0-1. はじめに
タイトルで釣りました、すみません。
最近低レイヤ技術の学習にハマっていて、先日「自作エミュレータで学ぶx86アーキテクチャ」という本を元に、Linux上でx86エミュレータを自作しました。
(なんで低レイヤを学び始めたのか?などはこちらの記事に書いています。)
で、せっかくなのでその備忘録として書籍を進めていく中でやったことや苦労したことなどをまとめたら、これからCPUや低レイヤを勉強したいと考えている人の参考になるかもしれないと思ったので、記事にすることにしました。
低レイヤに興味ある方もそうでない方もぜひ最後までご覧ください。
0-2. 対象読者
- CPUの動作を知りたい人
- 低レイヤに興味がある人
- コンピュータの内部について理解したい人
本記事の内容
| 章 | タイトル | 備考 |
|---|---|---|
| 0-1. | はじめに | |
| 0-2. | 対象読者 | |
| 1. | 前提 | 初学者が低レイヤを学ぶ上での注意点を説明しています |
| 2. | 本の紹介 | |
| 3. | 良かったところ | 筆者の目線でこの本の良かった部分について説明しています |
| 4. | 大変だったところ | 実際に実装する中で大変だった部分について説明しています |
| 5. | これだけは知っておきたい! 〜低レイヤ基礎知識 6 選〜 | 本記事のメイン部分です。低レイヤを学ぶ上で必須となる知識について丁寧に解説していきます。 |
| 6. | 次に挑戦したいこと | |
| 7. | おわりに | |
| 8. | 参考文献 |
1. 前提
本題に入る前に、今回の書籍のようなある程度低レイヤ目の技術書を初学者の人が読み進める際の注意点について、個人的意見を少しお伝えしておきたいと思います。
1-1. 低レイヤ技術の全体感を掴んでおこう
まず最初にやっておいた方がいいのは、**「低レイヤ技術の全体感を掴んでおくこと」**です。
そもそもさっきから出てくる「低レイヤの技術」というのは要は**「コンピュータシステムの仕組み」ということで、例えば高水準言語で Hello World と書かれたコードがどのような処理をされて、画面に出力されているかを細かく理解できているか**ということになります。
で、これを理解するためには具体的には以下のような要素についてちゃんと理解しておく必要があります。1
| 項目 | 内容 |
|---|---|
| (高水準言語) | 抽象度が特に高いプログラミング言語という意味で代表的な言語としては、C言語やJavaがある。 |
| 低水準言語 | コンピュータ用のプログラミング言語のうち、機械語ないし機械語に近いアセンブリ言語などの言語の総称。 |
| コンパイラ | 高水準言語で書かれたコンピュータプログラムを、コンピュータが解釈・実行できる形式に一括して変換するソフトウェア。 |
| アセンブラ | アセンブリ言語で記述されたコンピュータプログラムを、コンピュータが直接解釈・実行できる機械語(マシン語)による表現(オブジェクトコード)に変換するソフトウェア。 |
| OS | ソフトウェアの種類の一つで、機器の基本的な管理や制御のための機能や、多くのソフトウェアが共通して利用する基本的な機能などを実装した、システム全体を管理するソフトウェア。 |
| CPU | コンピュータの主要な構成要素の一つで、他の装置・回路の制御やデータの演算などを行う装置 |
このように、低レイヤの技術といってもその実体は様々な要素が複雑に絡み合っているものなのです。
そのため、これらの全体感、つまり「全体からみた各要素の役割」や「各要素ごとの繋がり」を理解しておくことがまず何よりも重要となってきます。
この全体感を抑えないまま、要素ごとの学習を進めていってしまうと、**「自分が一体全体の中のどんな役割を担う部分の勉強をしているのか」**ということを見失ってしまい、何度も何度も見返しながら学習を進めていく羽目になってしまい、結果的に非常に効率が悪くなってしまいます。
また、自分が今やっている学習の意義も見出せなくなってしまうため、モチベーションの低下にもつながりかねません。
そういったことを防ぐためにも、まずはざっくりでいいので低レイヤの全体感を把握しましょう。
具体的には、以下の書籍を読むことをおすすめします。
| おすすめ書籍 | |
|---|---|
| ① | 「コンピュータはなぜ動くのか?」 |
| ② | 「プログラムはなぜ動くのか?」 |
| ③ | 「キタミ式イラストIT塾 基本情報技術者」 |
①「コンピュータはなぜ動くのか?」

言わずとしれた名著。低レイヤの勉強を始めようと考えている人が真っ先に読むべき本です。
以下の「プログラムはなぜ動くのか?」とセットで読むことで、低レイヤの全体感を掴むことができます。
特に第2章の「コンピュータを作ってみよう」の内容はかなり秀逸。
というのも**「実際のコンピュータ製作を紙面上で体験してみよう」という他の書籍では中々お目にかかれないような内容**になっており、予め用意された回路図を元に実際に色鉛筆でなぞっていくという作業をすることにより、擬似的な配線作業を体験することができ、コンピュータの動作原理を簡単に学ぶことができます。
低レイヤを学びたい人にもそうでない人にも非常におすすめの一冊です。
②「プログラムはなぜ動くのか?」

「コンピュータはなぜ動くのか?」の続編のような本で、こちらは「コンピュータ全体の動き」というよりは「プログラムがどのようにして実行されるのか?」といったことに焦点が当たっています。
図が非常に豊富で、普段意識しない低レイヤについてわかりやすく学ぶことができます。
少し補足ですが、個人的には上記二冊は
「コンピュータはなぜ動くのか?」→「プログラムはなぜ動くのか?」
の順番で読むことをおすすめします。
というのも、本の著者の矢沢久雄さんは、「プログラムはなぜ動くのか?」を読んだ読者から「内容がやや難しい」との声があったため、「コンピュータはなぜ動くのか?」を執筆されたという経緯があります。
そのため内容的には「コンピュータは〜」の方が易しくなっており、こちらを読んでから「プログラムは〜」を読んだ方が内容が頭に入ってきやすいからです。
③「キタミ式イラストIT塾 基本情報技術者」

こちらは基本情報技術者試験を受けたことがある方ならご存知の、いわゆる「キタミ式」と呼ばれる本です。
本来は基本情報技術者試験用の参考書として有名なこちらの本ですが、低レイヤを学ぶ上でも非常に参考になります。
詳しい説明は拙著の「IT知識0から1ヶ月で基本情報技術者試験に合格した話」で解説していますので、よければそちらをご覧ください。
1-2. 作りながら学ぼう
次に意識して欲しいのが、**「『作りながら学ぶ』を念頭に学習を進めていく」**ということです。
「概念レベルの抽象的な話だけだとどうしても理解ができない部分が発生してしまうので、手を動かしながら学んだ方が効率が良い」
というのはプログラミングを学習しているとよく言われる話ですが、低レイヤの場合は特にそれが顕著です。
というのも、みなさんがよく学習する高水準言語だとまだ概念レベルの話でもなんとかイメージできることが多いのですが、低レイヤの場合その割合が極めて少ないからです。
これは現代のコンピュータシステムが私たち人間が使いやすいように「抽象化」されてしまっており、その中身がいい意味でブラックボックス化されてしまっていることに起因しています。
そのため、実際学ぶ際は**「自分で手を動かして作りながら学ぶ」**ということが極めて重要になってきます。
作りながら学ぶ過程で何度もつまづき、その度に原因を調査するということを繰り返し行うことで、概念レベルの理解から「OSやCPUがどのように実装されているのか」「細かいやり取りがどのように行われているのか」を理解することできます。
低レイヤの技術を学ぼうと思った際は、最終的に何か成果物を作る教材を使用することをお勧めします。
1-3. C言語に触れておこう
最後に**「C言語に触れておこう」**というのを挙げておきます。
まずC言語について以下に簡単な説明を載せておきます。
C言語とは、広く普及している手続き型の高水準プログラミング言語の一つ。汎用的な言語で様々な分野で広く利用されているが、特にハードウェアを直接制御するプログラムの開発で利用される機会が多い。
※引用元 IT用語辞典
ここで太字で囲った部分に注目してください。
C言語の大きな特徴として、このように**「ハードウェアを直接制御できる」**というのがあります。
具体的にはメモリやCPUを制御するための構文が用意されていて、いわゆる低水準言語としての機能も持ち合わせているのです。
この特徴からOSやハードウェアの生の姿を見るような目的にはC言語は非常に適しており、低レイヤの書籍には頻繁に利用されています。
そのため、低レイヤを学び始めようとする人はまず最初に軽くでいいのでC言語に触れ、ある程度理解しておくことをおすすめします。
現に私自身も2~3日軽くC言語の勉強を行ったおかげで、低レイヤ関連の書籍の理解が深まりましたし、また高水準言語を学んでいるときには全く知らなかったポインタなども学ぶことができ、プログラミング自体の理解も深まりました。
さてそんなC言語の学習教材に関してですが、ネット上に無料で落ちているものがたくさんあるので、適当にググって出てきたものをやってもらうとひとまずは大丈夫かと思います。
一応個人的におすすめなのは
です。(通称苦C)
こちらは開発環境の準備なども丁寧に載っていて、かつ内容もかなりまとまっているので初学者の方には特におすすめです。
またネット上の教材だといまいちやる気が起きないというような方は書籍の購入を検討してもいいでしょう。
個人的におすすめは
です。
非常にわかりやすいと評判のスッキリシリーズのC言語版ですが、こちらは開発環境が事前に準備されているため、自分で準備する必要すらありません。
そのためスムーズに学習に入れますし、また内容自体もイラストが豊富で非常にわかりやすいものとなっていますので、初学者の方には特におすすめです。
2. 本の紹介
さて、では本題に入っていきしょう。
まずは今回私が参考にさせていただいた本について簡単にご紹介しておきます。

CPUの動きをパソコン上で再現するエミュレータ制作を通して、コンピュータの中身の全般的な理解を目指します。
C言語をはじめとする高級言語が主流の今、その基礎となる機械語やアセンブリ言語がCPUでどう実行されるかを意識することはめったにありませんが、本書ではそういった“低級言語”を実行するエミュレータの制作を通してx86 CPUの仕組みや、その周りで動くメモリ、キーボード、ディスプレイといった部品とCPUの関わりをしっかり学び、エンジニアとしての“深み”を身につけることを目指します。
Chapter 1 C言語とアセンブリ言語
Chapter 2 ポインタとアセンブリ言語
Chapter 3 CPU がプログラムを実行する仕組み
Chapter 4 BIOS の仕組みと実機起動
Appendix
A 開発環境のインストールと構成
B ASCII コード表
※引用元 マイナビBOOKS 内容紹介
内容紹介にある通り、こちらの「自作エミュレータで学ぶx86アーキテクチャ」は全4章からなる比較的薄めの本なのですが、その中身は見た目に反して割と重いです。
簡単にChapterごとにどんな内容を学ぶのかを説明しておきますと、まずChapter1ではC言語プログラムが機械語に変換される様子を実際に手を動かしながら確認しつつ、さらにアセンブリ言語との関係性について解説しています。
そしてそれらを通して、C言語プログラムが最終的にどのような形に変換されてCPU上で実行されるのかを確認します。
続くChapter2では、C言語でつまづきがちなポインタについて、アセンブリ言語との関係性から紐解いています。
またこの章からx86 エミュレータ作りも開始します。
そしてChapter3はこの本の中心となる章で、エミュレータを実際に作りながらCPUが動く仕組みについての理解を深めていきます。
具体的にはHDDのプログラムをどのように読み込んで、どのようにCPUが解釈、実行するのか?を学んでいきます。
最後のChapter4では、コンピュータ起動に欠かせないBIOSについて学び、実機上でOSの力を借りずにプログラムを実行するということに挑戦します。
実際に手を動かしながら、**コンピュータがどのように起動するのか?**を学んでいくことができます。
3. 良かったところ
次に筆者目線で本書を読んで良かったと思う部分について、挙げていきいきます。(あくまで一個人の主観です。)
3-1. エミュレータ作りの難易度が低いため理解がしやすい
まずはなんと言っても**「CPUエミュレータの中でも比較的難易度が低いものを作るため理解がしやすい」**という点が良かったです。
そもそもエミュレータというのは
あるハードウェアやソフトウェアの動作を模倣する別のソフトウェア
を意味します。
例えば、有名どころでいうとOracle VM VirtualBoxなどもエミュレータです。
これはOS上で実行されるアプリケーションの一つとして仮想的なコンピュータを構築し、その上で別のOSを実行することができるものになります。
具体的には、Virtualboxを導入することによりMac環境でWindowsやLinuxなど複数のOSを切り替えて使用することが可能になります。
まさにOSを**"エミュレート(模倣)"**していますね。
そして、今回作成するエミュレータはCPUの動作をソフトウェアで模倣し、その上で別のソフトウェアを実行する"CPUエミュレータ"になります。
ただ一口にCPUレベルで模倣するとは言ってもいくつか種類があり、また難易度もそれぞれ異なります。
ざっと難易度の高い順から並べると
- トランジスタの電圧変動をリアルタイムで忠実に再現
- クロック毎のNANDゲートのON/OFFを再現
- 機械語を実行した結果、レジスタがどうなるかを再現
のようになります。
1や2のようなエミュレータを作るには、ハードウェア記述言語(VHDL)を用いてCPUを設計し、FPGAという半導体デバイスに実装して、その動作を確認したりする必要があります。
しかし、これは具体的な設計の段階で、基本となる論理回路や算術論理演算ユニット(ALU)をはじめとするハードウェアの基礎知識が必要となり、回路設計の経験が乏しい場合はそのハードルの高さがボトルネックになります。
一方、ここで作成するエミュレータは3のようなエミュレータであり、CPUの動作をソフトウェア上で模倣するCPUエミュレータであり、使用する言語も高水準言語(本書ではC言語)とVHDLなどよりはとっつきやすいものとなっています。
これは、3のようなエミュレータを作る場合データ処理はあくまでエミュレータが動くパソコンのCPUの演算装置をそのまま使うため、ハードウェア的なエミュレートを必要としないからです。
そのため、ハードウェアの知識がなくても簡単にCPUを作成できて、かつコンピュータ内部を学習することもできます。
以上のように初学者がCPUの動作を学ぶには、まさに本書のような
「難易度の低いレジスタ部分のみを再現するエミュレータ」
を作ることがうってつけなんです。
3-2. アセンブリ言語やポインタの理解が深まる
次に挙げられるのが、**「アセンブリ言語やポインタの理解が深まる」**という点です。
内容紹介にもありますが、本書のエミュレータを作ることにより、CPUの仕組みやその周りで動くメモリ、キーボード、ディスプレイと言った部品とCPUとの関わりを学ぶことができます。
中でも機械語やアセンブリ言語のような低水準言語については深く学ぶことになっていきます。
というのも、本書のエミュレータ作成の流れとしては、**「機械語プログラムが書かれたファイルを受け取って、それを先頭から順に実行していくようなもの」**を想定しており、必然的に機械語やアセンブリ言語の構造を知る必要があるからです。
具体的には機械語のオペコードを読み取って、その値に応じて処理を実装していくという流れでエミュレータを作っていくのですが、そのためには「オペコードにどんな種類のものがあるのか?」といったことを知るのが必要不可欠です。
またアセンブリ言語や機械語の学習と同時に、ハードウェア的な目線からメモリを学習していくため、一般的に難しいとされるポインタを普段とは違う角度からも学ぶことができます。
そのため、ポインタの理解に苦しんでいる人には非常に役に立ちます。
オペコードというのは、機械語の命令の種類を表す部分を指し、各命令により1~3バイトまで幅があります。
ちなみに機械語は以下のような構造を取っており、各部分ごとに何を示しているのかが異なっています。
(i386の仕様)

4. 大変だったところ
次に実際に本書を読み進めていく中で大変だった部分について説明していきます。
4-1. 環境構築
本書の開発環境はWindowsを想定しているため、MacやLinuxでは動作しません。
ですが私は都合上どうしてもLinuxで開発したかったため、本書の内容をLinux上で実行できるよう工夫する必要がありました。
具体的にはこちらの記事を参考に、Manjaro環境2を用意し、必要なツール等をインストールして環境構築をしていったのですが。初めのうちは色々と失敗してしまい、少し大変でした...
具体的には参考記事の方では他のLinuxディストリビューションでも可能だと書かれていたのですが、私の場合他のディストリビューションで試してもなぜかエラーが出てしまい、実行することができませんでした。
(原因はいまだに不明)
そのため、諦めて参考記事の方と同じようにManjaroで開発することにしました。
Manjaroは今まで使用したことがなかったのですが、パッケージマネージャー等の細かな違い以外は他のディストリビューションとほぼ同じだったため、特段困ることはありませんでした。
ちなみに実機にManjaroをインストールする方法はいろいろありますが、私はVirtualboxを利用しました。
VirtualboxにManjaro環境を構築する方法はググったらすぐに出てきますので、こちらでは割愛させていただきます。
4-2. エミュレータの動作原理の把握
次に苦労したのが、本書のメインであるエミュレータプログラムの実装です。
具体的には**「エミュレータが、どういう動きをして機械語プログラムを解釈し実行しているのか?」を把握することに苦労しました。**
これは私自身が本書の一周目からいきなりプログラムの細部まで理解しようとしてしまったため、中々先に進めず挫折しそうになったことが原因です。
本書で作成するエミュレータの動作原理をざっくりまとめると、
①機械語のオペコード部分を読み取る
②オペコードの値に従って関数ポインタテーブルから処理を取り出し、実行する
というものになっており、この関数ポインタテーブルのイメージを掴むのに少し苦労しました。
(慣れればそこまで難しくはありません。)
個人的意見になりますが、CPUをハード部分から実装したことがあったり、またはCPUエミュレータを作ったことがある人の場合本書の内容を一周目でいきなり理解できるかもしれませんが、それ以外の人にはいきなりエミュレータの細部の動きまで理解することはぶっちゃけハードルがかなり高いです。
そのため、低レイヤ初学者の方は一周目はコピペ駆動開発気味で進めていき、「エミュレータ全体の動きをなんとなく理解できたらいいや」くらいのノリで読み進めていくことをおすすめします。
そしてエミュレータの細部の動きは二周目以降で理解していくという形が理想的かと思います。
現に私自身も、「一周目でいきなり全てを理解するのは諦めよう」と割り切ってからはスムーズに本書を読み進めていくことができましたし、また二周目以降は一周目で全体感を理解できているため、すんなりとプログラムの細部まで理解することができました。
ただ本書は一周だけしてざっくり全体像を理解しておくだけでもかなり勉強になりますので、時間がない方などは一周だけでも充分価値はるかと思います。
5. これだけは知っておきたい! 〜低レイヤ基礎知識 6 選〜
最後に、本書の中で**「これはプログラミング初学者の方でも知っておいた方が良さそう」**と思った部分について簡単にまとめていきたいと思います。
低レイヤに興味ある方もそうでない方も、エンジニアを目指すのなら知っておいて損はない知識かと思いますので、参考にできるところがあればぜひ参考にしてください。
| 節 | 項目名 |
|---|---|
| 5-1. | 二進法 |
| 5-2. | 機械語とアセンブリ言語 |
| 5-3. | CPU |
| 5-4. | メモリ |
| 5-5. | プログラム実行までの流れ |
| 5-6. | 条件分岐 |
5-1. 二進法
二進法とは簡単に言うと、2をひとかたまりとして数を表す方法です。また二進法で表された数のことを二進数と呼びます。
そもそも現在私たちが使用しているのは、「アラビア数字」と呼ばれるもので、これは「位取り記数法」という方法で数を表します。
位取り記数法とは、
数の表現方法の一種で、あらかじめ定められたN 種類の記号(数字)を列べることによって数を表す方法である。(位取りのことを桁ともいう。)
※引用元 Wikipedia
つまり簡単に言うと、**「適当に何種類かの数字を選んで、それを横一列に並べる」**と言うことです。
そして、当然ですがこの選ぶ数字の種類によって、同じ数でも表記が変わってきます。
例えば、十種類の数字を選んだ場合、
16 32 128
のようにみなさんが日常で使用する馴染み深い表現になります。
しかし、例えば二種類の数字を選んだ場合、上記の数は
10000 100000 10000000
のようになり、あまり見たことがない表現へと変化します。ポイントは同じ数を表しているものの、その表現方法が異なるということです。
このように、**位取り記数法は「何種類の数字」を選ぶかによって同じ数でも表現方法が異なってきて、**そのため、各表現方法を区別できるよう名前をつけることが必要になってきます。
そこで前者のように十種類の数字を用いた位取り記数法を十進位取り記数法、別名十進法と呼び、後者のように二種類の数字を用いた位取り記数法を二進位取り記数法、別名二進法と呼ぶことになりました。
ところでこの位取り記数法の大きな特徴としては、**「同じ数字でも書かれた場所によって異なる意味を持つ」**というものがあります。
つまり、例えば十進法の場合、各位置ごとに10の累乗の重みが付与され、その10の累乗を単位として「桁上がり」が発生することになるのです。
イメージしやすいように先ほど例であげた「128」で考えてみると、次のようになります。

これと同様に、二進法の場合も2の累乗を単位として「桁上がり」が発生します。
具体的には右から順に2の0乗、1乗、2乗……というような重みが付加されることになるのです。
【補足】
この特徴によりアラビア数字は
・どれだけ大きな数であっても理論上表すことが可能
・二つの数字を縦に並べた際、各位が一列に揃うため計算しやすい
と言う他の表現法にはない大きなメリットが得られました。
またこうしたアラビア数字のような表現方法が考案された背景としては、アラビア数字以前は「数をまとめる」という発想はあったものの、
・大きな数字が出てくるたびに新しい記号が必要
・数字の長さが長い方が大きい数を表していないため、数の大きさが比べにくい
というクリティカルな問題を抱えていたことが大きいそうです。エジプト数字なんかがその典型例です。
(この辺りの話を詳しく知りたい方は、ドゥニ・ゲージ「数の歴史」などを読むことをおすすめします。)
5-2. 機械語とアセンブリ言語
私たちが普段書くプログラムは、当然ですがそのままの状態ではコンピュータで実行されません。
これはコンピュータは人間のように「文字の羅列を読み取って解釈し、実行する」ということができないためで、そのためコンピュータに命令を出す場合、人間が普段読み書きする文字とは別の手段で命令を伝える必要があります。
このコンピュータにわかるような形で記述された命令のことを機械語と呼び、この機械語は通常0と1だけで記述されます。
以下はC言語のサンプルプログラムを機械語とアセンブリ言語に変換したものです。
(アセンブリ言語はこの後すぐに説明します。)
各行に機械語命令とそれに対応するアセンブリ言語・C言語プログラムが表示されています。
機械語の中に0と1以外の数が並べられているのは16進数で表記しているためです。
void func(void) {
int val = 0;
val++;
}
void func(void) {
0: 55 push ebp
1: 89 e5 mov ebp,esp
3: 83 ec 10 sub esp,0x10
int val = 0;
6: c7 45 fc 00 00 00 00 mov DWORD PTR [ebp-0x4],0x0
val++;
d: ff 45 fc inc DWORD PTR [ebp-0x4]
}
10: 90 nop
11: c9 leave
12: c3 ret
この例から見ても、機械語とはただの数値の羅列であり、人間がパッと見で理解できるものではないことがわかります。
上記のC言語のように、我々人間が普段用いている言葉に似たプログラミング言語を高水準言語と呼びます。
また高水準言語で書かれたプログラムは、プログラムを実行する際に機械語に翻訳されます。
その翻訳作業のことを「コンパイル」と呼び、翻訳のためのプログラムを「コンパイラ」と呼びます。
さてここで**「アセンブリ言語」**という言葉が出てきましたので、簡単に説明しておきましょう。
アセンブリ言語とはざっくりいうと、「機械語を人間にもわかるような形に置き換えた言語」のことです。
機械語で書かれたプログラムは、先ほどの例にもあるように通常0と1の羅列であるため、それぞれの数字が何を意味しているのか判断することが我々人間には非常に難しいです。
そこで、この0と1の羅列を人間が分かりやすいように、その機能を表す英語に似たニックネームをつけて区別する方法が考案されました。
例えば、加算を行う機械語にはadd、比較を行う機械語にはcmpという略語をつけます。
この略語のことをニーモニックと呼び、そしてニーモニックを使ってプログラムを記述する際に用いられる言語のことをアセンブリ言語と呼びます。
アセンブリ言語は扱う上で大事なポイントが二つあります。
一つ目は、人間用に作られたものであるため、アセンブリ言語で記述されたソースコードであっても最終的には機械語に変換しなければコンピュータは実行することはできないということです。
アセンブリ言語は機械語と同じことを表していますが、コンピュータ用ではありませんので当然と言えば当然です。
ちなみにこの変換のためのプログラムをアセンブラと呼び、アセンブリ言語から機械語に変換することをアセンブルすると言います。
二つ目が、アセンブリ言語で記述されたソースコードと機械語は1対1に対応しているということです。
アセンブリ言語は機械語を読みやすくするために考案された言語であるため、機械語と1対1に対応しているのは当然ですね。
またこの性質を利用して
「アセンブリ言語で記述されたプログラムを読みながら、コンピュータの生の動きを調べる」
ということが低レイヤの勉強をするときには非常に有効になってきます。
(書籍やネット上の低レイヤ関連の記事なんかでもこの手法はよく用いられます。)
ちなみに機械語とアセンブリ言語は1対1に対応するため、機械語からアセンブリ言語に逆変換することも可能です。
このような機能を持った逆変換プログラムのことを逆アセンブラと呼び、逆変換することを逆アセンブルすると言います。
(アセンブリ言語についてもう少し詳しく勉強したい方はこちらのQiitaの記事が非常に参考になります。)
5-3. CPU
では先ほど挙げた「機械語プログラム」は一体どのようにしてコンピュータで実行されるのでしょうか?
これを知るためには、まずはCPUの仕組みについて知る必要があります。
まずCPUとはCentral Processing Unitの略で、日本語で**「中央処理装置」**と呼ばれており、その名の通りコンピュータの中枢として活躍しています。
よく入門書などで**「コンピュータの頭脳」**と書かれていますが、まさにその通りでコンピュータはCPUを中心に動いています。
ではそのCPUは一体どういう仕組みで動いているのでしょうか?
ここではざっくりした動きのイメージを掴んでもらうため、あえて比喩的な表現を用いながら説明させていただきます。
実際のCPUは内部で電気回路が動いていてもっと複雑なんですが、ここでは理解しやすいようにあえてそういった回路の話は抜きに進めさせていただきます。
まずCPUというのを一つの作業場として考え、その中にそれぞれ自分の役割を持った人が働いているとします。
ちなみに作業と言っても「自分たちで自立して考えながら行う作業」ではなく、「外部から与えられた命令に従って行う作業」というイメージを持っていてください。
では作業場が円滑に動くためには、どんな人がいればいいでしょうか?
真っ先に思いつくのは、外部からの命令を実行する人ですね。
具体的には、外部の命令に従って「計算」を行う役が必要になってきそうです。この「計算役」にあたる部分は一般的に**「演算装置」**と言われます。

次に、外部とのやりとりを担当する人も必要そうです。
具体的には、**「外部から命令やデータを送ってもらう」「外部にデータを送り出す」**といったことを行う役が必要です。
こういった「外部との交渉役」にあたる部分は**「制御装置」**と呼ばれます。

この制御装置ですが実は、「外部との交渉役」だけでなく、**「現場の責任者」**も担当しています。
具体的には、**「外部からの命令を解釈して、計算役に指示する」**といったことも行っているのです
これは簡単に言うと命令を見て、実際に作業を行う人に対して「おい出番だぞ!!」と伝えるようなイメージです。
つまり、制御装置は「交渉役」かつ「現場監督」であり、計算以外の処理を全て担当しているというわけです。
いわば敏腕マネージャーみたいなもので、この制御装置がいるおかげで、演算装置は計算に専念できるというわけですね。
さて、これで作業は進みそうに見えますが、もっと効率的に作業を行えるようにするためには、実はもう一人重要な役が必要になります。
それは**「作業場のみんなに一定の間隔で作業を行わせる役」で、こういった役を担う人を「クロック」**と呼びます。
具体的には、**「はい!作業始め!」と指示を出しみんなに決められた量の作業をさせ、一定時間が経過した後に「そこまで!」と時間を区切り、また次の作業を「作業始め!」と言って始めさせる...**といったことを行います。
一見必要なさそうに見えるこの役ですが、CPU内部には様々な役割を持った装置があるため、それらの動きを統一するためにはどうしても必要になります。
クロックがないと、みんなバラバラに動き出してしまうため、作業がちゃんと進まなくなってしまいます。
簡単に言うと、クロックは指揮者みたいなものですね。

さて、ここまでCPUという作業場で実際に作業を行なったり、外部とやり取りをする「人」に着目して見てきましたが、今度は「人」ではなく、作業場にある設備について見ていきましょう。
人間の場合でも仕事や作業に使われる部屋には、必要になるものを置いておくためのスペースがあります。
それと同様に、CPU作業部屋の中にも
- 「これから演算に使用するデータを置いておく場所」
- 「計算との途中結果や最終結果を置いておく場所」
- 「外から取ってきた命令を置いておく場所」
などがあります。
こうした場所を**「レジスタ」**と呼びます。
制御装置は、外から取ってきた命令やデータをレジスタに置きますし、演算装置はレジスタに置かれたデータに対して計算を行い、計算結果をまたレジスタに置きます。そしてその計算結果を制御装置が外に持っていきます。

前節のサンプルコード中に登場したebpやespもレジスタを指します。
具体的には以下のような役割を持ったレジスタが存在しています。
| 名前 | 別名 | 主な役割 |
|---|---|---|
| eax | アキュムレータ | 値を累積する |
| ebx | ベース | メモリ番地を記憶する |
| ecx | カウンタ | 文字列の添字やループの回数を数える |
| edx | データ | I/O装置の番地を記憶する |
| esi | ソースインデックス | 入力データの添字を記憶する |
| edi | デスティネーションインデックス | 出力データの添字を記憶する |
| esp | スタックポインタ | スタックの先頭を指す |
| ebp | ベースポインタ | スタック上の何らかのデータを指す |
| eip | 命令ポインタ | 現在実行中の命令の番地を指す |
| eflags | フラグレジスタ | 演算結果やCPUの状態などを指す |
一つ注意して欲しいのがCPUの種類が異なれば、その内部にあるレジスタの数や種類、レジスタに格納できる値のサイズが異なるということです。
例えば、上にあげたレジスタの名前はx86固有のもので、他のCPUには適用されません。ただ、大雑把に分類するならほぼ表のように大別できると考えていいかと思います。
このうちeipやeflagsは特殊レジスタと呼ばれ、単純に「ものを置いておく場所」という役割の他に、作業の状態を表示する「掲示板」みたいな役割を果たします。
例えば、「次に○番目の作業を行います」のように、次に実行する命令番号を表示したり、「さっきの計算結果はプラスではなく、マイナスになりました」のように、計算の途中結果を表示したりします。
このように特殊レジスタは、レジスタによってそれぞれ固有の役割が存在し、CPUの動作を司る重要な役割を担っています。

ここまででわかる通り、CPU内部には様々な役割を持った装置が存在しており、それらがお互いに協力し合いながらプログラムを実行しているのです。
(以下はイメージ図です。)

5-4. メモリ
前節でCPUについてざっくり説明してきましたが、今度は先ほどのCPUがやり取りしてた「外」について見ていきましょう。
「外」といっても実は二つ存在していて、一つは**「メモリ」と呼ばれるもの、もう一つはキーボードやディスプレイ、HDDなどのいわゆる「周辺機器」**と呼ばれるものです。
そして、先ほどCPUが命令を送ってもらったり、あるいは逆にデータを送ったりして直接やり取りしていたのは、この「メモリ」になります。
つまり、コンピュータはメモリにデータやプログラムが格納されていて、それらがCPUに順次読み出されて実行されていくという仕組みで動いているのです。
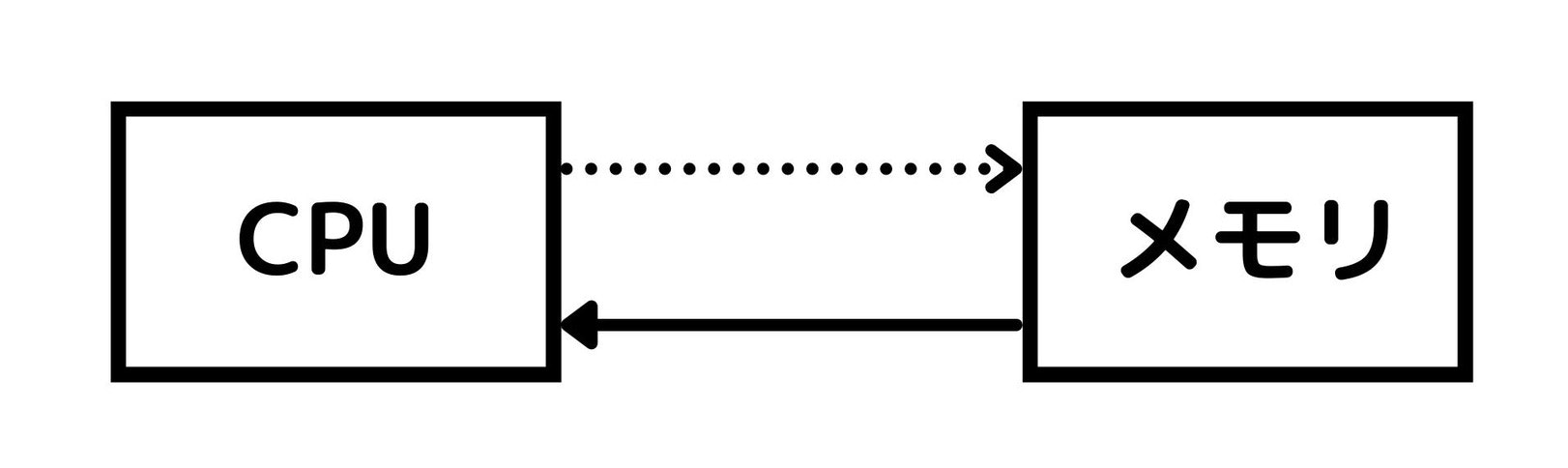
さて、ではなぜプログラムの実行に外部の「メモリ」がわざわざ必要なのでしょうか?
レジスタにデータやプログラムを格納しながら、作業してはいけないのでしょうか?
この理由は様々なものが考えられますが、その一つとして**「単一の記憶媒体で、高速大容量かつ不揮発性を兼ね備えたものが存在しないから」**というものがあります。
少し詳しく解説しておくと、通常メモリやレジスタなどは**「記憶装置」と呼ばれ、その名の通りデータやプログラムの「記憶」に使われる装置**になります。
そして、この記憶装置には色々な種類があって、一般にコンピュータにおける記憶装置は以下のような階層構造を取っていることで有名です。
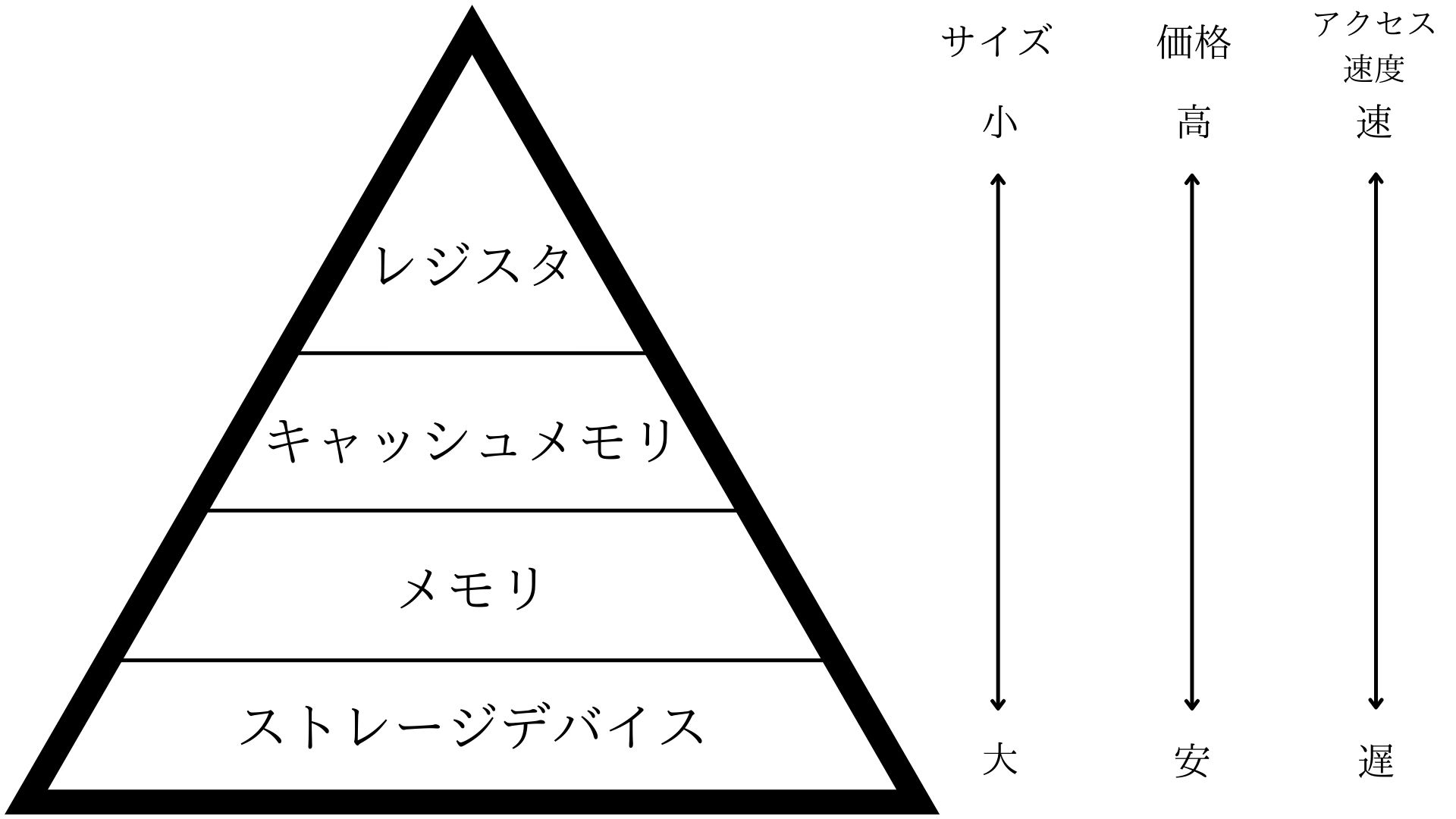
これは、図の上層ほどサイズが小さく、単位バイト当たりの価格が高価な反面、アクセス速度が高速だということを示しています。
ここから大規模で複雑な作業を要求される現代のコンピュータでは、サイズの小さいレジスタを記憶装置として使用するのは不可能に近いことがわかるでしょう。
例えばLinuxカーネル(OSのプログラム)だと、そのソースコードは2000万行を超える大規模なものとなってしまい、物理的な面でも金銭的な面でもレジスタに格納することはほぼ不可能です。
そのため、
- ある程度の容量を持っている
- 金銭的にまだ安い
という特徴を持つメモリにスポットが当たったわけです。
このメモリを用いることで、先ほどのレジスタの問題はほぼ解消され、例え複雑な作業を要求されたとしてもある程度対応可能になります。
とはいっても、メモリとレジスタだけでは実はまだ**「データが保存できない」という致命的な欠陥を抱えています。**
データが保存できないと、作業をしている途中に何かしらのトラブルでコンピュータが動かなくなったり、電源が切れてしまった場合に、作業結果が全て消えてしまうということになってしまいます。
そんなコンピュータだと安心して作業することはできませんし、何よりめちゃくちゃ不都合ですよね。
これは、メモリとレジスタは両方とも電源を切ると中身がなくなってしまう、いわゆる**「揮発性」**という特徴を持っていることに起因しています。
そのため、作業の結果を保存できるようにするためには、電源が切れても中身がなくなってしまわない**「不揮発性」**の特徴を持つ記憶装置が必要になってきます。
それが先ほどの図の一番下にあるストレージデバイス、つまりHDDのようなデバイスなのです。

このストレージデバイスがあることにより、コンピュータはデータを保存でき、電源が切れたとしても記憶は残るし、また次に電源を入れたときに読み出すことも可能になります。
5-5. プログラム実行までの流れ
では先ほどまでの内容を踏まえた上で、「機械語プログラム」が実行されるまでの流れを簡単に見ていきましょう。
基本的には先ほども説明した通り、
①CPUがメモリからプログラムを読み取る
②プログラムを実行する
という一連の流れを繰り返します。
この過程の中で、先ほども説明したCPUの作業場の人たちがそれぞれ活躍していくわけです。
では、この①、②の過程についてもう少し詳しく見ていきましょう。
まず、先ほどの①、②の過程は細かく見ていくと3段階に分かれていて、各段階を
- フェッチ
- デコード
- 実行
と呼びます。
まずフェッチですが、これは英語のfetchから来ており(Gitを使ったことがある人はgit fetchなんかでお馴染みかもしれません。)日本語で**「取り出す」**という意味になります。
つまり、フェッチは**「メモリからプログラムを取り出して、CPU内部に取り込む」**ということを行っているのです。
具体的には、eipレジスタに格納された番地(掲示板に書かれた番号と思えばいいです。)のメモリ領域から機械語命令を取り出して、CPU内部へ送ってもらうということを行っています。
これを担当しているのは、もちろん**"外部との交渉役"である「制御装置」**になりますね。
そして、次にデコードですが、これは**「命令を読み取り、必要な装置に出番を伝える」**ということを行います。
具体的には、「機械語命令から、実際のCPU内部の回路を制御する信号を作り出す」ということを行なっています。
例えば、加算命令の場合、デコードすると演算装置が必要なことがわかるので、演算装置に信号を送ります。
これも、先ほどのCPUの説明から**「制御装置」**が行うことが予想できるでしょう。
そして最後の実行ですが、これはその名の通り**「読み取った命令を実行する」**ということを行います。
具体的には、「回路を動作させ、演算したりメモリを読み書きしたりする」ということを行っています。
先ほどの加算命令なら、加算を実行します。
これには、もちろん演算装置が活躍しますね。
そして、プログラムの実行が終わると、自動的にeipレジスタ(掲示板に書かれた番号)が1つ増加し、次の命令へと移ります。
このように、プログラムはCPUとメモリが連携し合いながら実行されていくのです。
5-6. 条件分岐
前節の「プログラム実行までの流れ」で、勘の良い人はこんな疑問を持ったかもしれません。
プログラムの動作の説明で、命令ポインタ(eip)がCPUの動作を司る重要な役割を担っていることはわかったけど、もう一つの特殊レジスタのフラグレジスタは何に役立っているのか?
実はフラグレジスタにもちゃんとした役割が存在していて、これは**「状況に応じて命令の流れを変える」**ということを可能にしています。
これだけでは意味がわからないと思うので、詳しく解説していきます。
先ほどさらっと説明しましたが、通常次のプログラムの実行に移る際、命令ポインタ(eipレジスタ)の値は自動的に1つ増えます。
そのため、基本的にプログラムはメモリーに記憶された下位アドレス(小さい番地)から上位アドレス(大きい番地)に向かって流れていきます。
このようなプログラムの流れを**「順次進行」**と呼び、みなさんが書いたコードが基本的に上から順に実行されるのはこれが理由です。
しかし、コンピュータにもっと複雑なプログラムを実行させるためには、「順次進行」だけでは足りません。
身近な運動会のプログラムを例に考えてみましょう。
運動会のプログラムは通常
- 入場
- 校長先生の開会の挨拶
- 宣誓式
- 準備体操
- 1年生100m走
- ...
- ...
のように段取りが組まれていますが、このプログラムは状況によって変えたい部分なども発生してきます。
例えば、表彰式などは
「どのクラスが優勝したか?」
「どの組が優勝したか?」
によって変える必要があります。
これがもし順次進行しかできない場合、「必ずA組が優勝」ということになってしまい、大変なことになってしまいます。
このように、状況によってプログラムの流れを変えない限りは、複雑なプログラムを作り上げることは不可能なのです。
では、もし優勝したクラスによってプログラムの流れを変えたい場合実際どのようにしたら良いでしょうか?
ここで必要になってくるのが「条件分岐」です。
つまり、
①A組が優勝した場合
- ...
- ...
② B組が優勝した場合
- ...
- ...
というプログラムが組めたら先ほどの問題は解決されるのです。
こうすれば、状況に応じてプログラムの内容を変更できますし、また様々な状況を加味したもっと複雑なプログラムにも対応できるようになります。
さて、話をコンピュータに戻しましょう。
このような「条件分岐」を可能にするのが**「フラグレジスタ(eflags)」**なのです。
以下にフラグレジスタを使って具体的にどのように条件分岐が行われているのか?をサンプルプログラムを用いて説明していきます。
まずCPUは何かしらの計算が終わる度に、フラグレジスタに計算結果の状態を書き込みます。
例えば、減算命令の場合、計算結果が+だったら「プラス」と書き込むし、ーにだったら「マイナス」と書き込みます。
実際はもっと複雑な仕組みになっています。詳しい説明は書籍の方に書いていますので、そちらを参照してください。ここではわかりやすくするため、かなり簡略化しています。
そして、この「フラグレジスタ」の値を書き換えた後に**「条件付きジャンプ命令」**を実行します。
これはジャンプ命令の一種で、フラグレジスタの状態に応じてジャンプ命令を実行するかしないかが決まる命令です。
まずジャンプ命令について簡単に説明しておくと、これは命令レジスタの値を指定した値に書き換える命令となります。
先ほどのCPUの図でいうと**「掲示板の内容を勝手に書き換える」**ということを行う命令です。
つまり、これによりプログラムの流れを「順次進行」から変更することができるのです。
以下はジャンプ命令を用いた簡単なサンプルプログラムです。
int abs(int i) {
if (i >= 0)
{
return i;
} else
{
return -i;
}
}
0: 55 push ebp
1: 89 e5 mov ebp, esp
3: 83 7d 08 00 cmp dword [ebp+0x8], byte +0x0
7: 78 05 js 0xe
9: 8B 45 08 mov eax, [ebp+0x8]
C: E8 05 jmp short 0x13
E: 8B 45 08 mov eax, [ebp+0x8]
11: F7 D8 neg eax
13: 5D pop ebp
14: C3 ret
二つめの機械語とアセンブリ言語で書かれたプログラムを見てください。
この6行目にjmpと書かれていますが、これが最も単純なジャンプ命令になります。
(ジャンプ命令にも色々種類があります。)
jmpは無条件に指定された番地までジャンプする命令で、今回の例だとオペランドに指定された0x13番地(pop ebp)までジャンプします。
そして、4行目にあるjsが**「条件付きジャンプ命令」**です。
jsはjmp if signの略で、フラグレジスタがマイナスの場合に指定した番地までジャンプします。
今回の例だと、前の行でcmp命令が実行されており、これによりフラグレジスタの値が書き変わり、その内容にしたがってジャンプ命令を実行するかどうかを決めます。
もし、cmp命令でフラグレジスタが書き換えられたら、ジャンプ命令により0xe番地(mov eax, [ebp+0x8])までジャンプします。
つまり、まとめると条件分岐は
①フラグレジスタの値を書き換える(サンプルプログラムだと、cmp命令で書き換えを行う)
②**「条件付きジャンプ命令」を実行する**
という一連の動作を経て、実行されていることになります。
このように、コンピュータへの命令は常にメモリに格納されている順番で実行されているわけではなく、ジャンプ命令を駆使しながら命令の流れを柔軟に変更して行われているということなのです。
そしてこれにより、コンピュータは非常に複雑な作業も実行できるようになるのです。
6. 次に挑戦したいこと
最後に次にやってみたいことですが、今の時点で「CPUが内部でどんな風に動作しているのか?」のイメージをざっくり掴むことはできたのですが、
「じゃあどうしてCPUがそういった命令を実行できるのか?」
「そもそもコンピュータはどうして加算命令や減算命令を実行できるのか?」
といった根本的なところがわからないままの状態で少し気持ち悪いので、次は論理回路やVHDLの勉強をしつつ、ハードウェア的なエミュレートもしていけたらいいかなと思っています。
具体的には名著「CPUの創りかた」あたりにチャレンジしていけたらいいなと思います。
また、周辺機器とのやりとりもあまり扱われていなかったので、Linuxカーネルの勉強も同時並行的に進めていけたらいいなぁとも思っています。
低レイヤ最高。
7. おわりに
本記事の内容がみなさんの参考になれば嬉しいです。
最後までご覧いただきありがとうございました。
8. 参考文献
- 自作エミュレータで学ぶx86アーキテクチャ
- コンピュータはなぜ動くのか?
- プログラムはなぜ動くのか?
- キタミ式イラストIT塾 基本情報技術者
- コンピュータ、どうやってつくったんですか? はじめて学ぶ コンピュータの歴史としくみ