こんにちは、qiitaに投稿するのは初めてなので緊張してます。プログラミング経験も浅いのでもっとうまくコードを書く方法もあると思いますが、その際はぜひご教授いただけると幸いです。
さて、私は最近メンタルの調子の波にちょっとやばみを感じています。今は、メンタルの調子が割といいのですが、逆に良すぎて羽目をはずすことが多いです。私は人として大丈夫なのでしょうか?
ということで、今回は形態素分析を使ってツイートからメンタルの良し悪しの変化を調べてみようと思います。形態素分解析というのは、文章を単語ごとに分けて、それを処理して分析する手法のことを言います。下図はmecabというツールを使って単語分けをしてみた例です。

さて、まずツイートを取得するのですが、この際方法が二通りあります。一つはtwitterAPIを用いる方法、もう一つはtwitterのアカウント設定から全ツイート履歴をダウンロードする方法です。前者は、ソースコードを少しいじるだけで様々な人のツイートを分析できるメリットがあるのですが、上限3400ツイートまでしか取得できないというデメリットがあります。後者は、すべてのツイートを取得できますが、アカウントのユーザー本人しかダウンロードできないというデメリットがあります。
私はツイ廃なので3400ツイートでは時間にして一年分しか解析できなかったので、今回は後者の方法でやってみたいと思います。
計算方法
osetiという先人の作ったライブラリを利用します。(詳しくは製作者様の記事へ→https://qiita.com/yukinoi/items/46aa016d83bb0e64f598) これに準じて計算をします。oseti.Analyzer.analyze(文章)の値をこの記事では以後ポジティブ度と呼びます。
下準備
まず、自分の全ツイートを取得しましょう。ツイッター公式の指示に従ってください。
ダウンロードしたらダウンロードしたファイルの中からtweets.jsというファイルを探してください。この中にあなたのツイートがすべて入っています。
(筆者はJavaScriptを勉強したことがないので以下の方法は非効率かもしれません。ご注意ください。)
さて、このファイルはリストの中に辞書がたくさん入っている形になっています。つまり[{},{},{}...]という形です。
# true=Trueを付け加える
# false=Falseを付け加える
window.YTD.tweet.part0 = [ { #←これをtweetsに変える
"retweeted" : false,
"source" : "<a href=\"http://twitter.com/download/iphone\" rel=\"nofollow\">Twitter for iPhone</a>",
"entities" : {
"hashtags" : [ ],
"symbols" : [ ],
"user_mentions" : [ ],
"urls" : [ ]
},
"display_text_range" : [ "0", "14" ],
"favorite_count" : "2",
"id_str" : "1183917914736381953",
"truncated" : false,
"retweet_count" : "0",
"id" : "1183917914736381953",
"created_at" : "Tue Oct 15 01:30:01 +0000 2019",
"favorited" : false,
"full_text" : "これがツイートの本文です",
"lang" : "ja"
}, #以下略
やることは5つです。
・window.YTD.tweet.part0とかいうよくわからない変数名を勝手に名付け直します。ここではtweetsと名付け直しました。
・これを読み込む時になぜかtrue,falseが変数とみなされるエラーが生じたので、文頭にtrue=True false=Falseと付け加えます。
・\uから始まるものは絵文字で、これを含む文を解析しようとするとバグるので置き換え等で消しておいてください。
・拡張子を.pyに変えておいてください。
・このファイルをメインのプログラムと同じ階層のディレクトリに移動する。
使用するライブラリ類
%matplotlib inline #jupyter notebookでやるならいるやつ
import oseti
import matplotlib.pyplot as plt
import numpy as np
import datetime
from tweets.py import tweets #ツイートファイルを読み込む
importするものは以上です。osetiのインストールは
pip install oseti
でインストールできます。
データを格納する
analyzer=oseti.Analyzer()
table={"values":[],"dates":[]} #ここに日付とポジティブ度を格納
for i in range(len(tweets)):
try:
if(("extended_entities" not in tweets[i]) and tweets[i]["lang"]=="ja"): #exetnded_entitiesというkeyがあるものはリツイートや引用リツイートなので除去。あと日本語ツイートのみ抽出
table["values"].append(analyzer.analyze(tweets[i]["full_text"])[0])
#formatchanger()は日付をdatetime型に合わせるために変形する自作関数
table["dates"].append(formatchanger(tweets[i]["created_at"]))
except:
print("error!?",i)
print(tweets[i]["full_text"])
ここでtry-except文を使っているのは下図のようなツイートでerrorになるためです。

可視化
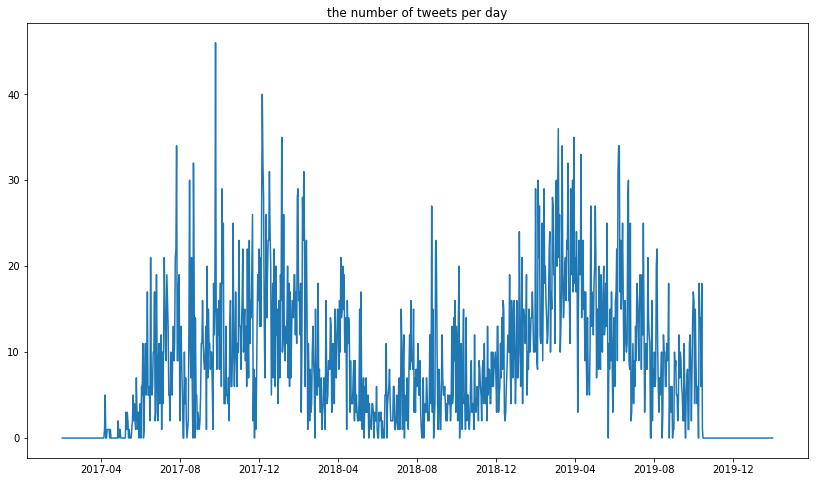
全ツイート数の変化
まず、ツイート数の変化を見てみましょう。
# x軸に使うためのリストを作成
x=[]
time_zero=datetime.date(2017,2,1)
for i in range(365*3): #3年間のデータを見る
x.append(time_zero)
time_zero+=datetime.timedelta(days=1)
y={} #ツイート数格納用辞書
for date in x:
y["{0:%Y-%m-%d}".format(date)]=0
for datum in table["dates"]:
y["{0:%Y-%m-%d}".format(datum)]+=1
fig=plt.figure(figsize=(14,8))
ax=fig.add_subplot(111)
ax.plot(x,list(y.values()))
plt.title("the number of tweets per day")
plt.show()
結果がこれです。一昨年と今年はやけにツイートしてますね。
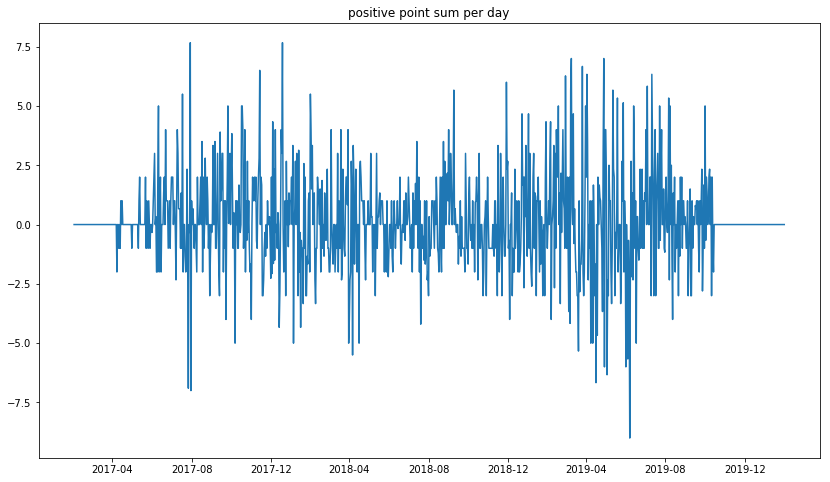
合計ポジティブ度の変化
z={} #合計ポジティブ格納用辞書
for date in x:
z["{0:%Y-%m-%d}".format(date)]=0
for i in range(len(table["dates"])):
try:
z["{0:%Y-%m-%d}".format(table["dates"][i])]+=table["values"][i]
except:
print("error occurred in ",i)
fig=plt.figure(figsize=(14,8))
ax=fig.add_subplot(111)
ax.plot(x,list(z.values()))
plt.title("positive point sum per day")
plt.show()
結果がこれです。よく見るとわかりますが上下に変動しています。
一日平均ポジティブ度の変化
合計ポジティブ度だと、ツイート数が多い日の影響が大きくなるので、一日平均をとりましょう。ついでに10日間移動平均をとってもっとわかりやすい推移を見てみましょう。
z_bar=[] #平均ポジティブ度格納用
for i in range(len(x)):
if list(y.values())[i]!=0: #このif文は0除算回避
z_bar.append(list(z.values())[i]/list(y.values())[i])
else:
z_bar.append(0)
fig=plt.figure(figsize=(14,8))
ax=fig.add_subplot(111)
plt.title("mean positive point")
ax.plot(x,z_bar)
plt.show()
z_bar_10=[]
for i in range(len(x)):
z_bar_10.append(np.mean(z_bar[i:i+10])) #データの端っこ(ツイッター開始時と現在)での処理を本当はしなければならないが略
fig=plt.figure(figsize=(14,8))
ax=fig.add_subplot(111)
ax.plot(x,z_bar_10)
plt.title("moving average line")
plt.show()
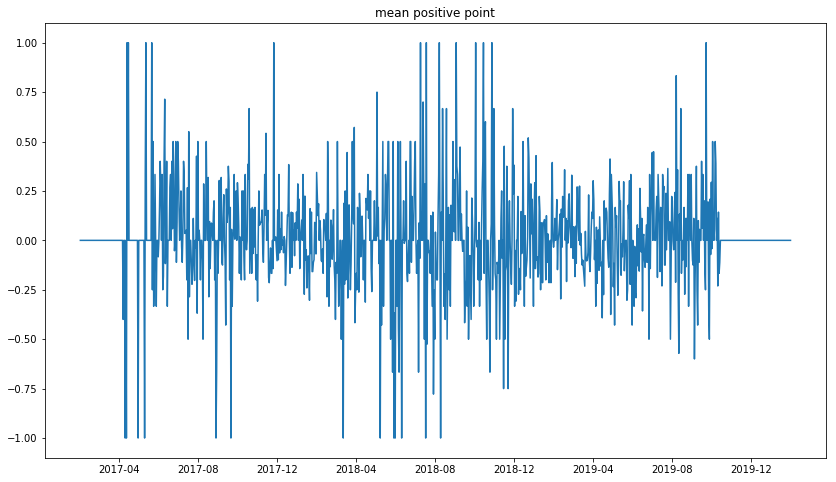
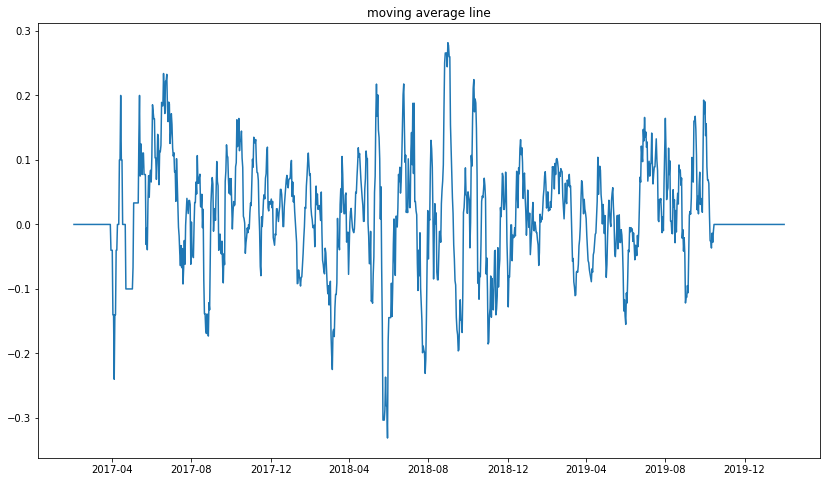
ああ、それっぽい。二年前の冬は確かにちょっと元気なかった気がするし、最近はやけに元気だ。
フーリエ解析しよう
フーリエ変換してみましょう。
F=np.abs(np.fft.fft(z_bar))
fig=plt.figure(figsize=(14,9))
# サンプリングの周期が1日なのでx軸は0から1の範囲です。あとで0除算を避けるため始点は0より少し大きくしています。
axis=np.linspace(0.0001,1,len(F))
plt.plot(axis,F)
plt.title("Foulier transformed")
plt.show()
結果がこちらです。
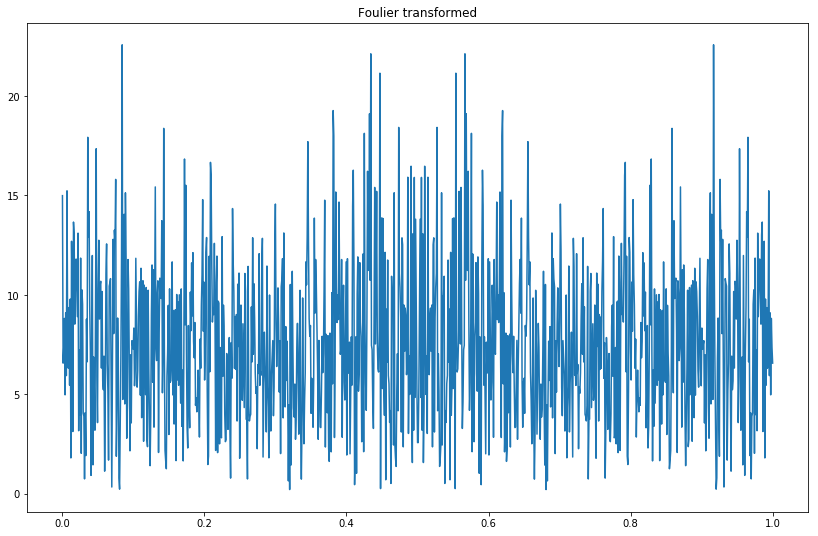
周波数0.8/日くらいの波がありそうですね。ですが周波数0.8/日と言われても困るので周期に直しましょう。
axis2=1/axis
plt.xlim(0,500)
plt.plot(axis2,F) #フーリエ変換をさらに周期のグラフに変換したもの
plt.title("mental cycle")
plt.show()
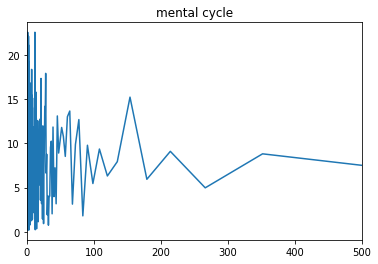
これが私のメンタルサイクルです!!
このグラフを見てみると、180日のあたりでグラフの値が大きくなっています。180日周期で感情の波があるということです!!
物理的意味を考えてみましょう。180日周期というのはつまり半年。なぜ半年周期で気分が上げ下げするのでしょうか?フーリエ変換前のグラフに戻ってみると、毎年1月とか7月にメンタルが落ち込んでその後回復している。う〜んなんでだろう。
・・・・・・
あっ!!
結論
期末試験はクソ!!長期休みサイコー!!
以上です。乱文失礼しました。