はじめに
日頃の情報収集のため、国土地理院のサイトで提供している RSS (RDF) フィードを取得しようとしたら、問題がいくつか発生。
これを解決するのにあれこれ行ってみたけども、やっぱり公式でなんとかして欲しい…という陳情も交えたネタ記事です。
(ちょいちょい、この記事をベースに Notebook LM が作成した、やや大げさなスライド画像を入れてます)
なにが起きたか?
行なった事を順を追って並べると、こんな感じです。
-
その1
- 国土地理院のRDFを Slack でフィードを受け取りたい
↓ - RDF のフィードが https のエラー
↓ - PCではなんとかなるが、Slack ではどうしようもない
- 国土地理院のRDFを Slack でフィードを受け取りたい
-
その2
- GitHub Pagesを RDF 配信のプロキシとして利用。 Slack で受け取れるようにしてみた
↓ - RDFが構文崩れ
- GitHub Pagesを RDF 配信のプロキシとして利用。 Slack で受け取れるようにしてみた
-
その3
- 元の RDF をプログラムで無理矢理加工。RSS2.0形式にしてみた
↓ - Slackでフィードを受け取れるようになった
↓ - …が、これでいいのか?
- 元の RDF をプログラムで無理矢理加工。RSS2.0形式にしてみた
という話です。

では、それぞれ細かく見てきましょう。
ことの詳細
その1: RDFフィードを読み込むと HTTPS のエラーが発生
国土地理院サイトの新着情報をお知らせするRSSフィードはこちらにあります。
- RSS(RDF) フィードを含むページ: https://www.gsi.go.jp/whatsnew.html
- RDF フィード自体のURL: https://www.gsi.go.jp/index.rdf
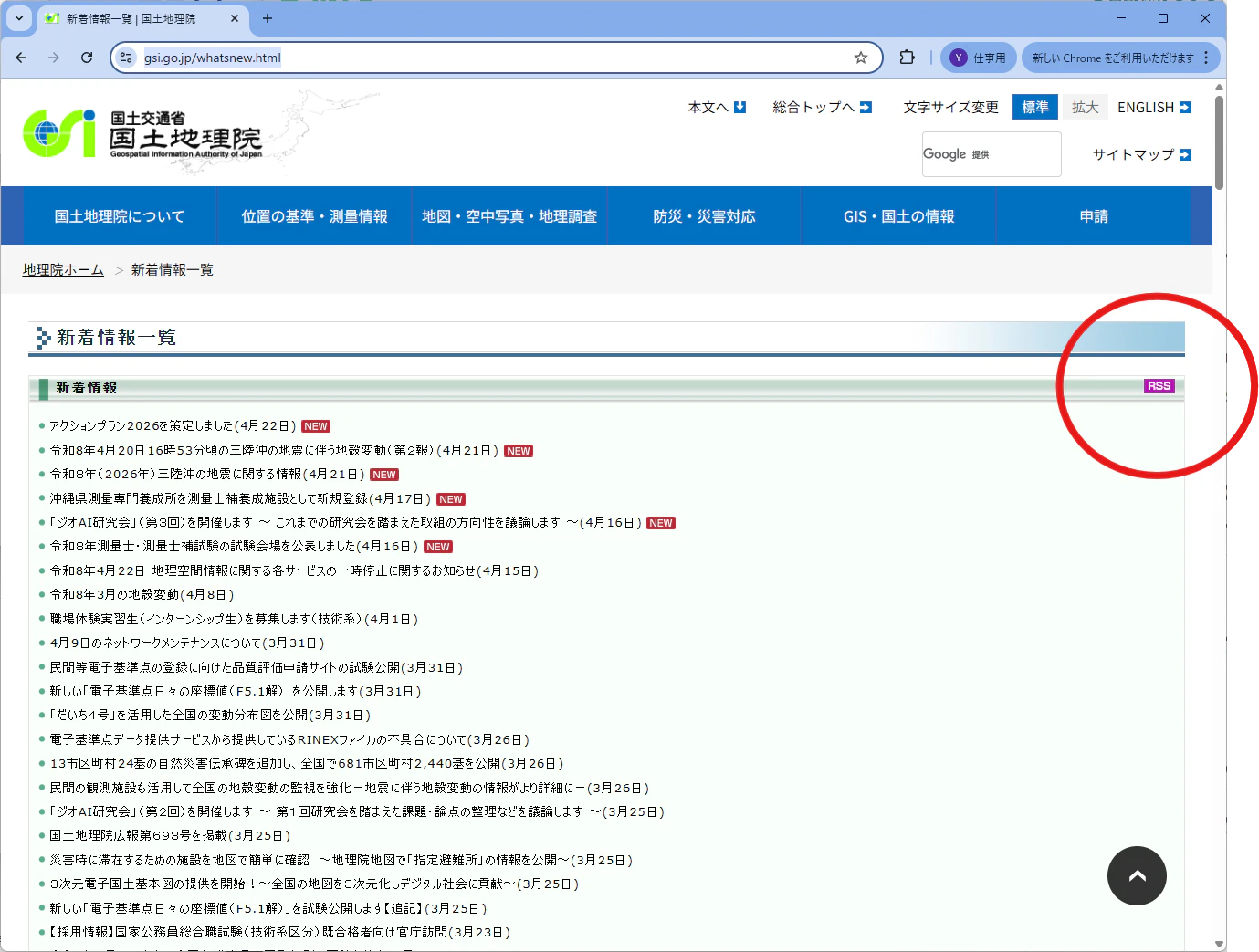
Slack で定期的に RSS フィードを受け取るには、任意のチャンネル・DM等に /feed subscribe [feed url] というコマンドを送信することで登録できます。
が、国土地理院の RSS フィードを実際受け付けてみるとこのようなエラーが出てきます。
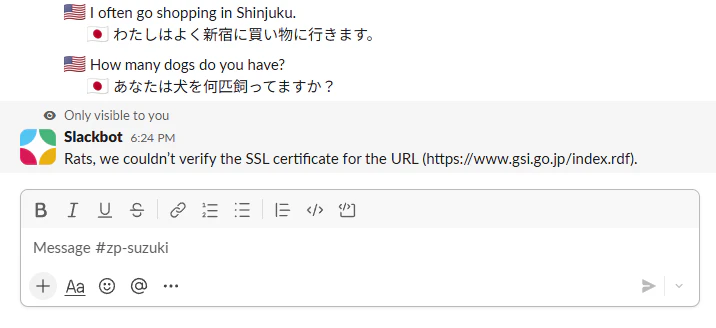
Rats, we couldn’t verify the SSL certificate for the URL (https://www.gsi.go.jp/index.rdf).`
このエラーについて、詳しく調べるためにインターネットの規格を決めている団体・W3C が提供する Feed Validator を使ってみます。
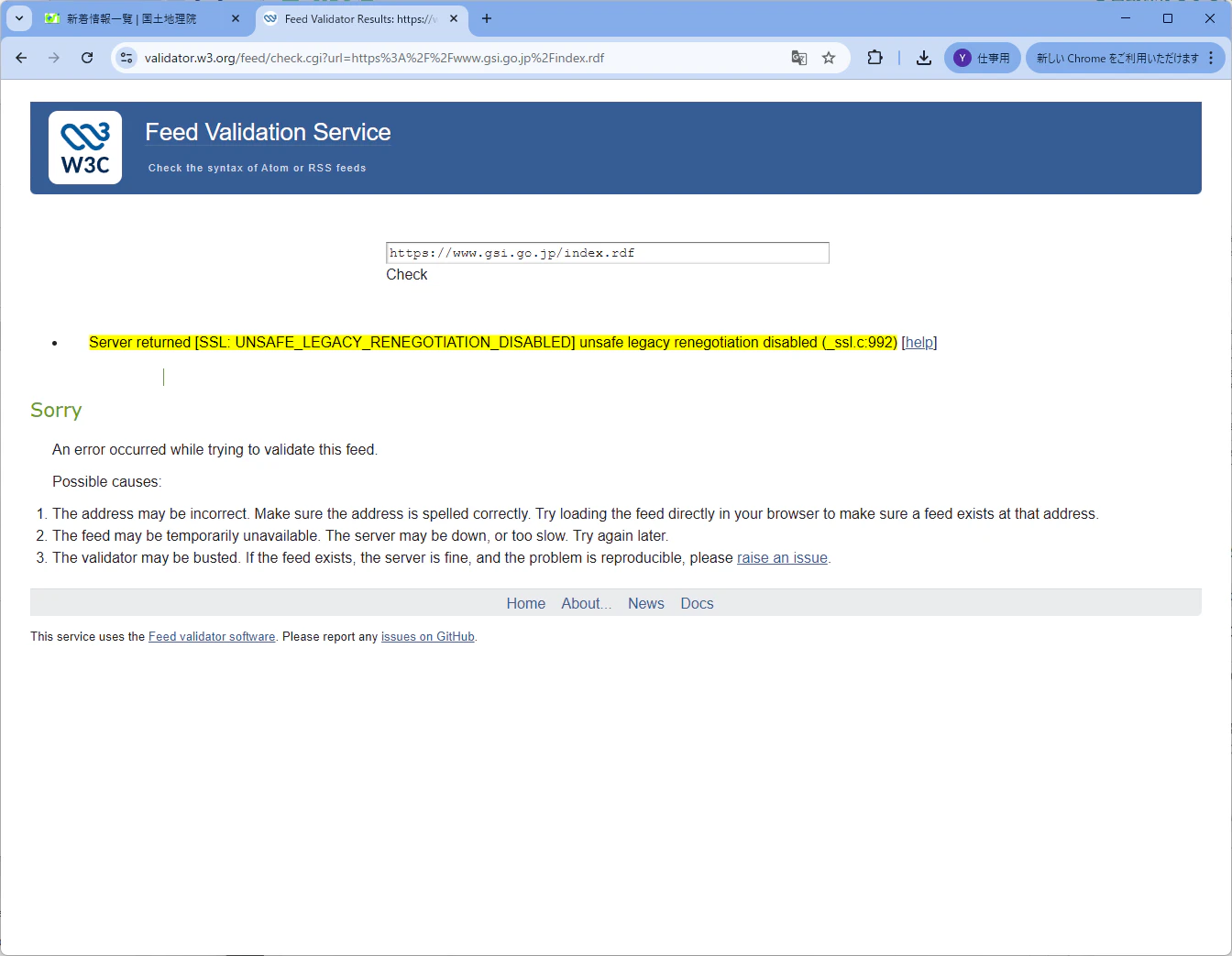
フィードを解析すると、このようなエラーが出てきます。
Server returned [SSL: UNSAFE_LEGACY_RENEGOTIATION_DISABLED] unsafe legacy renegotiation disabled (_ssl.c:992)`
こちら UNSAFE_LEGACY_RENEGOTIATION_DISABLED というエラーは、調べてみると、
- レガシーTLS 再ネゴシエートを誤って強制する、古くなった、またはバグのある SSL プロキシが原因で発生する
ということで SSL 通信周りの問題です。
このエラー、ローカルの PC では、例えば /etc/pki/tls/openssl.cnf にて、Options = UnsafeLegacyServerConnect というオプションを追加することで、エラーを黙って見過ごすようになりますが、今回は Slack で読ませたいので、こんなオプションは当然指定できません。
さあ困った。
その2: Github Pages を RDF のプロキシとして使うが、RDF が壊れてた
この問題の解決方法として、私が思いついたのは、
- 正しい SSL 通信が可能なプロキシサーバを準備
- プロキシを経由してフィードを取得する
というものです。
ただ、この方法を選んだ時点で、国土地理院のサイトから直接得るフィードでなくなってしまうのが難点です。
が、個人的に Slack 上でサイトの更新情報をチェックするぐらいならまあいいか、ということで作業を進めます。
とはいえ、この作業でプロキシサーバは特に立てません。
手っ取り早い方法として GitHub Pages をプロキシ代わりに使ってみることにします。
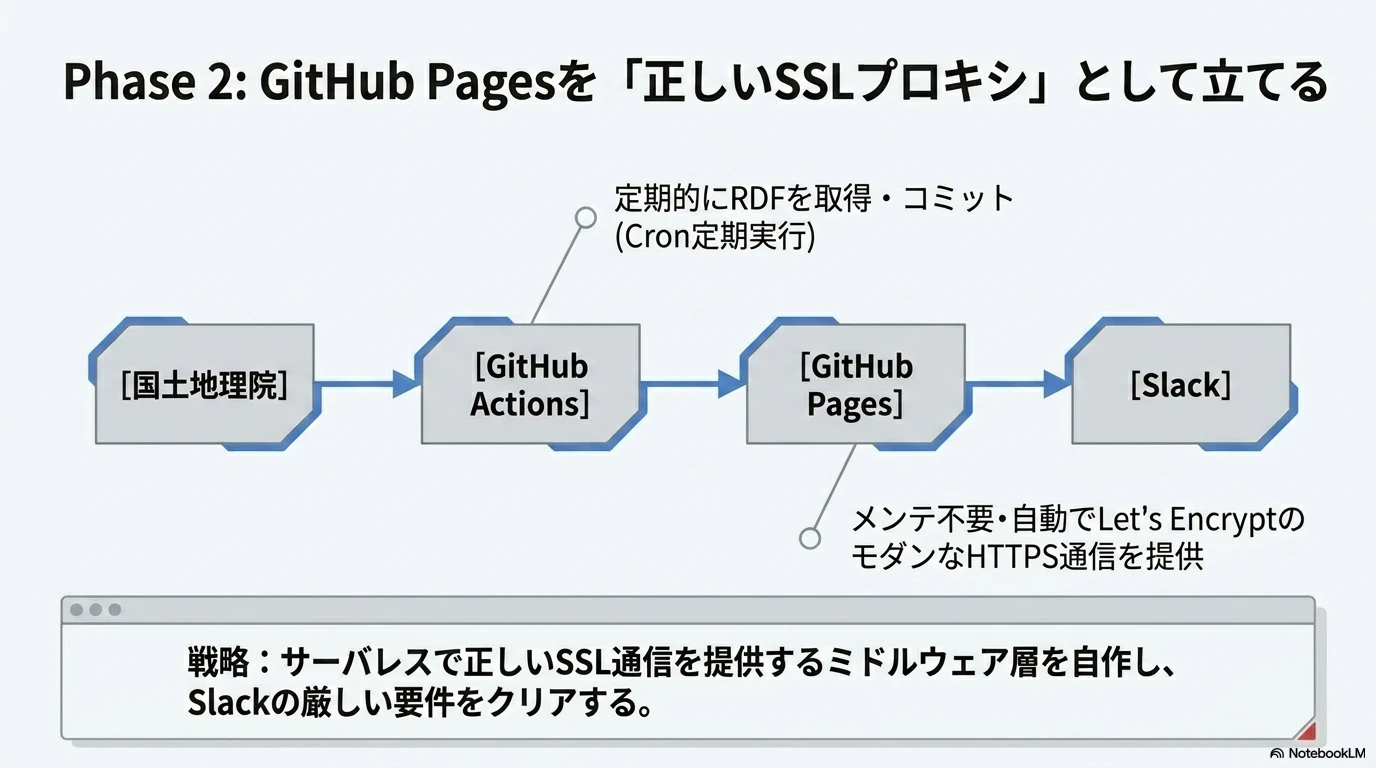
GitHubリポジトリ、GitHub Actions では以下の操作を行います。
- リポジトリに設定した GitHub Actionsを定期的に cron 実行
- Actions で動かす Python スクリプトにより国土地理院のRDFフィードを取得
- 取得したフィードをリポジトリに対し追加・コミット
これらの処理により、リポジトリに RDF を保存しつつ、GitHub Pages を介してフィードも配信できる…という仕組みです。
GitHub のリポジトリをコンテンツをして公開する Pages では、とくに指定しない限り Let's Encrypt の SSL 証明書がHTTPSの通信に使われ、また、証明書自体も自動更新されます。
この環境はサーバレスであり、ソースも含めて公開可能で、サーバのメンテナンスもなるべく避けつつコンテンツを公開する…という目的に、わりと都合が良いです。
サーバは建てなければ建てないほどセキュリティ的に良いものですからね。
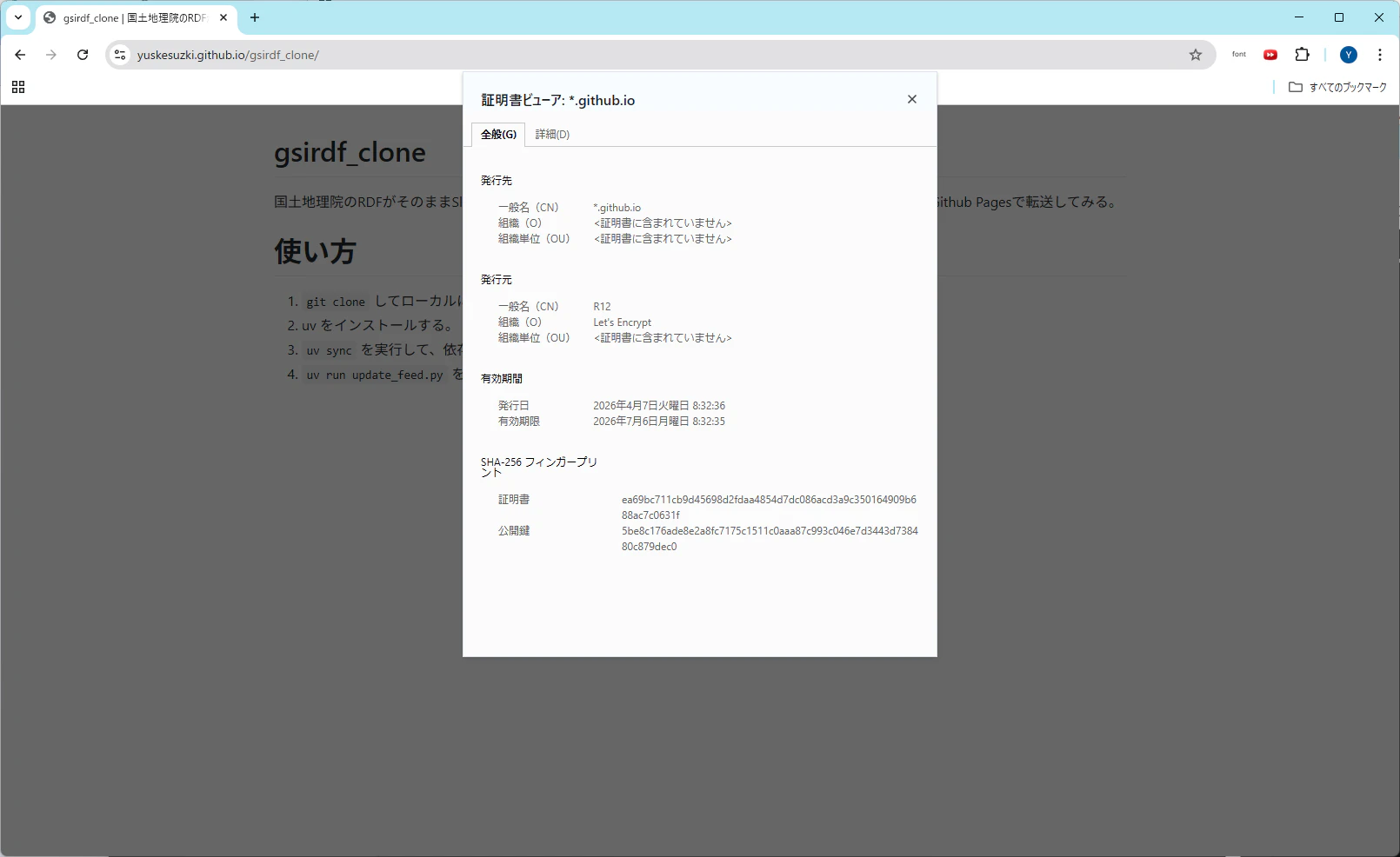
ということで、リポジトリに配置した RDF フィードを Slack で読み込んでみると、SSL通信の問題は解消したものの、今度はこんなエラーが。なんなの。
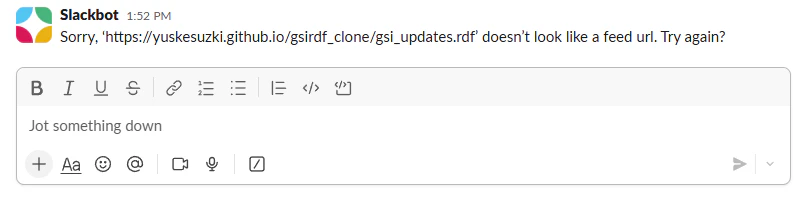
Sorry, 'https://yuskesuzki.github.io/giirdf_clone/gis_updates.rdf' doesn't look like a feed url. Try again?
どうもコンテンツがフィードとして認識されてないようです。
このフィードを再び、W3C Feed Validator にかけてみると、こんなことがわかりました。
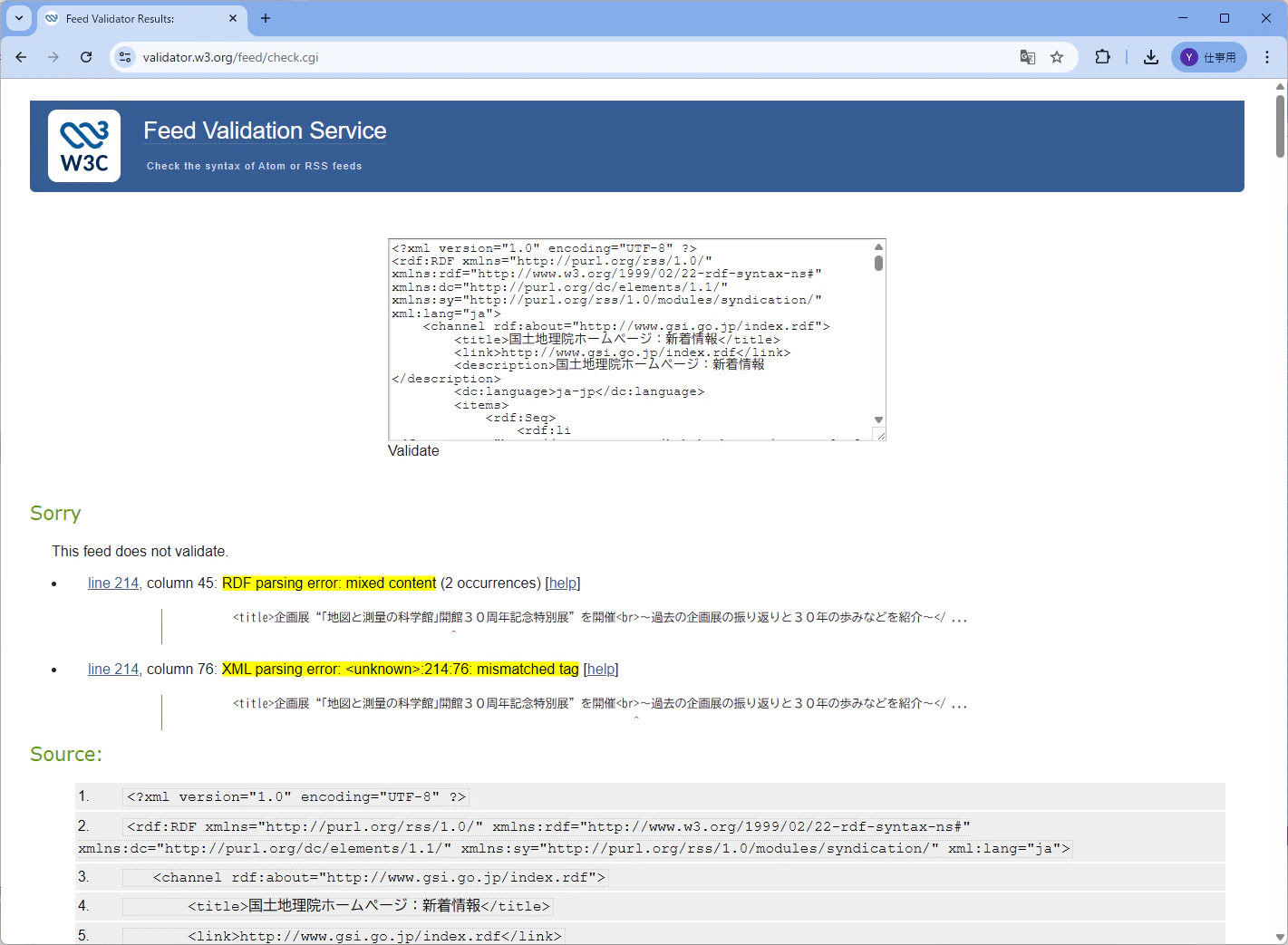
エラー箇所をピックアップするとこんな感じです。
Sorry
This feed does not validate.
line 214, column 45: RDF parsing error: mixed content (2 occurrences) [help]
<title>企画展“「地図と測量の科学館」開館30周年記念特別展”を開催<br>~過去の企画展の振り返りと30年の歩みなどを紹介~</ ...
^
line 214, column 76: XML parsing error: <unknown>:214:76: mismatched tag [help]
<title>企画展“「地図と測量の科学館」開館30周年記念特別展”を開催<br>~過去の企画展の振り返りと30年の歩みなどを紹介~</ ...
開催<br>~過去 という title 属性に <br> タグでしたかー。
どうやら、余分なHTMLタグが RDF フィードに含まれており、これを除去しないと Slack では認識できないようです。

さあ、再び困った。
その3: RDF を無理矢理加工して、RSS 2.0 形式に変更
ということで、GitHub Actions で取得した RDF フィードを加工しちゃいます。
用意した GitHub Actions では、処理中 Python スクリプトを動かして RDF フィードの取得・保存を行っており、このスクリプトにデータ加工する処理も含めることにします。
ついでなんで、RDF フィードでなく、RSS 2.0の形式に書きかえちゃいましょう。
これには Python の HTML パーサー BeautifulSoup で元の RDF を解析しつつ、RSS 2.0 形式のフィードを新たに組み立てる…という手順が使えます。
コードとしては、このようなものになるでしょう(まあ生成AIに書かせてるんですけどね)
import re
from curl_cffi import requests
from bs4 import BeautifulSoup
import xml.etree.ElementTree as ET
from email.utils import formatdate
from datetime import datetime
import time
...(略)...
response = requests.get(url, impersonate="chrome", verify=False, timeout=30)
response.raise_for_status()
raw_text = response.text
# 構文エラーの原因となる <br> タグを事前に除去
raw_text = re.sub(r'<br\s*/?>', ' ', raw_text, flags=re.IGNORECASE)
soup = BeautifulSoup(raw_text, 'html.parser')
# Atom名前空間を追加 (W3C推奨要件)
rss = ET.Element("rss", {
"version": "2.0",
"xmlns:atom": "http://www.w3.org/2005/Atom"
})
channel = ET.SubElement(rss, "channel")
ET.SubElement(channel, "title").text = "国土地理院 更新情報"
ET.SubElement(channel, "link").text = "https://www.gsi.go.jp/"
ET.SubElement(channel, "description").text = "国土地理院のRDFを自動修復したフィードです。"
# atom:linkの追加 (W3C推奨要件)
ET.SubElement(channel, "atom:link", {
"href": FEED_URL,
"rel": "self",
"type": "application/rss+xml"
})
items = soup.find_all('item')
for item in items:
title_tag = item.find('title')
link_tag = item.find('link')
desc_tag = item.find('description')
date_tag = item.find('dc:date') or item.find('date')
title = title_tag.get_text(separator=" ", strip=True) if title_tag else "タイトルなし"
# 【修正点1】linkタグの取得方法を強化(空要素問題の回避)
# RDFの仕様上、itemの属性(rdf:about)にURLが入っていることが多いのでまずそれを探す
link_url = item.get('rdf:about') or item.get('about')
# 属性にない場合、linkタグの「隣のテキスト」としてパースされてしまったURLを拾う
if not link_url and link_tag and isinstance(link_tag.next_sibling, str):
link_url = link_tag.next_sibling.strip()
# それでも見つからない場合のフォールバック
if not link_url or not link_url.startswith("http"):
link_url = "https://www.gsi.go.jp/"
description = desc_tag.get_text(separator=" ", strip=True) if desc_tag else ""
date_str = date_tag.get_text(strip=True) if date_tag else ""
pub_date = formatdate(time.time())
if date_str:
try:
dt = datetime.fromisoformat(date_str.replace('Z', '+00:00'))
pub_date = formatdate(dt.timestamp())
except Exception:
pass
rss_item = ET.SubElement(channel, "item")
ET.SubElement(rss_item, "title").text = title
ET.SubElement(rss_item, "link").text = link_url
ET.SubElement(rss_item, "description").text = description
ET.SubElement(rss_item, "pubDate").text = pub_date
# 【修正点2】guid要素の追加 (W3C推奨要件)
ET.SubElement(rss_item, "guid", {"isPermaLink": "true"}).text = link_url
tree = ET.ElementTree(rss)
if hasattr(ET, 'indent'):
ET.indent(tree, space=" ", level=0)
tree.write(output_file, encoding="utf-8", xml_declaration=True)
print(f"Success: Parsed and saved as valid RSS 2.0 to {output_file}")
ということで、加工した RSS 2.0 フィードがこちらです。
たびたび記事に登場する W3C Feed Validator からも This is a valid RSS feed. というお墨付きもいただきました ![]()
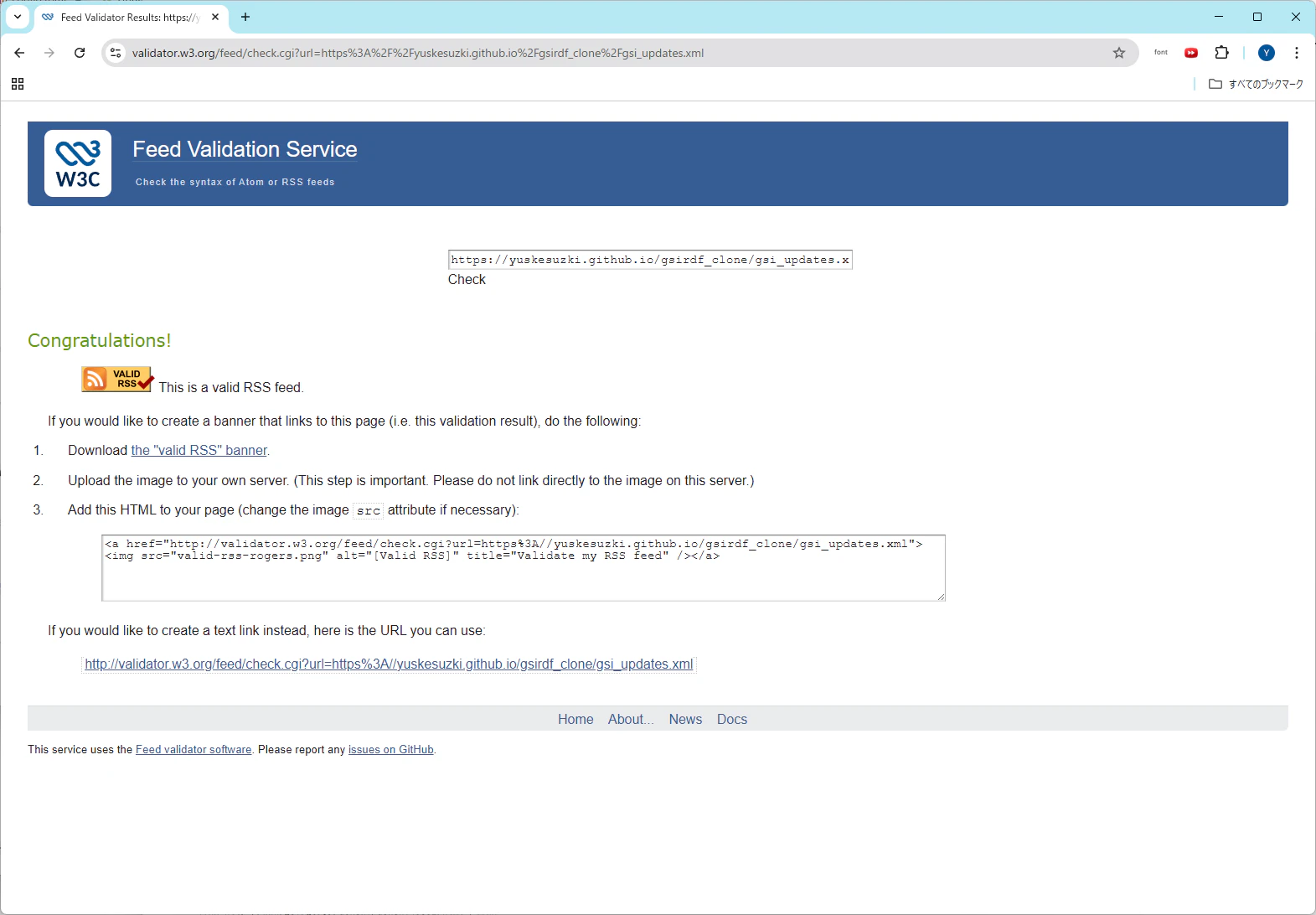
というわけでめでたしめでたし。

が、ホントにいいのか?
…が、個人で使う分にはこんな力技でなんとかすればいいんですが、国土地理院として RSS リーダーで読めないRDFをフィードしているのは、やはりいかがなものでしょう?
できれば、公式のサイトからのフィードが壊れておらず、通信も適切である事が大事だと思います。
したがいまして、国土地理院さまにおいては、RDF 配信環境の見直しについて、ささやかながら願っております。
以上です。
参考資料
- curlでunsafe legacy renegotiation disabledが発生した場合の対処方法(AmazonLinux2023)
- RDFフィードのプロキシ用 GitHub リポジトリ