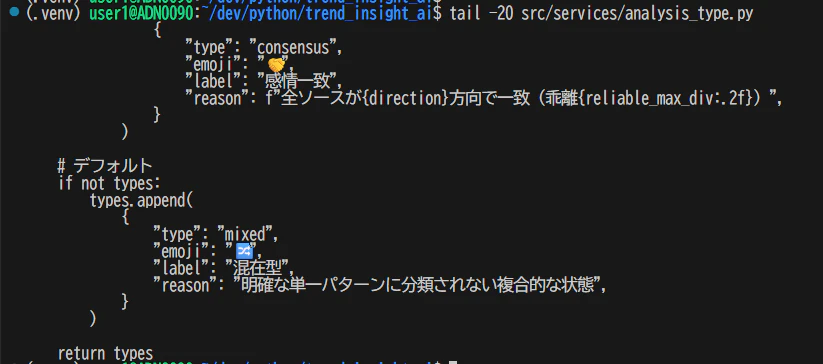
# ファイルの末尾20行
tail -20 src/services/analysis_type.py
プログラムコードの読み込みではあまり使用しないかもしれないが、ログファイルで直近のログを確認する際に良く使用する
awkで特定パターンの行だけ抜く
# 関数定義行だけ抽出(行番号付き)
awk '/^def |^class /{print NR": "$0}' src/services/analysis_type.py
出力例:
8: def detect_analysis_types(
このファイルには公開関数が1つしかないことが一瞬で分かる。シンプルなモジュールだと判断できる。
4: 呼び出し関係を追う
関数の中身が分かったら、次は「誰がこれを呼んでいるか」「これは何を呼んでいるか」を追う。これがコードリーディングの本質的な作業です。
呼び出し元を探す
# select_representativeを使っている箇所(定義行を除外)
grep -rn "select_representative" --include="*.py" | grep -v "^.*:def "

grep -vでパターンを除外できる。定義行自体は既に知っているので、呼び出し側だけ見たい時に使う。
importの依存関係を追う
# このファイルが何をimportしているか
grep "^from\|^import" src/services/analysis_pipeline.py
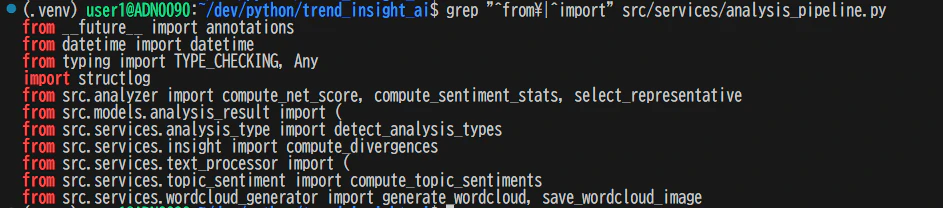
# 逆に、このモジュールをimportしているファイルは?
grep -rl "from src.services.topic_sentiment" --include="*.py"

この双方向の追跡で、モジュール間の依存グラフが頭の中に組み上がっていく。
5: 実践
ここまでのテクニックを組み合わせて、実践していく
例として分析プロジェクトの中で「分析タイプ判定」についての機能を追いかけてみる。
5-1. キーワードで当たりをつける
「分析タイプ」に関係しそうなキーワードで検索する。
grep -rn "分析タイプ" --include="*.py"
出力:
tests/test_analysis_type.py:1:"""分析タイプ判定のテスト."""
tests/test_analysis_pipeline.py:89: """分析タイプが1つ以上割り当てられる."""
src/ui/pages.py:67: # 分析タイプ
src/ui/pages.py:68: st.subheader("📋 分析タイプ")
src/ui/components.py:103: """分析タイプを表示する."""
src/services/analysis_type.py:1:"""分析タイプ判定サービス - ルールベースのパターン分類."""
src/services/analysis_type.py:15: """分析結果から該当する分析タイプを判定する.
src/services/analysis_type.py:25: 該当する分析タイプのリスト(優先度順).
src/services/analysis_pipeline.py:181: # 分析タイプ判定
src/reporter.py:172: # 分析タイプ情報
src/reporter.py:176: type_text = "\n■ 分析タイプ\n " + "\n ".join(type_labels)
これで全体像が見えた。本体は analysis_type.py、呼び出し元は analysis_pipeline.py、テストも存在する。
5-2. 本体の構造を確認する
# 関数定義だけ抽出
grep -n "^def \|^class " src/services/analysis_type.py
出力:
8:def detect_analysis_types(
公開関数は1つだけ。責務が明確なモジュールだと分かる。
5-3. 関数のシグネチャと引数を読む
sed -n '8,30p' src/services/analysis_type.py
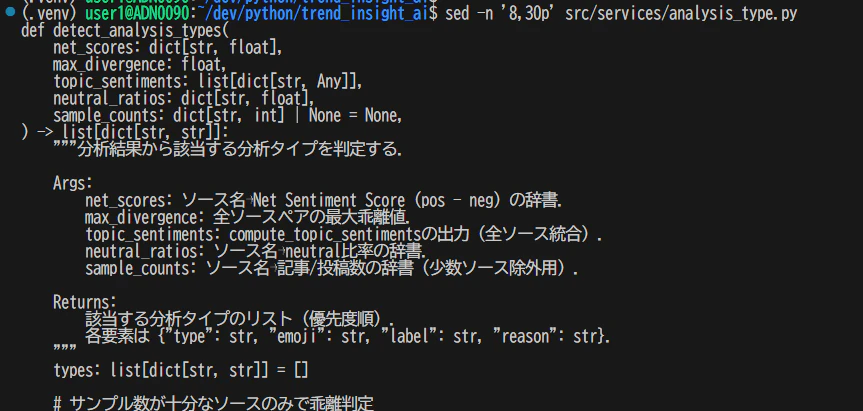
これで引数の型と意味(docstring)が読める。何を入力に取って何を返すのか、ファイルを開かずに把握できる。
5-4. 関数内の処理ロジックを読み解く
# コメント行だけ抽出して判定の流れを把握
grep -n "^ # " src/services/analysis_type.py

コメントだけ抜き出すと、以下の処理が推測できる。コードを1行も読まずに設計意図が分かった。
1. データのフィルタリング
* サンプル数が十分にあるソースのみを対象にする。
* 信頼できるソースが2つ以上ある場合に対象を絞る。
2. 乖離・一致パターンの判定基準(ロジック)
* 構造的乖離: ソース間で評価の方向性が真逆である状態。
* トピック集中型: 相対的な評価に基づく特定の傾向。
* 中立支配: 信頼できるソースの多くが「中立(neutral)」を示している状態。
* 感情一致: ソース間の方向性が同じで、ズレ(乖離)が小さい状態。
3. 上記の条件に当てはまらない場合
* デフォルト処理。
5-5. 呼び出し元での使い方を確認する
「5-1. キーワードで当たりをつける」で以下プログラムファイルにて「分析タイプ判定」処理を呼び出しているのが分かっている
src/services/analysis_pipeline.py:181: # 分析タイプ判定
そこで、呼び出し方を調べてみる
上記で181行目で呼び出しているので、前後を若干開けて検索。ここでは大雑把に175行目から200行目とする
sed -n '175,200p' src/services/analysis_pipeline.py
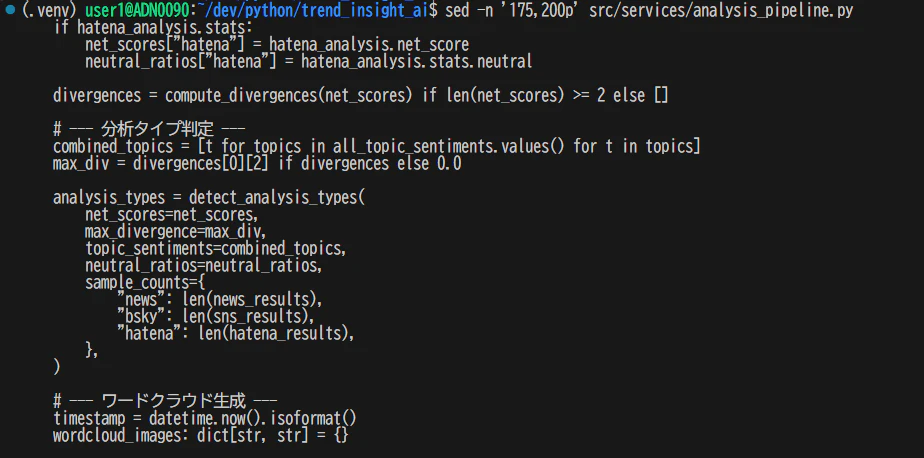
どんな引数を渡しているかが分かれば、この関数が何のデータを受け取って動いているかが明確になる。
応用: よく使う調査パターン集
Protocolとその実装クラスの調査
ちなみにProtocolとその実装クラスと言うのは、Javaでいう所のinterfaceとimplementsと大雑把に解釈で良いかと思います
# Protocol定義を探す。「.venv」、「__pycache__」ディレクトリを除外
grep -rn "class.*Protocol" --include="*.py" --exclude-dir=".venv" --exclude-dir="__pycache__"
出力結果
src/protocols.py:9:class SentimentAnalyzerProtocol(Protocol):
src/protocols.py:17:class DataCollectorProtocol(Protocol):
src/protocols.py:31:class ReportGeneratorProtocol(Protocol):
src/protocols.py:37:class HistoryRepositoryProtocol(Protocol):
# 上記検索結果のDataCollectorProtocolを型ヒントで使っているファイル
grep -rn "DataCollectorProtocol" --include="*.py" | grep -v "class.*Protocol"
出力結果
src/orchestrator.py:20: DataCollectorProtocol,
src/orchestrator.py:52: collector: DataCollectorProtocol,
例外の発生箇所を追う
# カスタム例外がどこでraiseされているか
grep -rn "raise.*Error" --include="*.py" src/ | grep -v ".venv"
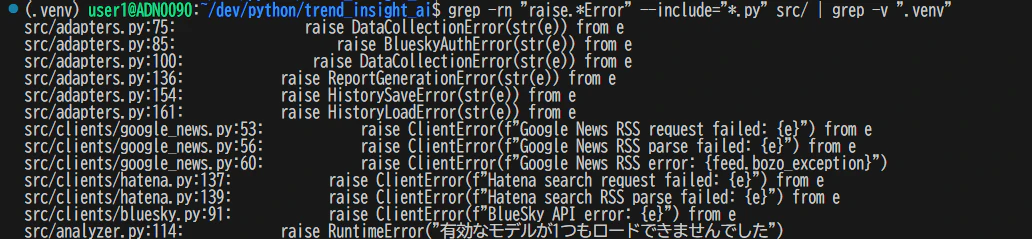
TODOやFIXMEを洗い出す
grep -rn "TODO\|FIXME\|HACK\|XXX" --include="*.py" --exclude-dir=".venv" --exclude-dir="__pycache__"
特定のデコレータが付いた関数を探す
Pythonでいうデコレータと言っているのは、Javaで言う所のアノテーション(@Override, @Testなど)の様な物です
# pytestのslowマーカーが付いたテスト
grep -B 1 "def test_" tests/ -rn | grep "slow"
-B 1で1行前も表示するので、デコレータとセットで確認できる。
まとめ
コマンドベースでのソースコード調査のルーチンは以下
- grepで場所を特定する
キーワードから「どのファイルの何行目か」を見つける - sed/headで中身を読む
見つけた場所の周辺を、必要な分だけ読む - grepで関係を追う
呼び出し元・呼び出し先・import関係を辿る
この3ステップを繰り返すだけで、未知のコードベースでも構造が見えてくる。IDEの支援がない環境でもある程度まで調査できるのが、良い
最初は grep -rn と sed -n の2つだけ覚えておけば良いかと思う。
慣れてきたら awk や grep -v による絞り込みを加えていけば、調査の精度が上がっていくのではないかと思う
ここでは、コマンドベースでの調査方法を上げましたが、IDEを十分に使える環境であれば、参考程度で良いかと思います
補足: モダンな代替ツール(ripgrep / fd)
本記事では「どの環境にもあるコマンド」を前提としたが、ツールのインストールが許される環境であれば ripgrep (rg) と fd を使うことで同じ作業がより快適になる。
何が違うのか
| 従来 | モダン | 主な改善点 |
|---|---|---|
grep -rn |
rg |
.gitignoreを自動で読込み、.venv等の除外指定が不要。大規模リポジトリで高速化が可能となる |
find |
fd |
同様に.gitignoreを自動で除外してくれる。正規表現がデフォルトで使え、出力が見やすい |
どちらも「やっていること」は本記事の grep / find と同じで、検索の考え方やステップは変わらない。
インストール
# Ubuntu / Debian
sudo apt install ripgrep fd-find
# ※ fd-find は "fdfind" コマンドとしてインストールされる場合がある
# macOS (Homebrew)
brew install ripgrep fd
対応表: 本記事のコマンドをrg / fdで書き直す
プロジェクト全体像の把握(ステップ1相当)
# find版: 除外指定が冗長だった
find . -type f -name "*.py" -not -path "./.venv/*" -not -path "./__pycache__/*" | sort
# fd版: .gitignoreに書かれたパスは自動除外される
fd -e py
キーワード検索(ステップ2相当)
# grep版: --include と --exclude-dir を毎回指定しなければいけなかった
grep -rn "topic_sentiment" --include="*.py" --exclude-dir=".venv" --exclude-dir="__pycache__"
# rg版: 除外指定不要、ファイルタイプは -t で指定
rg "topic_sentiment" -t py
ファイル名だけ表示
# grep版
grep -rl "DataCollectorProtocol" --include="*.py"
# rg版
rg -l "DataCollectorProtocol" -t py
前後の文脈表示
# grep版
grep -rn -C 3 "compute_divergences" --include="*.py"
# rg版
rg -C 3 "compute_divergences" -t py
関数定義だけ抽出
# grep版
grep -rn "^def \|^class " --include="*.py" src/services/
# rg版: 正規表現がデフォルトで使える(エスケープ不要)
rg "^(def |class )" -t py src/services/
注意点
-
rg/fdはあくまで追加インストールが必要なツールです。本記事の趣旨はIDEや追加ツールなどいじりづらい環境下での調査がメインの話です - 基本的には、
grep/findだけで完結させたいので、まずはそちらを押さえておくのが良いかなと思います - 既に
grep/findに慣れていれば、オプションの対応関係は直感的に理解しやすいと思います。基本的コマンドを抑えてからrgを触った方が良いかと思いました