はじめに
本記事は、以下の手順をまとめた記事の前編です。
(前編)
- コンソールを用いて、ローカル環境からABEJA Platformにファイルをアップロードする
- ABEJA Platoformのノーブック上からデータレイクのファイルを参照する
(後編) - ABEJA Platformのジョブ機能を用いて、scikit-learnを使った機械学習モデルを学習する
- モデルをWeb APIとしてデプロイする
後編はこちらの記事を参照して下さい。
https://qiita.com/yushin_n/items/1f027dcdf3ea968f0903
ローカル環境からABEJA Platformにファイルをアップロードする
ファイルの用意
サンプルとして、Scikit-learnのIrisデータセットをロードします。
import numpy as np
import os
import pandas as pd
from sklearn import datasets
# load iris datasets
iris = datasets.load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['target'] = iris.target
CSV形式で保存します。
# save as csv
os.makedirs('./data', exist_ok=True)
file_path = './data/iris.csv'
df.to_csv(file_path, index=False)
データレイクチャンネルへのファイルのアップロード
コンソールのデータレイク --> チャンネルから「+チャンネル作成」をクリックして、チャンネルを作成します。
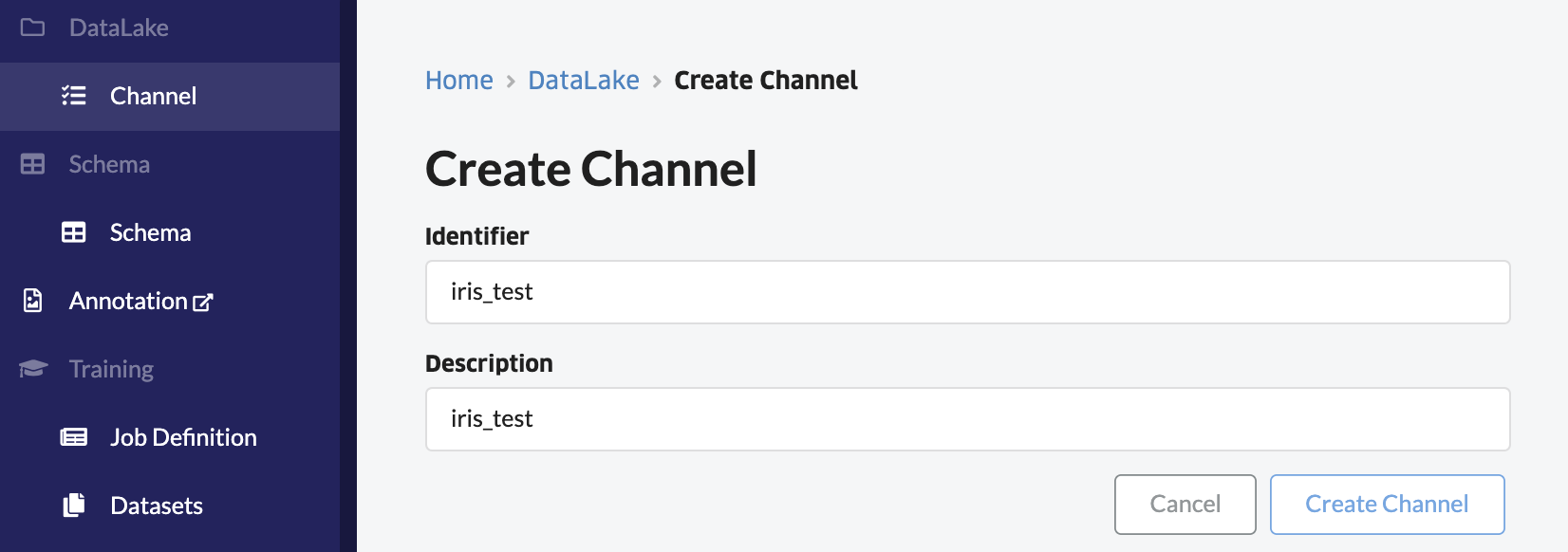
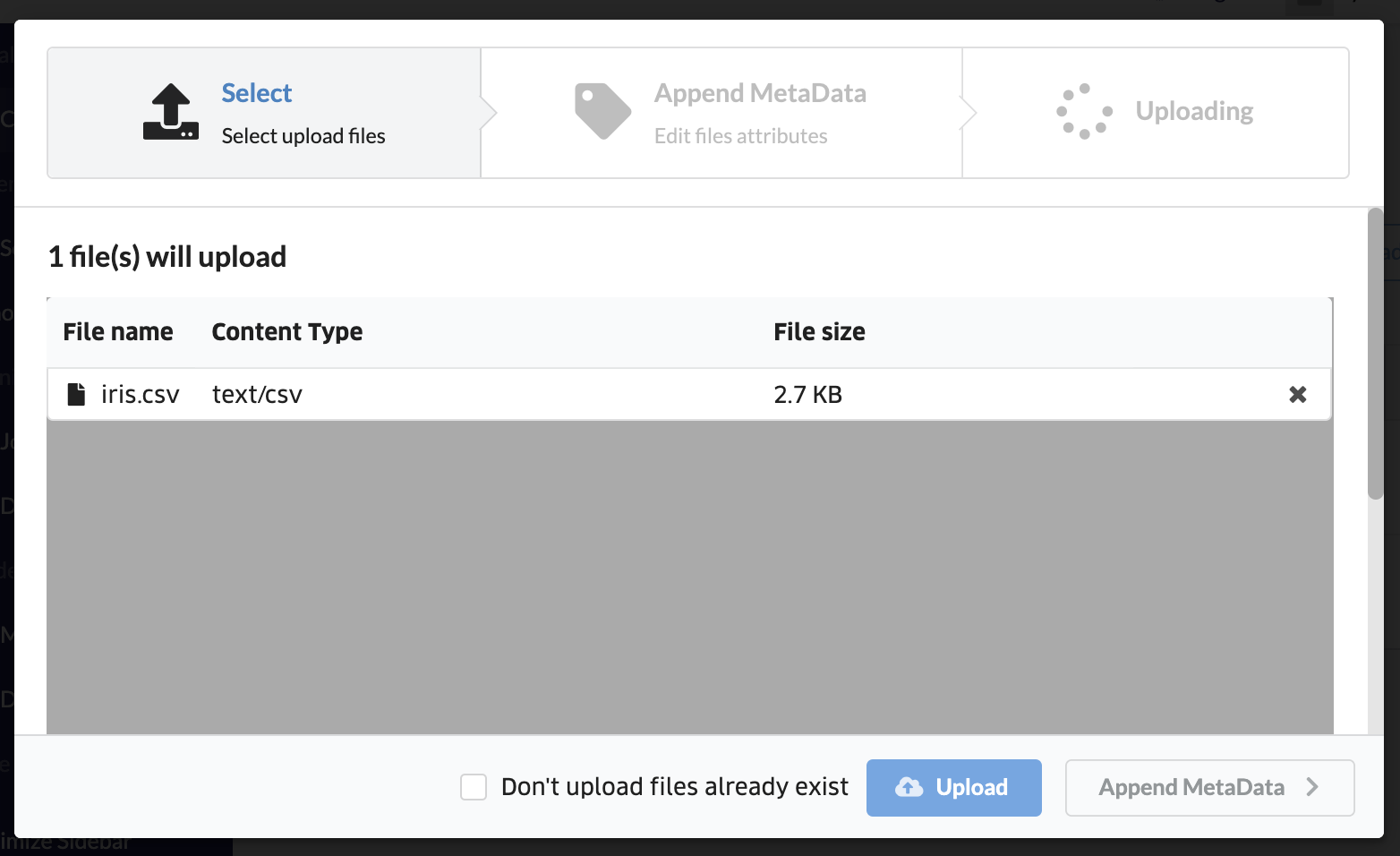
「アップロード」をクリックして、先ほど作成したCSVファイルをアップロードします。
ABEJA Platoformのノートブック上からデータレイクのファイルを参照する
ノートブックの立ち上げ
コンソールのジョブ定義から、「+ジョブ定義を作成」をクリックして、ジョブ定義(ワークスペースのようなもの)を作成します。
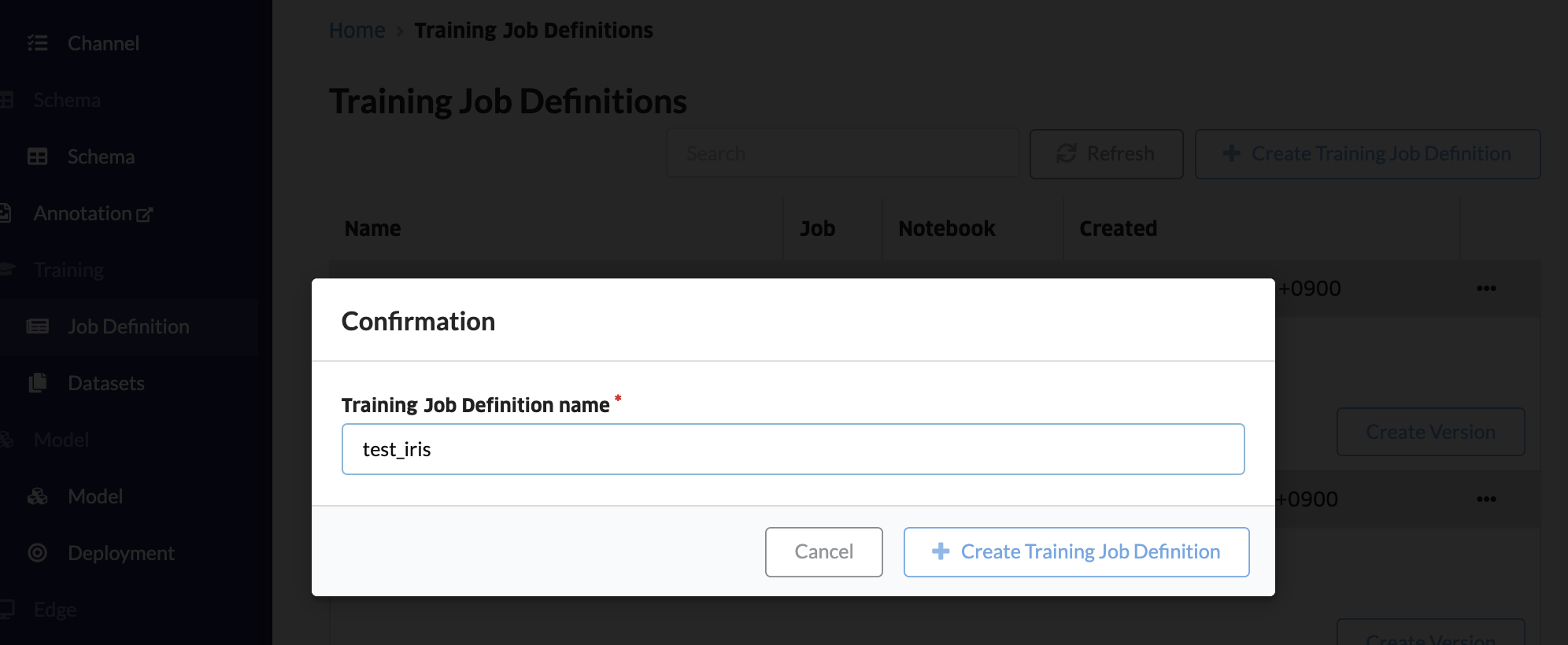
ノートブックをクリックします。
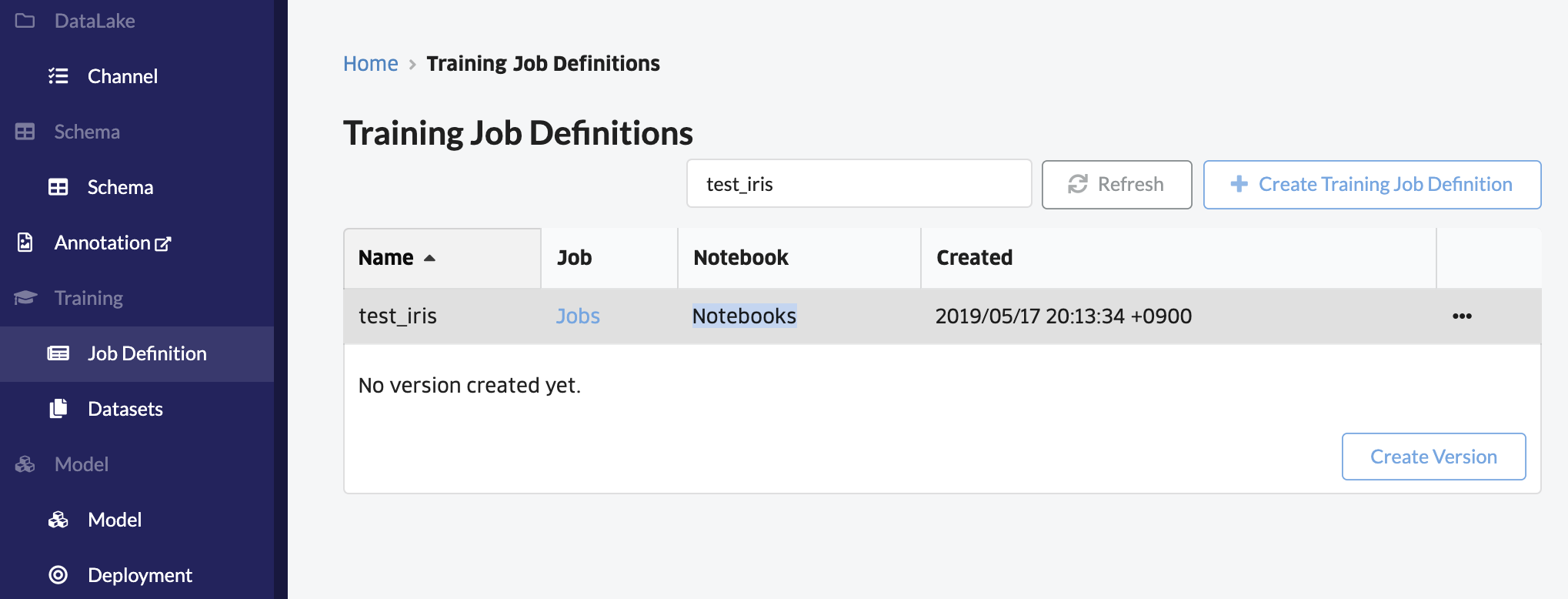
「+ノートブック作成」をクリックして、インスタンスの種類を選びます。今回はcpu-1を選択します。
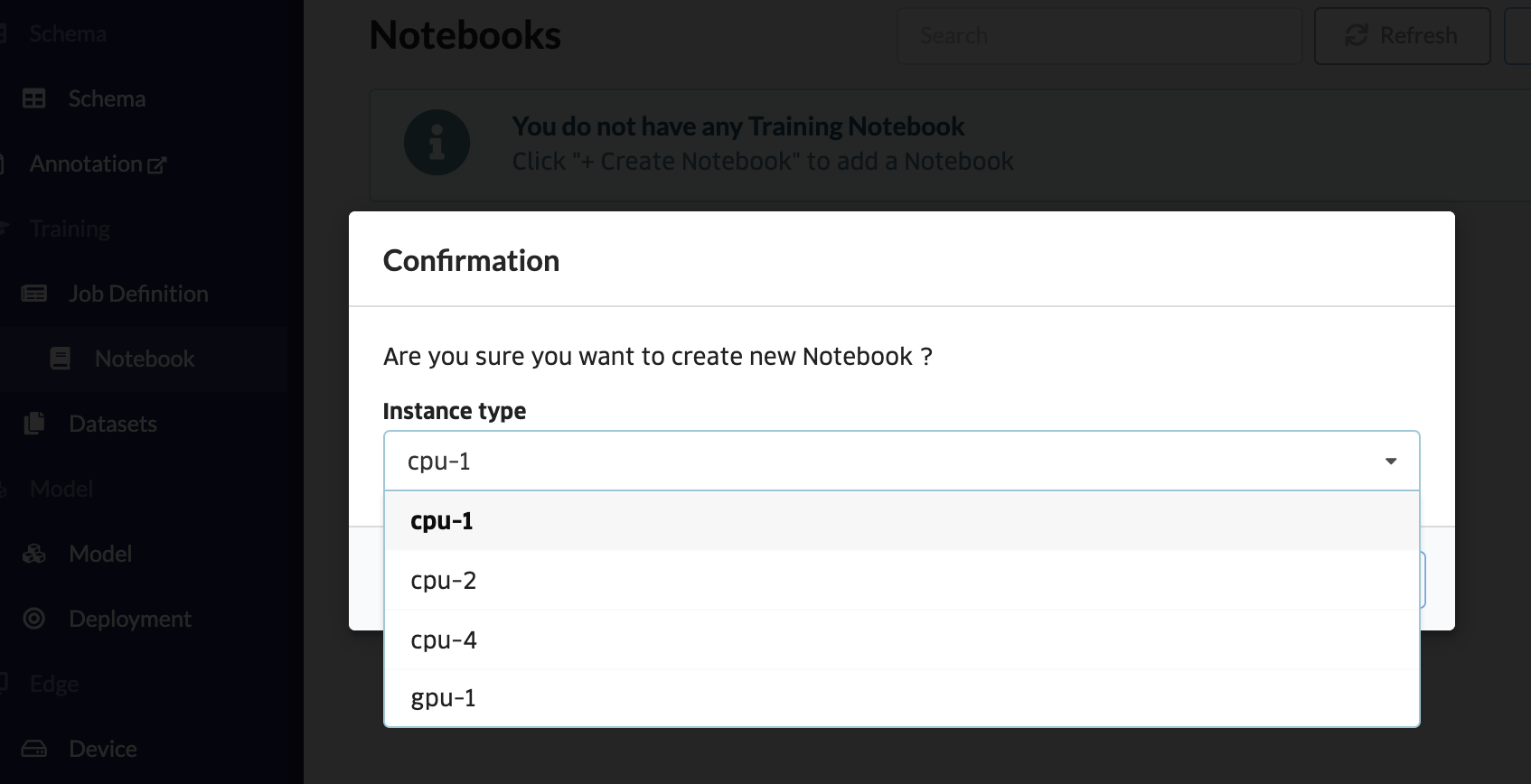
「ノートブックを開く」をクリックして、Jupyter Notebookの画面から、ノートブックを立ち上げます。
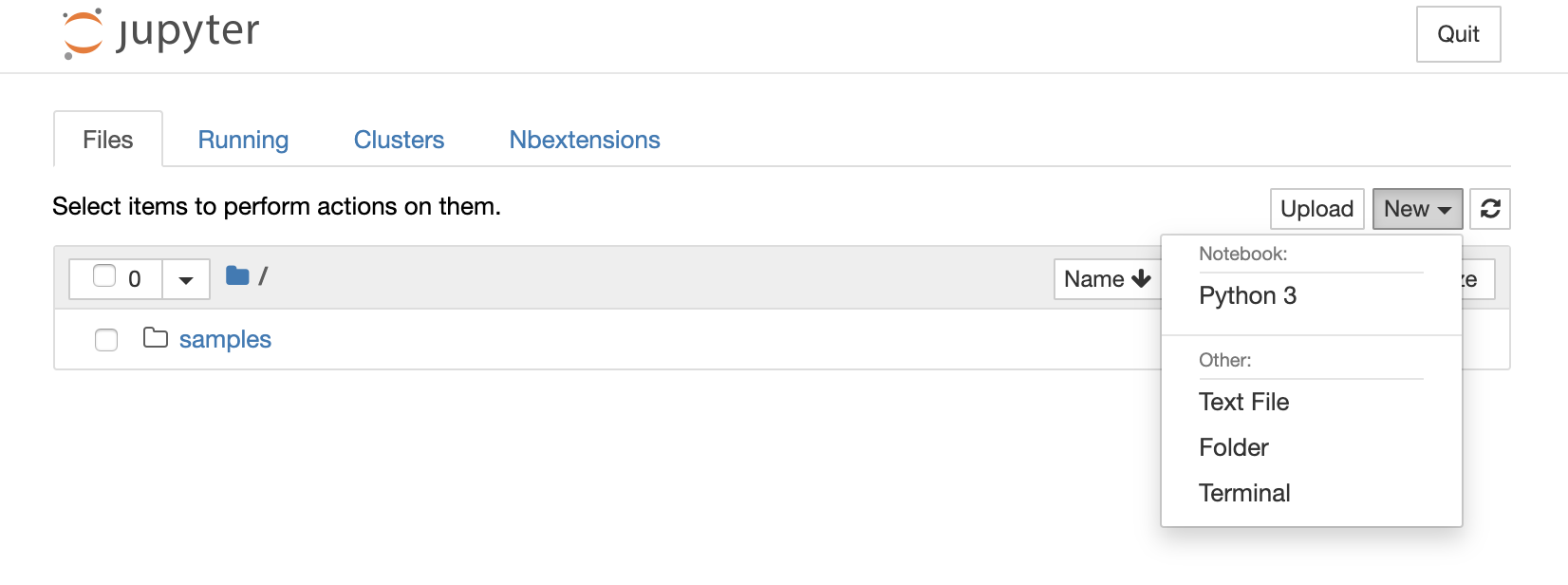
DataLakeのファイルの参照
今回は、データレイクのチャンネルにあるファイルの中から、最も新しい日付のファイルをロードすることにします。まず、コンソールのチャンネルから、チャンネルIDをコピーして入力します。
import numpy as np
import os
import pandas as pd
from abeja.datalake import Client as DatalakeClient
# set datalake channel_id
channel_id = 'XXXXXXXXXXXXX'
def load_latest_file_from_datalake(channel_id):
datalake_client = DatalakeClient()
channel = datalake_client.get_channel(channel_id)
# load latest file path
for f in channel.list_files(sort='-uploaded_at'):
latest_file_path = f.download_url
latest_file_datetime = f.uploaded_at
print('load file uploaded at {} (UTC time).'.format(latest_file_datetime))
break
return latest_file_path
file_path = load_latest_file_from_datalake(channel_id)
data = pd.read_csv(file_path, sep=',')
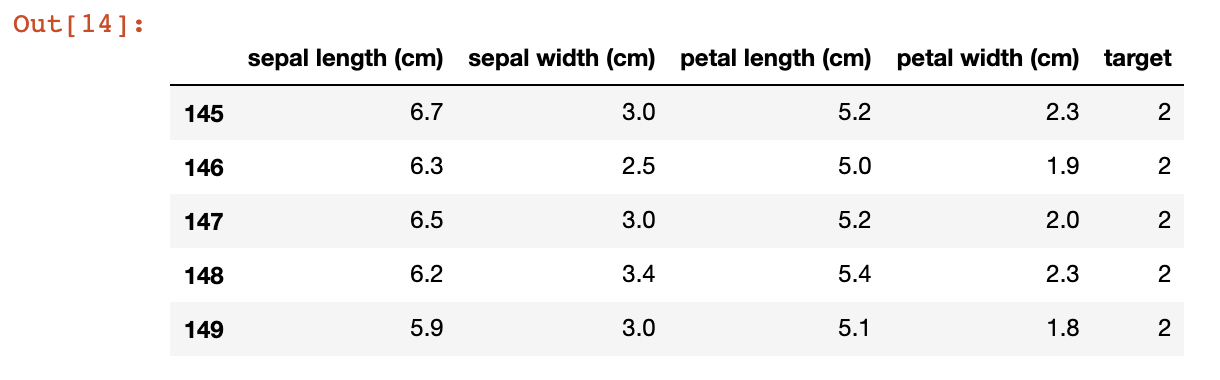
data.tail()
データレイクの中の最新のデータをロードすることができました。
ノートブックのcpuイメージには、CPU 環境で使用できる機械学習およびディープラーニングの代表的なライブラリ/フレームワークが含まれている(ライブラリ一覧)ため、すぐにデータの分析や機械学習モデルの開発を行うことが可能です。
参考
ABEJA Platform SDKを使用して、データレイクのチャンネルを作成してファイルをアップロードしたり、データレイクから複数のファイルを取得したりすることも可能です。手順については、公式ドキュメントを参照して下さい ![]()
https://sdk-spec.abeja.io/datalake/sample_tutorial.html