はじめに
本記事は、以下の手順をまとめた記事の後編です。
(前編)
- コンソールを用いて、ローカル環境からABEJA Platformにファイルをアップロードする
- ABEJA PlatoformのNotebook上からDataLakeのファイルを参照する
(後編) - ABEJA PlatformのJobを用いて、scikit-learnを使った機械学習モデルを学習する
- モデルをWeb APIとしてデプロイする
前編はこちらの記事を参照して下さい。
https://qiita.com/yushin_n/items/adb48e5ffd2229d1eacf
ABEJA PlatformのJobを用いて、scikit-learnを使った機械学習モデルを学習する
学習用コードの用意
ABEJA PlatformのJobで学習を実行するために、まず、学習用コードを所定のトレイニングハンドラー関数の形式で用意します。
今回使用したサンプルコードは、こちらから取得可能です。
https://github.com/abeja-inc/Platform_handson/tree/master/iris_scikit-learn
Jobのバージョンの作成
Job DefinitionのCreate Versionをクリックして、学習用コードをzip圧縮したファイルをドラッグ&ドロップします。
Runtimeには、使用するイメージを選択します。Handlerには、ファイル名.ハンドラー関数名を指定します。今回はtrain.pyのhandler関数を呼び出すため、train.handlerを入力します。

Version 1が作成されました。
コンソールからパラメータを変更するため、エポック数、C、ABEJA PlatformのDataLakeのチャンネルIDを環境変数から取得するようにしています。
また、コンソール上にAccuracyとLossを表示するために、ABEJA Platform SDKのStatisticsを使用しました。
# import library
import numpy as np
import os
import pandas as pd
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
from sklearn.metrics import log_loss
from sklearn.externals import joblib
from abeja.datalake import Client as DatalakeClient
from abeja.train import Client as TrainClient
from abeja.train.statistics import Statistics as ABEJAStatistics
# define training result dir
ABEJA_TRAINING_RESULT_DIR = os.environ.get('ABEJA_TRAINING_RESULT_DIR', '.')
# define parameters
epochs = int(os.environ.get('NUM_EPOCHS', 1))
c = float(os.environ.get('C', 1))
# define datalake channel_id and file_id
channel_id = os.environ.get('CHANNEL_ID', 'XXXXXXXXXX')
def load_latest_file_from_datalake(channel_id):
datalake_client = DatalakeClient()
channel = datalake_client.get_channel(channel_id)
# load latest file path
for f in channel.list_files(sort='-uploaded_at'):
latest_file_path = f.download_url
latest_file_datetime = f.uploaded_at
print('load file uploaded at {} (UTC time).'.format(latest_file_datetime))
break
return latest_file_path
def handler(context):
"""
the following csv file should be stored in the datalake channel.
---
sepal_lenght (cm), sepal_width (cm), petal_lenght (cm), petal_width (cm), target
float, float, float, float, int
---
"""
iris = datasets.load_iris()
file_path = load_latest_file_from_datalake(channel_id)
data = pd.read_csv(file_path, sep=',')
X = data[iris.feature_names].values.astype('float64')
Y = data['target'].values.astype('int64')
print('successfully load datalake channel file.')
# train test split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, train_size=0.7)
# define model
model = LogisticRegression(solver='lbfgs', C=c,
multi_class='multinomial', max_iter=epochs)
# train model
model.fit(X_train, Y_train)
# evaluate model
train_acc = accuracy_score(Y_train, model.predict(X_train))
train_loss = log_loss(Y_train, model.predict_proba(X_train))
valid_acc = accuracy_score(Y_test, model.predict(X_test))
valid_loss = log_loss(Y_test, model.predict_proba(X_test))
# update ABEJA statisctics
train_client = TrainClient()
statistics = ABEJAStatistics(num_epochs=epochs, epoch=epochs)
statistics.add_stage(name=ABEJAStatistics.STAGE_TRAIN,
accuracy=train_acc,
loss=train_loss)
statistics.add_stage(name=ABEJAStatistics.STAGE_VALIDATION,
accuracy=valid_acc,
loss=valid_loss)
train_client.update_statistics(statistics)
print('Train accuracy is {:.3f}.'.format(train_acc))
print('Train loss is {:.3f}.'.format(train_loss))
print('Valid accuracy is {:.3f}.'.format(valid_acc))
print('Valid loss is {:.3f}.'.format(valid_loss))
# save model
joblib.dump(model, os.path.join(ABEJA_TRAINING_RESULT_DIR, 'model.pkl'))
Training Jobの作成
続いて、Jobsをクリックして、Create Training Jobをクリックします。
ファイルが保存されているDataLakeのCHANNEL_IDを、環境変数として設定します。

ジョブを作成すると、学習が開始されます。
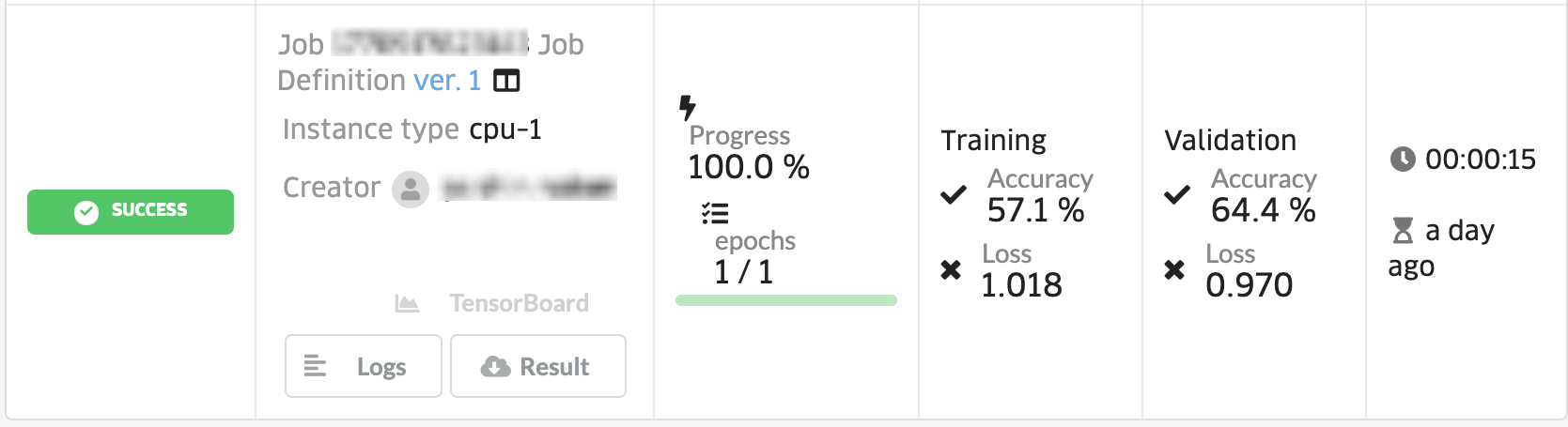
Accuracyが低いため、パラメータを変更して、再度学習をしてみます。先ほどのCreate Training Jobの画面から、NUM_EPOCHSとCを指定します。
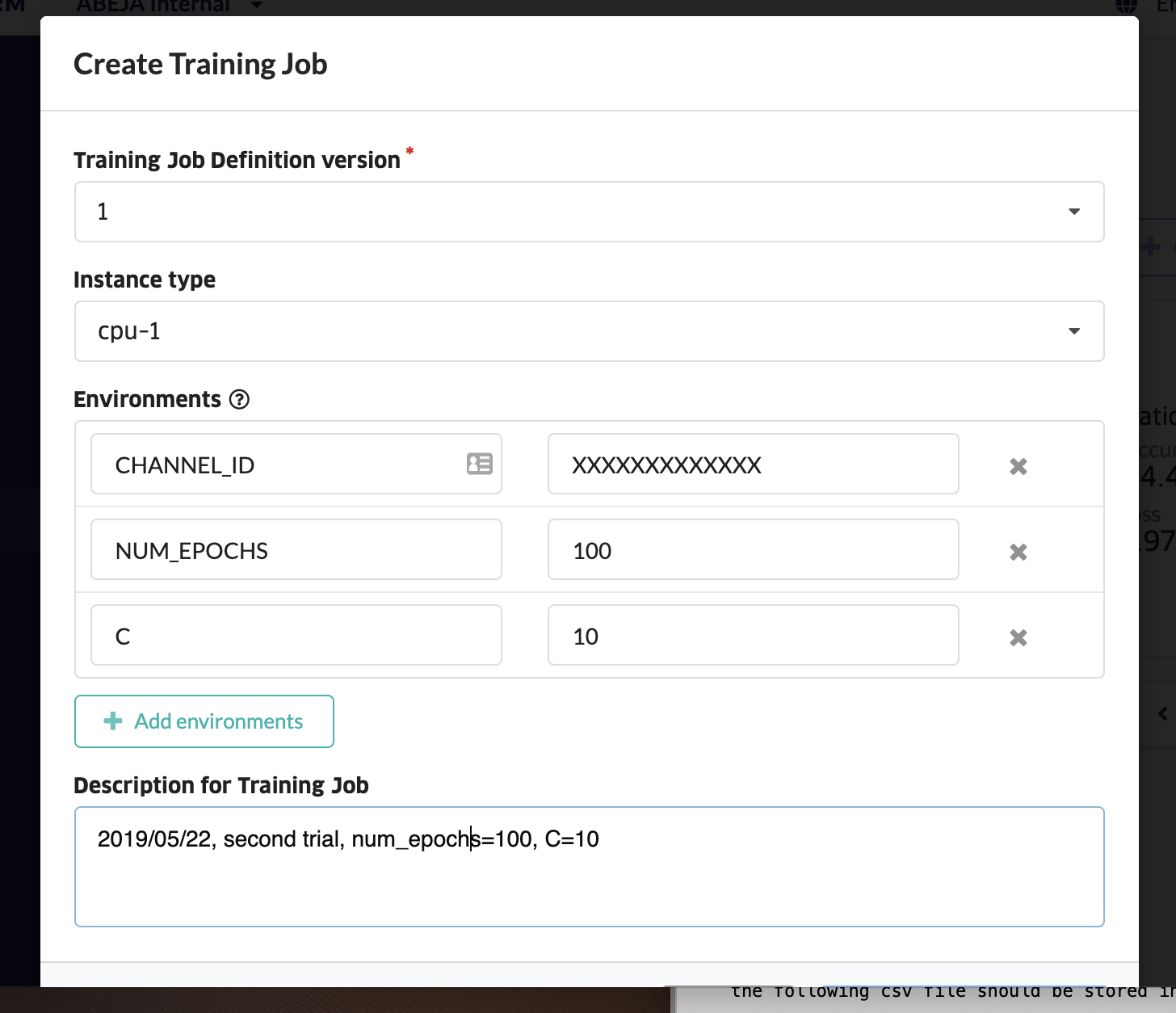
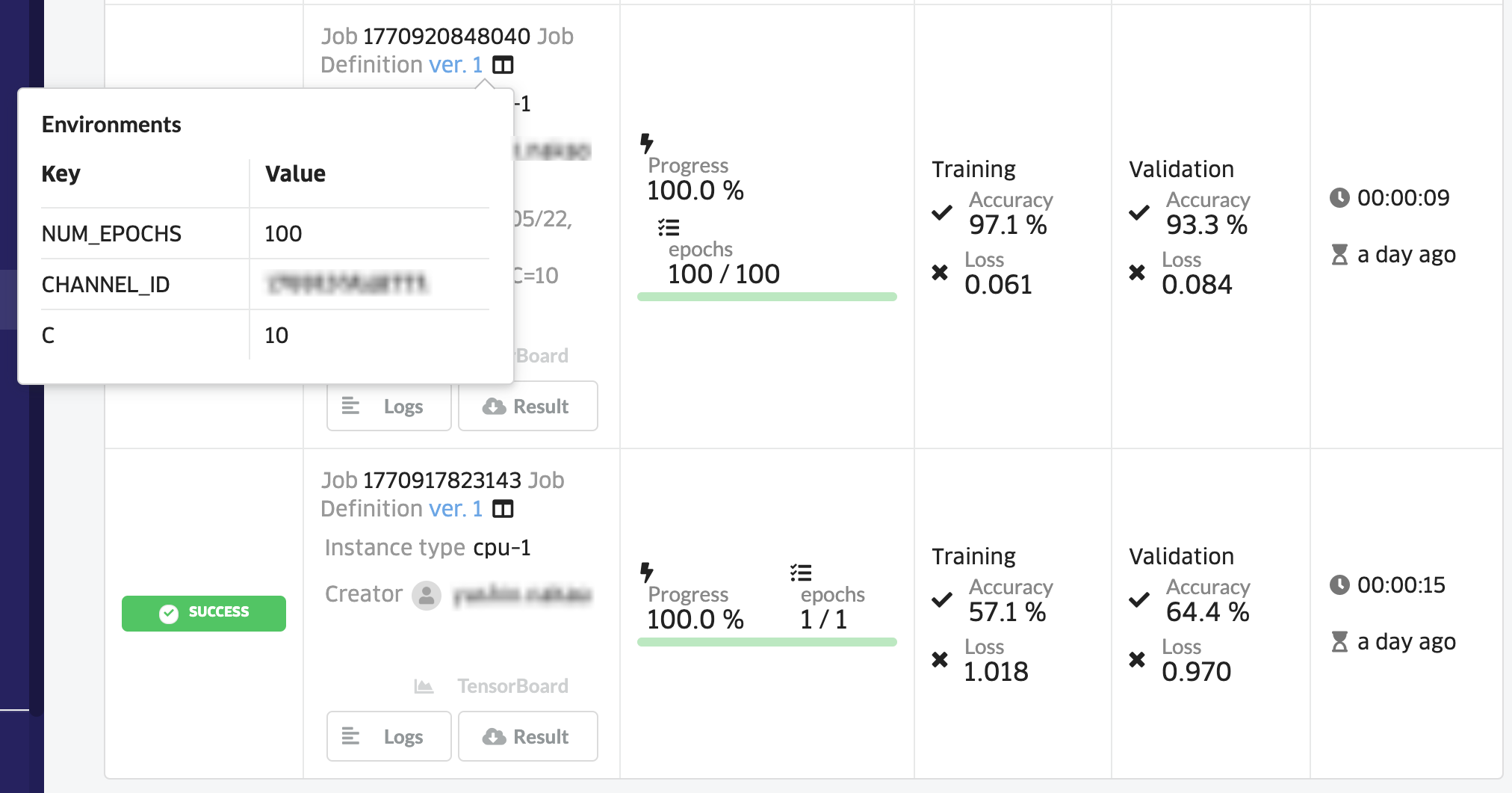
Validation Accuracyが93.3%まで上がりました!
指定した環境変数は、Ver.1の右隣のアイコンをクリックして確認することができます。
モデルをWeb APIとしてデプロイする
推論用コードの用意
先ほど学習したモデルをWeb APIとしてデプロイします。
まず、推論用コードをモデルハンドラー関数の形式で用意します。
# prediction
import os
import pandas as pd
import json
import numpy as np
from sklearn.externals import joblib
model = joblib.load(os.path.join(os.environ.get('ABEJA_TRAINING_RESULT_DIR', '.'), 'model.pkl'))
def decode_predictions(result):
categories = {
0: 'setosa',
1: 'versicolor',
2: 'virginica'
}
result_with_labels = [{"label": categories[i], "probability": score} for i, score in enumerate(result)]
return sorted(result_with_labels, key=lambda x: x['probability'], reverse=True)
def handler(_iter, ctx):
'''
_iter: json file
{"iris": {"sepal_length (cm)": "XX",
"sepal_width (cm)": "XX",
"petal_length (cm)": "XX",
"petal_width (cm)": "XX"}}
'''
for iter in _iter:
sepal_length =iter['iris']['sepal_length (cm)']
sepal_width = iter['iris']['sepal_width (cm)']
petal_length = iter['iris']['petal_length (cm)']
petal_width = iter['iris']['petal_width (cm)']
x = np.array([[sepal_length, sepal_width, petal_length, petal_width]]).astype('float64')
result = model.predict_proba(x)[0]
sorted_result = decode_predictions(result.tolist())
yield {"result": sorted_result}
モデルの作成
コンソールのModelのCreate Modelをクリックします。Jobと同様に、Runtimeには、使用するイメージを選択して、Handlerには、ファイル名.ハンドラー関数名を指定します。また、Deploy after creatingにチェックを入れます。
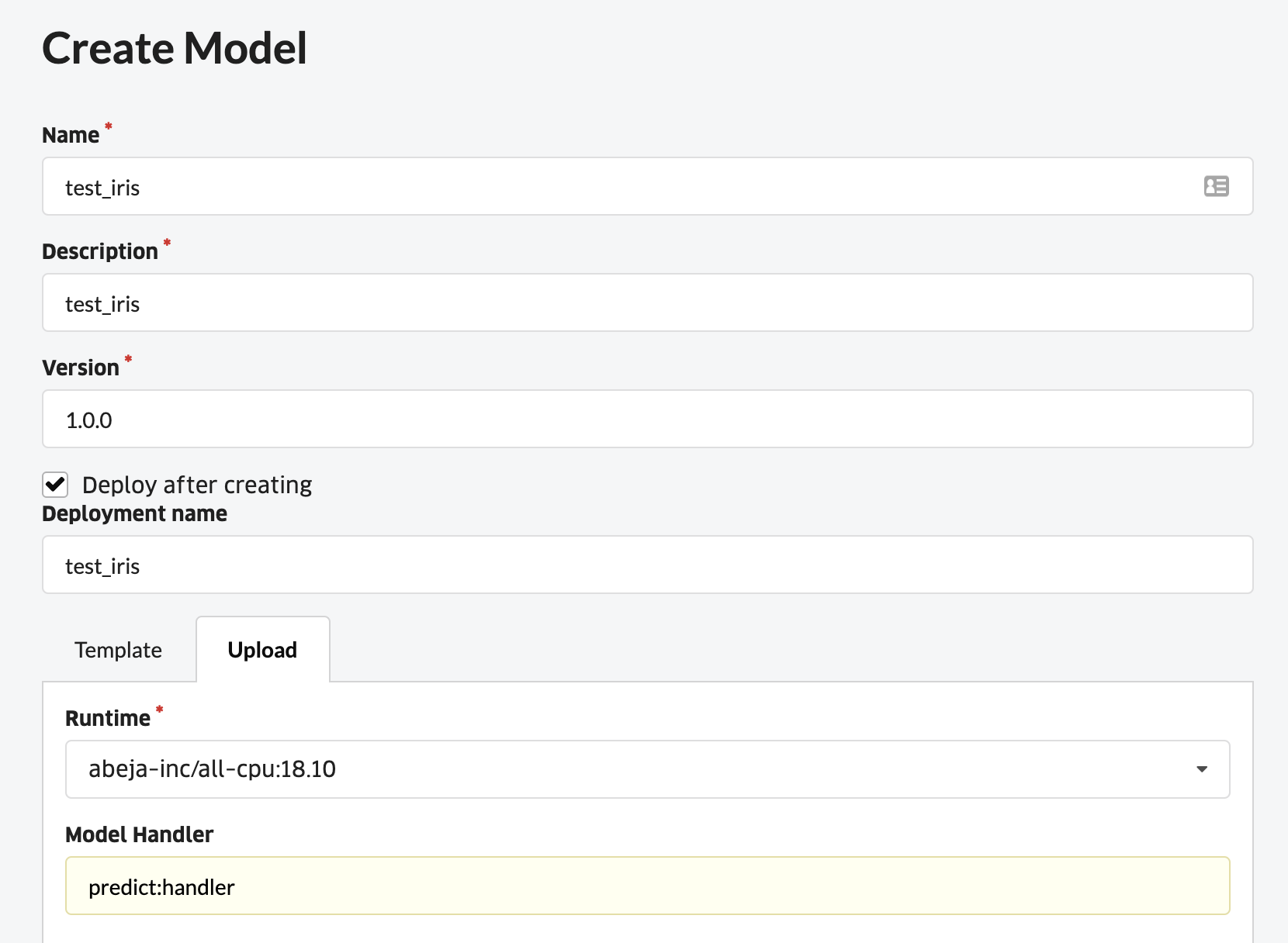
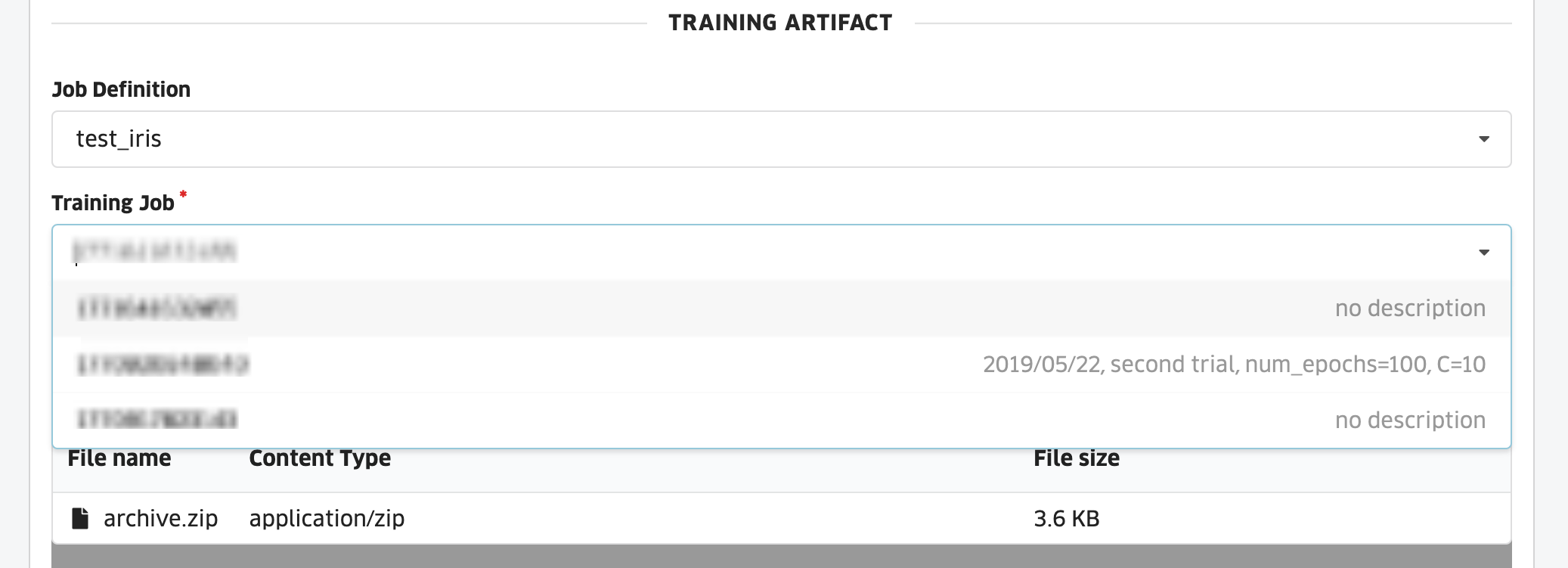
Training Jobから、デプロイしたいモデルが保存されているJobを選択した後、推論用コードをzip圧縮したファイルをドラッグ&ドロップします。
JobのDescriptionにメモを書いておくと、いい感じに見分けることができます。
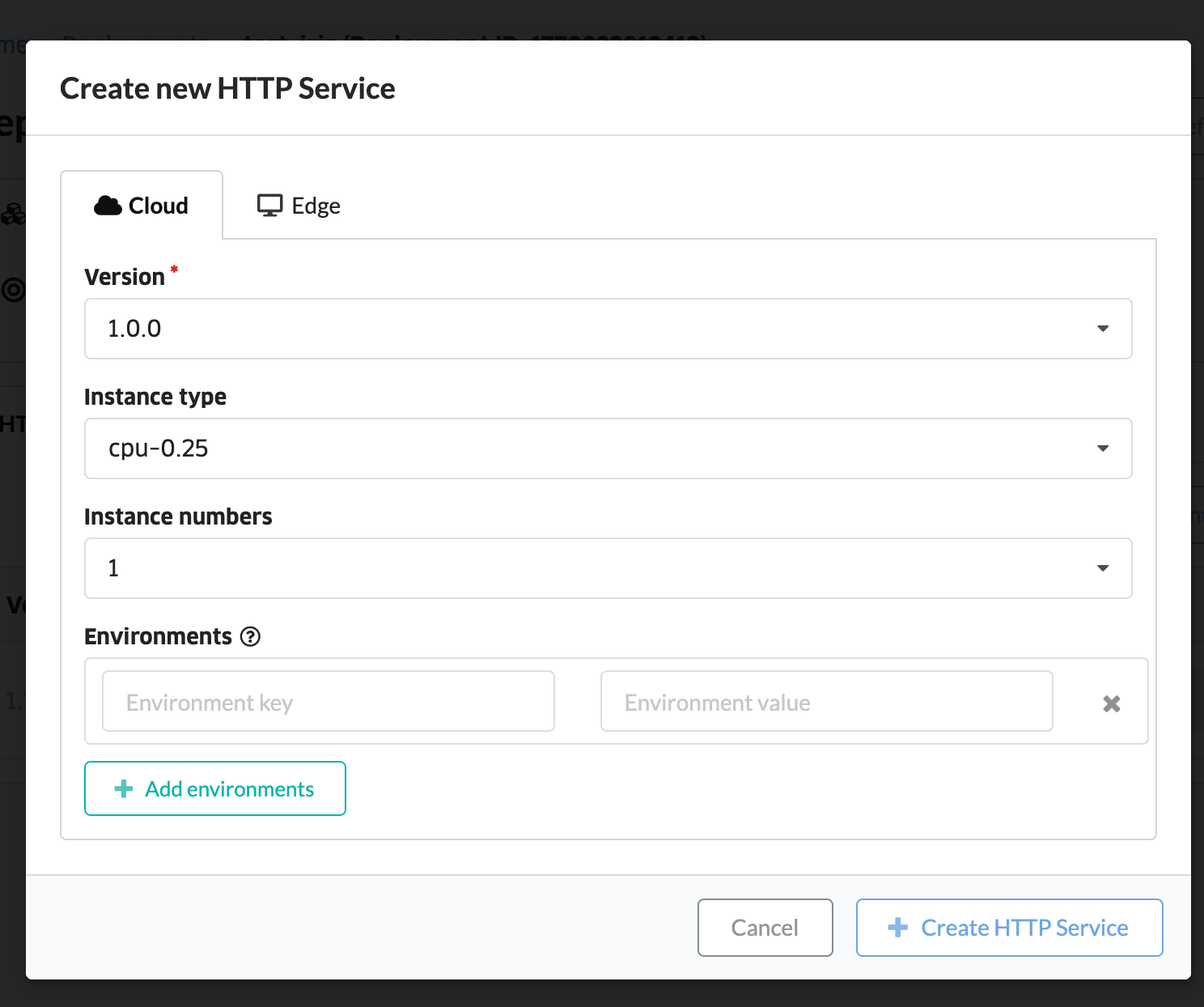
モデルのデプロイ
コンソールのDeploymentから、先ほど作成したデプロイメントをクリックします。そしてCreate HTTP Serviceをクリックします。
モデルがWeb APIとしてデプロイされました。
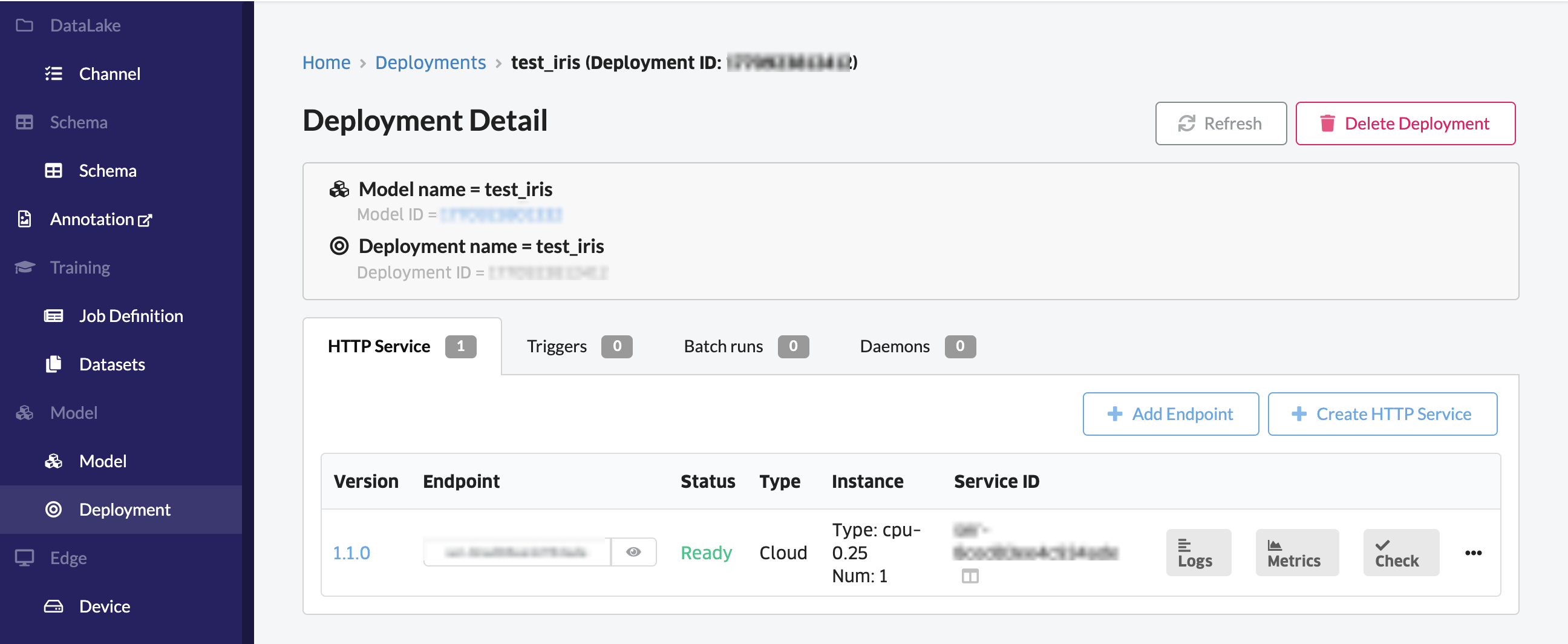
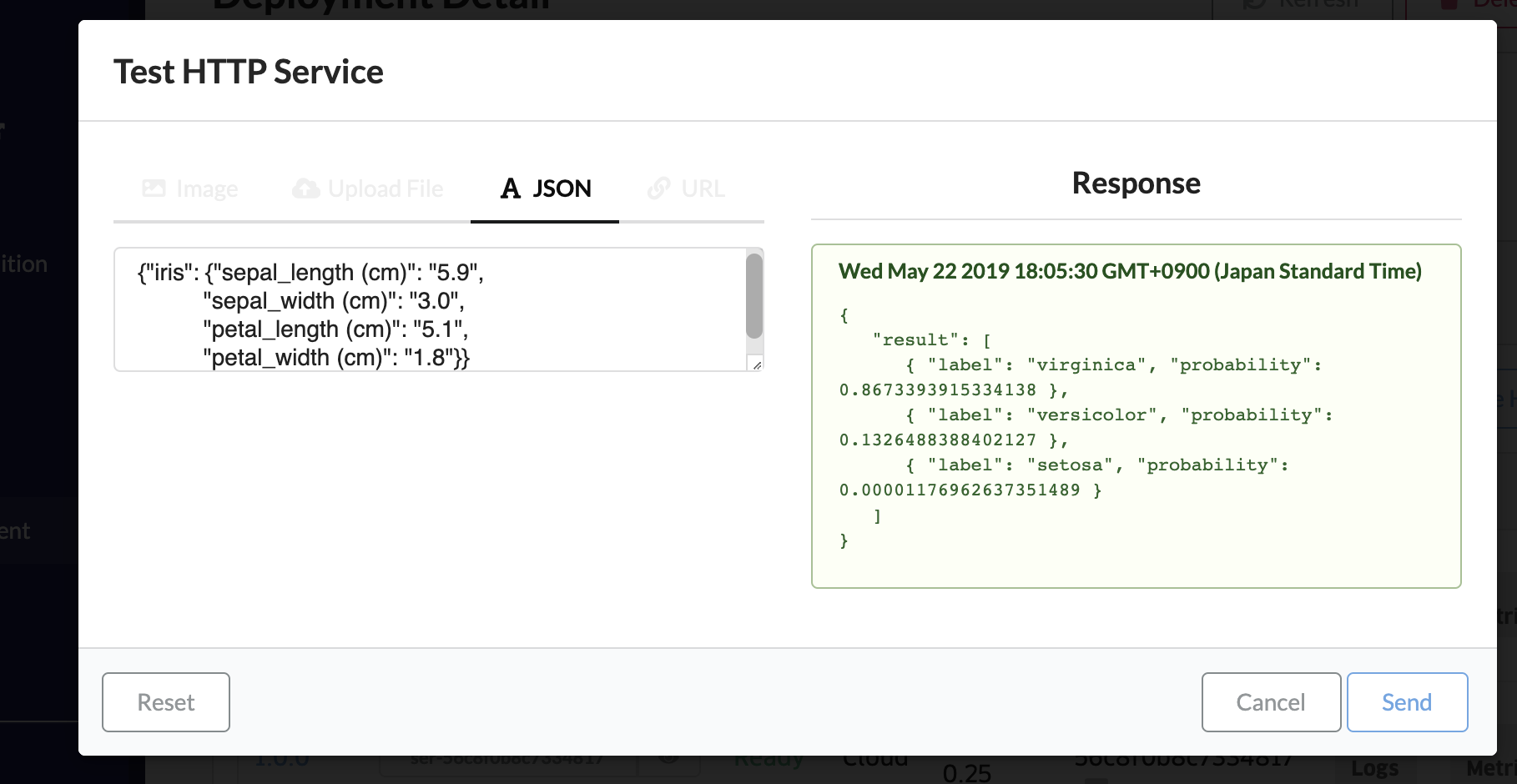
モデルのテスト
curlコマンドでエンドポイントにリクエストを送ったり、Checkをクリックして、ブラウザ上でテストを行ったりすることができます。
まとめ
本記事では、ABEJA Platformで、DataLakeにファイルを保存して、scikit-learnを使った機械学習モデルを学習・デプロイする手順をまとめました。ABEJA Platformには、データ蓄積〜モデル学習〜運用のサイクルを回してモデルのバージョンが更新された場合に、Web APIを容易に切り替えることができる機能もあります。詳しくは公式ドキュメントを参照下さい ![]()
https://developers.abeja.io/getting-started-guide/continuous-machine-learning-delivery/redeploy-http-service/
参考
サンプルコード
https://github.com/abeja-inc/Platform_handson/tree/master/iris_scikit-learn