はじめに
カイ二乗検定では、一般に観測データの統計誤差のみを考慮しますが、理論モデルにも系統・統計誤差がある場合、それを無視した解析では正確性が損なわれる可能性があります。
例えば、X線天文学における超新星残骸の膨張や衝撃波の固有運動(proper-motion)解析では、観測データだけでなく、比較対象となる理論モデル(過去の観測データやシミュレーション)の不確かさも重要になります。
より正確な解析を行うには、こうしたモデルの統計誤差を考慮する必要があります。
本記事では、Katsuda et al. (2008) や Tanaka et al. (2020) の研究をもとに、モデル誤差を反映したカイ二乗統計量の修正方法を解説します。
さらに、ポアソン統計に従う観測データを用いたシミュレーションをPythonで実装し、カイ二乗フィッティングを用いてシフト量を推定する方法を示します。
本記事の実装コードは Google Colab からも閲覧・実行できますので、ぜひご活用ください。
なお、データには統計誤差だけでなく、系統誤差も含まれることがあります。例えば、エネルギー較正のズレやバックグラウンド補正の不備などが影響する場合、それらの誤差の評価は別途考慮する必要があります。本記事では 観測データの統計誤差とモデル誤差 に焦点を当てており、系統誤差の詳細な評価は扱いません。
標準的なカイ二乗の定義
通常、カイ二乗は以下のように定義されます。
\chi^2 = \sum_{i=1}^n \frac{(y_i - f(x_i))^2}{\sigma_i^2}
- $y_i$ : 観測データ
- $f(x_i)$ : 理論モデル
- $\sigma_i$ : 観測データの誤差
この式では、観測データの誤差 $\sigma_i$ のみを考慮しています。
モデルに誤差がある場合のカイ二乗
通常のカイ二乗フィッティングでは、観測データの誤差(測定誤差)のみを考慮します。
しかし、実際には理論モデル自体にも不確かさがある場合があり、その誤差を無視すると過剰なフィッティングや誤った誤差評価につながる可能性があります。
そこで、モデルの誤差 $\sigma_{\text{model},i}$ も考慮した修正式を導入します。
\chi^2 = \sum_{i=1}^n \frac{(y_i - f_\text{best}(x_i))^2}{\sigma_i^2 + \sigma_{\text{model},i}^2}
ここで、
- $f_\text{best}(x_i)$ : 最も適合する(最良の)理論モデルの予測値
- 観測データをもとに決定される理論的な推定値を指します。
- $\sigma_{\text{model},i}$ : 理論モデルの不確かさ
- モデルが理論的に完璧ではなく、近似や未知の要因による誤差を持つことを表します。
このように、観測誤差 $\sigma_i$ とモデル誤差 $\sigma_{\text{model},i}$ の両方を考慮することで、より現実的で正確な誤差評価が可能になります。
特に、天文学や物理学のデータ解析では、理論モデルの不確実性を考慮することで、より妥当なフィッティング結果を得ることができます。
この式は、一見複雑に見えますが、カイ二乗の基本的な考え方に基づいています。
分母の $\sigma_i^2$ は重み付けの役割 を果たし、誤差が大きいデータ点ほど影響を小さくします。同様に、$\sigma_{\text{model},i}^2$ を加えることで、理論モデルの不確実性も考慮 されます。
つまり、観測データとモデルの両方の信頼性に応じた重み付けが自然に行われる形になっています。
導出
1. 観測誤差のみを考慮したカイ二乗統計量の導出
まず、通常のカイ二乗統計量は、観測値 $y_i$ がモデル値 $f(x_i)$ に従うと仮定し、
各観測値 $y_i$ が以下のガウス分布に従うとします。
y_i \sim \mathcal{N}(f(x_i), \sigma_i^2)
このとき、各データ点の尤度関数(確率密度関数)は
L_i = \frac{1}{\sqrt{2\pi\sigma_i^2}} \exp \left(-\frac{(y_i - f(x_i))^2}{2\sigma_i^2} \right)
となります。
$n$ 個のデータについて、全体の尤度関数(同時尤度)は、独立なガウス分布の積として
L = \prod_{i=1}^n L_i = \prod_{i=1}^n \left[\frac{1}{\sqrt{2\pi\sigma_i^2}} \exp \left(-\frac{(y_i - f(x_i))^2}{2\sigma_i^2} \right)\right]
と表せます。
この尤度の対数を取ると、
\ln L = \sum_{i=1}^n \left[-\frac{1}{2} \ln (2\pi\sigma_i^2) - \frac{(y_i - f(x_i))^2}{2\sigma_i^2}\right]
第一項は定数であり、最尤推定の観点から無視できます。
すると、次の式を最大化することと等価になります。
\ln L = - \sum_{i=1}^n \frac{(y_i - f(x_i))^2}{2\sigma_i^2}
この対数尤度を最小化する形式にするために $-2$ をかけると、カイ二乗統計量の定義
\chi^2 = \sum_{i=1}^n \frac{(y_i - f(x_i))^2}{\sigma_i^2}
が導かれます。
2. モデル誤差を考慮した尤度関数
次に、モデル $f(x_i)$ も不確かさを持っていると仮定します。
ここでは、モデル誤差もガウス分布に従うと仮定します。
f(x_i) \sim \mathcal{N}(f_{\text{best}}(x_i), \sigma_{\text{model},i}^2)
つまり、理論モデルの予測値 $f(x_i)$ は、最良のフィット値 $f_{\text{best}}(x_i)$ の周りに、モデル誤差 $\sigma_{\text{model},i}$ を伴って分布すると考えます。
このとき、観測値 $y_i$ の分布は、モデル $f(x_i)$ の不確かさも含めた形で考える必要があります。
3. 観測値の合成分布の計算
観測値 $y_i$ は、以下の2つの独立な誤差を含みます。
-
観測誤差(測定装置のノイズ):
y_i \sim \mathcal{N}(f(x_i), \sigma_i^2)- これは、測定誤差によって観測値が変動することを表しています。
-
モデル誤差(理論モデルの不確かさ):
f(x_i) \sim \mathcal{N}(f_{\text{best}}(x_i), \sigma_{\text{model},i}^2)- これは、理論モデル自体の不確実性を表しています。
ここで、ガウス分布の合成の性質(再生性)を利用すると、$y_i$ の分布は次のようになります。
y_i \sim \mathcal{N}(f_{\text{best}}(x_i), \sigma_i^2 + \sigma_{\text{model},i}^2)
これは、観測値 $y_i$ は、最良のモデル $f_{\text{best}}(x_i)$ の周りに、観測誤差 $\sigma_i$ とモデル誤差 $\sigma_{\text{model},i}$ の両方を考慮した分散を持つガウス分布に従うことを示しています。
4. モデルの誤差を含んだ尤度関数の導出
モデルの誤差を含んだ尤度関数は、この合成分布に基づいて以下のように書けます。
L_i = \frac{1}{\sqrt{2\pi(\sigma_i^2 + \sigma_{\text{model},i}^2)}} \exp \left(-\frac{(y_i - f_{\text{best}}(x_i))^2}{2(\sigma_i^2 + \sigma_{\text{model},i}^2)} \right)
これを用いた全データの尤度関数は、
L = \prod_{i=1}^n \left[\frac{1}{\sqrt{2\pi(\sigma_i^2 + \sigma_{\text{model},i}^2)}} \exp \left(-\frac{(y_i - f_{\text{best}}(x_i))^2}{2(\sigma_i^2 + \sigma_{\text{model},i}^2)} \right)\right]
これの対数を取ると、
\ln L = \sum_{i=1}^n \left[-\frac{1}{2} \ln (2\pi(\sigma_i^2 + \sigma_{\text{model},i}^2)) - \frac{(y_i - f_{\text{best}}(x_i))^2}{2(\sigma_i^2 + \sigma_{\text{model},i}^2)}\right]
第一項は定数なので省略すると、
\ln L = - \sum_{i=1}^n \frac{(y_i - f_{\text{best}}(x_i))^2}{2(\sigma_i^2 + \sigma_{\text{model},i}^2)}
を最大化することになります。これを最小化する形式にするために $-2$ をかけると、
\chi^2 = \sum_{i=1}^n \frac{(y_i - f_{\text{best}}(x_i))^2}{\sigma_i^2 + \sigma_{\text{model},i}^2}
となります。
$f_{\text{best}}(x_i)$ と $f(x_i)$ の関係性について
一般的に、$f_{\text{best}}(x_i)$ は観測データ $f(x_i)$ をもとに決定されますが、解析の枠組みによっては $f_{\text{best}}(x_i) = f(x_i)$ とみなして扱うこともあります。
たとえば、ポアソン統計に従う固有運動解析(後述)では、観測値そのものが最尤推定値となるため、$f_{\text{best}}(x_i) = f(x_i)$ として解析するのが一般的です。
応用例
X線天文学の一次元の固有運動解析では、モデル誤差を考慮したカイ二乗フィッティングが実用されています。
たとえば、Katsuda et al. (2008) や Tanaka et al. (2020)の方法では、以下のカイ二乗統計量を用います。
\chi^2(\Delta x) = \sum_{i} \frac{(f_i - g_i(\Delta x))^2}{\Delta f_i^2 + \Delta g_i(\Delta x)^2}
ここで、
- $f_i, \Delta f_i$ : 1つ目の観測データのフラックスと誤差
- $g_i(\Delta x), \Delta g_i(\Delta x)$ : 2つ目の観測データ(プロファイルシフト後)のフラックスと誤差
このカイ二乗フィッティングを用いることで、最も適切なプロファイルシフト量 $\Delta x_{\text{min}}$ を求め、2つのエポック間の固有運動を決定します。
Tanaka et al. 2020では、プロファイルを1ピクセル未満の精度で人工的にシフトし、観測データのビンと整合するように調整することで、ピクセルサイズの制約を超えた固有運動の測定を実現しています。
この式は、2つの観測データを対称的に扱う形になっている点が重要です。$f_i$ と $g_i$ を入れ替えても同じ形式になるため、どちらの観測も均等に考慮される設計になっています。
ただし、厳密には1ピクセル以下のシフトを考慮すると完全な対称性は崩れます。これは、離散的なピクセルデータを連続的にシフトする際の補間処理などの影響によるものです。それでも、この式の基本的な構造としては、特定のデータに偏ることなく、適切なカイ二乗評価が可能になっています。
この方法は様々な天体の固有運動解析で活用されています。
活用例:
- Katsuda et al. 2008
- Tanaka et al. 2020, 2021
- Matsuda et al. 2021
- Suzuki et al. 2022, 2023
- Wu et al. 2024
ポアソン統計とカイ二乗フィッティングの関係
X線天文学の観測データは本来ポアソン統計に従いますが、この手法はガウス分布を前提としたカイ二乗統計量を使用しています。
この点には理論的なギャップがありますが、ポアソン統計ではカウント数が大きくなるとガウス分布で近似できる(中心極限定理)ため、
統計が十分取れる一次元の固有運動解析では、カイ二乗フィッティングが有効となります。
そのため、ポアソンモデル(Cash 1979)で推定することもあります。
活用例:
実装
X線天文学の固有運動解析のため、ポアソン統計に従う観測データを用いたカイ二乗フィッティングによって推定する手法のシミュレーションをPythonを使って実装してみます。
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(2025)
# フィラメント構造(ガウス分布)を作成
sigma = 15 # フィラメントの幅(標準偏差)
true_shift = 10 # 既知のシフト量
x = np.arange(-50, 51, 1)
filament1 = np.exp(-x**2 / (2 * sigma**2))
filament2 = np.exp(-(x - true_shift)**2 / (2 * sigma**2))
# ポアソン統計に従うノイズを適用
exposure1 = 300
exposure2 = 100
obs_counts1 = np.random.poisson(filament1 * exposure1)
obs_counts2 = np.random.poisson(filament2 * exposure2)
obs_flux1 = obs_counts1 / exposure1
obs_flux2 = obs_counts2 / exposure2
# ポアソン統計に基づく誤差を計算
sigma_obs1 = np.sqrt(obs_counts1) / exposure1
sigma_obs2 = np.sqrt(obs_counts2) / exposure2
# シフトごとのカイ二乗値を計算
shift_range = 15 # シフトの探索範囲
shifts = np.arange(-shift_range, shift_range+1, 1)
chi2_values = np.zeros(len(shifts))
for i, shift_val in enumerate(shifts):
obs_flux2_shifted = np.roll(obs_flux2, -shift_val) # 観測2のデータをシフト
sigma_obs2_shifted = np.roll(sigma_obs2, -shift_val) # 観測2の誤差データをシフト
chi2_comp = (obs_flux1 - obs_flux2_shifted) ** 2 / (sigma_obs1**2 + sigma_obs2_shifted**2 + 1e-12)
chi2 = np.sum(chi2_comp[shift_range*2:-shift_range*2]) # 端の影響を避けるために中心部分のみ集計
chi2_values[i] = chi2 # 計算結果を保存
# Proper-motionを取得
estimated_shift = shifts[np.argmin(chi2_values)]
chi2_min = np.min(chi2_values)
# 結果のプロット
fig, axs = plt.subplots(2, 1, figsize=(10, 8))
# Observed filament data with noise bands
axs[0].plot(x, obs_flux1, '.-', label=f"Observation 1 (Exposure {exposure1}s)", alpha=0.7)
axs[0].plot(x, obs_flux2, '.-', label=f"Observation 2 (Exposure {exposure2}s, Shift {true_shift} px)", alpha=0.7)
axs[0].fill_between(x, obs_flux1 - sigma_obs1, obs_flux1 + sigma_obs1, color='blue', alpha=0.2, label="Obs1 Uncertainty")
axs[0].fill_between(x, obs_flux2 - sigma_obs2, obs_flux2 + sigma_obs2, color='orange', alpha=0.2, label="Obs2 Uncertainty")
# fitting rangeの境界
x_left = x[shift_range*2]
x_right = x[-shift_range*2 - 1]
axs[0].axvline(x=x_left, color='blue', linestyle='--', alpha=0.3, label="fitting range")
axs[0].axvline(x=x_right, color='blue', linestyle='--', alpha=0.3)
axs[0].legend()
axs[0].set_xlabel(r"$x$ (pixels)")
axs[0].set_ylabel("Flux")
axs[0].set_title("Poisson-noise affected filament observations")
axs[0].grid()
# Chi-squared function vs. shift
axs[1].plot(shifts, chi2_values, 'ko-', label=r"$\chi^2(\Delta x)$")
axs[1].axvline(x=true_shift, color='r', linestyle='-', alpha=1, label=f"True Shift ({true_shift} px)")
axs[1].axvline(x=estimated_shift, color='k', linestyle='--', alpha=0.5, label=rf"Estimated Shift ({estimated_shift} px, $\chi^2_{{\text{{min}}}}={chi2_min:.1f}$)")
axs[1].set_xlabel(r"$\Delta x$ (pixels)")
axs[1].set_ylabel(r"$\chi^2$")
axs[1].set_title(r"Chi-squared fit for different shifts")
axs[1].legend()
axs[1].grid()
plt.tight_layout()
plt.show()
出力結果
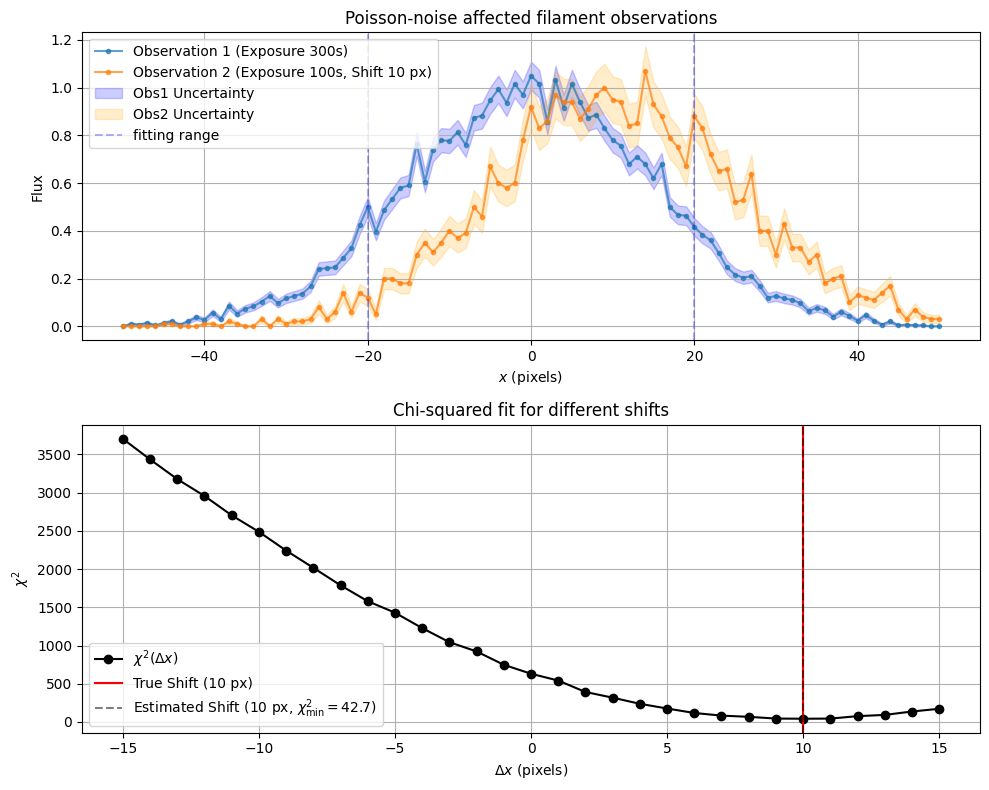
実装の説明
このコードでは、2つの観測データを異なる露光時間で取得し、固有運動によるシフトをカイ二乗フィッティングで推定しています。
1. 観測データの生成とカイ二乗フィッティングの流れ
-
観測データの生成: ガウス分布を仮定したフィラメント構造を作成し、片方を+10ピクセルシフトさせて表示。
-
ポアソンノイズの適用: 露光時間を Obs1 = 300s、Obs2 = 100s に設定し、短い露光の方がノイズが大きくなる様子を可視化。
-
カイ二乗フィッティング: 異なるシフト量に対してカイ二乗値を計算し、最も適したシフト量を決定。
-
シフト範囲の両端(左右2倍の範囲)を計算から除外
- 解析対象は統計が十分で構造がある中心領域に限定し、誤差の影響を抑えるため。
- シフトによってデータの外側がゼロで埋められる領域が発生し、それを含むと正しい評価ができないため。
-
シフト範囲の両端(左右2倍の範囲)を計算から除外
-
結果: 真のシフト(赤線)と推定シフト(黒点線)を比較し、固有運動を評価。
2. カイ二乗フィッティングの自由度
本記事では自由度について詳細には扱いませんが、カイ二乗フィッティングの自由度 は、使用したデータ点数から推定パラメータ数を引いたものとして定義されます。今回の解析では、41点のデータを使用し、推定パラメータはシフト量1つであるため、フィッティング全体の自由度は40となります。
カイ二乗統計量の最小値 $\chi^2_{\text{min}}$ は、理論的には自由度と同程度($\chi^2_{\text{min}} \sim 40$)となることが期待され、これが満たされていれば、2つのプロファイルは統計的に妥当な一致を示していると考えられます。
3. 誤差評価と信頼区間
シフト量という1つのパラメータを推定する際の誤差評価では、「自由度1のカイ二乗分布」を用いることに注意が必要です。具体的には、カイ二乗統計量 $\chi^2(\Delta x)$ の曲線において、最小値 $\chi^2_{\text{min}}$ からの増加量を基準に、累積分布分布(CDF)から信頼区間を決定します。
カイ二乗分布の詳細な累積分布関数については、Wikipediaのカイ二乗分布のページ を参照してください。
P(\chi^2 \leq \chi^2_{\text{min}} + \Delta\chi^2) = \text{CDF}(\Delta\chi^2; \nu=1)
これにより、自由度1のカイ二乗分布では以下のように信頼区間が決まります。
- $1\sigma$(約68.3%): $\chi^2 \leq\chi^2_{\text{min}} + 1$
- $2\sigma$(約95.4%): $\chi^2 \leq\chi^2_{\text{min}} + 4$
- $3\sigma$(約99.7%): $\chi^2 \leq\chi^2_{\text{min}} + 9$
4. 他のパラメータを固定した場合の自由度
注意すべきなのは、推定するパラメータが複数ある場合でも、他のパラメータを固定したうえで特定の1つのパラメータについて誤差評価を行う場合、その変動は自由度1のカイ二乗分布に従うという点です。例えば、2つのパラメータ($\Delta x, a$)を持つ場合でも、$a$ を固定した状態で $\Delta x$ の誤差を評価するなら、自由度1のカイ二乗分布を用いることができます。
この基準は、推定パラメータが1つ(または他のパラメータを固定した場合)の場合に適用されるものであり、全体のフィッティング自由度(例えば40)とは別の概念です。
まとめ
本記事では、理論モデル自体にも誤差がある場合のカイ二乗分布 を説明しました。モデル誤差を適切に取り入れることで、観測データの誤差と理論モデルの不確かさの両方を考慮した、より現実的な解析が可能になります。
特に、X線天文学における固有運動解析では、この手法が実際に適用されており、ポアソン統計に従う観測データでも統計が十分な場合にはガウス近似を用いることでカイ二乗フィッティングを適用できます。この手法を用いることで、解析結果の信頼性が向上し、より妥当な物理的解釈が可能になります。
また、ポアソンノイズを持つフィラメントデータを用いたシミュレーションを実装 し、カイ二乗フィッティングによる固有運動の推定を行いました。
この手法は、X線天文学のほか、画像解析や時系列データの評価 など幅広い分野で応用可能です。
なお、カイ二乗分布や統計解析について、まだ学ぶべきことがたくさんあります。今後も理解を深め、より正確で実用的な解析手法を探求していきたいと考えています。もし誤りや改良点がありましたら、ご指摘いただけますと幸いです。本記事が、データ解析の参考になれば幸いです。