はじめに
近年、企業は「データ駆動型経営」を目指す傾向が強まっています。つまり、感覚や経験ではなく、データに基づいて意思決定するという考え方です。
そのためには、膨大なデータを効率よく集め、管理し、分析する仕組みとしてAWSのサービスで考えてみたいと思います
クラウドを使う事で、手っ取り早くデータ分析に必要なサービスを利用出来ますので
改めてのAWSのメリットは以下と考えます
- スケーラブル:必要な時に必要なだけリソースを使える
- 多様なサービス:データ収集、加工、分析、可視化まで一気通貫
- コスト最適化:使った分だけ課金される
データ分析の全体像
データ分析は大きく以下の流れです。
- データを集める(ログ、CSV、APIなど)
- データを保存する(データレイクやデータベース)
- データを加工する(ETL処理)
- データを分析する(SQL、機械学習)
- 結果を可視化する(BIツール)
用語の補足
データレイク
RDBの様に整理されたデータでは無く、ローデータの様に何でもデータファイルを置いておける場所
Amazon S3 のイメージ。オブジェクトストレージ
- 構造化データ(表形式のデータ)
- 非構造化データ(画像、ログ、動画など)
AWSでよく使うデータ分析サービス
- Amazon S3:データレイクの基盤
- Amazon Redshift:データウェアハウス(大量の構造化データを高速分析)
- Amazon Athena:S3上のデータをSQLで簡単に分析
- AWS Glue:ETL(データの抽出・変換・ロード)
- Lake Formation:データレイクのセキュリティ・権限管理
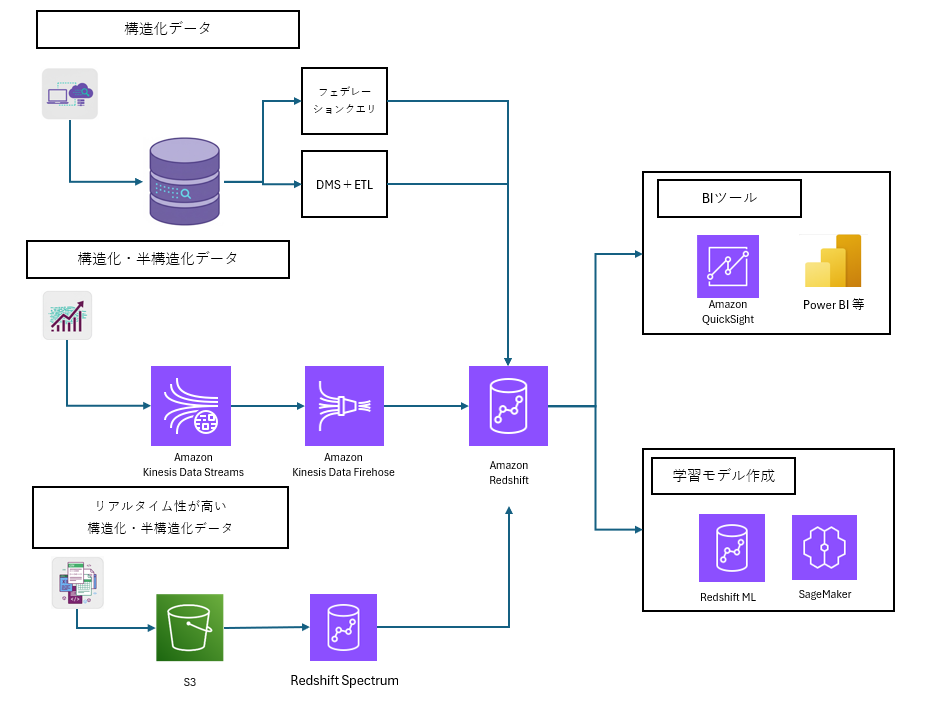
Redshiftを中心としたアーキテクチャのイメージ
まとめ
企業など(組織、社会)にて膨大なデータが生まれている。そのデータを分析する事でインサイトを求めるニーズが存在する
データ分析の流れとしては、データを集めて、保存、加工、分析、分析結果を見やすく表示する
AWSでもデータ分析サービスを提供している
まずは、「データレイク=S3」、「データウェアハウス=Redshift」と大雑把に概要を押さえたい