はじめに
現在、一人一人のユーザーに特化したパーソナルなAIエージェントの開発を進めています。
このエージェントを実現するにあたって「ユーザーAさんの予定」と「ユーザーBさんの好み」を混同しないためには、ユーザーごとにパーソナライズされた記憶 を管理する能力が不可欠です。
これを実現するRAG (Retrieval-Augmented Generation) 技術において、単に高精度なだけでなく、「指定したユーザーのデータだけを対象に」 や 「特定の期間の記憶だけを対象に」 といった柔軟な検索を行う仕組みが必要になります。
この記事では、Vertex AI Vector Search の ハイブリッド検索 と トークン・数値フィルタリング機能 を組み合わせ、ユーザー単位 かつ 日付範囲でも絞り込み可能な 高度なパーソナライズ検索 を実現する方法の知見をまとめます。
対象読者
- マルチユーザー対応RAGのアーキテクチャに興味がある方
- Vector Searchで特定の条件(ユーザーIDなど)に基づいて検索結果を絞り込みたい方
- Firestoreのデータを活用したパーソナルな検索基盤を構築したい方
ハイブリッド検索と、高度なフィルタリング
ハイブリッド検索とは?
ハイブリッド検索は、性質の異なる2種類のベクトルを組み合わせて検索精度を向上させる技術です。
-
Dense Vector(密ベクトル): テキスト全体の「意味」や「文脈」を捉えるのが得意です。「今日の天気は?」と「本日の気候について教えて」を類似した質問として認識できます
-
Sparse Vector(疎ベクトル): テキストに含まれる「単語(キーワード)」そのものを捉えるのが得意です。専門用語や固有名詞など、特定のキーワードに完全一致させたい場合などに強みを発揮します
Vector Searchでは、この2つのベクトルで検索した結果を RRF (Reciprocal Rank Fusion) というアルゴリズムで賢く統合し、最適な結果を返してくれます。
なぜフィルタリングが重要なのか?
パーソナルAIエージェントでは、「user_001さんの記憶」だけを検索対象にする必要があります。これを実現するのがトークンフィルタリングです。データにuser_idという「名前空間」でユーザーIDを紐づけておくことで、検索時に特定のユーザーのデータのみを対象にできます。
さらに、「user_001さんの先週の記憶」のように、期間で絞り込みたいケースも頻繁に発生します。
これを実現するのが 数値フィルタリング です。
データにevent_datetimeのような数値形式の日時を持たせておくことで、範囲を指定した検索が可能になります。
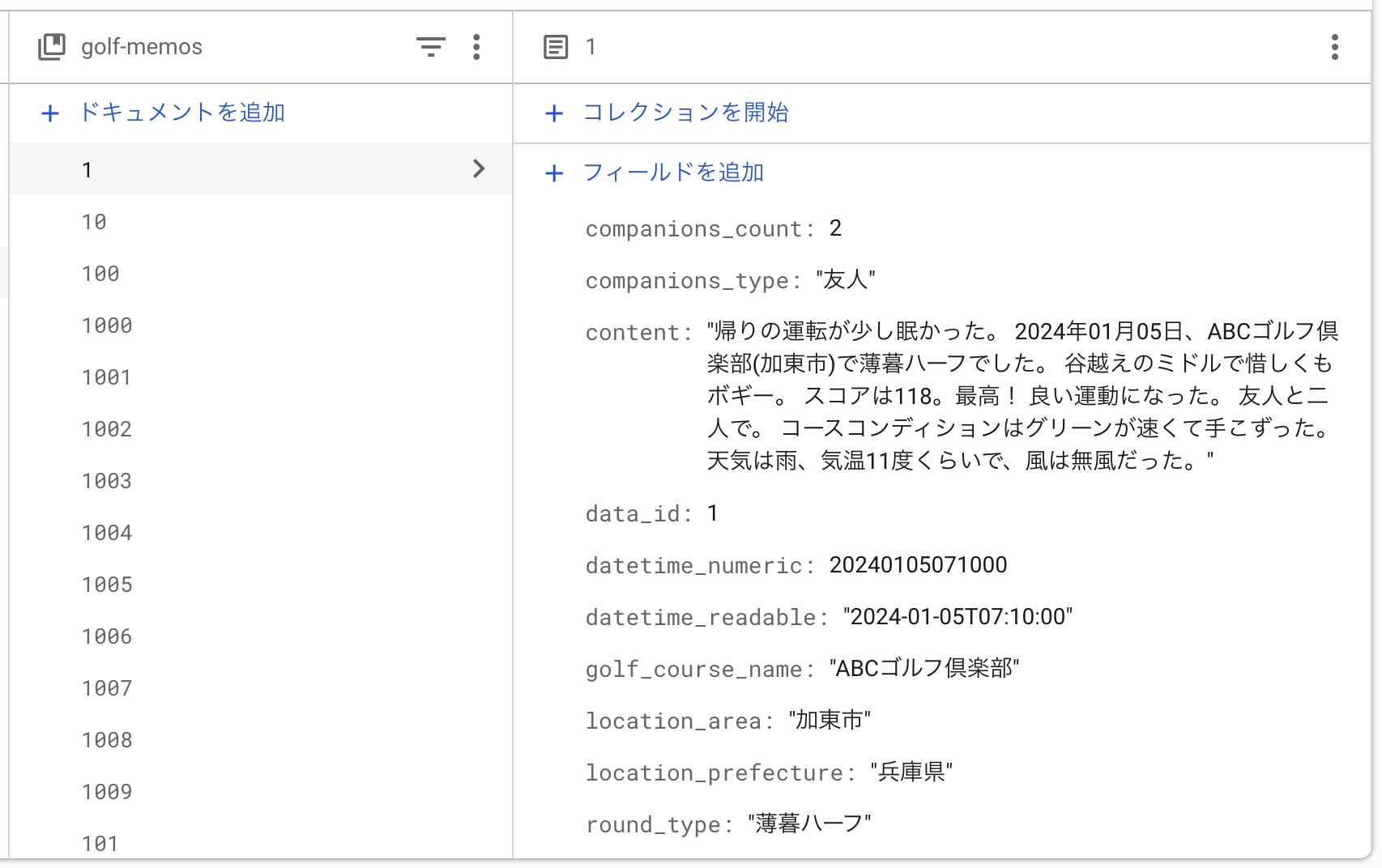
Step 0: データの準備 (Firestoreへの投入)
ベクトル検索を行うには、まず検索対象となる元のデータが必要です。
今回は、GCS (Google Cloud Storage) に配置したCSVファイルを読み込み、Firestoreに格納するプロセスから始めます。
テスト用のデータはGeminiで作成しました。
なぜFirestoreを使うのか?
Vector Searchは、ベクトルデータそのものと、そのベクトルがどのドキュメントに紐づくかというID情報のみを保持します。
検索結果として得られるのはドキュメントのIDリストです。
そのため、IDを元に検索結果の本文やメタデータを取得するためのデータベースが別途必要になります。
今回は、スキーマレスで扱いやすいFirestoreをその役割で採用しました。
GCS上のCSVをFirestoreに投入する
以下のPythonスクリプトは、pandasライブラリを使ってGCS上のCSVファイルを読み込み、Firestoreにバッチ書き込みを行います。
ドキュメントIDには、CSV内のdata_id列を使用しています。
import pandas as pd
from firebase_admin import initialize_app, firestore
import google.api_core.exceptions
import sys
# GCS上のCSVファイルのパス
GCS_CSV_PATH = 'gs://YOUR_BUCKET_NAME/path/to/your/data.csv'
# データを投入するFirestoreのコレクション名
FIRESTORE_COLLECTION = 'golf-memos'
def ingest_csv_to_firestore(csv_path, collection_name):
"""GCS上のCSVファイルを読み込み、Firestoreにデータを投入する"""
try:
try:
# 既に初期化済みの場合のエラーを避ける
initialize_app()
except ValueError:
pass # 初期化済みなら何もしない
db = firestore.client()
print(f"GCSからCSVファイルを読み込んでいます: {csv_path}")
df = pd.read_csv(csv_path, header=0)
print(f"{len(df)}件のデータを読み込みました。Firestoreへの書き込みを開始します...")
batch = db.batch()
commit_count = 0
for index, row in df.iterrows():
# DataFrameの列にアクセスする方法を修正
doc_id = str(row.data_id)
doc_ref = db.collection(collection_name).document(doc_id)
data_dict = row.where(pd.notna(row), None).to_dict()
batch.set(doc_ref, data_dict)
commit_count += 1
# 500件ごとにコミット
if commit_count >= 499:
batch.commit()
batch = db.batch()
commit_count = 0
if commit_count > 0:
batch.commit()
print(f"データ投入がすべて完了しました!")
except Exception as e:
print(f"エラーが発生しました: {e}", file=sys.stderr)
if __name__ == '__main__':
ingest_csv_to_firestore(GCS_CSV_PATH, FIRESTORE_COLLECTION)
このスクリプトを実行することで、Vector Searchの準備段階として、検索対象となるドキュメント群をFirestore上に構築できます。
Step 1: Vertex AI Vector Search の準備
まず、GCP上でパーソナル検索に対応したインデックスとエンドポイントを作成します。
フィルタリングのための「名前空間(Namespace)」
Vector Searchで「このデータはユーザーAのもの」と区別するために、トークンの制限 という機能を使います。
データ登録時に「user_id」のような 名前空間(Namespace) を定義し、そこに具体的なユーザーID(例: user-001)を紐づけておくことで、検索時にそのユーザーIDを持つデータだけを対象にできます。
今回は、インデックス作成時にこのフィルタリング機能を有効にする設定を行います。
1. インデックス設定ファイルの作成
{
"display_name": "personal-hybrid-search-index",
"description": "Personal Hybrid Search Index",
"metadata": {
"contentsDeltaUri": "gs://YOUR_BUCKET_NAME/personal_hybrid_search/index",
"config": {
"dimensions": 768,
"approximateNeighborsCount": 150,
"distanceMeasureType": "DOT_PRODUCT_DISTANCE",
"shardSize": "SHARD_SIZE_SMALL",
"algorithm_config": {
"treeAhConfig": {
"leafNodeEmbeddingCount": 5000,
"leafNodesToSearchPercent": 7
}
}
}
},
"index_update_method": "STREAM_UPDATE"
}
(※フィルタリング設定は、インデックス作成自体には含めず、データ登録時に指定します。)
2. インデックスの作成
作成した設定ファイルを使い、Vector Searchインデックスを作成します。
gcloud ai indexes create \
--project=YOUR_PROJECT_ID \
--location=asia-northeast1 \
--metadata-file=hybrid_index.json \
--display-name=personal-hybrid-search-index

3. インデックスエンドポイントの作成とデプロイ
次に、作成したインデックスにアクセスするための口(エンドポイント)を作成し、インデックスを紐付け(デプロイ)します。
# エンドポイントの作成
gcloud ai index-endpoints create \
--project=YOUR_PROJECT_ID \
--location=asia-northeast1 \
--display-name=personal-hybrid-search-endpoint \
--public-endpoint-enabled=true
# エンドポイントにインデックスをデプロイ
gcloud ai index-endpoints deploy-index $INDEX_ENDPOINT_ID \
--deployed-index-id=$NEW_DEPLOY_ID \
--display-name="$NEW_DEPLOY_NAME" \
--index=$ACTIVE_INDEX_ID \
--min-replica-count=$MIN_REPLICA_COUNT \
--max-replica-count=$MAX_REPLICA_COUNT \
--region=$LOCATION \
--project=$PROJECT_ID

Step 2: フィルタ情報を付与したベクトルデータの準備
最新のコードでは、Firestoreのデータをベクトル化し、トークン制限(userId) と 数値制限(日付) の両方のフィルタ情報を付与した上で、インデックス登録用のJSONLファイルを生成します。
この事前準備スクリプト(prepare_index_data.py)が、後の高機能な検索の土台となります。
import os
import sys
import json
import pandas as pd
from dotenv import load_dotenv
from google.cloud import storage
from google.cloud import aiplatform
import time
from embedding import text_to_dense_embedding, text_to_tfidf
load_dotenv()
PROJECT_ID = os.environ.get("PROJECT_ID")
LOCATION = os.environ.get("LOCATION")
INPUT_CSV_PATH = "sample_user_data_rich_timeseries.csv"
LOCAL_JSONL_PATH = "./embeddings_rich_timeseries_numeric.json"
GCS_BUCKET_NAME = os.environ.get("GCS_BUCKET_NAME")
GCS_DESTINATION_DIR = "embedding_data_rich_numeric/"
GCS_JSONL_BLOB_NAME = f"{GCS_DESTINATION_DIR}embeddings.json"
def upload_file_to_gcs(bucket_name, source_file_name, destination_blob_name, project_id=None):
try:
storage_client = storage.Client(project=project_id)
bucket = storage_client.bucket(bucket_name)
blob = bucket.blob(destination_blob_name)
blob.upload_from_filename(source_file_name)
return True
except Exception as e:
print(f"GCSへのアップロードエラー: {e}", file=sys.stderr)
return False
def prepare_and_upload_with_all_features():
aiplatform.init(project=PROJECT_ID, location=LOCATION)
df = pd.read_csv(INPUT_CSV_PATH, header=0)
# TF-IDF Vectorizerの学習
all_contents = df['content'].fillna('').astype(str).tolist()
text_to_tfidf(all_contents[0], fit_vectorizer_on_corpus=all_contents)
# ベクトル化とJSONLファイル作成
count = 0
with open(LOCAL_JSONL_PATH, "w", encoding='utf-8') as f_jsonl:
for index, row in df.iterrows():
data_id = str(row.get('data_id', ''))
user_id_str = str(row.get('user_id', ''))
content = str(row.get('content', ''))
datetime_numeric_val = row.get('datetime_numeric')
if not all([data_id, user_id_str, content, pd.notna(datetime_numeric_val)]):
continue
dense_vector = text_to_dense_embedding(content)
sparse_vector_dict = text_to_tfidf(content)
# トークン制限と数値制限のデータを準備
restricts_list = [{"namespace": "user_id", "allow": [user_id_str]}]
numeric_restricts_list = [
{"namespace": "event_datetime", "value_int": int(datetime_numeric_val)}
]
record = {
"id": data_id,
"embedding": dense_vector,
"restricts": restricts_list,
"numeric_restricts": numeric_restricts_list,
"sparse_embedding": {
"dimensions": sparse_vector_dict.get("dimensions", []),
"values": sparse_vector_dict.get("values", [])
}
}
f_jsonl.write(json.dumps(record, ensure_ascii=False) + "\n")
count += 1
# GCSへアップロード
if count > 0:
upload_file_to_gcs(GCS_BUCKET_NAME, LOCAL_JSONL_PATH, GCS_JSONL_BLOB_NAME, project_id=PROJECT_ID)
if os.path.exists(LOCAL_JSONL_PATH):
os.remove(LOCAL_JSONL_PATH)
if __name__ == "__main__":
prepare_and_upload_with_all_features()
Step 3: パーソナライズされたハイブリッド検索の実行
今回の検証スクリプトでは、userIdによるトークンフィルタと、日付による数値フィルタの両方を同時に適用できます。
1. 数値フィルタリングの適用方法
Vector Searchでは、文字列による完全一致(トークンフィルタ)だけでなく、「特定の日時以降」や「特定のスコア以上」といった数値の範囲を指定したフィルタリングも可能です。
今回は、datetime_numericというフィールド(例: 20250903100000)に対して、「以上(GREATER_EQUAL)」や「以下(LESS_EQUAL)」といった条件を指定することで、日付範囲検索を実現しています。
2. フィルタ検索の実行コード
以下のスクリプトは、コマンドラインから ユーザーID と 日付(範囲指定も可) を受け取り、それらの条件でフィルタリングされたハイブリッド検索を実行します。
-
filterパラメータ:userIdなどのトークン制限を指定します -
numeric_filterパラメータ: 日付などの数値制限を指定します
import os
import sys
import pandas as pd
from dotenv import load_dotenv
import google.cloud.aiplatform as aiplatform
from google.cloud.aiplatform.matching_engine.matching_engine_index_endpoint import HybridQuery, Namespace, NumericNamespace
from datetime import datetime
from embedding import text_to_tfidf, text_to_dense_embedding
load_dotenv()
PROJECT_ID = os.environ.get("PROJECT_ID")
LOCATION = os.environ.get("LOCATION")
INDEX_ENDPOINT_ID = os.environ.get("INDEX_ENDPOINT_ID")
DEPLOYED_HYBRID_INDEX_ID = os.environ.get("ACTIVE_DEPLOYED_INDEX_ID")
INPUT_CSV_PATH = "sample_user_data_rich_timeseries.csv"
def parse_date_filter_input(date_input_str):
numeric_filters = []
if not date_input_str or not date_input_str.strip():
return numeric_filters
date_input_str = date_input_str.strip()
if "-" in date_input_str: # 範囲指定
parts = date_input_str.split('-')
if len(parts) == 2 and parts[0].strip() and parts[1].strip():
start_num = int(parts[0].strip() + "000000")
end_num = int(parts[1].strip() + "235959")
numeric_filters.append(NumericNamespace('event_datetime', start_num, op='GREATER_EQUAL'))
numeric_filters.append(NumericNamespace('event_datetime', end_num, op='LESS_EQUAL'))
else: # 単一日付
start_num = int(date_input_str + "000000")
end_num = int(date_input_str + "235959")
numeric_filters.append(NumericNamespace('event_datetime', start_num, op='GREATER_EQUAL'))
numeric_filters.append(NumericNamespace('event_datetime', end_num, op='LESS_EQUAL'))
return numeric_filters
def main(query_text, target_user_id, date_filter_numeric_list):
aiplatform.init(project=PROJECT_ID, location=LOCATION)
query_dense_emb = text_to_dense_embedding(query_text)
query_sparse_emb = text_to_tfidf(query_text)
hybrid_queries = HybridQuery(
dense_embedding=query_dense_emb,
sparse_embedding_dimensions=query_sparse_emb["dimensions"],
sparse_embedding_values=query_sparse_emb["values"],
rrf_ranking_alpha=0.7
)
user_id_token_filter = [Namespace('user_id', [target_user_id])]
my_index_endpoint = aiplatform.MatchingEngineIndexEndpoint(index_endpoint_name=INDEX_ENDPOINT_ID)
hybrid_resp = my_index_endpoint.find_neighbors(
deployed_index_id=DEPLOYED_HYBRID_INDEX_ID,
queries=[hybrid_queries],
num_neighbors=50,
filter=user_id_token_filter,
numeric_filter=date_filter_numeric_list if date_filter_numeric_list else None
)
df = pd.read_csv(INPUT_CSV_PATH, header=0, index_col='data_id')
# ... (結果表示処理) ...
for idx, neighbor in enumerate(hybrid_resp[0]):
item_id = int(neighbor.id)
# (結果表示の詳細は省略)
print(f"rank: {idx+1}, id: {item_id}, ...")
if __name__ == "__main__":
input_user_id = input("フィルタリングするユーザーID入力 (例: user_001): ")
input_query_text = input("検索するテキスト入力: ")
date_filter_input = input("フィルタリングしたい日付 (単一例: 20250501, 範囲例: 20250501-20250507, 未指定: Enterのみ): ")
numeric_date_filters = parse_date_filter_input(date_filter_input)
main(input_query_text, input_user_id, numeric_date_filters)
実行結果
コマンドラインからuserIdを指定して実行すると、そのユーザーのデータのみが検索結果として返されます。
# 日付を指定しない場合
python hybrid_search_filter_test.py
(Python出力) フィルタリングするユーザーID入力 (例: user_001): user_001
(Python出力) 検索するテキスト入力: おすすめのゴルフ場は?
(Python出力) フィルタリングしたい日付 (単一例: 20250501, 範囲例: 20250501-20250507, 未指定: Enterのみ):
--- 'user_001' の検索結果 ---
rank: 1 , id: 1001, user: user_001 , date: 2024-08-15T10:00:00 , content: 先週行ったABCゴルフ倶楽部は最高だった。特に景色が... , dense: 0.891, sparse: 0.920
rank: 2 , id: 1025, user: user_001 , date: 2024-07-02T13:30:00 , content: DEFカントリーのランチはカレーがおすすめ。... , dense: 0.855, sparse: 0.810
...
おわりに
今回は、Vertex AI Vector Searchのハイブリッド検索に トークンフィルタ と 数値フィルタ を組み合わせることで、ユーザーごと かつ 日時でも絞り込み可能な、高度なパーソナライズ検索を実装する方法を紹介しました。
filter および numeric_filter パラメータを駆使することで、マルチユーザー環境でも各ユーザーのプライバシーを保ちつつ、個人的な文脈に基づいた柔軟で高精度なRAGを実現できます。
このパーソナライズ検索は、私たちが開発しているAIエージェントが、真に「個人のためのアシスタント」として機能するための重要な一歩となります。
この検索基盤を Firebase Genkit というフレームワークに組み込むことで運用面を意識した設計の検証をして実導入に向けた動きを進めていきます。
Firebase Genkitに組み込んでいく検証や応用については 次回の記事 にまとめます。