はじめに
本記事では、paiza の新作プログラミングゲーム「電脳少女プログラミング2088 ─壊レタ君を再構築─」の 公式イベント に参加し、問題に挑戦しました。難易度が高く、最適な解法を見つけるのに苦戦しましたが、最終的にはブラックボックステストを活用してクリアしました。完全攻略とはなりませんでしたが、記事にまとめたいと思います。
挑戦した問題は「思い出の屋上」です。
問題概要
- 街は
H×Wのマス目で構成されており、ギャング同士の縄張り争いが発生しています。 - それぞれの縄張りは、特定の中心
(r, c)からマンハッタン距離S以下のマスを占めます。 - 既存の縄張りのエリアと重ならないように、新たな縄張りを作成します。
- 可能な限り最大の
Sを持つ新しい縄張りを配置し、そのSを出力します。
解法のポイント
-
畳み込みを用いた配置可能性の判定
- 既存の縄張りがない領域を
1、縄張りがある領域を0とする配列を作成し、外側を1でパディング。 - マンハッタン距離フィルタ を適用し、畳み込みを行う。
- その結果、畳み込みの出力がフィルタの総要素数と一致する領域があれば、新しい縄張りを配置可能と判断する。
- 既存の縄張りがない領域を
-
二分探索で最大
Sを求める-
S=0からS = H + W - 1まで二分探索を行い、最大のSを求める。(Sが最大になるケースは角に一つだけ領域を取るケース。)
-
-
結果の可視化
- 既存の縄張りと新しく配置した縄張りを色分けし、視覚的に確認。
実装コード
実装コードについて説明します。
このコードの探索範囲 right = sum(occupied_grid.shape) - 1 が理論的には正しいですが、
探索範囲が広がると 計算量が増えすぎてタイムアウトする可能性があります。
そのため、コード提出時のブラックボックステストの末、 right = max(occupied_grid.shape) という制限で正解することができましたが、汎用的な解法として処理速度の観点で改善の余地があります。
提出したコードはこちら
- 提出用のコードでは可視化の部分は除いています。
- 問題の形式に合わせた
input()で受け取れる仕様になっています。
H W M
r_1 c_1 S_1
r_2 c_2 S_2
...
r_M c_M S_M
-
H, Wはグリッドの行数と列数。 -
Mは既存の縄張りの数。 -
r_i, c_i, S_iはそれぞれ、i 番目の縄張りの中心の座標とサイズS。
import numpy as np
import matplotlib.pyplot as plt
from scipy.signal import convolve2d
def create_manhattan_mask(height, width, center_r, center_c, size):
"""
指定した座標 (center_r, center_c) を中心にマンハッタン距離 size のフィルタを作成
"""
mask = np.zeros((height, width), dtype=int)
center_r -= 1 # 1-indexed → 0-indexed
center_c -= 1
# 全セルに対してマンハッタン距離を計算
y, x = np.meshgrid(np.arange(height), np.arange(width), indexing='ij')
manhattan_distances = np.abs(y - center_r) + np.abs(x - center_c)
# マンハッタン距離 size 以下のセルを 1 にする
mask[manhattan_distances <= size] = 1
return mask
def get_best_placement(occupied_grid, territory_size):
"""
配置可能な最大 S の縄張りの中心位置を取得
"""
mask_height, mask_width = 2 * territory_size + 1, 2 * territory_size + 1
center_r, center_c = territory_size + 1, territory_size + 1
# マンハッタン距離のフィルタを作成
territory_mask = create_manhattan_mask(mask_height, mask_width, center_r, center_c, territory_size)
# 既存の縄張りを反転 (0: 縄張り, 1: 空き)
empty_grid = 1 - occupied_grid
# 畳み込みで配置可能な領域を計算
placement_scores = convolve2d(empty_grid, territory_mask, mode='same', boundary='fill', fillvalue=1)
# 配置可能な最大 S の位置を取得
max_possible_match = np.max(placement_scores)
if max_possible_match == np.sum(territory_mask):
return True
return None
def find_max_territory_size(occupied_grid):
"""
配置可能な最大 S を求める(二分探索)
"""
# S の探索範囲(right = sum(occupied_grid.shape) - 1が正しいが
# 時間が足りずタイムアウトになることを確認。
# 一応これで正解にはなるが汎用的なコードではないことに注意)
left, right = 0, max(occupied_grid.shape)
best_size = -1
best_position = None
while left <= right:
mid = (left + right) // 2
flag = get_best_placement(occupied_grid, mid)
if flag:
best_size = mid # さらに大きくできるか試す
left = mid + 1
else:
right = mid - 1
return best_size
# 既存の縄張りをセット
grid_height, grid_width, num_territories = [int(i) for i in input().split()] # グリッドサイズ
occupied_grid = np.zeros((grid_height, grid_width), dtype=int) # 初期化(空白)
# 既存の縄張りのデータ
existing_territories = []
for i in range(num_territories):
existing_territories.append([int(j) for j in input().split()])
for r, c, S in existing_territories:
territory_mask = create_manhattan_mask(grid_height, grid_width, r, c, S)
occupied_grid |= territory_mask # 縄張りを適用
# 最大 S の探索
max_territory_size = find_max_territory_size(occupied_grid)
# 結果の表示
print(max_territory_size)
実装コードの可視化
ここでは、この問題を可視化してわかりやすく示したいと思います。
import numpy as np
import matplotlib.pyplot as plt
from scipy.signal import convolve2d
def create_manhattan_mask(height, width, center_r, center_c, size):
"""
指定した座標 (center_r, center_c) を中心にマンハッタン距離 size のフィルタを作成
"""
mask = np.zeros((height, width), dtype=int)
center_r -= 1 # 1-indexed → 0-indexed
center_c -= 1
# 全セルに対してマンハッタン距離を計算
y, x = np.meshgrid(np.arange(height), np.arange(width), indexing='ij')
manhattan_distances = np.abs(y - center_r) + np.abs(x - center_c)
# マンハッタン距離 size 以下のセルを 1 にする
mask[manhattan_distances <= size] = 1
return mask
def get_best_placement(occupied_grid, territory_size):
"""
配置可能な最大 S の縄張りの中心位置を取得
"""
mask_height, mask_width = 2 * territory_size + 1, 2 * territory_size + 1
center_r, center_c = territory_size + 1, territory_size + 1
# マンハッタン距離のフィルタを作成
territory_mask = create_manhattan_mask(mask_height, mask_width, center_r, center_c, territory_size)
# 既存の縄張りを反転 (0: 縄張り, 1: 空き)
empty_grid = 1 - occupied_grid
# 畳み込みで配置可能な領域を計算
placement_scores = convolve2d(empty_grid, territory_mask, mode='same', boundary='fill', fillvalue=1)
# 配置可能な最大 S の位置を取得
max_possible_match = np.max(placement_scores)
if max_possible_match == np.sum(territory_mask):
best_r, best_c = np.unravel_index(np.argmax(placement_scores), placement_scores.shape)
return best_r, best_c
return None
def find_max_territory_size(occupied_grid):
"""
配置可能な最大 S を求める(二分探索)
"""
left, right = 0, sum(occupied_grid.shape) - 1 # S の探索範囲
best_size = -1
best_position = None
while left <= right:
mid = (left + right) // 2
best_pos = get_best_placement(occupied_grid, mid)
if best_pos:
best_size = mid # さらに大きくできるか試す
best_position = best_pos
left = mid + 1
else:
right = mid - 1
return best_size, best_position
# 既存の縄張りをセット
grid_height, grid_width = 3, 3 # グリッドサイズ
occupied_grid = np.zeros((grid_height, grid_width), dtype=int) # 初期化(空白)
# 既存の縄張りのデータ
existing_territories = [(2, 2, 1)] # (row, column, size)
for r, c, S in existing_territories:
territory_mask = create_manhattan_mask(grid_height, grid_width, r, c, S)
occupied_grid |= territory_mask # 縄張りを適用
# 最大 S の探索
max_territory_size, best_position = find_max_territory_size(occupied_grid)
# 結果を可視化
fig, ax = plt.subplots(figsize=(7, 4))
occupied_grid_display = occupied_grid.copy()
# 最大 S を配置可能な位置に 2 を設定
if best_position:
best_r, best_c = best_position
new_territory_mask = create_manhattan_mask(grid_height, grid_width, best_r + 1, best_c + 1, max_territory_size)
occupied_grid_display[new_territory_mask == 1] = 2 # 最大 S の領域を 2 に設定
# 可視化
cmap = plt.colormaps.get_cmap("coolwarm") # 0: 空白, 1: 既存の縄張り, 2: 新しい縄張り
im = ax.imshow(occupied_grid_display, cmap=cmap, origin="upper")
# **グリッドの設定(間に線を引く)**
ax.set_xticks(np.arange(grid_width) + 0.5, minor=True)
ax.set_yticks(np.arange(grid_height) + 0.5, minor=True)
ax.set_xticks(np.arange(grid_width)) # 軸ラベルは整数
ax.set_yticks(np.arange(grid_height))
ax.set_xticklabels(np.arange(1, grid_width + 1))
ax.set_yticklabels(np.arange(1, grid_height + 1))
ax.grid(which="minor", color="gray", linestyle="--", linewidth=0.5)
# タイトルとカラーバー
plt.title(f"Max Possible S = {max_territory_size}")
# カラーバーのラベル設定
cbar = plt.colorbar(im, ax=ax, ticks=[0, 1, 2], boundaries=[-0.5, 0.5, 1.5, 2.5])
cbar.set_ticklabels(["Unoccupied", "Existing Territory", "New Maximum Territory"])
plt.show()
出力結果
-
入力例1
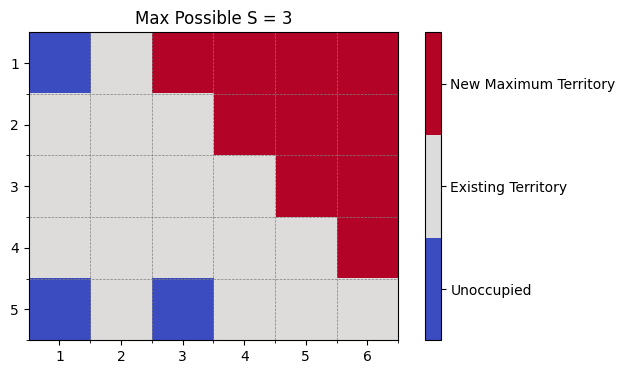
-
入力例2
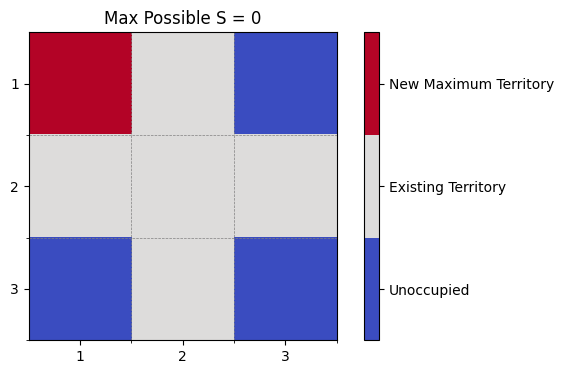
以下の図では、それぞれの色が意味するものを示しています。
-
赤色 (New Maximum Territory) : 配置可能な最大の新しい縄張り。(あくまで一例です。例えば、入力例2では、
S = 0で塗られる縄張りは他にもあります。) - 白色 (Existing Territory) : 既存の縄張り。
- 青色 (Unoccupied) : 縄張りがない空き地。
マンハッタン距離の可視化
畳み込みに使用したマンハッタン距離フィルタを可視化することで、このフィルタの特徴を理解します。
# サイズ S = 0 から 8 までを可視化(3x3 のグリッド)
territory_sizes = np.arange(9)
fig, axes = plt.subplots(3, 3, figsize=(9, 9))
for ax, territory_size in zip(axes.flat, territory_sizes):
mask_height, mask_width = 2 * territory_size + 1, 2 * territory_size + 1
center_r, center_c = territory_size + 1, territory_size + 1
# マンハッタン距離のフィルタを作成
territory_mask = create_manhattan_mask(mask_height, mask_width, center_r, center_c, territory_size)
ax.imshow(territory_mask, vmin=0, vmax=1, cmap='gray', origin='upper')
ax.set_title(f"S = {territory_size}")
ax.set_xticks([])
ax.set_yticks([])
plt.tight_layout()
plt.show()
出力結果

この可視化では、各 S に対して中心点からマンハッタン距離 S 以内の範囲が白(1)で示され、特徴的なひし形の形状を持ちます。これは、ユークリッド距離を基準とする場合に円形になる点と対照的であり、興味深い違いです。
また、コードの補足として、既存の縄張りがない領域を 1、外側も 1 でパディングした配列に畳み込み、その結果がフィルタの総要素数と一致する領域があれば、新しい縄張りを配置できる ことを意味します。実際には、縄張りがない領域のみを対象に計算する方が高速ですが、デバッグや可視化のしやすさを考慮すると、このようなフィルタ処理が有効な場合もあります。私は画像処理をよく活用するため、競技プログラミングとしては一般的でない手法かもしれませんが、今回は SciPy ライブラリを利用しました。
paizaについて
本イベントを提供している paiza は、プログラミング学習やスキルアップ、就活サービスなど、多くのエンジニアにとって貴重な場となっています。私も5年前、友人の勧めでプログラミングを勉強し始めた頃に利用し、特にスキルチェック機能を楽しんでいました。初心者でも学びやすく、競い合いながら成長できる環境が魅力的です。今回の挑戦を通じて、実践的なアルゴリズムの学習ができ、有意義な時間を過ごすことができました。今後の新しいサービスの展開にも期待しています。
イベント詳細:
まとめ
本記事では、マンハッタン距離フィルタを活用し、二分探索と畳み込みを組み合わせた最適な縄張り配置の探索手法を解説しました。可視化を通じてその効果も確認しました。
ただ、処理速度にはまだ課題があり、さらなる最適化が必要です。他の方の解法も参考にしながら、より効率的なアプローチを模索していきたいと思います。