はじめに
Apache Icebergを勉強し始めると、メタデータ や マニフェスト などのワードに出逢いますが、実際これらがどのように機能しているのか、説明を読むだけでは腹落ちするのが難しいです。
今回はその理解を深めるために、まっさらな状態から CREATE TABLE や INSERT をしたときの動きを、実際にどんなファイルが作られるのか に注目して整理していきたいと思います。
「Icebergテーブルって、結局どこに何ができているの?」を、図とファイル構造を見ながら確認していきます。
Icebergの基本アーキテクチャ
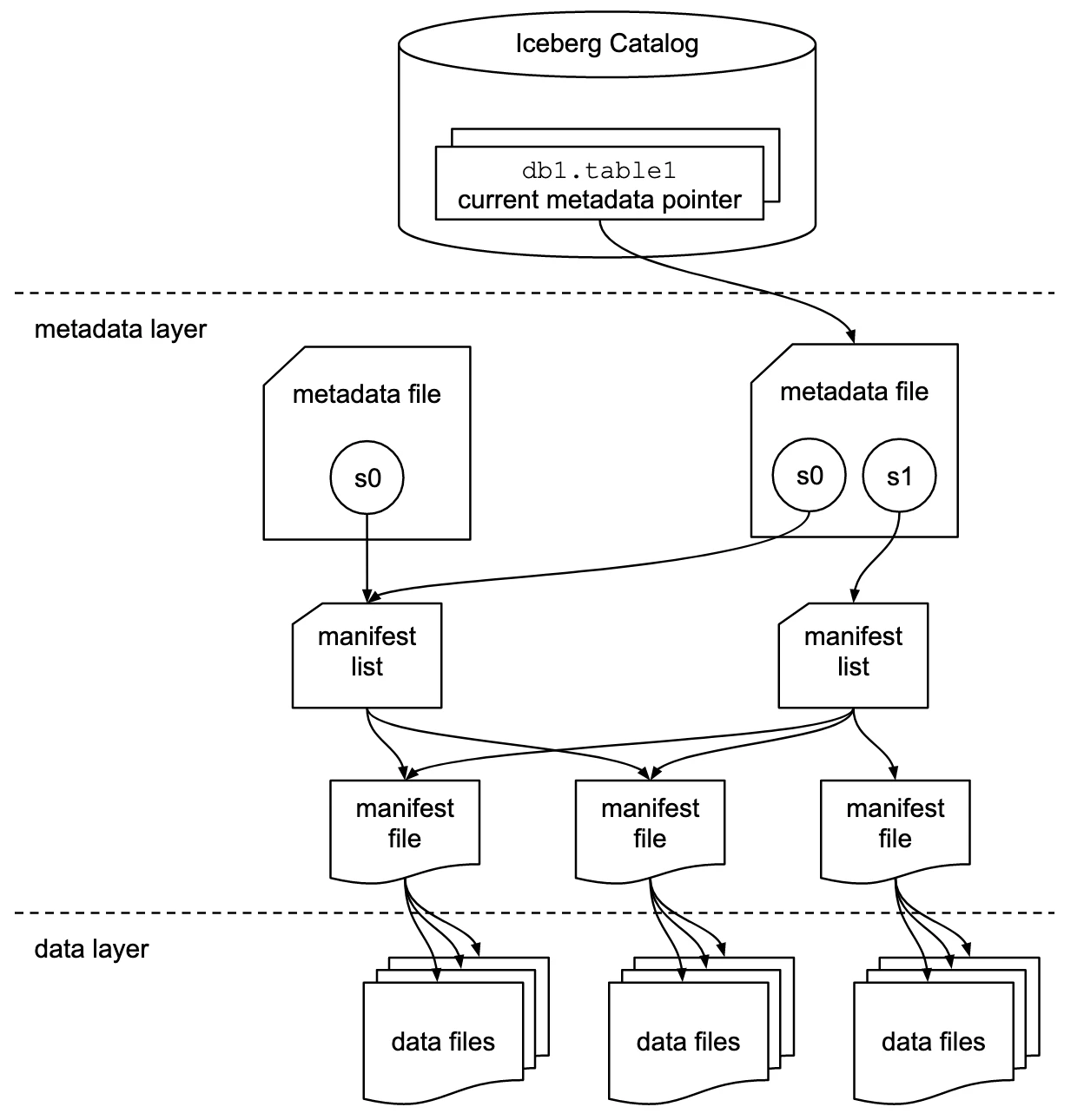
この図は、Apache Icebergの基本的な構成です。
Icebergでは、Catalog から現在の metadata file をたどり、そこから snapshot、manifest list、manifest file を経由して、最終的に data files にアクセスします。
Catalog → metadata file → snapshot → manifest list → manifest file → data files
この時点で細かく理解しきる必要はありません。
以降では、CREATE TABLE や INSERT を実行したときに、図のどの部分にあたるファイルが作られるのかを順番に見ていきます。
今回の前提
今回は、次のようなIcebergテーブルを例に作成してみます。
CREATE TABLE dev.db.sales (
id INT,
item STRING,
amount INT
)
USING iceberg;
その後、次のように3件だけデータを追加します。
INSERT INTO dev.db.sales VALUES
(1, 'apple', 100),
(2, 'banana', 200),
(3, 'orange', 300);
この記事の例では Hadoopカタログ を使い、warehouseを OCI Object Storage に向けています。
そのため、メタデータファイル、マニュフェストリスト、マニュフェストファイル、データファイルは、すべてObject Storage上の同じIcebergテーブル配下に保存されます。
Hive MetastoreやRESTカタログを使う構成では、最新メタデータファイルの管理方法が変わります。
ただし、メタデータファイルからスナップショット、マニュフェストリスト、マニュフェストファイル、データファイルへたどるというIcebergの基本構造は同じです。
保存先は、たとえば次のようなwarehouse配下とします。
oci://spark@NAMESPACE/iceberg/
※spark はバケット名。
例では、dev.db.sales というテーブルを扱い、データファイル形式はParquetを想定します。なお、本文では分かりやすさのために metadata/ や data/ をディレクトリのように表記します。
実際の配置イメージは次のようになります。
iceberg/
└── db/
└── sales/
ファイル名や細かな配置は、Spark / Flink / Trino などの実行エンジン、Icebergのバージョン、Catalog種別によって変わります。
ここでは構造を理解するための代表例として見ていきます。
:
1. CREATE TABLEを実行した場合
まず、まっさらな状態で CREATE TABLE を実行します。
CREATE TABLE dev.db.sales (
id INT,
item STRING,
amount INT
)
USING iceberg;
この時点では、まだデータは1件も作られていません。
作られるもの
CREATE TABLE を実行した場合、基本的に作られる中心は metadata file です。
たとえば、以下のような構成になります。
iceberg/
└── db/
└── sales/
└── metadata/ *追加
├── v1.metadata.json *追加
└── version-hint.text *追加
また、Catalogの種類によっては次のような名前になることもあります。
metadata/
└── 00000-3f8b7c0e-2a4d-4f1a-9c1b-xxxxxxxxxxxx.metadata.json
このmetadata fileには、テーブルのスキーマや保存場所、パーティション定義などが入ります。
metadata fileの中身イメージ
v1.metadata.json の中身は、イメージとしては次のようなものです。
{
"format-version": 2,
"table-uuid": "9f4b0c9d-xxxx-xxxx-xxxx-xxxxxxxxxxxx",
"location": "oci://spark@NAMESPACE/iceberg/db/sales",
"last-column-id": 3,
"schemas": [
{
"schema-id": 0,
"fields": [
{ "id": 1, "name": "id", "required": false, "type": "int" },
{ "id": 2, "name": "item", "required": false, "type": "string" },
{ "id": 3, "name": "amount", "required": false, "type": "int" }
]
}
],
"current-schema-id": 0,
"partition-specs": [
{
"spec-id": 0,
"fields": []
}
],
"default-spec-id": 0,
"snapshots": [],
"current-snapshot-id": null
}
ポイントは、次のとおりです。
-
schemasに列定義が入る -
partition-specsにパーティション定義が入る -
snapshotsはまだ空 -
current-snapshot-idはまだ存在しない、またはnull相当
(なお、Iceberg Java実装では、古いフォーマットでは「現在のSnapshotなし」を -1 として扱う場合もあります。仕様上は null や省略と同等に扱えるものとして説明されています。)
この時点で作られないもの
CREATE TABLE だけでは、基本的に次のものはまだ作られません。
| 要素 | 作られるか |
|---|---|
| Data File | 作られない |
| Manifest File | 作られない |
| Manifest List | 作られない |
| Snapshot | 基本的にまだない |
つまりこの段階は、
テーブルの設計図だけができていて、データ本体はまだない状態
です。
2. INSERTを実行した場合
次に、作成した空のテーブルにデータを追加します。
INSERT INTO dev.db.sales VALUES
(1, 'apple', 100),
(2, 'banana', 200),
(3, 'orange', 300);
Sparkでは、Icebergテーブルに新しいデータを追加する操作として INSERT INTO を使います。Iceberg公式ドキュメントでも、INSERT INTO はテーブルに新しいデータをappendする操作として説明されています
INSERTで作られるもの
INSERT を実行すると、主に次のものが作られます。
iceberg/
└── db/
└── sales/
├── data/ *追加
│ └── 00000-0-7f8c2b6d-9c4a-4f1a-a123-xxxxxxxxxxxx.parquet *追加
└── metadata/
├── v1.metadata.json
├── v2.metadata.json *追加
├── snap-8392038475629183741-1-7f8c2b6d.avro *追加
├── 7f8c2b6d-9c4a-4f1a-a123-xxxxxxxxxxxx-m0.avro *追加
└── version-hint.text
増えたものを整理すると、次のとおりです。
| ファイル | 役割 |
|---|---|
data/*.parquet |
実際のデータ本体 |
*-m0.avro |
マニュフェストファイル |
snap-*.avro |
マニュフェストリスト |
v2.metadata.json |
INSERT後の最新メタデータファイル |
図でいうと、ここで初めて次の流れができます。
スナップショット
↓
マニュフェストリスト
↓
マニュフェストファイル
↓
データファイル
この最初のスナップショットを、図では s0 のように表しています。
3. データファイル:実データ本体
data/ 配下のParquetファイルには、実際にINSERTした行が入ります。
data/
└── 00000-0-7f8c2b6d-9c4a-4f1a-a123-xxxxxxxxxxxx.parquet
中身のイメージは次のとおりです。
| id | item | amount |
|---|---|---|
| 1 | apple | 100 |
| 2 | banana | 200 |
| 3 | orange | 300 |
ただし、実体はParquetなどのカラムナ形式なので、CSVのようにそのままテキストで読めるわけではありません。
また、INSERTした行数とデータファイル数は必ず一致しません。 Sparkのタスク数、パーティション、ファイルサイズ設定などによって、1つまたは複数のデータファイルが作られます。
4. マニュフェストファイル:どのデータファイルがあるのかを記録する
次に、マニュフェストファイルです。
metadata/
└── 7f8c2b6d-9c4a-4f1a-a123-xxxxxxxxxxxx-m0.avro
マニュフェストファイルは、このSnapshotで使うData Fileの一覧 を持つAvroファイルです。
中身のイメージは次のようになります。
| status | content | file_path | file_format | record_count |
|---|---|---|---|---|
| ADDED | DATA | .../data/00000-0-7f8c2b6d-....parquet |
PARQUET | 3 |
実際には、これに加えて次のような情報も持ちます。
- パーティション値
- ファイルサイズ
- レコード件数
- null件数
- 列ごとの下限値・上限値
- 追加されたファイルか、既存ファイルか、削除されたファイルか
Icebergでは、マニュフェストファイルがはデータファイルや削除ファイルの情報を持ち、各ファイルのパーティション情報、メトリクス、追跡情報を含みます。クエリ計画時にはこの情報を使って読むべきファイルを判断します。
5. マニュフェストリスト:スナップショットが使うマニュフェストファイルの一覧
次に、マニュフェストリストです。
metadata/
└── snap-8392038475629183741-1-7f8c2b6d.avro
マニュフェストリストは、あるスナップショットが参照するマニュフェストファイルの一覧 を持ちます。
中身のイメージは次のようになります。
| manifest_path | added_files_count | existing_files_count | added_rows_count |
|---|---|---|---|
.../metadata/7f8c2b6d-...-m0.avro |
1 | 0 | 3 |
つまり、スナップショットからいきなりデータファイルを見るのではなく、次の順番でたどります。
スナップショット
↓
マニュフェストリスト
↓
マニュフェストファイル
↓
データファイル
この構造により、Icebergはテーブル全体のファイルを毎回すべて見に行くのではなく、メタデータを使って効率よく読み取り対象を絞り込めます。Icebergのパフォーマンス解説でも、まずマニュフェストリストでマニュフェストを絞り込み、その後マニュフェストを読んでデータファイルを取得する流れが説明されています。
6. INSERT後のメタデータファイル
INSERT後には、新しいメタデータファイルが作られます。
metadata/
├── v1.metadata.json
└── v2.metadata.json
新しく作られた v2.metadata.json には、INSERTによって作られたスナップショット情報が追加されます。
イメージは次のような形です。
{
"format-version": 2,
"table-uuid": "9f4b0c9d-xxxx-xxxx-xxxx-xxxxxxxxxxxx",
"location": "oci://spark@NAMESPACE/iceberg/db/sales",
"current-snapshot-id": 8392038475629183741,
"snapshots": [
{
"snapshot-id": 8392038475629183741,
"timestamp-ms": 1760000000000,
"summary": {
"operation": "append",
"added-data-files": "1",
"added-records": "3"
},
"manifest-list": "oci://spark@NAMESPACE/iceberg/db/sales/metadata/snap-8392038475629183741-1-7f8c2b6d.avro",
"schema-id": 0
}
],
"snapshot-log": [
{
"timestamp-ms": 1760000000000,
"snapshot-id": 8392038475629183741
}
]
}
ここで重要なのは、current-snapshot-id が設定されていることです。
このIDが、「今このテーブルの最新状態はどのスナップショットか」を示します。
図でいうと、メタデータファイルの中にある s0 がこのスナップショットに相当します。
7. 2回目のINSERTをすると、図に近い形になる
上の図には、メタデータファイルが2つあり、右側のメタデータファイルには s0 と s1 が描かれています。
これは、たとえば2回目のINSERTをした後の状態として見ると分かりやすいです。
INSERT INTO dev.db.sales VALUES
(4, 'grape', 400),
(5, 'melon', 500);
この場合、イメージとしては次のようになります。
iceberg/
└── db/
└── sales/
├── data/
│ ├── 00000-0-7f8c2b6d-....parquet
│ └── 00000-0-a91d3f10-....parquet *追加
└── metadata/
├── v1.metadata.json
├── v2.metadata.json
├── v3.metadata.json *追加
├── snap-8392038475629183741-1-7f8c2b6d.avro
├── snap-1029384756102938475-1-a91d3f10.avro *追加
├── 7f8c2b6d-....-m0.avro
└── a91d3f10-....-m0.avro *追加
このとき、カタログの 現在のメタデータポインタ は最新の v3.metadata.json を指します。
v3.metadata.json の中には、過去のスナップショット s0 と、新しいスナップショット s1 の情報が含まれます。
そして current-snapshot-id は s1 を指します。
図の右側のメタデータファイルが、まさにこの状態です。
現在のメタデータファイル
├── s0
└── s1 ← current-snapshot-id
また、図では複数のマニュフェストリストから同じマニュフェストファイルへ矢印が伸びています。
これは、マニュフェストファイルがスナップショット間で再利用されることがあるためです。Icebergでは、変更のたびにすべてのメタデータを書き直すのではなく、再利用できるマニュフェストファイルを使いながら新しいスナップショットを構成します。
8. カタログは何をしているのか
カタログは、ざっくり言うと テーブル名から現在のメタデータファイルを見つけるための台帳 です。
今回の例では、Sparkに次のようなカタログを設定しています。
.config("spark.sql.catalog.dev", "org.apache.iceberg.spark.SparkCatalog")
.config("spark.sql.catalog.dev.type", "hadoop")
.config("spark.sql.catalog.dev.warehouse", "oci://spark@NAMESPACE/iceberg/")
この設定により、dev というIcebergカタログが作られます。
ユーザーは次のようにテーブル名でアクセスします。
SELECT * FROM dev.db.sales;
このとき、処理エンジンはカタログを見て、
dev.db.sales
-> oci://spark@NAMESPACE/iceberg/db/sales/metadata/v3.metadata.json
のように、現在のメタデータファイルを見つけます。
図では、カタログの中にある 現在のメタデータポインタ が、右側のメタデータファイルを指しています。
カタログの種類によって、この持ち方は変わります。
| カタログ種別 | 現在のメタデータファイルの持ち方 |
|---|---|
| Hadoopカタログ | テーブルディレクトリや version-hint.text などをもとに解決 |
| Hive Metastore / Glueカタログ | メタストア側にメタデータファイルの場所を保持 |
| RESTカタログ | REST API経由でメタデータファイルの場所を取得 |
厳密な実装はカタログ種別で異なりますが、論理的には、
このテーブルを見るなら、まずこのメタデータファイルから始めてください
と教えてくれる役割です。
9. SELECT時はどう読まれるのか
SELECT * FROM dev.db.sales を実行したときの流れは、次のようになります。
1. カタログを見る
↓
2. 現在のメタデータファイルを読む
↓
3. current-snapshot-idを見る
↓
4. スナップショットからマニュフェストリストを読む
↓
5. マニュフェストリストからマニュフェストファイルを読む
↓
6. マニュフェストファイルからデータファイル一覧を取得する
↓
7. 必要なParquetファイルを読む
図に合わせると、右側のメタデータファイルから s1 を見て、s1 が指すマニュフェストリストを読み、そこからマニュフェストファイル、データファイルへたどっていく流れです。
このように、Icebergでは「ディレクトリ配下にあるファイルを全部読む」のではなく、現在のスナップショットからたどれるデータファイルだけを読む のがポイントです。
10. CREATE TABLEとINSERTで作成されるファイルまとめ
| 操作 | 作られる主なもの | データファイル | スナップショット | マニュフェストリスト / マニュフェストファイル |
|---|---|---|---|---|
CREATE TABLE |
メタデータファイル | なし | 基本なし | なし |
1回目のINSERT
|
データファイル / マニュフェストファイル / マニュフェストリスト / 新しいメタデータファイル | あり |
s0 ができる |
あり |
2回目以降のINSERT
|
追加データファイル / 追加マニュフェスト / 新しいメタデータファイル | あり |
s1, s2... ができる |
既存マニュフェストを再利用することもある |
一言でいうと、
-
CREATE TABLEは テーブルの設計図を作る -
INSERTは データ本体を置き、そのデータをIcebergのメタデータに登録する -
INSERTを重ねると スナップショットが増え、カタログの現在のメタデータポインタが新しいメタデータファイルへ切り替わる
という動きです。
おわりに
Icebergテーブルは、単なるParquetファイルの集まりではありません。
CREATE TABLE しただけなら、主に作られるのは メタデータファイル です。
この時点では、データファイルやマニュフェストファイルはまだ基本的に存在しません。
一方で INSERT すると、実データである データファイル に加えて、それを管理する マニュフェストファイル、スナップショット単位で束ねる マニュフェストリスト、そして最新状態を示す新しい メタデータファイル が作られます。
最初は少し複雑に見えますが、たどる順番はシンプルです。
カタログ
↓
メタデータファイル
↓
スナップショット
↓
マニュフェストリスト
↓
マニュフェストファイル
↓
データファイル
上の図も、この順番で見るとかなり理解しやすくなります。
CREATE TABLEで設計図を作り、INSERTでデータとその管理情報を追加する。
まずはこのイメージを持っておくと、Icebergのメタデータやマニュフェストの役割がぐっと見えやすくなると思います。