対象読者
- アセンブリに触れてみたい!という初心者の方
- メモリ、アドレスといった専門用語、C言語の簡単な文法(intやprintf)がわかる(ググって調べることができる)
目標
- ソースコード, .sファイル, 実行可能ファイル, バイナリ, アセンブリ, リンカ, コンパイラの違い、関係が分かる
- x86_64(amd64)の簡単な代入命令、算術命令(四則演算)が読めるようになる。
筆者
- バイナリ初心者。最近CTFが楽しい。
- まだまだ分からないことが多いので、間違いの指摘などよろしくお願いします。
1. はじめに
まず、Compiler Explorer( https://godbolt.org/ ) にアクセスしてください。
このウェブサイトでは左側に打ち込んだソースコードが、右側でアセンブリなどに変換されます。
左側の言語選択でCを選択し、以下のソースコードをコピペしてください。
内容は以下のように、1+2を計算して出力するプログラムです。
# include <stdio.h>
int main()
{
int a=1;
int b=2;
printf("%d\n", a+b);
return 0;
}
右側に自動的にアセンブリが表示されたと思います! 🐡🐡🐡
ではアセンブリを見てみましょう。
.LC0:
.string "%d\n"
main:
push rbp
mov rbp, rsp
sub rsp, 16
mov DWORD PTR [rbp-4], 1
mov DWORD PTR [rbp-8], 2
mov edx, DWORD PTR [rbp-4]
mov eax, DWORD PTR [rbp-8]
add eax, edx
mov esi, eax
mov edi, OFFSET FLAT:.LC0
mov eax, 0
call printf
mov eax, 0
leave
ret
…何が書かれているか分かりませんね。
というわけで、今回は最終的に、このアセンブリがなんとなく読めるようになることを目標にします。
それでは前提知識を説明していきます。はじめに、アセンブリなどの用語の説明をしていきます。
2. 前提知識
用語説明
まず、それぞれの言葉を説明します。
- バイナリ: 0と1で書かれたデータ形式(機械語よりも広い概念)
- 機械語: 0と1で書かれた、CPUが直接理解できる言語
- アセンブリ: 機械語を、人間が見やすいようにそれぞれの命令を一対一に対応させた言語
- ソースコード: 人間が理解できる言語のコード(機械語に変換される)
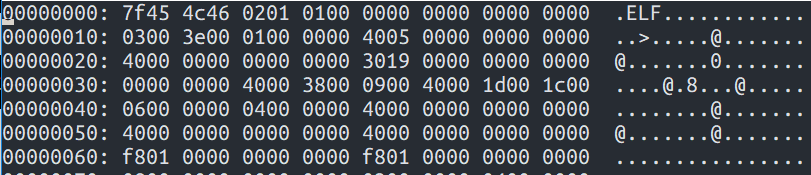
バイナリ、機械語はバイナリエディタやvimで見ることができます(0と1だと桁数が大きくなりすぎるため、16進数で表現していることが多いです)
以下の図は実際にバイナリを見た時の様子で、: の左側がアドレス、真ん中がバイナリの16進数表現、一番右はそのASCII表現になっています。
- .s ファイル: アセンブリの書かれたファイル(これが、Compiler Explorerで右側に表示されているものに当たります。)
- .o ファイル: オブジェクトファイル
- 実行可能ファイル: 機械語で書かれたファイル
- リンカ: オブジェクトファイルを、他のライブラリなどとつなげて実行可能ファイルに変換するプログラム
- コンパイラ: ソースコードをアセンブリに変換するプログラム
説明文だけでは苦しいので、以下の図を見てみましょう。C言語で書かれたソースコードを実行ファイルに変換しています。
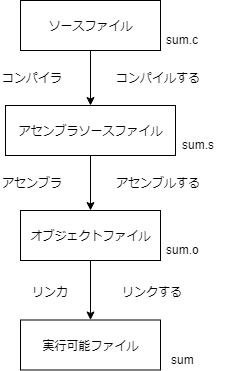
- まず、ソースコードが書かれたファイル(ソースコードファイル)を作る(sum.c)
- コンパイラが、ソースコードファイルをコンパイルしてアセンブリを生成(sum.s)
- アセンブラが、アセンブリをアセンブルしてオブジェクトファイルを生成(sum.o)
- リンカが、オブジェクトファイルにライブラリなどをくっつけて実行可能ファイルを生成(sum)
(本当は1→2の段階でコンパイラは多くの作業を行っています。詳しくは http://0x19f.hatenablog.com/entry/2018/05/08/220516 の"コンパイルの処理の流れ"を見てください。)
おおまかには1~4の流れでソースコードが実行可能ファイルに変換されます。
アセンブリの読み方
では次に、アセンブリの読み方について学んでいきましょう。
- 構文(各パーツの名称と説明)
- 命令(代入、四則演算を表す命令の説明)
- メモリやレジスタの仕組み(eax, edxなどはここで説明)
の3点を押さえれば少しずつ読めるようになります!まずは構文から。
構文
構文にはIntel記法とAT&T記法があります。今回はIntel記法を説明します。eax, edxは変数のようなものだと思ってください(後で詳しく説明します。)
add eax, edx
上のように、
<Mnemonic> <Destination>, <Source>
の順に並んでいます。
- Mnemonicは命令
- Destinationは値を受け取る領域のアドレス
- SourceはDestinationに作用する値、または値の入っている領域のアドレス
難しいので、例を挙げます。
addは加算を表します。
add eax, edx
これは、”edxの値を、eaxの値に加えて、eaxに格納する”という意味になります。eaxの値が2, edxの値が1とすると、この命令によってeaxの値が3(=1+2)に変化し、edxの値は変化せず1となります。

命令
ここでは代入命令と、算術命令の一部のみ触れます。他にもたくさんの命令があるのでhttp://milkpot.sakura.ne.jp/note/x86.html などを参考にしてみてください。(自分でfor文などを含むC言語ファイルを作ってそれをアセンブリに変換して、眺めてみて分からない命令を調べてみるとおもしろいです)
- 代入命令
mov
movはMOVeを表します。
mov <destination>, <source>
sourceの値(アドレス、もしくは値)をdestinationにコピーして入れる操作。例えば、mov eax, 2なら、eaxに2を入れて、eax=2になります。 mov eax, ebx なら、ebxに格納されている値をeaxに入れることになります。
lea
leaはLoad Effective Addressを表します。
lea <destination>, <source>
ここで、Effective Addressについて簡単に説明します。
Effective Addressは、以下の図のように、4つの部品から成り立っています。

Base, Indexにはレジスタの値が入り、ScaleとDisplacementには数値が入ります(すごく雑な説明なので、詳しくはIntel SDMの1, 3.7.5 Specifying an Offsetの項を見てください)
このようにして計算された値をEffective Addressと言います。
leaは、sourceの値(ここがEffective Addressに当たります)をdestinationにコピーして入れる操作。例えば、ebx=3のとき、 lea eax, [ebx] なら値3がeaxに入ります。(このとき、Effective Addressは3(=ebx)になります)
movとleaの違いについて
movとleaの違いはとても難しいのでここで取り上げます。
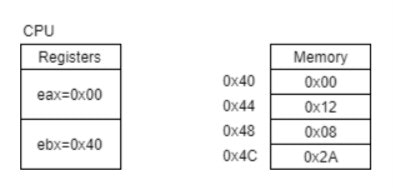
上はCPUの中のRegisterとMemoryを簡単に表しています。(CPU, Register, Memoryについてはメモリやレジスタの仕組みで詳しく説明します。)
mov eax, [ebx+8]
lea eax, [ebx+8]
の違いを考えてみましょう。
movもleaも、[アドレス] という形でメモリアクセスをする書き方になっています。
- movは実際にメモリアクセスが行われます。ここでは
ebx+8、つまり0x48にあるデータ0x08が読みだされ、eaxに格納され、eax=0x08となります。 - leaはメモリアクセスが行われません。
[]内のアドレス値がそのままeaxに読みだされます。つまり、eax=0x48となります。
- 算術命令
add
addはADDを表します。
add <destination>, <source>
sourceの値をdestinationに足して、destinationに入れる操作。例えば、eax=2, ebx=3で add eax, ebx なら、eaxにebxを足してeaxに入れるのでeax=5, ebx=3となる。
sub
subはSUBtractを表します
sub <destination>, <source>
sourceの値をdestinationから引いて、destinationに入れる操作。例えば、eax=4, ebx=2で sub eax, ebx なら、eaxからebxを引いてeaxに入れるのでeax=2, ebx=2となる。
imul
imulはInteger MULtiply (signed)を表します。signedは符号付き(負の値も扱う)という意味です。
imul <destination>, <source>
sourceの値をdestinationに掛けて、destinationに入れる操作。例えば、eax=3, ebx=2で imul eax, ebx なら、eaxにebxを掛けてeaxに入れるのでeax=6, ebx=2となる。
idiv
idivはInteger DIVide (signed)を表します。
idiv ebx
eaxの値をebxで割り、商をeax, 余りをedxに入れる操作。例えば、eax=5, ebx=3で idiv ebx なら、eax=1, ebx=3, edx=2となる。
idivについて詳しく(2の補数における符号拡張)
実際はidivはもう少し複雑な構造をしています。このあと説明するメモリやレジスタの仕組みを読んだ後にここを読むとさらに理解が深まると思います。
https://www.felixcloutier.com/x86/idiv を参考にすると、上のidiv ebxは以下のような流れで計算されます。
(まず、idiv命令が実行される前に、別の命令によりedxが設定されます)
次に、edx:eaxをebxで割り、商をeax, 余りをedxに入れます。
ここで、edx:eaxはedxとeaxをつなげたものです。edxは符号拡張のため初期化されているので、eaxの最上位のビットで埋められます。
eax = 0x00000005ならば最上位ビットは0なのでedx:eax=0x0000000000000005となります。
eax=0xfffffffb(-5)ならば、最上位ビットはfなので、edx:eax=0xfffffffffffffffbになります。こうすることで、符号が拡張されても2の補数で見ると数字が変化することはありません。
今回は、eax=5なので、edx:eax=0x0000000000000005をebx=3で割って、eax=1, ebx=3, edx=2となります
メモリやレジスタの仕組み
次は、eaxやebxといったものが何を指すのか説明します。
用語説明のところで、ソースコードが機械語で書かれた実行可能ファイルに変換される過程は分かりました。では、コンピュータはどのようにして機械語から処理を行っているのでしょうか?
機械語から処理を行うまでには、CPUとメモリが関わっています。
- CPU: 演算処理を行う。この中にレジスタがある。
- メモリ: 情報を記録しておける。
一般に使われているコンピュータは”ノイマン型コンピュータ”と呼ばれていて、ノイマン型コンピュータには二つの特徴があります。
- プログラム内蔵方式: プログラムを主記憶装置(メモリ)の中に書き込んでおく。
- 逐次制御方式: CPUが主記憶装置からプログラムの命令を読み込み、順に実行する
まとめると、メモリに書き込まれた機械語が、CPUによって順に実行されていく、という流れになっています。
ではここまでを踏まえて、レジスタの役割と、eax, ebxなどが何を指すのか見ていきましょう。
レジスタ
ここでは紛らわしいので以下のように区別します
- レジスタ: raxレジスタ、rbxレジスタ…といった個別のもの。
- レジスタ(領域): レジスタから構成される領域。
レジスタ(領域)はCPU内に存在し、CPUの演算に欠かせないものです。データを一時保持する役割を持っていて、高速にやり取りできることが利点です。ここでは、演算をするときに重要なレジスタの一部(rax, rbx, rcx, rdx, rip, rbp, rsp)を紹介します。他のレジスタについては、 http://milkpot.sakura.ne.jp/note/x86.html を見てください。
汎用レジスタ
rax
raxの構造は以下のようになっています。
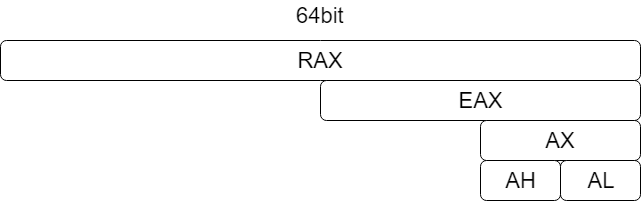
raxは64bitあり、その下位32bitがeaxレジスタ、そのさらに下位16bitがaxレジスタ、その上位8bitがahレジスタ、下位8bitがalレジスタとなっています。
raxのAは、Accumulator(累算器)のAです。ここには演算の戻り値が記録されることが比較的多いです。
rbx
rbxも同じように、その下位32bitがebxレジスタ、そのさらに下位16bitがbxレジスタ、その上位8bitがbhレジスタ、下位8bitがblレジスタという構造になっています。
rbxのBは、Base addressのBです。ここにはメモリのアドレスが記録されることが比較的多いです。
rcx
rcxも同じように、その下位32bitがecxレジスタ、そのさらに下位16bitがcxレジスタ、その上位8bitがchレジスタ、下位8bitがclレジスタという構造になっています。
rcxのCは、Count registerのCです。ここにはループの回数(カウンタ値)などが記録されます。
rdx
rdxも同じように、その下位32bitがedxレジスタ、そのさらに下位16bitがdxレジスタ、その上位8bitがdhレジスタ、下位8bitがdlレジスタという構造になっています。
rdxのDはData registerのDです。ここには割り算の余りなどのデータが記録されます。(命令のidivを思い出してください。)
特殊なレジスタ
残りのrip, rbp, rspについて説明します。これらはメモリのアドレスを記録しておくためのレジスタです。
まず、ノイマン型コンピュータではメモリからプログラムの命令を読み込み逐次実行していきます。では、メモリのどの部分に何が書き込まれているのか見ていきましょう。
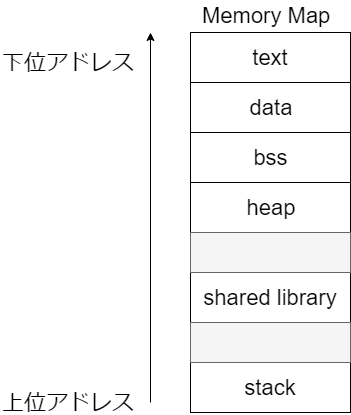
text領域には機械語で命令が書かれていて、ここから一命令ずつ読みだしてCPUで実行しています。
stack(スタック領域)はスタックと呼ばれるデータ構造をしています。図で上の方が小さいアドレスで、下の方(底の方)に行くにつれてアドレスの値は大きくなります。今回は、このstackに注目します。
stackは、変数や関数呼び出しに使われます。スタックやヒープについてより詳しく知りたい場合は https://keens.github.io/blog/2017/04/30/memoritosutakkutohi_puto/ がお勧めです。
stackには、スタックフレームという単位でデータが積まれます。以下の図のように、アドレスが小さいほうからローカル変数、RBP、リターンアドレスという構造になっています。

- リターンアドレスは、現在実行中の関数から別の関数を呼び出したときに積まれます。これは、その呼び出した関数の処理が終了した後どのアドレスに戻ればいいかを指し示しています。
- RBPはこれから説明します。この関数が呼ばれる前の関数のベースポインタを指します。(pushという命令で積まれているのが分かります)
- ローカル変数は、その関数の中で使われる変数を指します。
rip
ripのipはInstruction Pointerの略です。次に実行する命令(Instruction)のアドレスを記録します。
rbp
rbpのbpはBase Pointerの略です。現在の処理のスタックフレームの底部分(base)のアドレスを記録します。
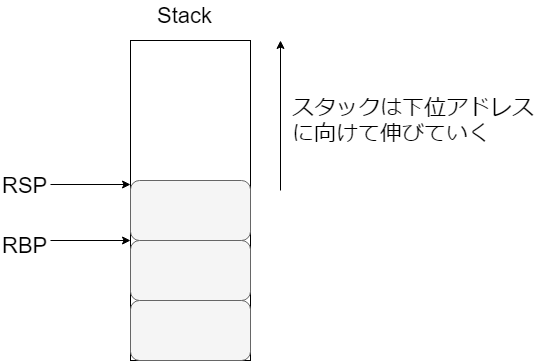
rsp
rspのspはStack Pointerの略です。スタック領域(stack)に積まれているデータのうちの一番小さいアドレスを記録します。
- 以下の図で、rspとrbpが指し示しているアドレスを示しています(メモリのアドレスの値が、レジスタの中に記録されています)
以上で前提知識パートは終了です。お疲れさまでした。
3.アセンブリを読んでいく
それでは、用語、構文、命令、メモリやレジスタの仕組みがだいたい分かったので、元に戻ってアセンブリを読んでみましょう!(触れていない部分は適宜補完します)
.LC0:
.string "%d\n"
- この部分は、
.LC0というラベルがつけられた領域です。LC0はLocal Constantの略で、文字列などの定数を表します。ラベルとは、メモリ上の場所を名前付けしたもので、コンパイル時にメモリのアドレスに変化します。たいてい、ドットではじまるラベルはコンパイラが用意したローカルラベルで、自分で定義した関数やmainだとドットが前につきません。 -
.stringはディレクティブと呼ばれます。ディレクティブはコンパイラが用意した、GNU assemblerに対する命令のようなものです(機械語と対応するものではありません)。今回は、GNU assemblerに文字列であることを示すために用いられています。 -
"%d\n"は文字列です。
main:
- mainラベルです。C言語での int main() 部分に対応します。
push rbp
mov rbp, rsp
sub rsp, 16
- この部分で、メモリのスタック領域に場所を確保しています。(Function Prologueと呼ばれています。)
以下、このFunction Prologueを一行ずつ説明します。
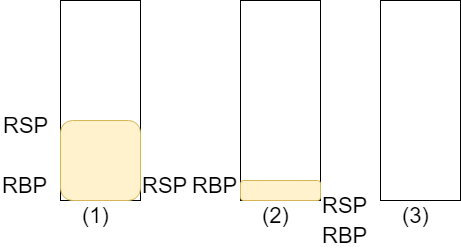
push rbp
- push命令は、レジスタの値をスタックに積みます。このとき、スタックの先頭であるrspも更新されます。(デクリメントされます)。ここでは、rbpをスタックに積んでいます。(このときのrbpはmain処理が始まった段階なので、main処理を呼ぶスタートアップと呼ばれる初期化過程で積まれた値が入っています。)
- 図では(1)→(2)
mov rbp, rsp
- rspをrbpに代入しています。図では(2)→(3)
sub rsp, 16
- rspから16を引いて領域を確保しています。図では(3)→(4)

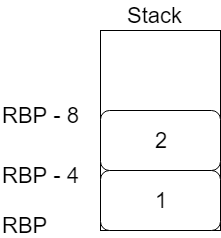
mov DWORD PTR [rbp-4], 1
mov DWORD PTR [rbp-8], 2
- この部分で、先ほど確保したメモリのスタック領域に数を代入しています。
-
DWORD PTR [xxx], numberは、4バイト単位でアクセスして、numberをxxxに代入することを表しています。 - つまり、スタック領域は以下のようになります。(stackは図で上の方がアドレスが小さくなることに注意)
mov edx, DWORD PTR [rbp-4]
mov eax, DWORD PTR [rbp-8]
- この部分で、演算を行うために、メモリからレジスタへと数を代入しています。
- edx=1, eax=2になりました。
add eax, edx
- この部分で、eax=2, edx=1 → eax=3, edx=1に変化します。
mov esi, eax
- ここから、printfするための準備を行います。関数の引数順に、使われるレジスタが決まっています。第一引数はediレジスタ, 第二引数はesiレジスタなので、
printf("%d\n", a+b);の第二引数になるesiにa+bの値eaxを代入しています。 - 引数とレジスタについて、詳しくは https://refspecs.linuxfoundation.org/elf/x86_64-abi-0.99.pdf のp.21を見てください。
. If the class is INTEGER, the next available register of the sequence %rdi, %rsi, %rdx, %rcx, %r8 and %r9 is used13 .
が該当箇所です。
mov edi, OFFSET FLAT:.LC0
- ここも同様に、printfの第一引数にstringを入れるために、ediに代入しています。
- OFFSET FLATは、データを記録したラベルを表示するときに前につけるものです。
mov eax, 0
- ここは、呼び出す関数がvector registerを使う数をeaxに代入しています。今回はprintfで整数を入れるので、0になります。詳しくは、https://stackoverflow.com/questions/6212665/why-is-eax-zeroed-before-a-call-to-printf を見てください。小数を扱う時にvector registerが使われるので、そのときにeaxが0以外になります。
call printf
- printf関数を呼び出しています。
mov eax, 0
- ここは
return 0;に対応しています。eaxは戻り値が入ることを思い出しましょう。
leave
ret
- ここはFunction Epilogueと呼ばれる部分です。leaveとretでFunction Prologueの逆の操作を行います。leaveで確保した領域を解放し、retで元の処理にもどるという流れです。
- leave命令は
mov rsp, rbp
pop rbp
を行っています。以下の図を見てください。
ベースのポインタをrspにコピーすることでスタック領域に確保していた部分を解放します。(1)→ (2)
その後、rbpをpopします。(2)→ (3)
- ret命令により、もとの関数の処理に戻ります。(今回はmain関数なので、main関数を呼び出した処理に戻り、直ちにexit()が呼ばれます。)
- main処理を呼び出す前、呼び出した後について、詳しくは https://www.atmarkit.co.jp/ait/articles/1703/01/news173.html を見てください。
以上でアセンブリを読み終えました。
この後は、知っている、またはググって理解できる命令を増やしたり、レジスタやスタックの使われ方について理解することでどんどんアセンブリが読めるようになっていくと思います。後は最適化とかあるんですが、そこは僕もよく知りません。お疲れさまでした!
最後に
Tksiさん、 えびちゃんさん、uchan_nosさん に記事の作成、修正を手伝ってもらいました。ありがとうございます!