
はじめに
「データリネージ」という言葉、
データカタログやデータガバナンスの文脈で見かけることがありますよね。
この記事では、
データリネージとは何か と なぜ大事なのか を、ざっくり整理します。
ざっくり言うと
データリネージは、
「そのデータが、どこから来て、途中でどう変わって、最終的にどこで使われているか」をたどれるようにする考え方 です。
IBM は data lineage を「データがどこで生まれ、どう変化し、最終的にどこへ行くかを追跡すること」と説明しており、Microsoft も「データの起点から、組織内で時間とともにどう移動するかをたどるライフサイクル」と整理しています。

たとえば、ある売上ダッシュボードの数字を見たときに、
- 元データはどの業務システムから来たのか
- 途中でどんなETL / ELT処理が入ったのか
- どのテーブルに集約されたのか
- その結果がどのBIレポートやAIアプリで使われているのか
が分かる状態です。
つまり、データリネージは
データの“流れの見取り図” のようなものです。
なぜデータリネージが必要なのか
データ活用でよくあるのが、
「この数字、どこから来たの?」
という状況です。
たとえば、売上ダッシュボードの数値が急に変わったとします。
そのとき、データリネージが見えていなければ、
- 元データが変わったのか
- ETLの処理が変わったのか
- 集計ロジックが変わったのか
- BI側の定義が変わったのか
を追うのは時間がかかります。

ここでリネージが見えていると、
どこを見ればいいかがすぐ分かるようになります。
つまり、
- 信頼性の確認
- 影響範囲の把握
- 障害調査
をやりやすくするのが役割です。
データカタログでも lineage が分かると 「このデータを安心して使えるか」判断しやすい状態になります。
具体例で考える
例えばこんな流れです。
受注DB → ETL処理 → DWH/レイクハウスの売り上げテーブル → 部門向けデータマート → BIダッシュボード
このとき、営業部が見ている「月別売上」の数字に違和感があったとします。
データリネージがないと、
「どこがおかしいのか」を人づてに探すしかありません。
でも、データリネージが見えれば、
- このダッシュボードはどのデータマートを見ているか
- そのデータマートはどの集計テーブルから作られたか
- その集計テーブルはどのETLジョブで更新されているか
- そのETLジョブはどの受注テーブルを読んでいるか
をたどれます。
つまり、
結果から原因まで逆算できる
のがデータリネージです。

データカタログとの違い
ここは混同しやすいポイントです。
- データカタログ:何のデータがあるかを探す・理解する
- データリネージ:そのデータがどう流れてきたかを見る
イメージとしては、
- カタログ=一覧表・案内板
- リネージ=経路図
です。
つまり、
カタログが 「何があるか」 を見せるものだとすると、
リネージは 「どうつながっているか」 を見せるものです。

この2つは別物ですが、実際にはかなり相性がよく、
多くの製品ではカタログの中でリネージを一緒に見られるようになっています。
たとえば OCI Data Catalog では、Data Integration、Data Flow、カスタムアプリからの lineage を表レベル・列レベルで表示できます。Microsoft Purview は raw data から transformed data、可視化に使われるデータまでの lineage を扱えます。Google Cloud の Knowledge Catalog では lineage をグラフやリスト、API で参照でき、Databricks Unity Catalog では実行時 lineage を列レベルまで取得できます。
どこまで見えると嬉しいか
リネージには粒度があります。
テーブル単位
- Aテーブル → Bテーブル → ダッシュボード
まず分かりやすいのが、テーブル単位のリネージです。
これは、
-
ordersからsales_summaryが作られた -
sales_summaryがmonthly_sales_dashboardに使われている
といった、データセット同士のつながり を見るものです。

カラム単位
-
amount→total_sales -
birthdate→age_band
もう一段細かいのが、カラム単位のリネージです。
これは、
-
order_amountが集計されてmonthly_revenueになった -
customer_birthdateからage_bandが作られた
のように、どの列がどの列にどうつながったか を見ます。
Databricks や OCI Data Catalog、Google Cloud でも列レベルの lineage に対応する機能があります。
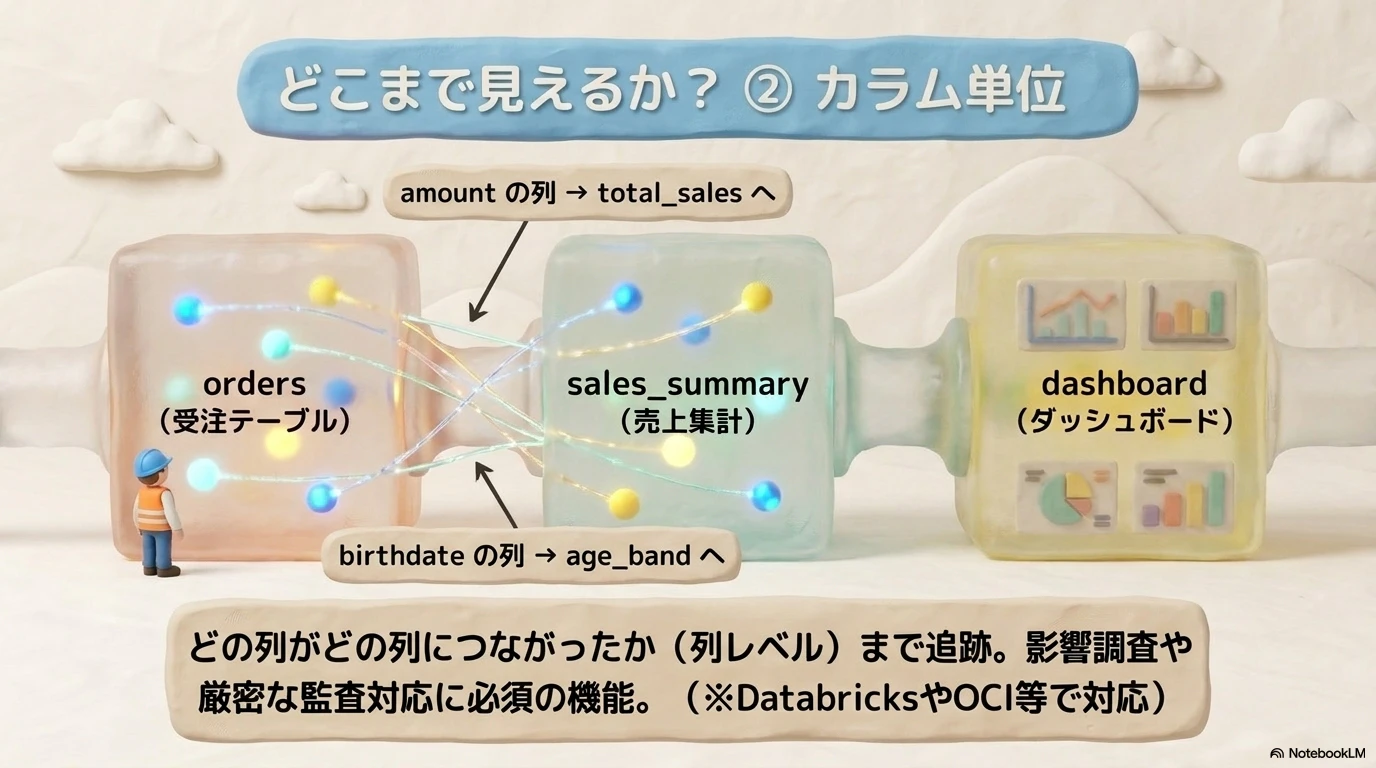
実務では、まずはテーブル単位で全体像が見えるだけでもかなり有用です。
その上で、影響調査や監査対応まで考えると、カラム単位まで追えるとさらに強いです。
どうやって取得するのか
データリネージは、自然に勝手に生まれるわけではありません。
多くの場合は、
- ETL / ELTツール
- SQLエンジン
- オーケストレーター
- データカタログ
- BIツール
などが実行ログやメタデータをもとに収集します。
ただし、すべての処理が自動で取れるとは限りません。
ツールによっては自動取得できる範囲に差があり、未対応の部分は手動登録やカスタム連携が必要になります。Microsoft Purview には manual lineage があり、OCI Data Catalog でも custom applications から lineage を取り込めます。また、OpenLineageは lineage メタデータ収集のためのオープン標準として使われています。
なので、
データリネージは 「ツールを入れれば全部終わり」ではなく、どこまで自動で取り、どこを運用で補うかを考えるもの と捉えるのが大事です。

データリネージがあっても、万能ではない
データリネージが見えていても、
それだけで データ品質が担保されるわけではありません。
データリネージがあっても、
- データが正しい
- 定義が揃っている
とは限りません。
あくまで
「流れが見えるだけ」
です。
たとえば、
- 元データが古い
- 加工ロジックが間違っている
- 欠損値が多い
- 定義そのものがチーム間でずれている
といった問題は、リネージだけでは解決しません。
ただしその“流れ”が分かることで、
他の問題も追いやすくなります。

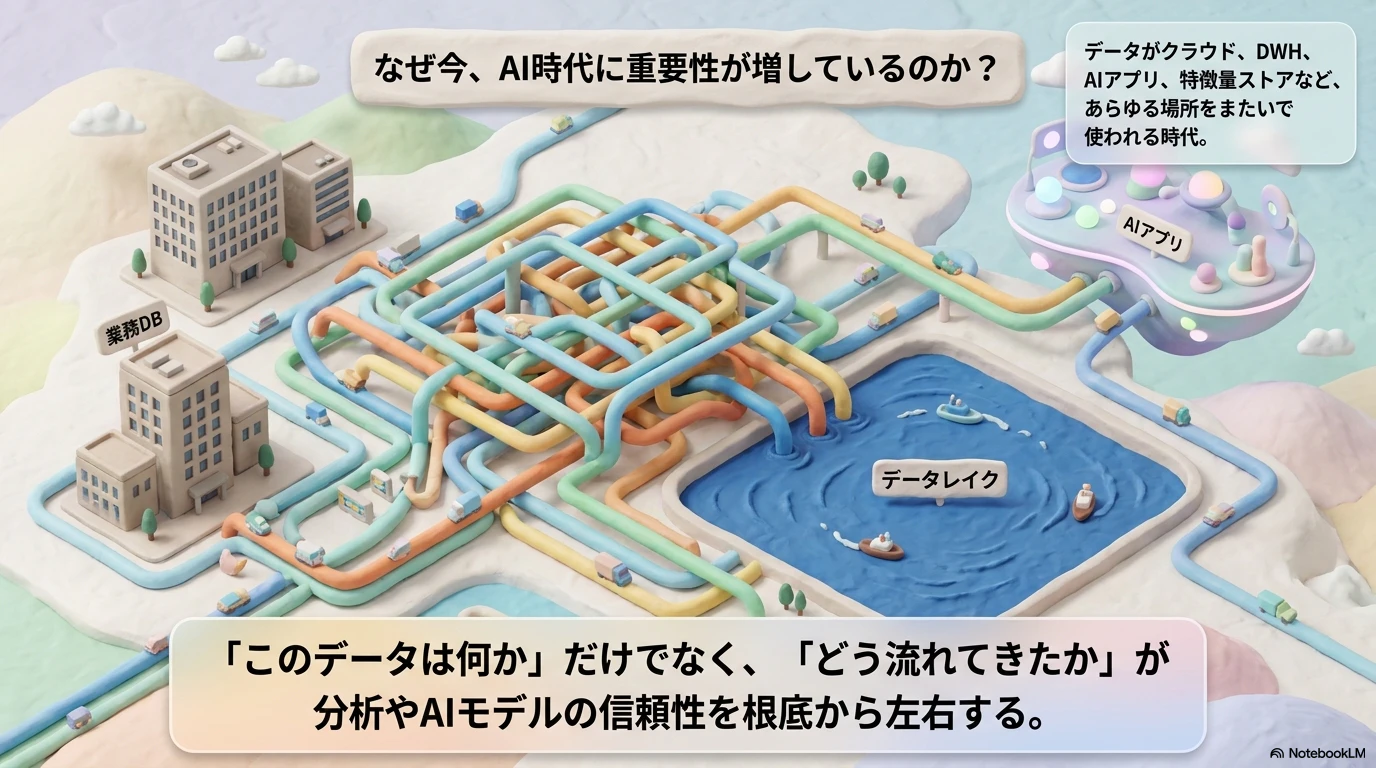
AI時代ほど重要になる
最近はデータが
- 業務DB
- DWH
- データレイク・レイクハウス
- BI
- AIアプリ
- ベクトル検索や特徴特徴量管理
など、いろんな場所をまたいで使われます。
その結果、
「このデータは何か」だけでなく
「どう流れてきたか」も重要になる
という状況になっています。
データが分散するほど、リネージの価値は上がります。
特に、分析やAIの結果を業務で使うなら、元データとのつながりや、変更時の影響範囲が追えることはかなり大事です。
まとめ
データリネージは、
データがどこから来て、どう加工され、どこで使われているかを追跡する考え方 です。
ポイントをまとめると、次のとおりです。
- データカタログが「何があるか」を見せるなら、データリネージは「どう流れているか」を見せる
- 信頼性の確認、影響調査、障害対応、監査対応に役立つ
- テーブル単位だけでも有用だが、カラム単位まで見えるとさらに強い
- 自動取得できる部分と、手動で補う部分がある
- ただし、リネージだけで品質や定義の問題までは解決しない
つまりデータリネージは、
データ活用のための“地図”であり、“経路図” のようなものです。
データが増え、加工も複雑になるほど、
「正しいデータがあるか」だけでなく、
「そのデータがどうやって今ここに来たのか」 を説明できることが重要になっていくのだと思います。
