はじめに
今回は、Oracle Autonomous AI DatabaseのData Transformsを使って、Snowflakeで作成したS3上のSnowflake-managed Iceberg表にデータ追加してみます。
1. 今回の構成
今回は、Oracle Autonomous DatabaseのData Transforms(データ変換) を使って、Snowflakeで作成したS3上のSnowflake-managed Iceberg表にデータを追加してみます。
Data Transformsは、データ・ロード、データ・フロー、ワークフローなどの形でデータ変換やデータ移動を設計できる機能です。今回使う中心機能は、Data Flowです。Data Flowでは、ソースのデータ・エンティティからターゲットのデータ・エンティティへ、列マッピングや変換処理を定義してデータを移動できます。この記事では、Inline Viewをソースにして、Snowflake接続上の表へロードするData Flowを作成します。
検証のポイントは、SnowflakeのWorksheetでINSERT文を実行するのではなく、ADB側からData Transformsの画面上でData Flowを作成・実行してデータを追加するという点です。
今回やること
- Data TransformsでInline Viewを作る
- Inline ViewをData Flowのソースにする
- Snowflake接続経由でSnowflake表へロードする
- ADBからDBMS_CATALOG経由で結果を確認する
1-1. 進め方
2つの方法で実行します。
-
方法1:Data Transformsでステージング表経由ロード
- Inline View
→ Snowflake通常表DT_CUSTOMER_ADD_STG
→ Snowflake-managed Iceberg表CUSTOMER_ICEBERG
- Inline View
-
方法2:Data TransformsでIceberg表へ直接ロード
- Inline View
→ Snowflake-managed Iceberg表CUSTOMER_ICEBERG
- Inline View
まずは、いきなり対象のIceberg表へロードせず、まずSnowflakeの通常表でステージング表を作りデータを挿入し、そこからIceberg表へロードします。(方法1)
この構成にすると、Iceberg表へ入れる前に中間表でデータを確認できるため、直接ロードよりも安全に検証できます。
動きを確認した後、方法2ではステージング表を使わず、Inline ViewからSnowflake-managed Iceberg表へ直接ロードします。
なお、ここでいう「Iceberg表へ直接ロード」は、Data TransformsがS3上のIcebergファイルやmetadata.jsonを直接更新するという意味ではありません。Data Transformsから見ているターゲットは、Data Transformsで作成したSnowflake接続上のCUSTOMER_ICEBERGです。Icebergのデータファイルやメタデータの更新はADB側で実施するのではなく、Snowflakeが担当します。
1-2. 前提
この記事では、以下がすでに作成済みである前提で進めます。
Snowflake:
Database : ICEBERG_TUTORIAL_DB
Schema : PUBLIC
Warehouse : ICEBERG_TUTORIAL_WH
Iceberg表 : CUSTOMER_ICEBERG
ADB:
DBMS_CATALOGでIcebergカタログをマウント済み
DBMS_CATALOGのカタログ名:
POLARIS_CAT
ADBからは、DBMS_CATALOGでマウントしたカタログを通して、次のようにIceberg表を参照します。
SELECT *
FROM "PUBLIC"."CUSTOMER_ICEBERG"@POLARIS_CAT;
つまり、データ追加の確認をする際流れは次のようになります。
- Data TransformsでSnowflake-managed Iceberg表へデータ追加
↓ - SnowflakeがIcebergデータファイルとメタデータを更新
↓ - ADBから
DBMS_CATALOG経由でCUSTOMER_ICEBERGを確認
1-3. 今回使うInline Viewとは
今回は、Data TransformsのInline Viewを使っていきます。
Inline Viewは、Data Transforms上で作成できるデータ・エンティティの一種です。通常のデータ・エンティティは、データベース上の表やビューをインポートして使います。一方、Inline Viewでは、Data Transforms上でSELECT文を直接定義し、そのSELECT結果を1つのデータ・エンティティとして扱えます。
具体的には、QueryタブにSELECT文を入力してInline Viewを作成し、Validate後に戻り列やプレビューを確認できるデータ・エンティティとなります。
今回、動作確認のために1行だけ追加していくため、ADB上に物理的な作業表を作成せず、Inline Viewを作成しそれを仮想的なソース表にしていきます。
2. Snowflake側でData Transforms用ユーザーとロールを作る
Data TransformsからSnowflakeへ接続するための専用ユーザーとロールを作ります。今回はData Transforms用に、必要な表にだけ書き込めるロールを作ります。
SnowflakeのWorksheetで以下を実行します。
USE ROLE ACCOUNTADMIN;
CREATE ROLE IF NOT EXISTS DT_ICEBERG_LOAD_ROLE;
GRANT USAGE ON WAREHOUSE ICEBERG_TUTORIAL_WH
TO ROLE DT_ICEBERG_LOAD_ROLE;
GRANT USAGE ON DATABASE ICEBERG_TUTORIAL_DB
TO ROLE DT_ICEBERG_LOAD_ROLE;
GRANT USAGE ON SCHEMA ICEBERG_TUTORIAL_DB.PUBLIC
TO ROLE DT_ICEBERG_LOAD_ROLE;
次に、Data Transformsから接続するためのSnowflakeユーザーを作成します。
CREATE USER IF NOT EXISTS DT_LOADER
PASSWORD = '<your_password>'
DEFAULT_ROLE = DT_ICEBERG_LOAD_ROLE
DEFAULT_WAREHOUSE = ICEBERG_TUTORIAL_WH
MUST_CHANGE_PASSWORD = FALSE;
GRANT ROLE DT_ICEBERG_LOAD_ROLE
TO USER DT_LOADER;
ここでは、DT_LOADERをData Transforms専用ユーザーとして使います。
確認します。
SHOW GRANTS TO USER DT_LOADER;
結果にDT_ICEBERG_LOAD_ROLEが表示されればOKです。

Iceberg表へデータを追加するため、CUSTOMER_ICEBERGに対してSELECTとINSERT権限を付与します。
GRANT SELECT, INSERT
ON TABLE ICEBERG_TUTORIAL_DB.PUBLIC.CUSTOMER_ICEBERG
TO ROLE DT_ICEBERG_LOAD_ROLE;
3. Snowflakeステージング表を作成する
方法1では、いったんSnowflakeの通常表にロードしてから、Iceberg表へ流します。Worksheet上で管理者ロールを使ってステージング表を作成します。
USE ROLE ACCOUNTADMIN;
USE WAREHOUSE ICEBERG_TUTORIAL_WH;
USE DATABASE ICEBERG_TUTORIAL_DB;
USE SCHEMA PUBLIC;
CREATE OR REPLACE TABLE DT_CUSTOMER_ADD_STG (
C_CUSTKEY INTEGER,
C_NAME STRING,
C_ADDRESS STRING,
C_NATIONKEY INTEGER,
C_PHONE STRING,
C_ACCTBAL NUMBER(12, 2),
C_MKTSEGMENT STRING,
C_COMMENT STRING
);
Data Transforms用ロールに、ステージング表への権限を付与します。
GRANT SELECT, INSERT
ON TABLE ICEBERG_TUTORIAL_DB.PUBLIC.DT_CUSTOMER_ADD_STG
TO ROLE DT_ICEBERG_LOAD_ROLE;
4. Data TransformsでSnowflake接続を作成する
ADBのDatabase ActionsからData Transforms(データ変換)を開きます。
Database Actions
→ Data Studio
→ Data Transforms
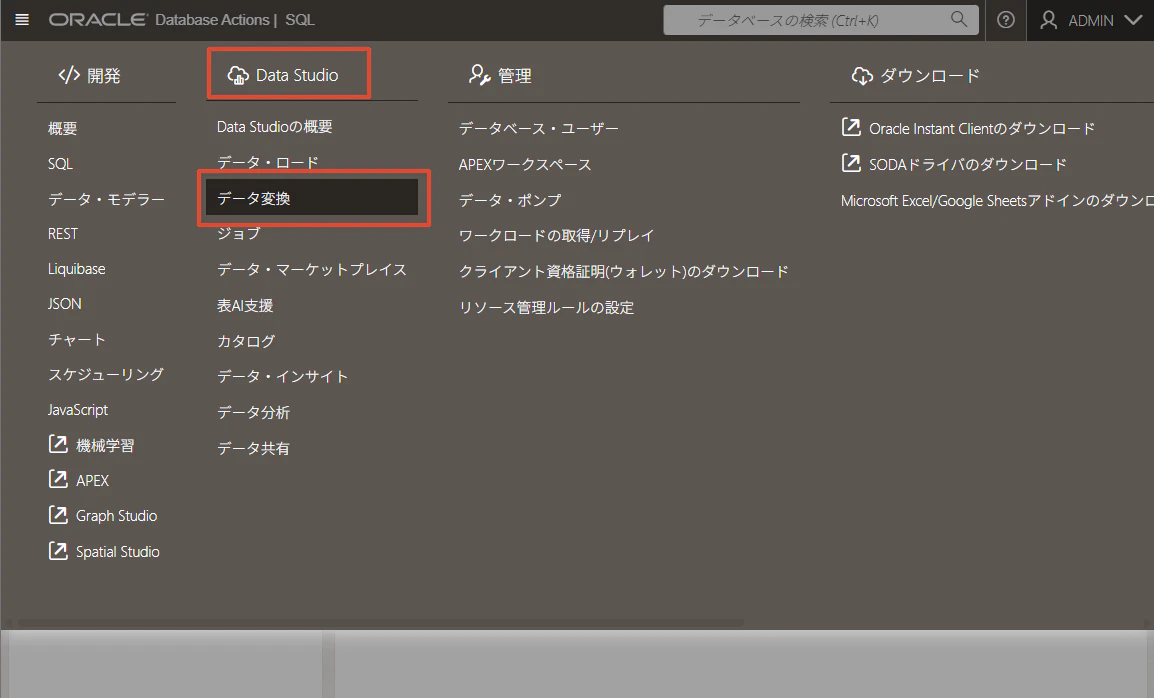
Snowflake接続を作成します。「接続の作成」をクリックします。
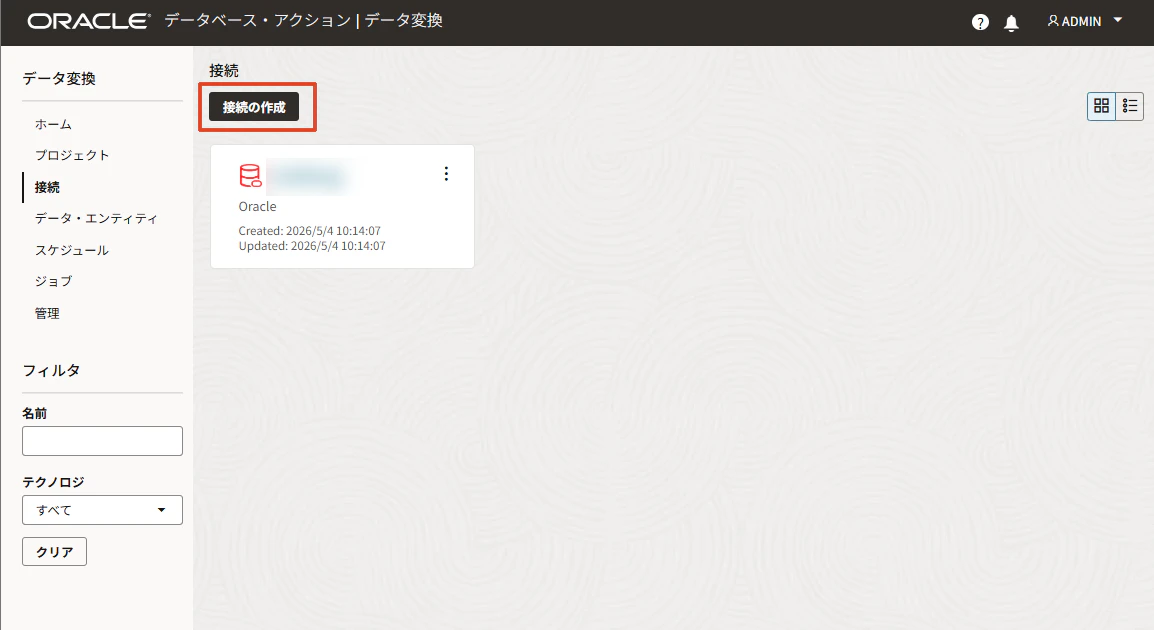
「Database」から「Snowflake」を選択し、「次へ」をクリックします。
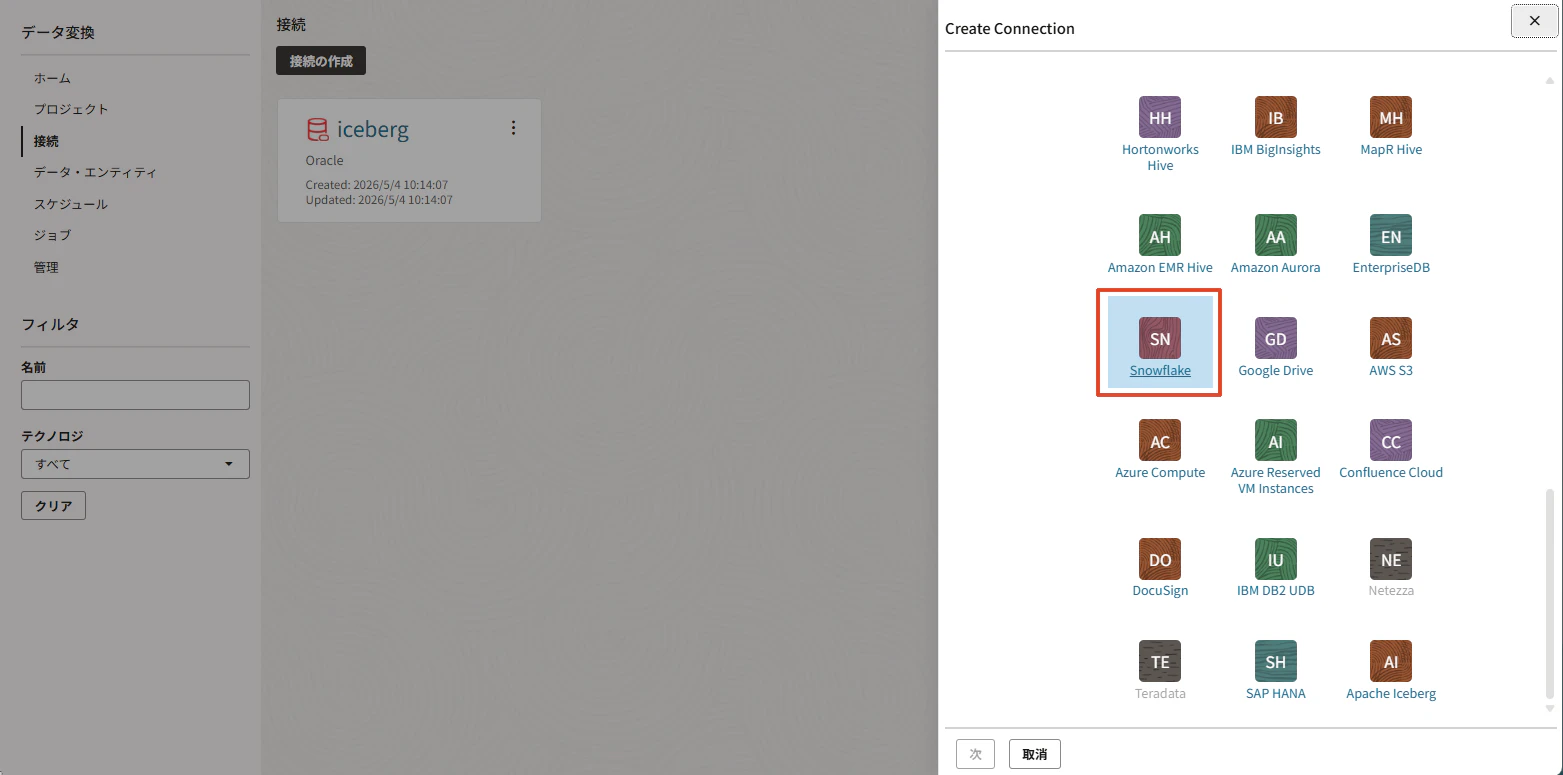
接続名は、今回は SNOWFLAKE_ICEBERG_WRITER にします。
JDBC URLは次の形式です。
jdbc:weblogic:snowflake:AccountName=<snowflake_account_name>;DatabaseName=ICEBERG_TUTORIAL_DB;Schema=PUBLIC;Warehouse=ICEBERG_TUTORIAL_WH;
例です。
jdbc:weblogic:snowflake:AccountName=abc12345.ap-northeast-1.aws;DatabaseName=ICEBERG_TUTORIAL_DB;Schema=PUBLIC;Warehouse=ICEBERG_TUTORIAL_WH;
AccountNameは、以下のコマンドで確認できます。
SELECT
CURRENT_ACCOUNT(),
CURRENT_REGION();
ユーザーには、先ほど作成したDT_LOADERを指定します。
入力後、接続のテストで接続確認します。
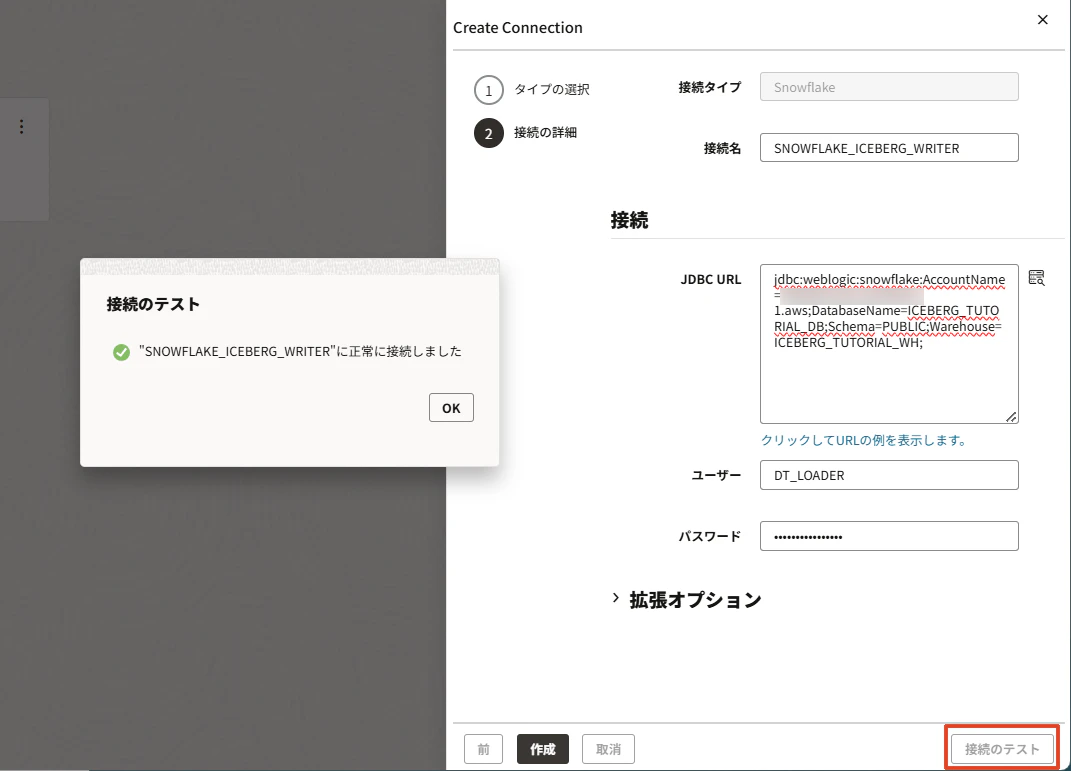
接続に成功したら、「作成」をクリックします。
Snowflake接続が作成できました。
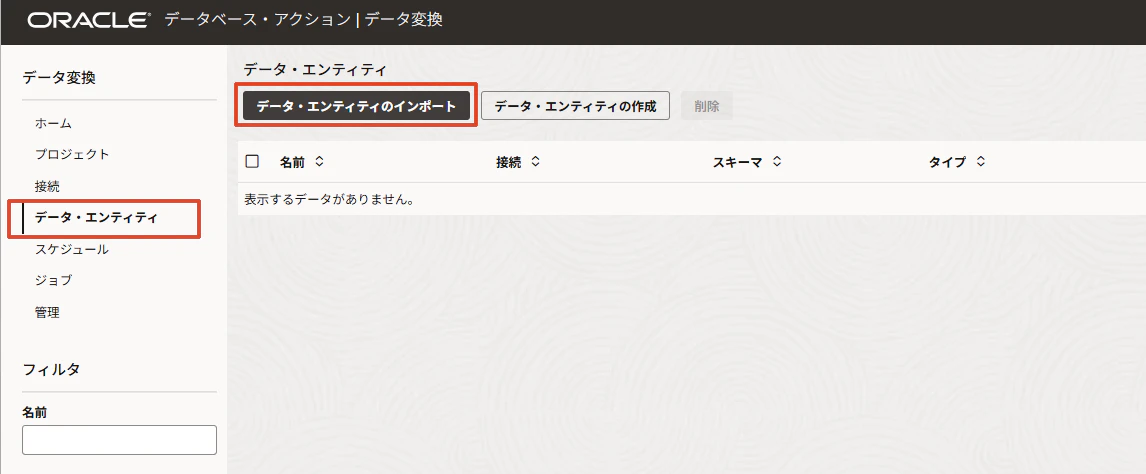
5. Data Entitiesをインポートする
Data FlowでSnowflake表を使えるように、Data Entitiesをインポートします。
Data Transforms画面で、「データ・エンティティ」>「データ・エンティティのインポート」に進みます。
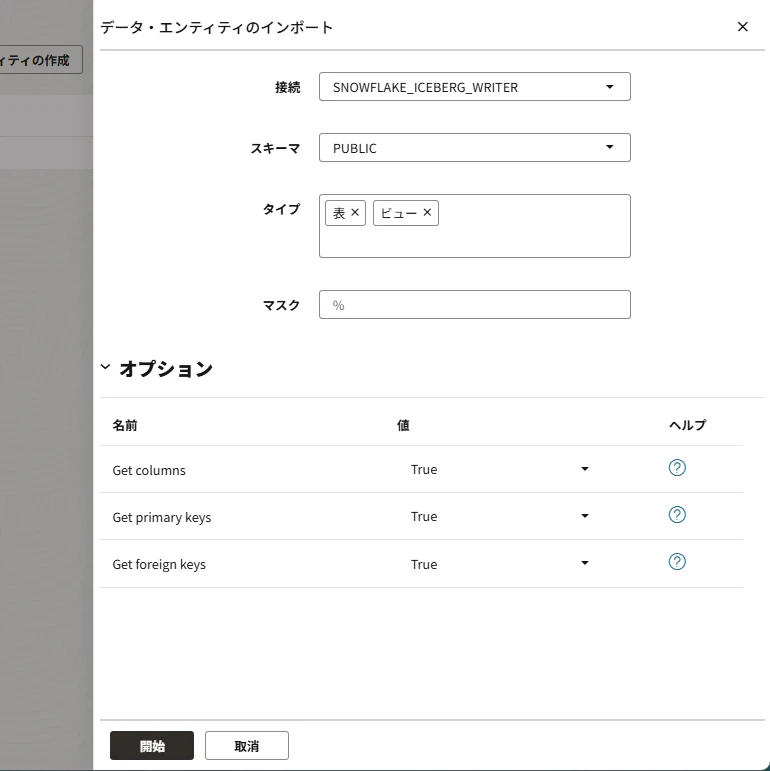
次のとおり選択し、「開始」をクリックします。
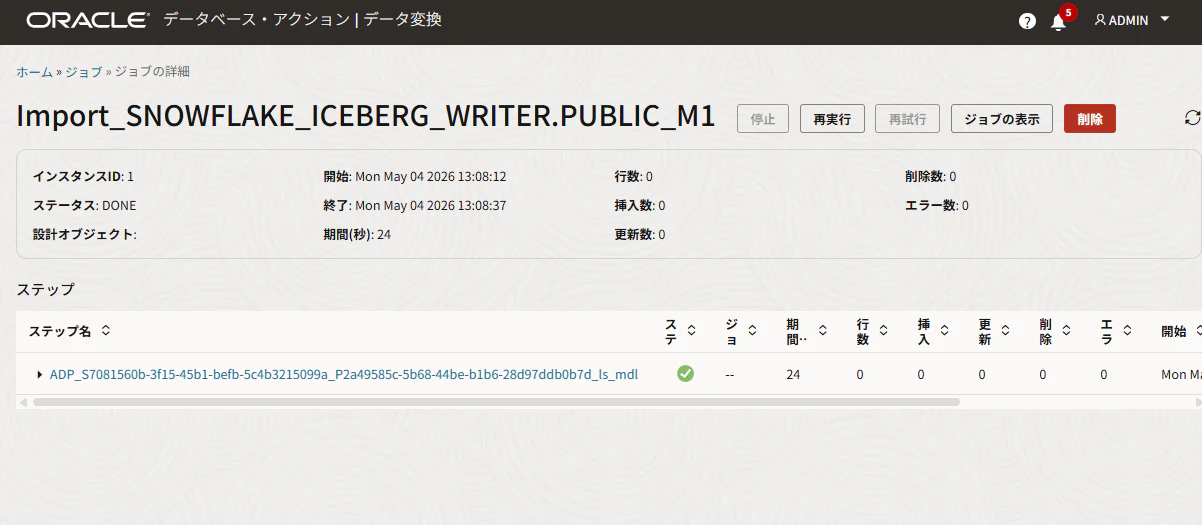
データ・エンティティのインポートが開始されました。
ジョブの詳細画面で、完了になったことを確認します。
6. Inline ViewをソースにしてData Flowを作成する
方法1:ステージング表経由ロードする
全体像
方法1では、ステージング表を経由してIceberg表へデータを追加します。
今回の検証では、Data Flowを2つ作成し、順番に実行します。
Data Flow 1:
IV_CUSTOMER_ADD_901
→ DT_CUSTOMER_ADD_STG
Data Flow 2:
DT_CUSTOMER_ADD_STG
→ CUSTOMER_ICEBERG
全体の流れは次のとおりです。
-
Inline View
1行分の検証データをSELECT文で定義
↓ -
Data Flow 1
Inline ViewからSnowflakeステージング表へロード
↓ -
Data Flow 2
Snowflakeステージング表からSnowflake-managed Iceberg表へロード
↓ -
ADB
DBMS_CATALOG経由でCUSTOMER_ICEBERGを確認
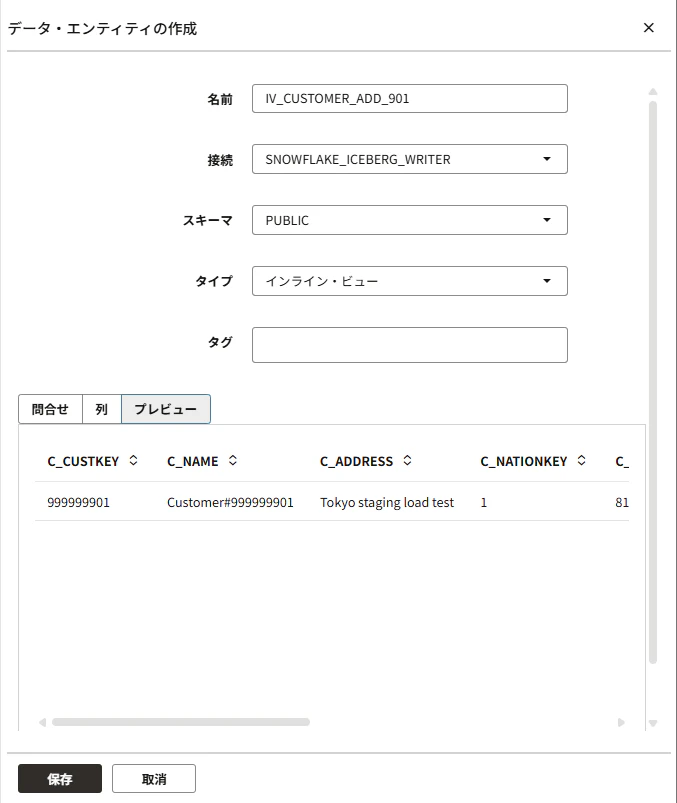
1. データ挿入用のInline Viewを作成する
Data Transformsの左メニューから進みます。
Data Entities
→ Create Data Entity
次のように入力します。
Name:
IV_CUSTOMER_ADD_901
Connection:
ADB側の接続
Schema:
ADMIN など
Type:
Inline View
Queryに次を貼ります。
ここではDUALから固定値を1行返すことで、Data Transforms上ではこのInline Viewを「1行だけ入った仮想的なソース表」のように扱えます。
SELECT
999999901 AS C_CUSTKEY,
'Customer#999999901' AS C_NAME,
'Tokyo staging load test' AS C_ADDRESS,
1 AS C_NATIONKEY,
'81-000-000-0901' AS C_PHONE,
901.11 AS C_ACCTBAL,
'BUILDING' AS C_MKTSEGMENT,
'Added via Data Transforms inline view staging route' AS C_COMMENT
FROM DUAL
その後、
Validate
Preview
Save
を実行します。
プレビューで1行見えればOKです。
2. Inline Viewからステージング表へData Flowを作成する
次にData Flowを作ります。
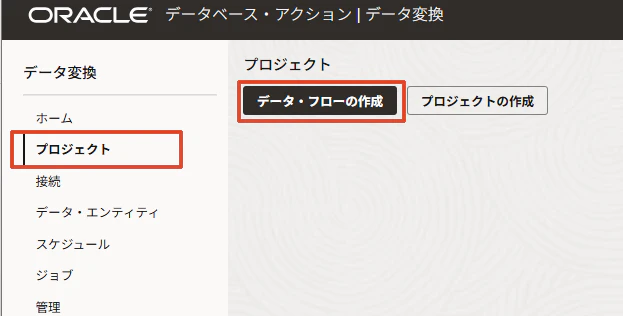
名前は例として、DF_INLINE_TO_SNOWFLAKE_STAGEとします。

接続とスキーマを選択してOKで進みます。
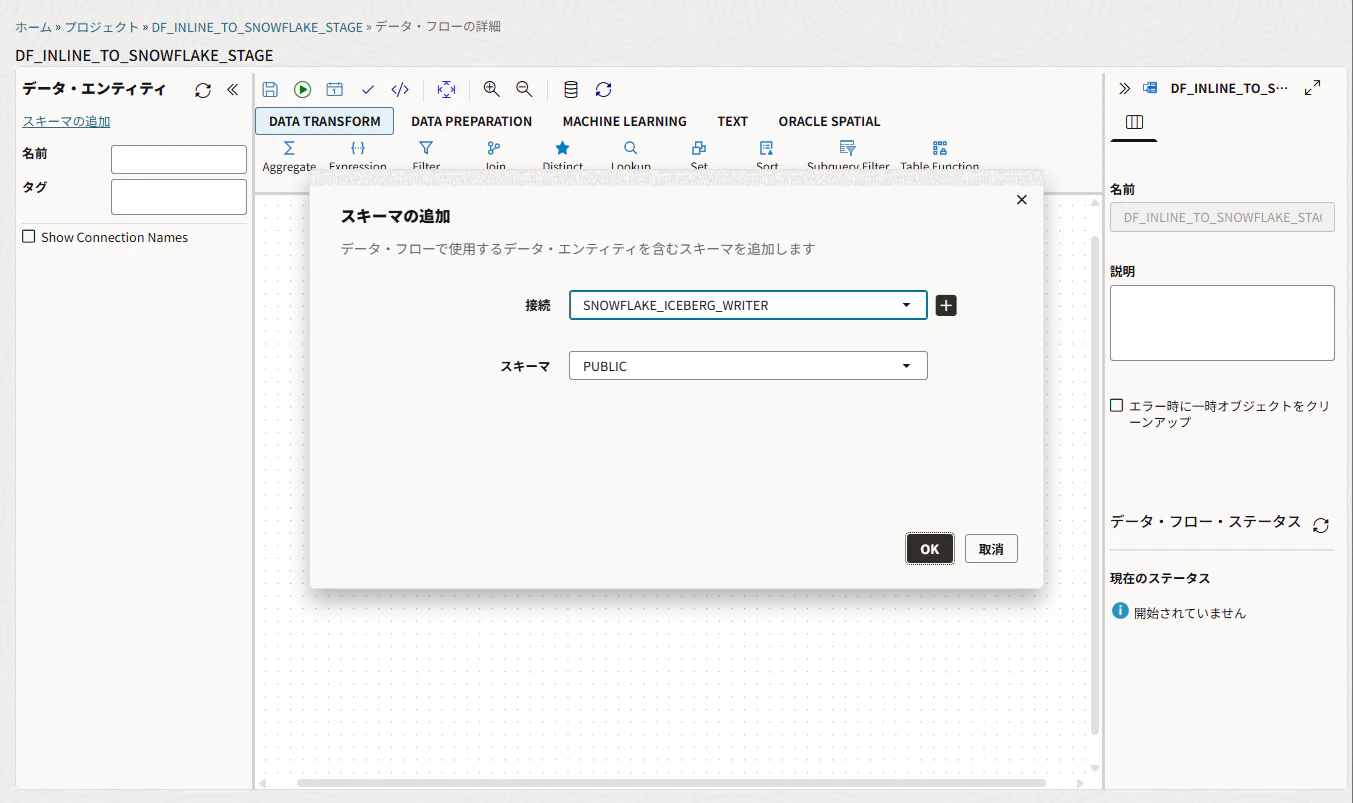
左側の PUBLIC の左にある三角 ▶ をクリックして展開します。
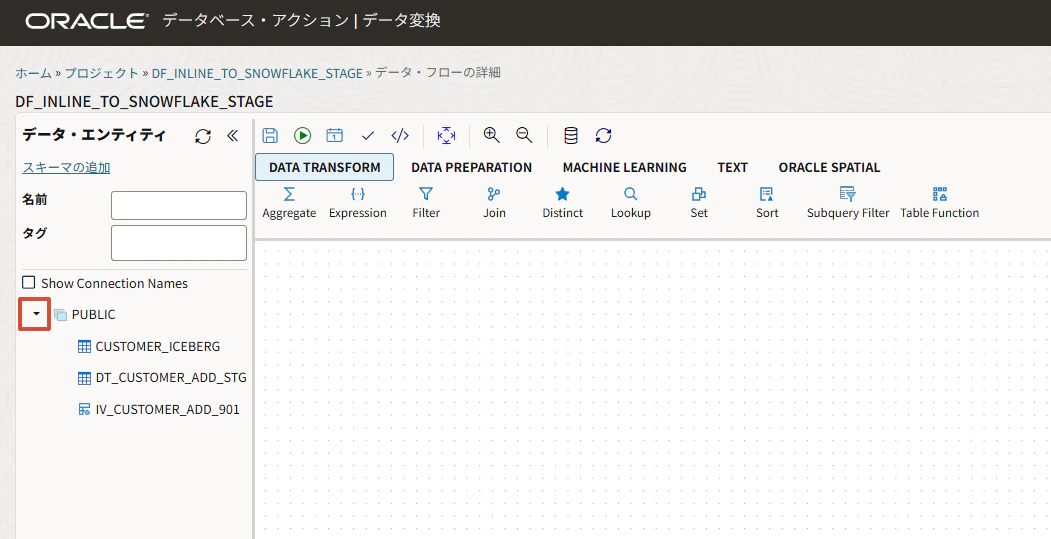
Data Flow Editorが開きます。ドラッグアンドドロップでまずソースを置きます。
IV_CUSTOMER_ADD_901
次にターゲットを置きます。
DT_CUSTOMER_ADD_STG
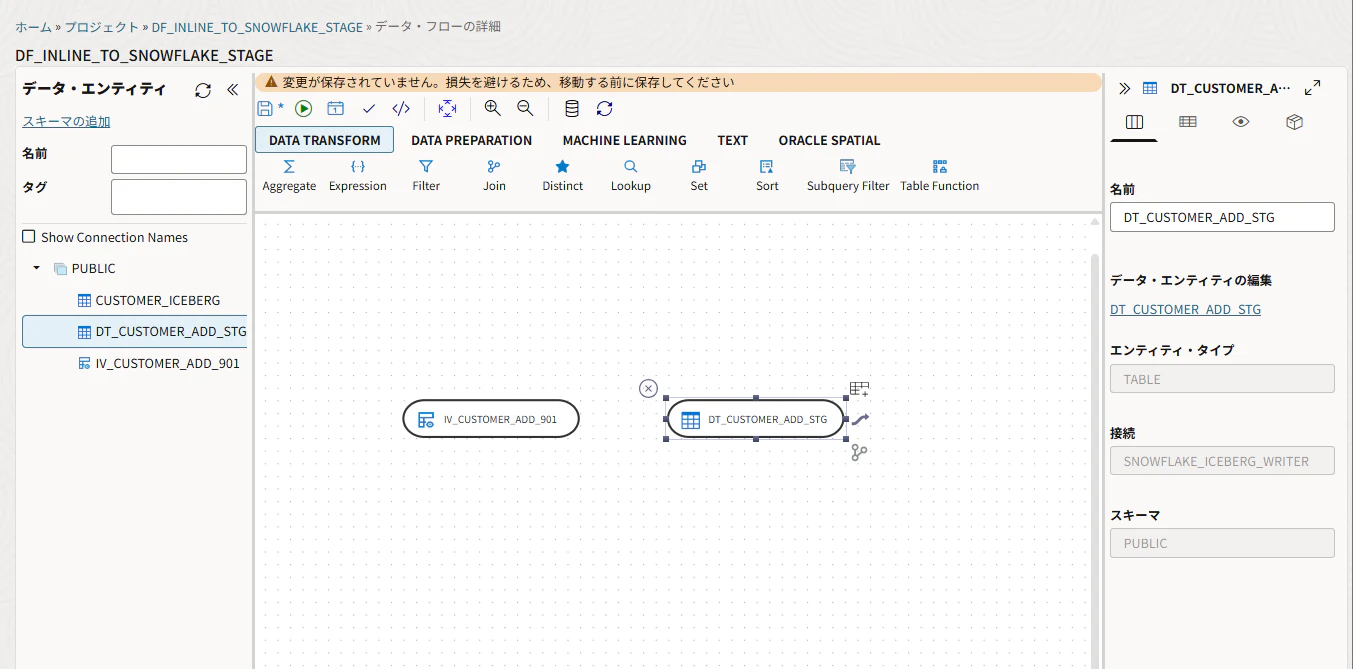
線でつなぎます。
IV_CUSTOMER_ADD_901
→ DT_CUSTOMER_ADD_STG
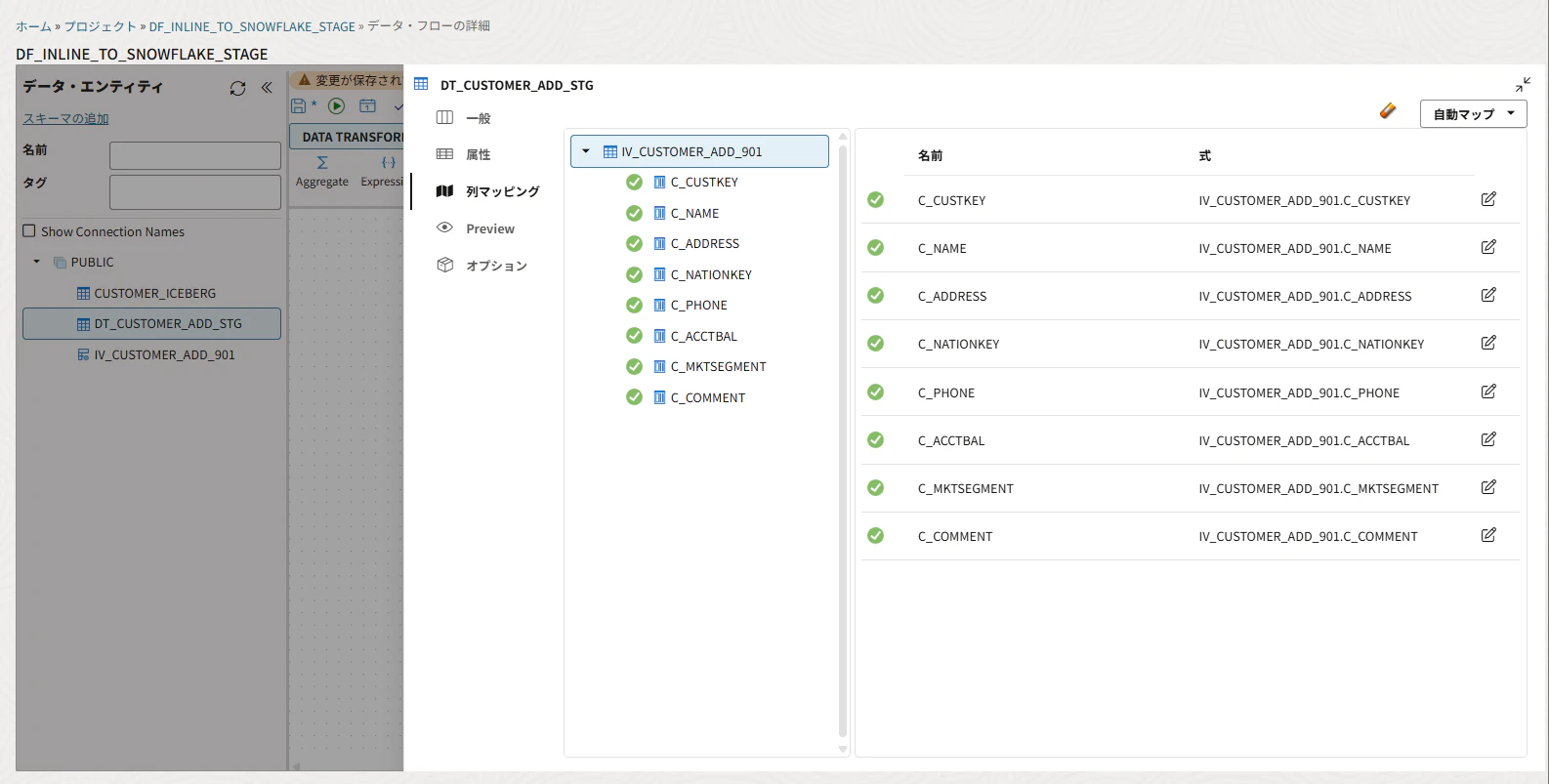
列マッピングを確認します。ターゲットをダブルクリックします。
C_CUSTKEY → C_CUSTKEY
C_NAME → C_NAME
C_ADDRESS → C_ADDRESS
C_NATIONKEY → C_NATIONKEY
C_PHONE → C_PHONE
C_ACCTBAL → C_ACCTBAL
C_MKTSEGMENT → C_MKTSEGMENT
C_COMMENT → C_COMMENT
保存、検証して実行します。
Save
Validate
Execute
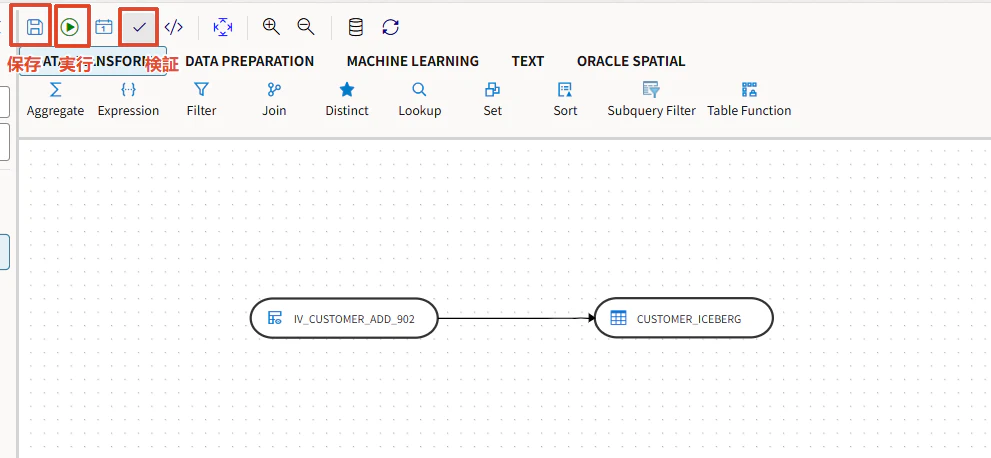
データ・フローを実行します。
ジョブが完了したことを確認します。
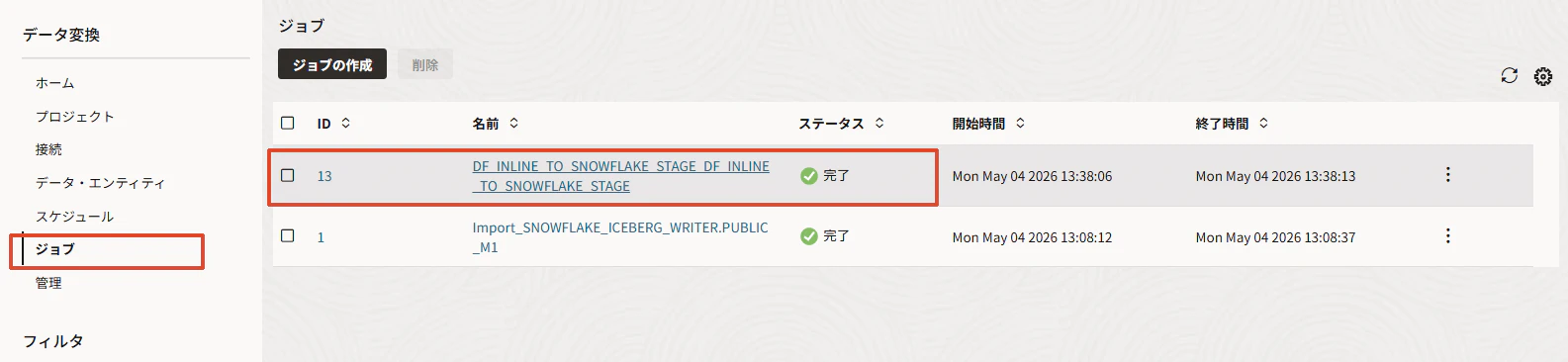
これで、Data TransformsからSnowflakeのステージング表に1行ロードできます。
ステージング表を確認してみます。
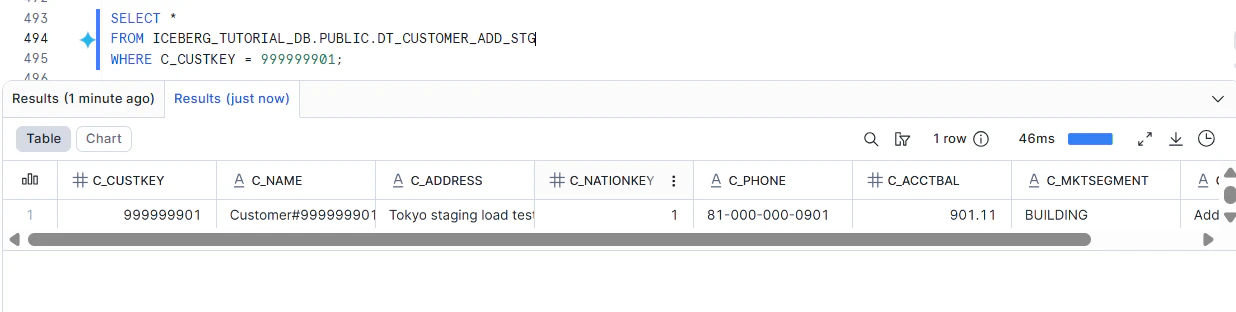
3. ステージング表からIceberg表へData Flowを作成する
新しいData Flowを作ります。
Create Data Flow
名前は例としてこうします。
DF_STAGE_TO_CUSTOMER_ICEBERG
ソースにSnowflakeのステージング表を置きます。
DT_CUSTOMER_ADD_STG
ターゲットにSnowflakeのIceberg表を置きます。
CUSTOMER_ICEBERG
線でつなぎます。
DT_CUSTOMER_ADD_STG
→ CUSTOMER_ICEBERG
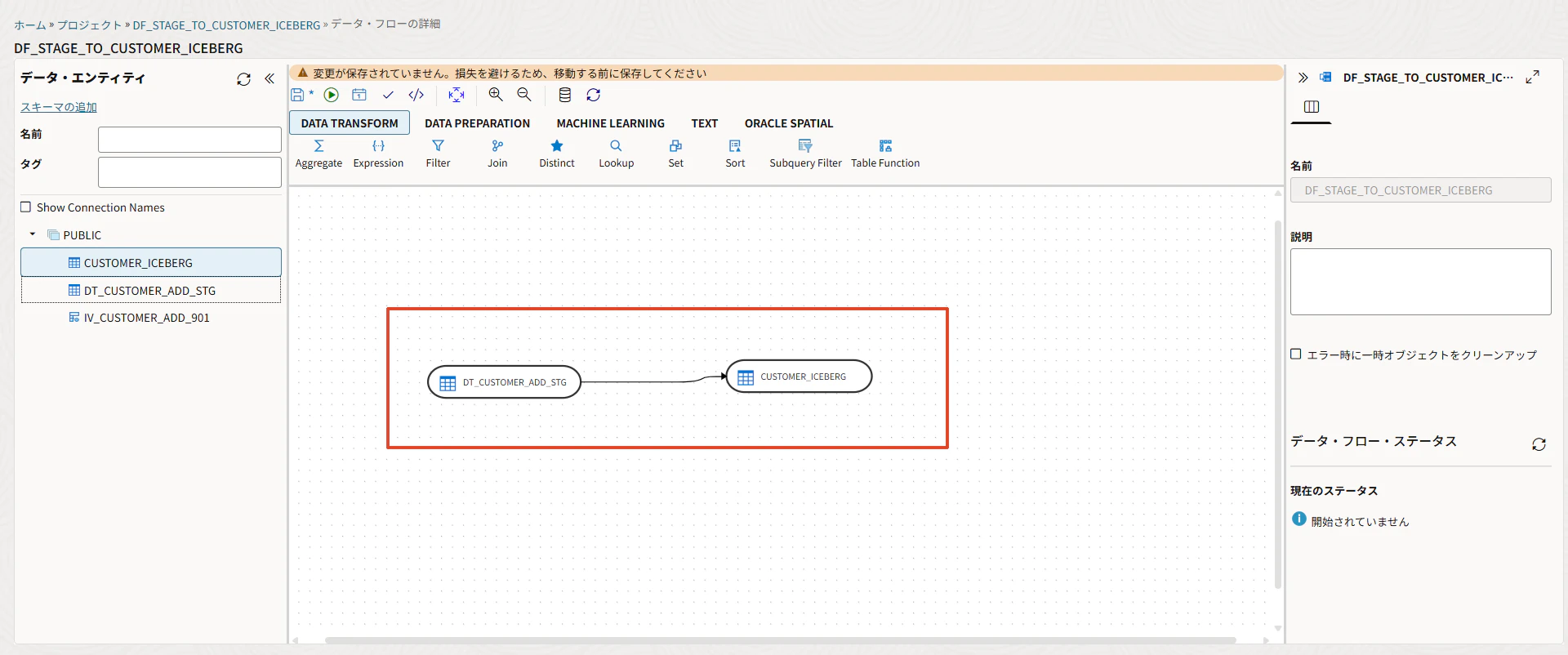
このData Flowも保存して実行します。
Save
Validate
Execute
これで、方法1はこのように実施しました。
Data Transforms:
Inline View
→ Snowflakeステージング表
→ Snowflake-managed Iceberg表
4. ADBから結果を確認する
ジョブが完了したことを確認して

CUSTOMER_ICEBERG表にデータが追加されているか確認します。
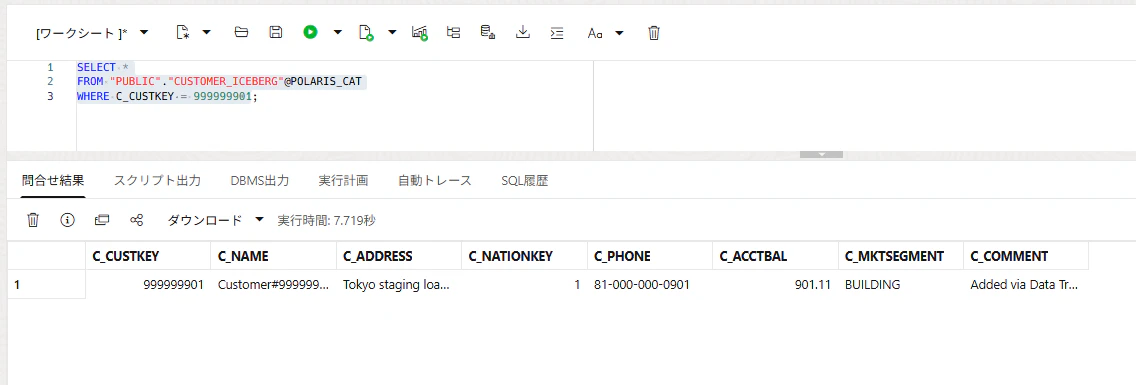
SELECT *
FROM "PUBLIC"."CUSTOMER_ICEBERG"@POLARIS_CAT
WHERE C_CUSTKEY = 999999901;
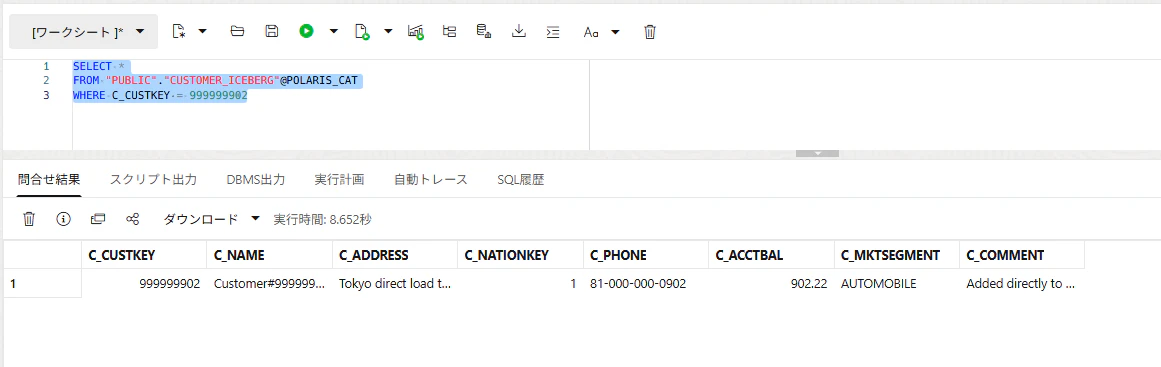
ADBからカタログを指定して、問い合わせをすると、新しく追加したデータが挿入されていることを確認できました!
※注意点として、今回の手順ではステージング表のデータを自動削除していません。同じData Flowを再実行すると、同じC_CUSTKEYの行が再度ロードされる可能性があります。再実行する場合は、別のC_CUSTKEYを使うか、ステージング表を事前に空にしてください。
方法2: Iceberg表へ直接ロードする場合
全体像
方法2では、ステージング表を使わず、Inline ViewからCUSTOMER_ICEBERGへ直接ロードします。
Inline View
1行分の検証データをSELECT文で定義
↓
Data Flow
Inline ViewからSnowflake-managed Iceberg表へ直接ロード
↓
ADB
DBMS_CATALOG経由でCUSTOMER_ICEBERGを確認
1. 直接ロード用のInline Viewを作成する
Data Entities
→ Create Data Entity
Name:
IV_CUSTOMER_ADD_902
Connection:
ADB側の接続
Schema:
ADMIN など
Type:
Inline View
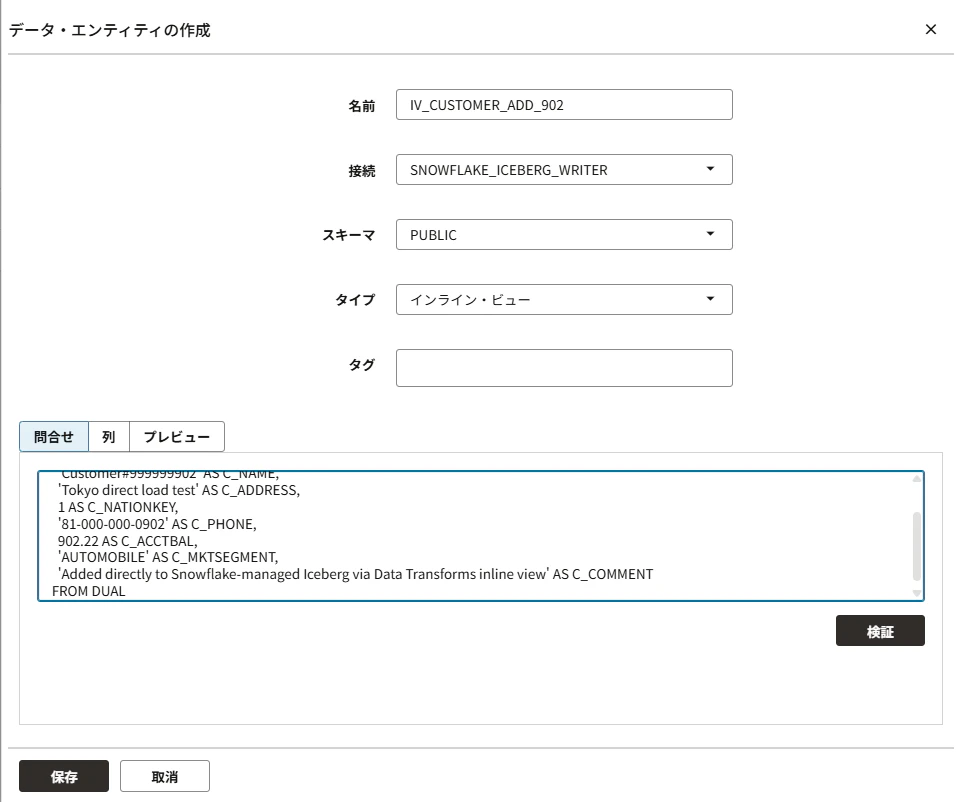
Queryに次を貼ります。
SELECT
999999902 AS C_CUSTKEY,
'Customer#999999902' AS C_NAME,
'Tokyo direct load test' AS C_ADDRESS,
1 AS C_NATIONKEY,
'81-000-000-0902' AS C_PHONE,
902.22 AS C_ACCTBAL,
'AUTOMOBILE' AS C_MKTSEGMENT,
'Added directly to Snowflake-managed Iceberg via Data Transforms inline view' AS C_COMMENT
FROM DUAL
Validate
Preview
Save
を実行します。
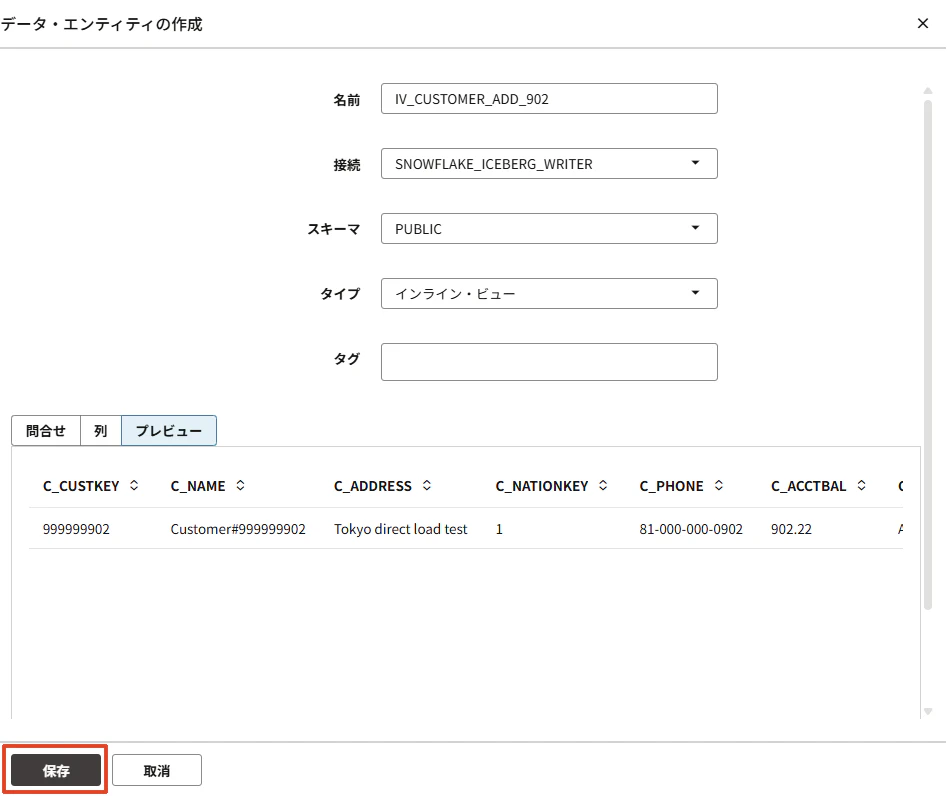
作成されました。
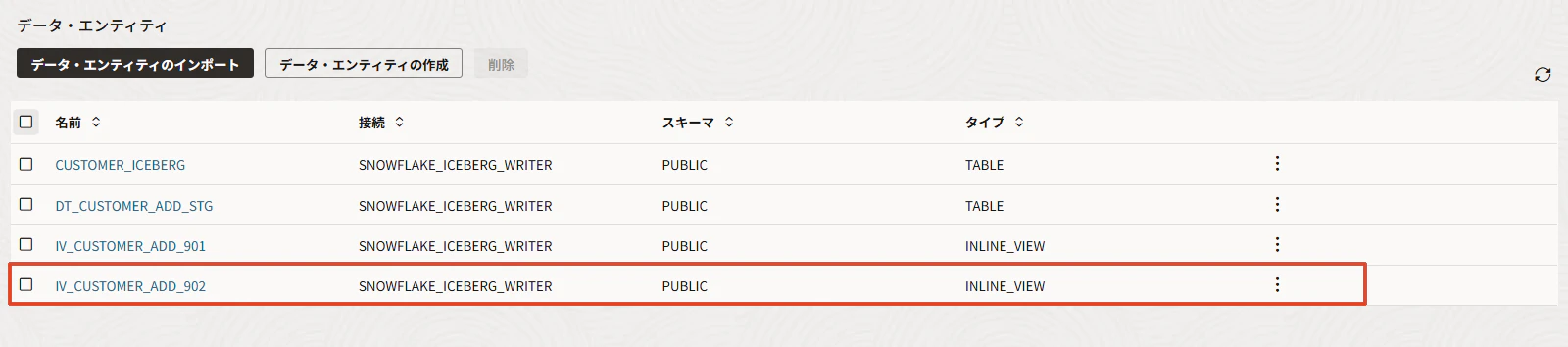
2. Inline ViewからIceberg表へData Flowを作る
左側のメニューから「プロジェクト」>「データ・フローの作成」に進みます。
Create Data Flow
名前は例としてDF_INLINE_TO_CUSTOMER_ICEBERG_DIRECTとしておきます。
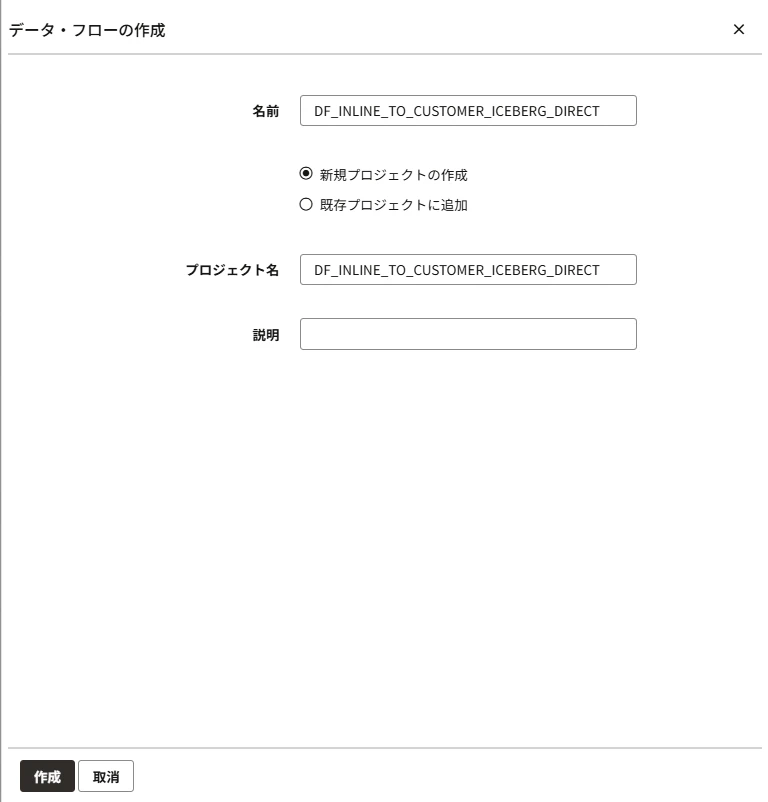
ビルダー画面が開きます。
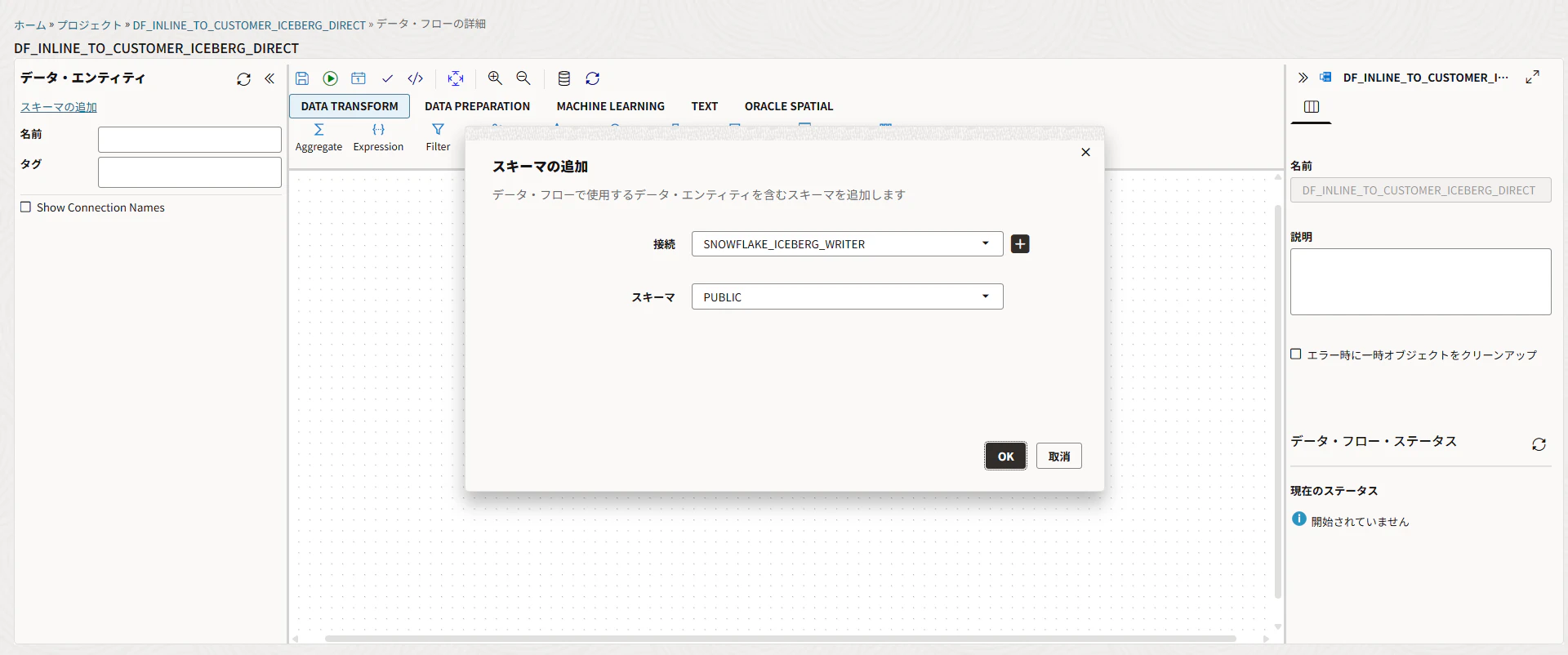
ソースにIV_CUSTOMER_ADD_902を置きます。
またターゲットにCUSTOMER_ICEBERGを置きます。
そして、2つを線でつなぎます。
IV_CUSTOMER_ADD_902
→ CUSTOMER_ICEBERG
ターゲットをダブルクリックして、列マッピングを確認します。
C_CUSTKEY → C_CUSTKEY
C_NAME → C_NAME
C_ADDRESS → C_ADDRESS
C_NATIONKEY → C_NATIONKEY
C_PHONE → C_PHONE
C_ACCTBAL → C_ACCTBAL
C_MKTSEGMENT → C_MKTSEGMENT
C_COMMENT → C_COMMENT
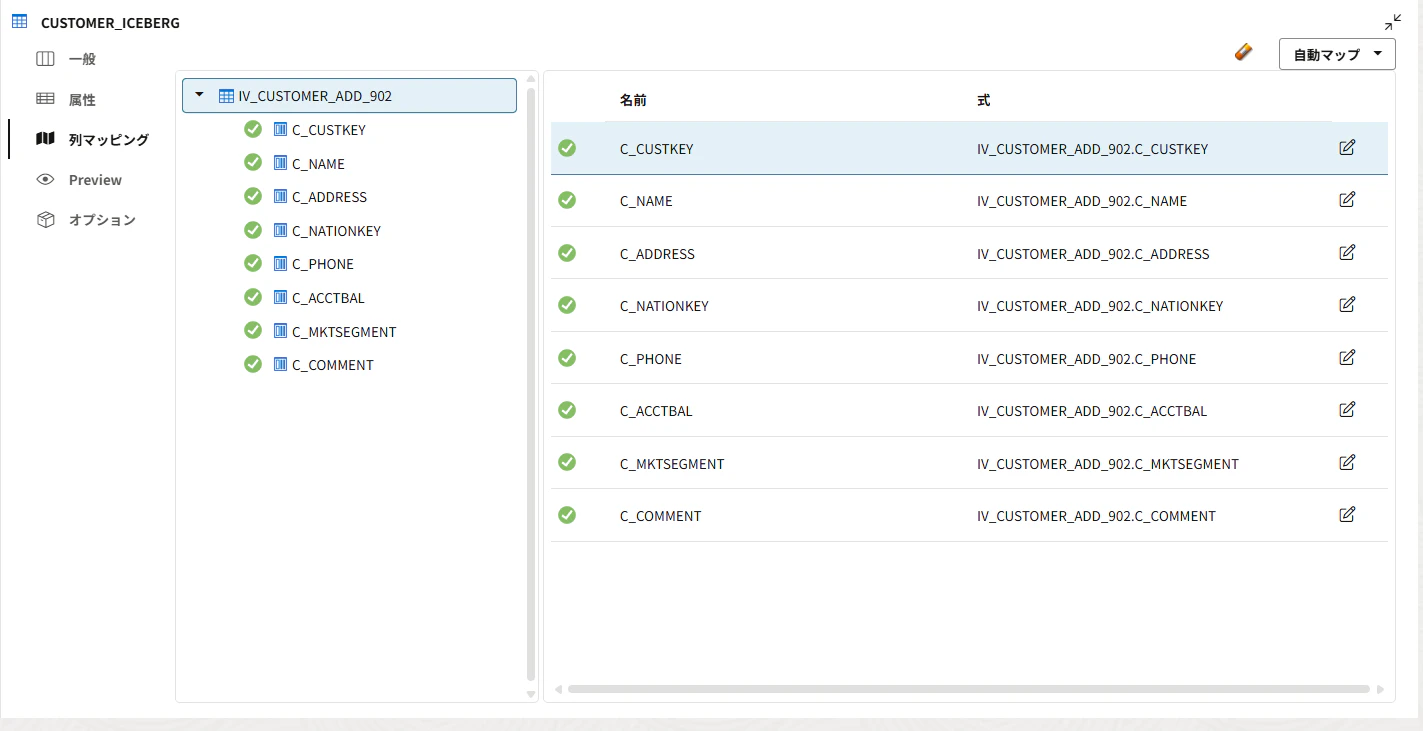
保存して実行します。
Save
Validate
Execute
これで、Data TransformsからSnowflake接続経由でCUSTOMER_ICEBERGへ直接1行ロードできます。
ここでいう直接ロードは、S3上のIcebergファイルをData Transformsが直接触るという意味ではありません。
Data Transforms
→ Snowflake接続
→ CUSTOMER_ICEBERG
→ SnowflakeがIcebergメタデータを更新
という動きをしています。
3. ADBから追加結果を確認する
ジョブが完了したことを確認して

CUSTOMER_ICEBERG表にデータが追加されているか確認します。
SELECT *
FROM "PUBLIC"."CUSTOMER_ICEBERG"@POLARIS_CAT
WHERE C_CUSTKEY = 999999902;
注意
Snowflake-managed Iceberg表に追加した後、必要に応じてADB側でDBMS_CATALOGのキャッシュをフラッシュします。
BEGIN
DBMS_CATALOG.FLUSH_CATALOG_CACHE(
catalog_name => 'POLARIS_CAT'
);
END;
/
終わりに
今回は、ADBのData Transformsを使って、Snowflakeで作成したSnowflake-managed Iceberg表にデータを追加してみました。
ステージング表を経由する方法は、Iceberg表へ入れる前に中間データを確認できるため、より安全に検証できます。
どちらの方法でも、Data TransformsがS3上のIcebergファイルを直接更新しているわけではありません。Data TransformsはSnowflake接続経由で表へロードし、Icebergのデータファイルやメタデータの更新はSnowflakeが担当します。
最後に、ADBからはDBMS_CATALOG経由で追加後のIceberg表を確認できました。これにより、Snowflake-managed Iceberg表に対して、Data Transformsからデータを追加し、ADB側から参照する一連の流れを確認できました。
参考
Transform Data Using Data Studio - Work with Connections